使用梯度下降法实现多项式回归
 使用梯度下降法实现多项式回归
使用梯度下降法实现多项式回归
使用梯度下降法实现多项式回归
实验目的
本实验旨在通过梯度下降法实现多项式回归,探究不同阶数的多项式模型对同一组数据的拟合效果,并分析样本数量对模型拟合结果的影响。
实验材料与方法
数据准备
- 生成训练样本:我们首先生成了20个训练样本,其中自变量服从均值为0,方差为1的标准正态分布。因变量由下述多项式关系加上均值为0,方差为1的误差项构成: Y=5+4X+3X2+2X3+er
- 数据可视化:使用Matplotlib库绘制了生成的数据点。
代码
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以保证实验可重复性
np.random.seed(0)
# 生成20个训练样本
n_samples = 20
X = np.random.normal(0, 1, n_samples)
e_r = np.random.normal(0, 1, n_samples) # 误差项
# 计算Y值
Y = 5 + 4 * X + 3 * X**2 + 2 * X**3 + e_r
# 使用matplotlib显示生成的数据
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.title('Generated Data')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()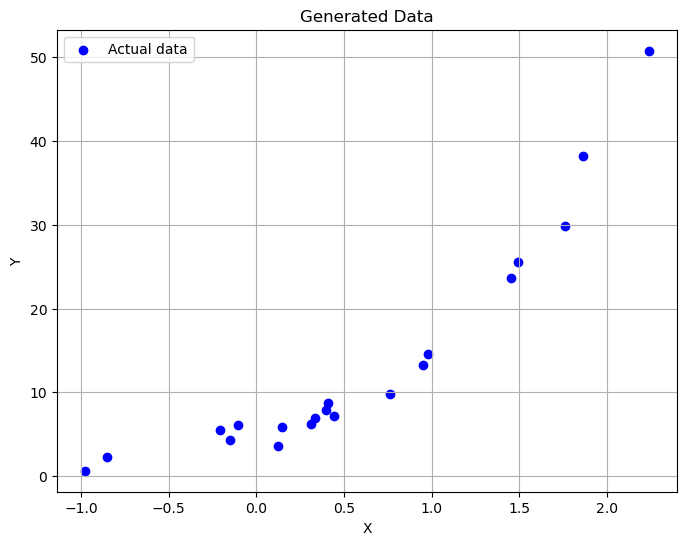
模型定义
- 定义多项式回归模型:我们定义了一个
MultinomialModel类,该类接受训练数据作为输入,并能够返回多项式模型的参数。类内部包括构造设计矩阵的方法、拟合数据的方法(使用梯度下降法)以及预测方法。
代码
class MultinomialModel:
def __init__(self, degree):
self.degree = degree
self.coefficients = None
def _design_matrix(self, X):
"""构造设计矩阵"""
n_samples = len(X)
design_matrix = np.ones((n_samples, self.degree + 1))
for i in range(1, self.degree + 1):
design_matrix[:, i] = X ** i
return design_matrix
def fit(self, X, Y, learning_rate=0.01, iterations=1000):
"""使用梯度下降法来拟合模型"""
n_samples = len(X)
self.coefficients = np.zeros(self.degree + 1) # 初始化系数
# 构造设计矩阵
X_design = self._design_matrix(X)
for _ in range(iterations):
# 预测
predictions = np.dot(X_design, self.coefficients)
# 损失函数的导数
gradient = 2 / n_samples * np.dot(X_design.T, predictions - Y)
# 更新系数
self.coefficients -= learning_rate * gradient
def predict(self, X):
"""基于学习到的模型预测新的数据点"""
X_design = self._design_matrix(X)
return np.dot(X_design, self.coefficients)
# 使用上述定义的类
degree = 3 # 设定多项式的阶数
model = MultinomialModel(degree)
# 拟合数据
model.fit(X, Y)
# 预测
Y_pred = model.predict(X)
# 可视化拟合结果
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.plot(X, Y_pred, color='red', label='Fitted curve')
plt.title('Polynomial Regression Fit')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
模型拟合与结果展示
- 模型训练与预测:对于设定的不同阶数的多项式模型,使用梯度下降法进行训练,并预测数据。
- 结果可视化:在同一张图表中,绘制了不同阶数多项式模型的拟合曲线,同时保留原始数据点的散点图。
代码
# 继续使用之前定义的MultinomialModel类
# 使用上述定义的类
degree = 3 # 设定多项式的阶数
model = MultinomialModel(degree)
# 拟合数据
model.fit(X, Y)
# 预测
Y_pred = model.predict(X)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
# 可视化拟合结果
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.plot(X_fit, Y_fit, color='red', label='Fitted curve', linewidth=2)
plt.title(f'Polynomial Regression Fit (Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 定义不同的多项式阶数
degrees = [1, 2, 3, 4, 5]
# 创建一个新的图形
plt.figure(figsize=(10, 8))
# 对于每个多项式阶数,拟合并绘制曲线
for degree in degrees:
model = MultinomialModel(degree)
model.fit(X, Y)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
plt.plot(X_fit, Y_fit, label=f'Degree {degree}')
# 绘制实际的数据点
plt.scatter(X, Y, color='blue', label='Actual data')
# 设置图例和其他细节
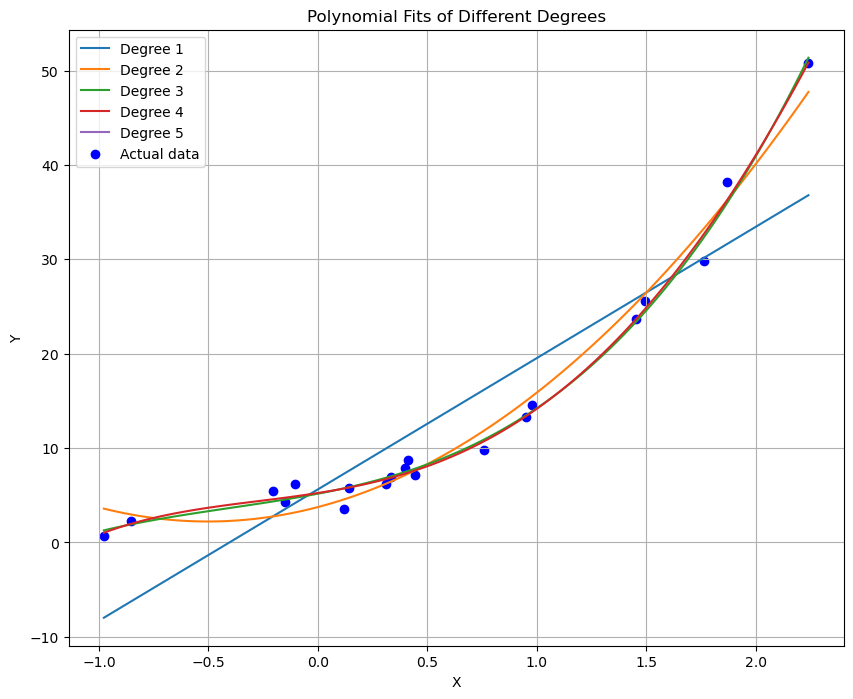
plt.title('Polynomial Fits of Different Degrees')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()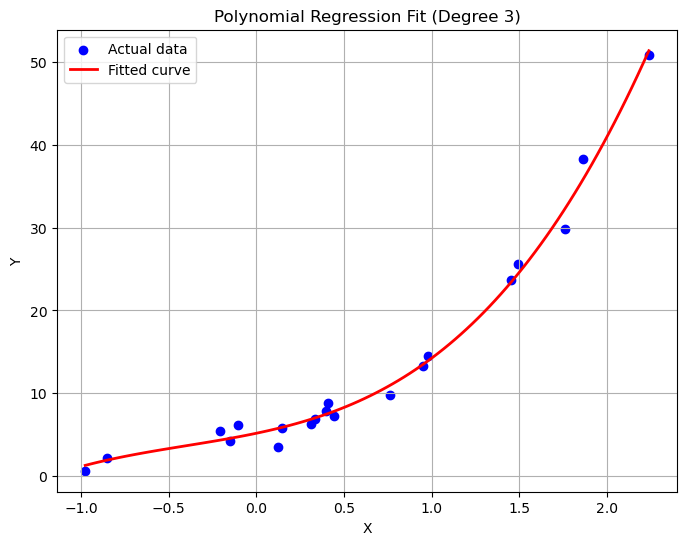
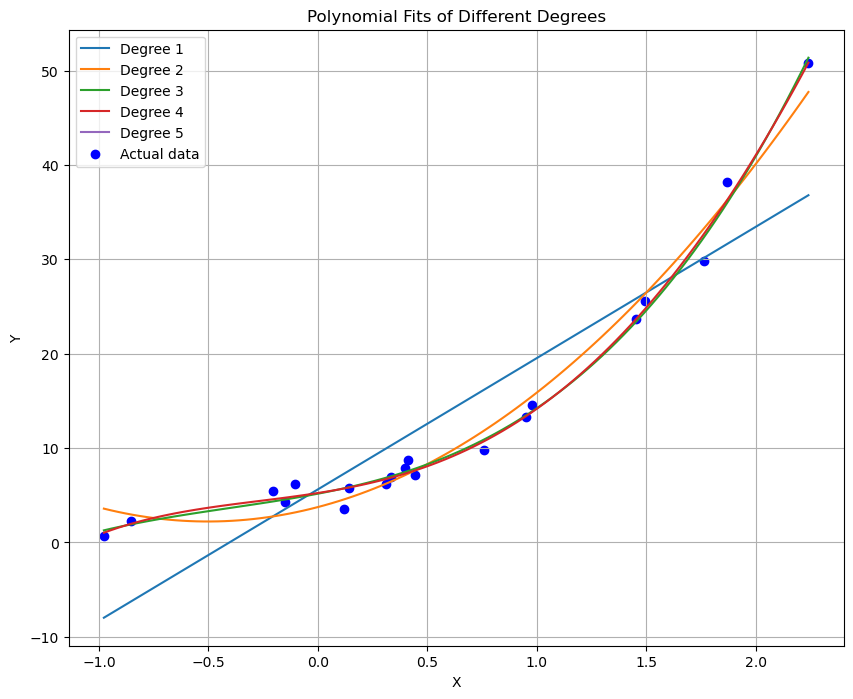
样本数量影响分析
- 增加样本数量:将样本数量从20增加到100,并重复以上步骤,观察模型拟合效果的变化。
代码
# 生成100个训练样本
n_samples = 100
X = np.random.normal(0, 1, n_samples)
e_r = np.random.normal(0, 1, n_samples) # 误差项
# 计算Y值
Y = 5 + 4 * X + 3 * X**2 + 2 * X**3 + e_r
# 使用matplotlib显示生成的数据
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.title('Generated Data with 100 samples')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 定义不同的多项式阶数
degrees = [1, 2, 3, 4, 5]
# 创建一个新的图形
plt.figure(figsize=(10, 8))
# 对于每个多项式阶数,拟合并绘制曲线
for degree in degrees:
model = MultinomialModel(degree)
model.fit(X, Y)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
plt.plot(X_fit, Y_fit, label=f'Degree {degree}')
# 绘制实际的数据点
plt.scatter(X, Y, color='blue', label='Actual data')
# 设置图例和其他细节
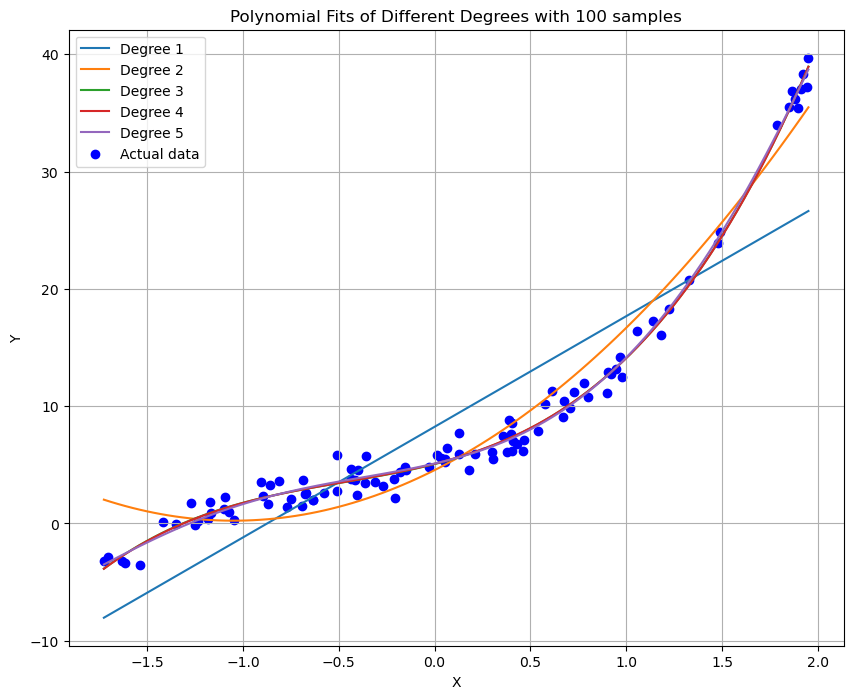
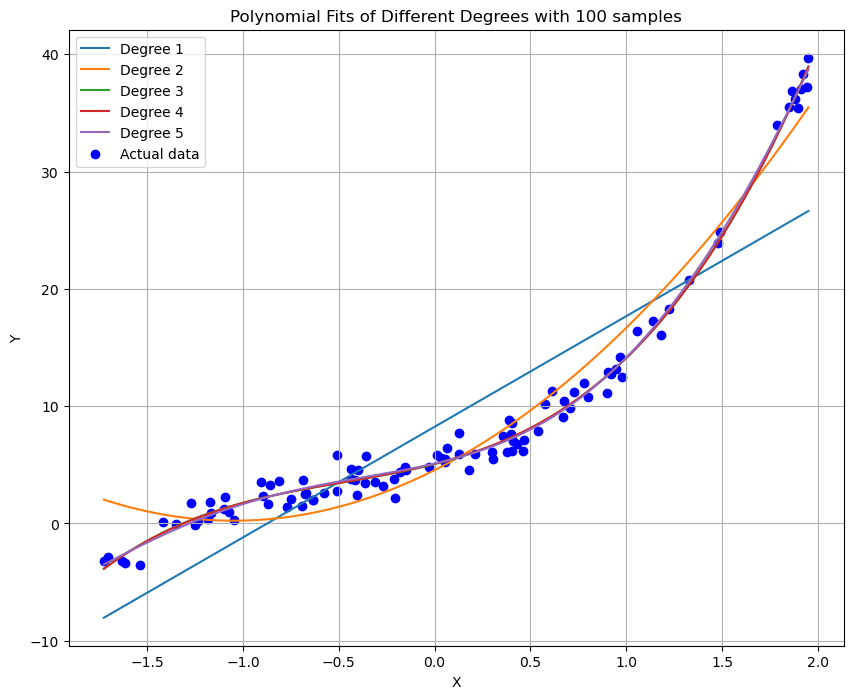
plt.title('Polynomial Fits of Different Degrees with 100 samples')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()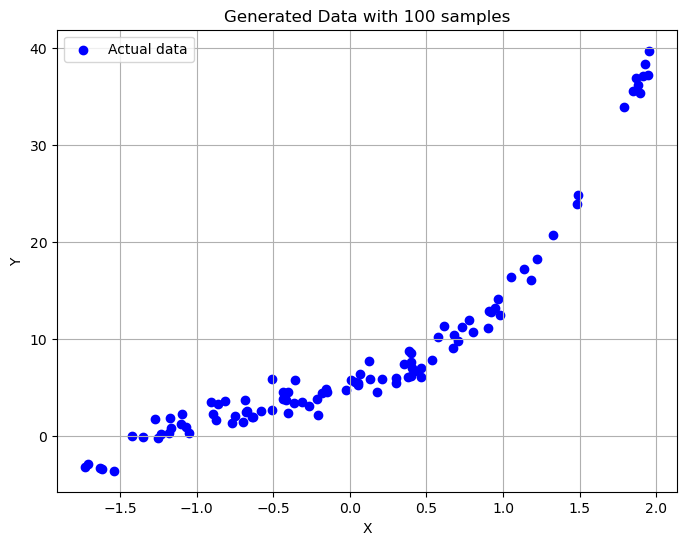
实验结果与讨论
结果展示
- 在初始阶段,我们观察到了不同阶数多项式模型对20个样本数据的拟合情况。随着多项式阶数的增加,模型逐渐从欠拟合状态转变为可能的过拟合状态,特别是在高阶数时,模型试图更紧密地跟随数据点的趋势。
- 当样本数量增加到100时,模型的表现变得更加稳定。高阶多项式模型虽然仍表现出一定的复杂度,但由于有更多的数据支持,过拟合的风险有所减小。模型能够更好地捕捉到数据的真实趋势。
讨论
- 模型复杂度与拟合效果:随着多项式阶数的提高,模型的复杂度增加,这使得模型能够更好地逼近训练数据。然而,过高阶数也可能导致过拟合,即模型在训练数据上表现优异但在未知数据上表现不佳。
- 样本数量的影响:增加样本数量有助于提高模型的泛化能力。更多的样本意味着模型可以学习到更多样化的特征,从而减少过拟合的风险。
结论
本次实验展示了如何使用梯度下降法实现多项式回归,并探讨了不同阶数及样本数量对模型拟合结果的影响。实验结果表明,在选择合适的多项式阶数以及确保有足够的训练样本的情况下,多项式回归模型可以有效地拟合非线性数据。
附录:完整代码
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以保证实验可重复性
np.random.seed(0)
# 生成20个训练样本
n_samples = 20
X = np.random.normal(0, 1, n_samples)
e_r = np.random.normal(0, 1, n_samples) # 误差项
# 计算Y值
Y = 5 + 4 * X + 3 * X**2 + 2 * X**3 + e_r
# 使用matplotlib显示生成的数据
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.title('Generated Data')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
class MultinomialModel:
def __init__(self, degree):
self.degree = degree
self.coefficients = None
def _design_matrix(self, X):
"""构造设计矩阵"""
n_samples = len(X)
design_matrix = np.ones((n_samples, self.degree + 1))
for i in range(1, self.degree + 1):
design_matrix[:, i] = X ** i
return design_matrix
def fit(self, X, Y, learning_rate=0.01, iterations=1000):
"""使用梯度下降法来拟合模型"""
n_samples = len(X)
self.coefficients = np.zeros(self.degree + 1) # 初始化系数
# 构造设计矩阵
X_design = self._design_matrix(X)
for _ in range(iterations):
# 预测
predictions = np.dot(X_design, self.coefficients)
# 损失函数的导数
gradient = 2 / n_samples * np.dot(X_design.T, predictions - Y)
# 更新系数
self.coefficients -= learning_rate * gradient
def predict(self, X):
"""基于学习到的模型预测新的数据点"""
X_design = self._design_matrix(X)
return np.dot(X_design, self.coefficients)
# 使用上述定义的类
degree = 3 # 设定多项式的阶数
model = MultinomialModel(degree)
# 拟合数据
model.fit(X, Y)
# 预测
Y_pred = model.predict(X)
# 可视化拟合结果
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.plot(X, Y_pred, color='red', label='Fitted curve')
plt.title('Polynomial Regression Fit')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 继续使用之前定义的MultinomialModel类
# 使用上述定义的类
degree = 3 # 设定多项式的阶数
model = MultinomialModel(degree)
# 拟合数据
model.fit(X, Y)
# 预测
Y_pred = model.predict(X)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
# 可视化拟合结果
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.plot(X_fit, Y_fit, color='red', label='Fitted curve', linewidth=2)
plt.title(f'Polynomial Regression Fit (Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 定义不同的多项式阶数
degrees = [1, 2, 3, 4, 5]
# 创建一个新的图形
plt.figure(figsize=(10, 8))
# 对于每个多项式阶数,拟合并绘制曲线
for degree in degrees:
model = MultinomialModel(degree)
model.fit(X, Y)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
plt.plot(X_fit, Y_fit, label=f'Degree {degree}')
# 绘制实际的数据点
plt.scatter(X, Y, color='blue', label='Actual data')
# 设置图例和其他细节
plt.title('Polynomial Fits of Different Degrees')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 生成100个训练样本
n_samples = 100
X = np.random.normal(0, 1, n_samples)
e_r = np.random.normal(0, 1, n_samples) # 误差项
# 计算Y值
Y = 5 + 4 * X + 3 * X**2 + 2 * X**3 + e_r
# 使用matplotlib显示生成的数据
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.title('Generated Data with 100 samples')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 定义不同的多项式阶数
degrees = [1, 2, 3, 4, 5]
# 创建一个新的图形
plt.figure(figsize=(10, 8))
# 对于每个多项式阶数,拟合并绘制曲线
for degree in degrees:
model = MultinomialModel(degree)
model.fit(X, Y)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
plt.plot(X_fit, Y_fit, label=f'Degree {degree}')
# 绘制实际的数据点
plt.scatter(X, Y, color='blue', label='Actual data')
# 设置图例和其他细节
plt.title('Polynomial Fits of Different Degrees with 100 samples')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()实验中使用的代码主要包括以下几个部分:
- 数据生成:使用numpy库生成服从特定分布的训练样本。
- 模型定义与实现:定义
MultinomialModel类,并实现梯度下降法训练模型的功能。 - 结果可视化:使用matplotlib库绘制数据点和拟合曲线。
- 分析样本数量的影响:增加样本数量,并观察拟合结果的变化。

