正则表达式regex
元字符
| 字符 | 描述 | 字符 | 描述 |
|---|---|---|---|
| \ | 转义符 | ||
| \d | digit匹配数字=[0-9] | \D | 非数字 |
| \w | word匹配字母、数字、下划线。等价于'[A-Za-z0-9_]' | \W | 非字母数字下划线 |
| \s | 空格,换行符,制表符 | \S | 非空白 |
| \t | table专门表示制表符 | ||
| \n | 专门表示换行符 | ||
| . | 除了换行符之外的任意内容 | ||
| [] | 字符组 | [^] | 非字符组 |
| ^ | 以……开头 | $ | 以……结尾 |
| | | 或(逻辑单位) | abc|ab | 如果两个规则有重叠,长在前,短在后 |
| () | 分组:把一部分正则规定为一组 | 限定|的作用域 | 限定一组正则的量词约束 |
量词:约束字符出现的次数
| 量词 | 描述 |
|---|---|
| {n} | 前面字符只出现n次数 |
| {n,} | 至少出现n次 |
| {n,m} | 至少出现n次,至多出现m次 |
| ? | 匹配0次或1次 ?前面的字符出现0次或1次都行 |
| + | 匹配1次或多次 |
| * | 匹配0次或多次 |
| \d(.\d+)? | 小数或整数 |
如图:
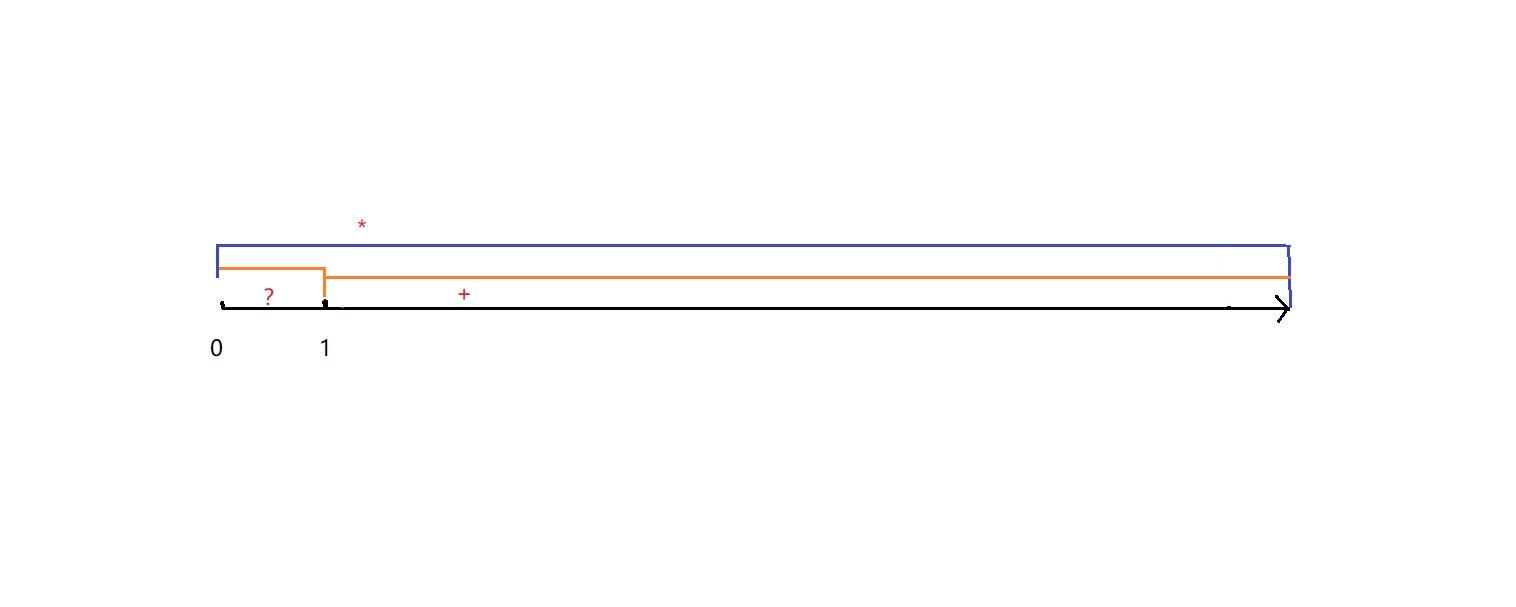
默认贪婪匹配,总是在符合量词条件的范围内尽可能多的匹配。【回溯算法:找到结尾,再回找要求的条件】
非贪婪匹配(惰性匹配):总是匹配符合条件范围内尽量小的
在量词后加? +?尽量少的取, +?3 一旦遇到3则匹配结束 元字符 量词 ?x 表示按照元字符规则在量词的范围内匹配,一旦遇到x就停止 #重点 .*?x 匹配任意内容的任意多次,一旦遇到x则停止 先判断是否是x,如果是就结束,如果不是,则继续
分组
分组命名 语法:(?P<组名>正则表达式) 引用分组 语法:(?P=组名)
引用分组,表示这个组中的内容与之前匹配的内容完全一致 \1,匹配第一个分组中的内容,使用时需要在字符串前加r转义
?的作用
1.量词: ?,匹配0次或1次 2.非贪婪匹配,?放在量词后 元字符量词?————>在量词范围内,尽量少的取 .*?x 匹配任意内容的任意多次,一旦遇到x则停止 3.分组 分组命名:(?P<组名>) 引用分组:(?P=组名) 取消分组优先:(?:正则表达式)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号