

MySql数据库去重
2020-02-20 15:04 默默不语 阅读(1405) 评论(0) 编辑 收藏 举报shoes表结构

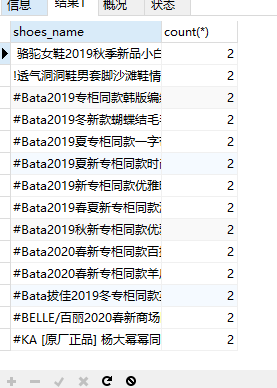
在此表中,shoes_name可能有重复,本篇博客记录如何去除重复数据。
1.首先要知道哪些数据是重复的, 可用group by 聚集函数找到:
SELECT shoes_name,count(*) from shoes GROUP BY shoes_name having COUNT(*)>1
注:having 一般和group连用,用来限制查到的结果,这里的意思是将shoes表按shoes_name组,count(*)计算每组的条数,hiving限制显示条数大于1的结果,即有重复的数据。
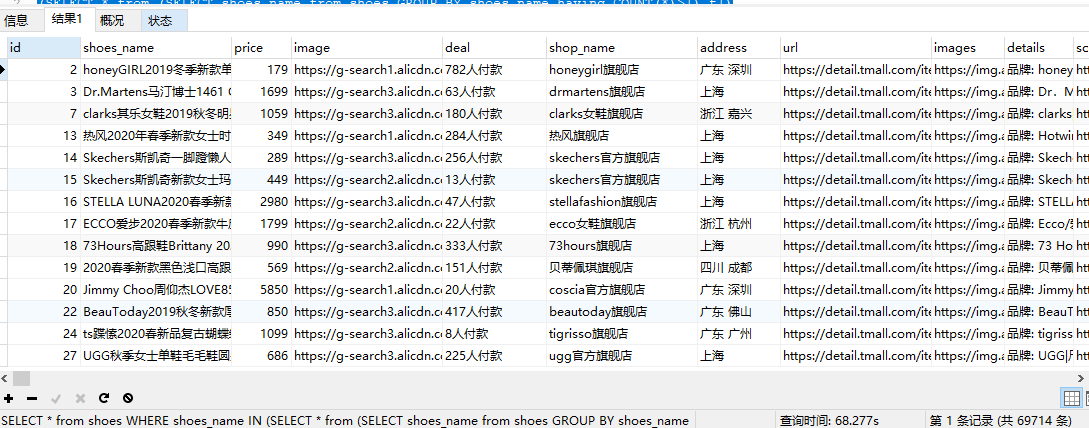
2.根据第一步中获得的shoes_name来获得所有重复的数据
SELECT * from shoes WHERE shoes_name IN( SELECT * from ( SELECT shoes_name from shoes GROUP BY shoes_name having COUNT(*)>1) t1 )
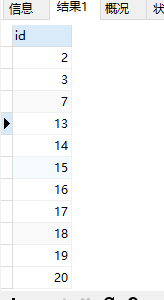
3.因为删除时我们要保留id最小的数据行,所以我们要查找最小的id。
SELECT id from shoes WHERE id in ( SELECT * from ( select MIN(id) from shoes GROUP BY shoes_name having COUNT(*)>1 )t2 )
4.删除这些重复数据,只保留最小的table_id

DELETE from shoes where shoes_name IN( SELECT * from( SELECT shoes_name FROM shoes GROUP BY shoes_name having COUNT(*)>1 )t1 ) AND id not IN( SELECT * from ( select MIN(id) from shoes GROUP BY shoes_name having COUNT(*)>1 )t2 )


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
2018-02-20 个人冲刺11