

基于物品的协同过滤算法ItemCF算法实现
2020-02-18 23:00 默默不语 阅读(2424) 评论(4) 编辑 收藏 举报基于物品的协同过滤算法(ItemCF)的基本思想是:给用户推荐那些和他们之前喜欢的物品相似的物品。 比如,该算法会因为你购买过《Java从入门到精通》而给你推荐《Java并发编程实战》。不过,基于物品的协同过滤算法并不利用物品的内容属性计算物品之间的相似度,二是通过分析用户的行为数据计算物品之间的相似度。该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。
实现代码:

# -*- coding=utf-8 -*- from operator import itemgetter from texttable import Texttable from collections import defaultdict import math #读取文件 def readFile(fileData): data=[] rates=[] f=open(fileData,"r") data=f.readlines() f.close() for line in data: dataLine=line.split("\t") rates.append([int(dataLine[0]),int(dataLine[1]),int(dataLine[2])]) return rates #创建字典,生成用户评分的数据结构 # 输入:数据集合,格式:用户id\t硬盘id\t用户评分 # 输出:1.用户字典:dic[用户id]=[(电影id,电影评分)...] # 2.电影字典:dic[电影id]=[用户id1,用户id2...] def createDict(rates): user_dict={} movie_dict={} for i in rates: if i[0] in user_dict: user_dict[i[0]].append((i[1],i[2])) else: user_dict[i[0]]=[(i[1],i[2])] if i[1] in movie_dict: movie_dict[i[1]].append(i[0]) else: movie_dict[i[1]]=[i[0]] return user_dict,movie_dict #建立物品倒排表,计算物品相似度 def itemCF(user_dict): N=dict() C=defaultdict(defaultdict) W=defaultdict(defaultdict) for key in user_dict: for i in user_dict[key]: if i[0] not in N.keys(): #i[0]表示movie_id N[i[0]]=0 N[i[0]]+=1 #N[i[0]]表示评论过某电影的用户数 for j in user_dict[key]: if i==j: continue if j not in C[i[0]].keys(): C[i[0]][j[0]]=0 C[i[0]][j[0]]+=1 #C[i[0]][j[0]]表示电影两两之间的相似度,eg:同时评论过电影1和电影2的用户数 for i,related_item in C.items(): for j,cij in related_item.items(): W[i][j]=cij/math.sqrt(N[i]*N[j]) return W #结合用户喜好对物品排序 def recommondation(user_id,user_dict,K): rank=defaultdict(int) l=list() W=itemCF(user_dict) for i,score in user_dict[user_id]: #i为特定用户的电影id,score为其相应评分 for j,wj in sorted(W[i].items(),key=itemgetter(1),reverse=True)[0:K]: #sorted()的返回值为list,list的元素为元组 if j in user_dict[user_id]: continue rank[j]+=score*wj #先找出用户评论过的电影集合,对每一部电影id,假设其中一部电影id1,找出与该电影最相似的K部电影,计算出在id1下用户对每部电影的兴趣度,接着迭代整个用户评论过的电影集合,求加权和,再排序,可推荐出前n部电影,我这里取10部。 l=sorted(rank.items(),key=itemgetter(1),reverse=True)[0:10] return l #获取电影列表 def getMovieList(item): items={} f=open(item,"r",encoding = 'ISO-8859-1') movie_content=f.readlines() f.close() for movie in movie_content: movieLine=movie.split("|") items[int(movieLine[0])]=movieLine[1:] # print(items) return items #主程序 if __name__=='__main__': itemTemp=getMovieList("D:/movieRecommend/ml-100k/u.item") #获取电影列表 fileTemp=readFile("D:/movieRecommend/ml-100k/u.data") #读取文件 user_dic,movie_dic=createDict(fileTemp) #创建字典 user_id=66 movieTemp=recommondation(user_id,user_dic,80) #对电影排序 rows=[] table=Texttable() #创建表格并显示 table.set_deco(Texttable.HEADER) table.set_cols_dtype(['t','f','a']) table.set_cols_align(["l","l","l"]) rows.append(["user name","recommondation_movie","from userid"]) for i in movieTemp: rows.append([user_id,itemTemp[i[0]][0],""]) table.add_rows(rows) print("推荐结果如下:") print(table.draw())
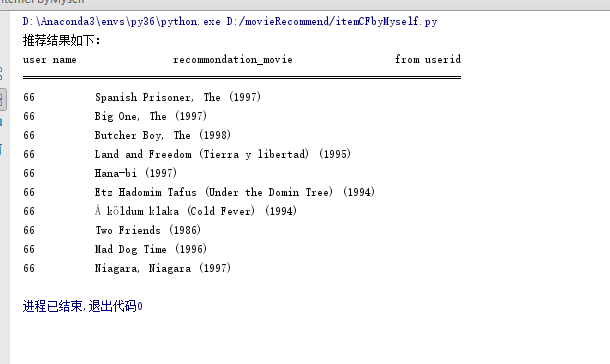
运行结果:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
2018-02-18 个人冲刺09