

jieba 分词库(python)
2020-02-02 18:11 默默不语 阅读(2255) 评论(0) 编辑 收藏 举报安装jieba:pip install jieba
原理:
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
分词:
jieba支持三种分词模式:
精确模式:试图将句子最精确地切开,适合文本分析
全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
示例:

#!/usr/bin/python # -*- coding: UTF-8 -*- import jieba strt = "我爱北京天安门!" # 全模式 sl = jieba.cut(strt, cut_all=True) print("全模式:", ",".join(sl)) # 精确模式,默认为精确模式,所以可以不指定cut_all=False sl = jieba.cut(strt, cut_all=False) print("精确模式:", ",".join(sl)) # 搜索引擎模式 sl = jieba.cut_for_search(strt) print("搜索引擎模式:", ",".join(sl))

关键词抽取算法主要有以下两种:
有监督学习算法:将关键词抽取过程视为二分类问题,先抽出候选词,然后对于每个候选词划定标签,其要么是关键词,要么不是关键词。然后训练关键词抽取分类器,当对一段新的文本进行抽取关键词时,先抽取出所有的候选词,然后利用训练好的关键词抽取分类器,对各个候选词进行分类,最终将标签为关键词的候选词作为关键词。
无监督学习算法:先抽取出候选词,然后对各个候选词进行打分,然后输出topN个分值最高的候选词作为关键词。根据打分的策略不同,有不同的算法,例如TF-IDF,TextRank等算法。
jieba分词实现了基于TF-IDF关键词抽取算法和基于TextRank关键词抽取算法,两类算法均是无监督学习的算法。以下对这两种算法进行介绍:
1.基于TF-IDF算法进行关键词提取
如果某个词在一篇文档中出现的频率高,也即TF(词频)高;并且在语料库中其他文档中很少出现,即DF的低,也即IDF高,则认为这个词具有很好的类别区分能力。TF-IDF算法中,将TF与IDF相乘。
代码示例:
#!/usr/bin/python # -*- coding: UTF-8 -*- import jieba import jieba.analyse # jieba.analyse.extract_tags(sentence,topK) 有两个参数,第一个为要提取的文本,第二个为要获取的按TF-IDF排序的词的个数 sentence = "有监督学习算法将关键词抽取过程视为二分类问题,先抽出候选词,然后对于每个候选词划定标签,其要么是关键词,要么不是关键词。然后训练关键词抽取分类器," \ "当对一段新的文本进行抽取关键词时,先抽取出所有的候选词,然后利用训练好的关键词抽取分类器,对各个候选词进行分类,最终将标签为关键词的候选词作为关键词。" topK = 5 result=jieba.analyse.extract_tags(sentence,topK) print(result)
运行结果:
2.基于TextRank算法进行关键词提取
代码示例:
#!/usr/bin/python # -*- coding: UTF-8 -*- import jieba from jieba import analyse textrank = analyse.textrank sentence = "有监督学习算法将关键词抽取过程视为二分类问题,先抽出候选词,然后对于每个候选词划定标签,其要么是关键词,要么不是关键词。然后训练关键词抽取分类器," \ "当对一段新的文本进行抽取关键词时,先抽取出所有的候选词,然后利用训练好的关键词抽取分类器,对各个候选词进行分类,最终将标签为关键词的候选词作为关键词。" # sentence为要提取的文本,topK为要获取的关键词的个数,withWeight为是否显示权重,allowPOS为要提取关键词的词性 result=textrank(sentence, topK=5, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v')) print(result)
运行结果:

jieba动态添加自定义词
#!/usr/bin/python # -*- coding: UTF-8 -*- import jieba content = "韩国东大门单鞋女方头绒面一脚蹬韩版休闲2020春季新款平底毛毛鞋" result = jieba.cut(content) print("自定义前:",",".join(result)) jieba.add_word("东大门") jieba.add_word("一脚蹬") jieba.add_word("毛毛鞋") result = jieba.cut(content) print("自定义后:",",".join(result))
运行结果:

jieba自定义词库
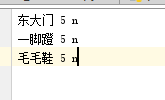
jieba支持自定义词库,需要使用时把自定义的词库load进来后jieba就会同时使用 jieba初始化时加载的词库 和 自定义词库,词典格式和dict.txt一样,一个词占一行,每一行分三部分,第一部分为词语,第二部分为词频,最后为词性(可省略),并用空格隔开。
用法:jieba.load_userdict(file_name) #file_name为自定义词典的路径
自定义词库:
工程目录:
代码示例:
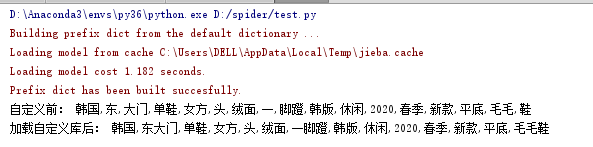
#!/usr/bin/python # -*- coding: UTF-8 -*- import jieba content = "韩国东大门单鞋女方头绒面一脚蹬韩版休闲2020春季新款平底毛毛鞋" result = jieba.cut(content) print("自定义前:",",".join(result)) jieba.load_userdict("./shoes") result = jieba.cut(content) print("加载自定义库后:",",".join(result))
运行结果:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
2018-02-02 个人冲刺01