python re 模块 正则表达式
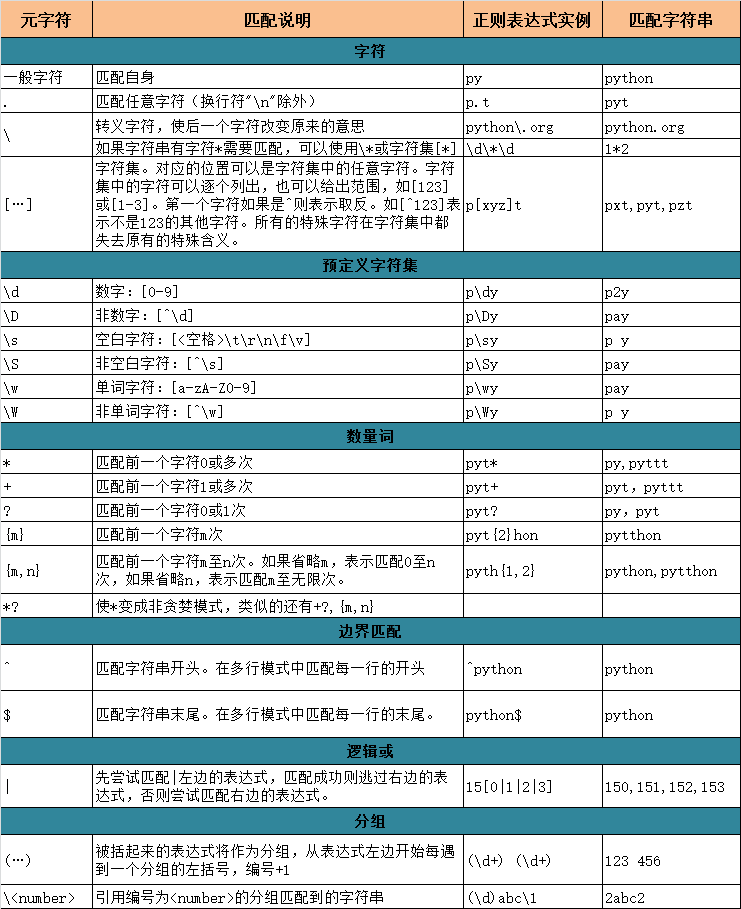
元字符:
原生字符串 r"\\" 在re中匹配一个\
re.findall(r"\\","atest\p") #得到一个\
re.findall("\\\\p","atest\p") # 匹配到\p
他需要先想python解释器传递两个斜杠\,然后re在用两个斜杠\,去匹配一个斜杠\。
import re str1 = 'output_1970.01.20.txt' ret = re.findall('\D{2}$',str1) print (ret) # ['xt'] # \D{4}$ 匹配字符串最后2位非数字的字符 ret2 = re.findall('\d{2}',str1) print (ret2) # ['19', '70', '01', '20'] # 获取连续的两个数字 # findall是把所有匹配的结果都放在列表中返回
import re str1 = 'output1970\.01\.20\.txt' ret = re.findall('\d{4}\\\\.',str1) print (ret) # ['1970\\.'] # 1、在python解释器中我们需要用\\表示一个\,因为我们需要一个\来转义一个\。 # 2、在re模块内部同样需要用\\表示一个\。所以最后表现出来是我们需要4个\来向re传2个\\.
re.findall()
把所有匹配到的结果放在列表中返回
re.search()
返回一个对象,这个对象可以使用group方法获取返回的值。他只返回第一次匹配到的结果
代码示例:
import re str1 = 'output_1970.01.20.txt' ret = re.search('(?P<year>\d{4}).(?P<month>\d{2}).(?P<day>\d{2})',str1) print (ret.group()) print (ret.group('year')) print (ret.group('month')) print (ret.group('day')) # (?P<name>...) 为group命名,所以在print year时可以获取指定的年
# 如果search没有找到匹配的内容,在ret.group()时会得到一个None。
re.match()
返回一个对象,只在字符串开始匹配。也返回第一次匹配到的结果。
re.split()
分割字符串。
re.split('[j,s]','smljal'),先用j去分割,在用s去分割。
re.sub()
与str的replace类似。
re.sub(r't\b','tet','test,python') # 把逗号前的t替换成tet。testet,python
re.compile()
将正则表达式编译成对象,再多地调用这个匹配规则
com = re.compile('\.com')
ret1 = com.findall('www.baidu.com')
ret2 = com.search('u.com.net.com').group()
print (ret1,ret2)
python 标准库 https://docs.python.org/3/library/re.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号