从零搭建hadoop集群之hadoop集群安装
1.集群规划
| HDSF | YARN | |
| hadoop01 | NanemNode(主机点),DataNode | NodeManager |
| hadoop02 | DataNode, SecondaryNamenode | NodeManager |
| hadoop03 | DataNode | NodeManager, ResourceManager(主节点) |
2. 再hadoop01的/home/hadoop目录下创建module 文件
3.下载2.7.6安装包 https://archive.apache.org/dist/hadoop/common/
4.上传hadoop安装包
通过xftp传送给到hadoop01机器的/home/hadoop/software目录下
[hadoop@hadoop01 software]$ tar -zxvf hadoop-2.7.6.tar.gz -C ../module/
5. 修改配置文件
cd /home/hadoop/module/hadoop-2.7.6/etc/hadoop
修改 hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_73
修改 core-site.xml
<configuration> <!-- 指定 hdfs 的 nameservice 为 myha01 --> <property> <name>fs.defaultFS</name> <value>hdfs://myha01/</value> </property> <!-- 指定 hadoop 工作目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/data/hadoopdata/</value> </property> <!-- 指定 zookeeper 集群访问地址 --> <property> <name>ha.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> </configuration>
修改 hdfs-site.xml
<configuration> <!-- 指定副本数 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!--指定 hdfs 的 nameservice 为 myha01,需要和 core-site.xml 中保持一致--> <property> <name>dfs.nameservices</name> <value>myha01</value> </property> <!-- myha01 下面有两个 NameNode,分别是 nn1,nn2 --> <property> <name>dfs.ha.namenodes.myha01</name> <value>nn1,nn2</value> </property> <!-- nn1 的 RPC 通信地址 --> <property> <name>dfs.namenode.rpc-address.myha01.nn1</name> <value>hadoop01:9000</value> </property> <!-- nn1 的 http 通信地址 --> <property> <name>dfs.namenode.http-address.myha01.nn1</name> <value>hadoop01:50070</value> </property> <!-- nn2 的 RPC 通信地址 --> <property> <name>dfs.namenode.rpc-address.myha01.nn2</name> <value>hadoop02:9000</value> </property> <!-- nn2 的 http 通信地址 --> <property> <name>dfs.namenode.http-address.myha01.nn2</name> <value>hadoop02:50070</value> </property> <!-- 指定 NameNode 的 edits 元数据在 JournalNode 上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/myha01</value> </property> <!-- 指定 JournalNode 在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/data/journaldata</value> </property> <!-- 开启 NameNode 失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <!-- 此处配置在安装的时候切记检查不要换行--> <property> <name>dfs.client.failover.proxy.provider.myha01</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用 sshfence 隔离机制时需要 ssh 免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!-- 配置 sshfence 隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>
修改 mapred-site.xml
<configuration> <!-- 指定 mr 框架为 yarn 方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 设置 mapreduce 的历史服务器地址和端口号 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop01:10020</value> </property> <!-- mapreduce 历史服务器的 web 访问地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop01:19888</value> </property> </configuration>
修改 yarn-site.xml
<configuration> <!-- 开启 RM 高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定 RM 的 cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <!-- 指定 RM 的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定 RM 的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop04</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop05</value> </property> <!-- 指定 zk 集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop02:2181,hadoop03:2181,hadoop04:2181</value> </property> <!-- 要运行 MapReduce 程序必须配置的附属服务 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 开启 YARN 集群的日志聚合功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- YARN 集群的聚合日志最长保留时长 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>86400</value> </property> <!-- 启用自动恢复 --> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!-- 制定 resourcemanager 的状态信息存储在 zookeeper 集群上--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration>
修改 slaves
添加 datanode 的节点地址:
hadoop01
hadoop02
hadoop03
6. 分发安装包到其他机器
scp -r hadoop-2.7.6 hadoop@hadoop02:$PWD
scp -r hadoop-2.7.6 hadoop@hadoop03:$PWD
7、 并分别配置环境变量
vim ~/.bashrc
添加两行:
export HADOOP_HOME=/home/hadoop/module/hadoop-2.7.6 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
8. 集群初始化操作(记住:严格按照以下步骤执行)
先启动 zookeeper 集群
启动:zkServer.sh start
检查启动是否正常:zkServer.sh status
分别在每个 zookeeper(也就是规划的三个 journalnode 节点,不一定跟 zookeeper 节点一样)节点上启动 journalnode 进程
hadoop-daemon.sh start journalnode
然后用 jps 命令查看是否各个 datanode 节点上都启动了 journalnode 进程 如果报错,根据错误提示改进
在第一个 namenode 上执行格式化操作
hadoop namenode -format
然后会在 core-site.xml 中配置的临时目录中生成一些集群的信息 把他拷贝的第二个 namenode 的相同目录下
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata/</value>
这个目录下
[hadoop@hadoop01 ~]$ scp -r ~/data/hadoopdata/ hadoop02:~/data
或者也可以在另一个 namenode 上执行:hadoop namenode -bootstrapStandby

格式化 ZKFC
hdfs zkfc -formatZK
在第一台机器上即可
启动 HDFS
start-dfs.sh
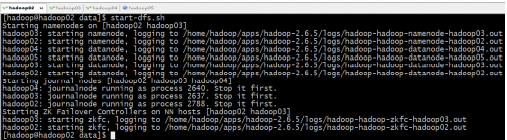
查看各节点进程是否启动正常:jps
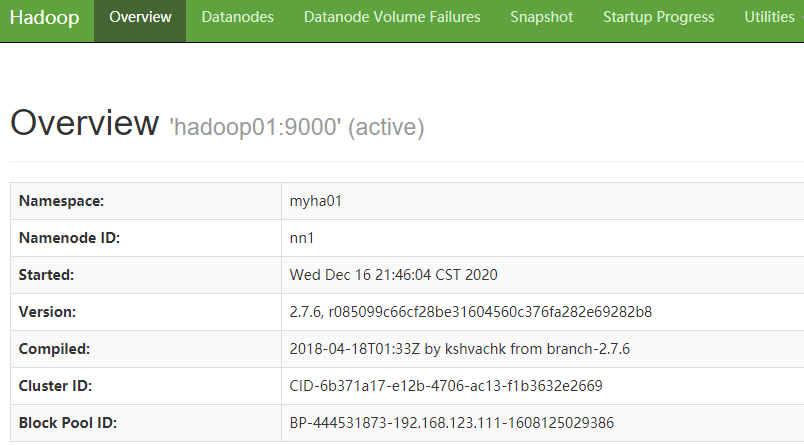
访问 web 页面 http://hadoop01:50070
启动 YARN
start-yarn.sh
在主备 resourcemanager 中随便选择一台进行启动,正常启动之后,检查各节点的进程:jps
若备用节点的 resourcemanager 没有启动起来,则手动启动起来
yarn-daemon.sh start resourcemanager
之后打开浏览器访问页面:http://hadoop03:8088
查看各主节点的状态
HDFS: hdfs haadmin -getServiceState nn1 hdfs haadmin -getServiceState nn2
YARN:
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
启动 mapreduce 任务历史服务器
mr-jobhistory-daemon.sh start historyserver
按照配置文件配置的历史服务器的 web 访问地址去访问: http://hadoop01:1988