
Flink的安装部署
一. Flink的下载
安装包下载地址:http://flink.apache.org/downloads.html ,选择对应Hadoop的Flink版本下载

Flink 有三种部署模式,分别是 Local、Standalone Cluster 和 Yarn Cluster。
二. Local模式
对于 Local 模式来说,JobManager 和 TaskManager 会公用一个 JVM 来完成 Workload。如果要验证一个简单的应用,Local 模式是最方便的。实际应用中大多使用 Standalone 或者 Yarn Cluster,而local模式只是将安装包解压启动(./bin/start-local.sh)即可,在这里不在演示。
三. Standalone HA模式
Standalone模式顾名思义,是在本地集群上调度执行,不依赖于外部调度机制例如YARN, 一般需要配置为HA,防止Jobmanager突然挂掉,导致整个集群或者任务执行失败的情况发生。下面介绍一下Standalone HA模式的搭建安装
当Flink程序运行时,如果jobmanager崩溃,那么整个程序都会失败。为了防止jobmanager的单点故障,借助于zookeeper的协调机制,可以实现jobmanager的HA配置—-1主(leader)多从(standby)。这里的HA配置只涉及standalone模式,yarn模式暂不考虑。
本例中规划Jobmanager:hadoop01,hadoop02(一个active,一个standby);Taskmanager:hadoop02,hadoop03;zookeeper集群
1. 集群部署规划
| 节点名称 | master | worker | zookeeper |
| hadoop01 | master | worker | zookeeper |
| hadoop02 | master | worker | zookeeper |
| hadoop03 | woker | zookeeper |
2. 解压
[hadoop@hadoop01 apps]$ tar -zxvf flink-1.7.2-bin-scala_2.11.tgz -C ./
[hadoop@hadoop01 apps]$ ls
azkaban flink-1.7.2 flink-1.7.2-bin-scala_2.11.tgz flume-1.8.0 hadoop-2.7.4 jq kafka_2.11-0.11 zkdata zookeeper-3.4.10 zookeeper.out
3. 修改配置文件
配置masters文件
该文件用于指定主节点及其web访问端口,表示集群的Jobmanager,vi masters,添加master:8081
[hadoop@hadoop01 conf]$ vim masters
hadoop01:8081
hadoop02:8081
配置slaves文件,该文件用于指定从节点,表示集群的taskManager。添加以下内容
[hadoop@hadoop01 conf]$ vim slaves
hadoop01
hadoop02
hadoop03
配置文件flink-conf.yaml

#jobmanager.rpc.address: hadoop01 high-availability:zookeeper #指定高可用模式(必须) high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181 #ZooKeeper仲裁是ZooKeeper服务器的复制组,它提供分布式协调服务(必须) high-availability.storageDir:hdfs://192.168.123.111:9000/flink-metadata/recovery/ #JobManager元数据保存在文件系统storageDir中,只有指向此状态的指针存储在ZooKeeper中(必须) high-availability.zookeeper.path.root:/flink #根ZooKeeper节点,在该节点下放置所有集群节点(推荐) high-availability.cluster-id:/flinkCluster #自定义集群(推荐)
#检查点生成的分布式快照的保存地点,默认是jobmanager的memory,但是HA模式必须配置在hdfs上,且保存路径需要在hdfs上创建并指定路径
state.backend: filesystem state.checkpoints.dir: hdfs://192.168.123.111:9000/flink-metadata/checkpoints state.savepoints.dir: hdfs:///flink/checkpoints
4. 拷贝安装包到各节点
[hadoop@hadoop01 apps]$ scp -r flink-1.7.2/ hadoop@hadoop02:`pwd`
[hadoop@hadoop01 apps]$ scp -r flink-1.7.2/ hadoop@hadoop03:`pwd`
5. 配置环境变量
配置所有节点Flink的环境变量
[hadoop@hadoop01 ~]$ vim .bashrc
export FLINK_HOME=/home/hadoop/apps/flink-1.7.2
export PATH=$PATH:$FLINK_HOME/bin
[hadoop@hadoop01 ~]$ source .bashrc
6. 启动flink
[hadoop@hadoop01 bin]$ pwd
/home/hadoop/apps/flink-1.7.2/bin
[hadoop@hadoop01 bin]$ ls
config.sh flink-daemon.sh mesos-appmaster.sh pyflink-stream.sh start-cluster.sh stop-zookeeper-quorum.sh
flink historyserver.sh mesos-taskmanager.sh sql-client.sh start-scala-shell.sh taskmanager.sh
flink.bat jobmanager.sh pyflink.bat standalone-job.sh start-zookeeper-quorum.sh yarn-session.sh
flink-console.sh mesos-appmaster-job.sh pyflink.sh start-cluster.bat stop-cluster.sh zookeeper.sh
[hadoop@hadoop01 bin]$ ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop01.
Starting taskexecutor daemon on host hadoop02.
Starting taskexecutor daemon on host hadoop03.
jps查看进程



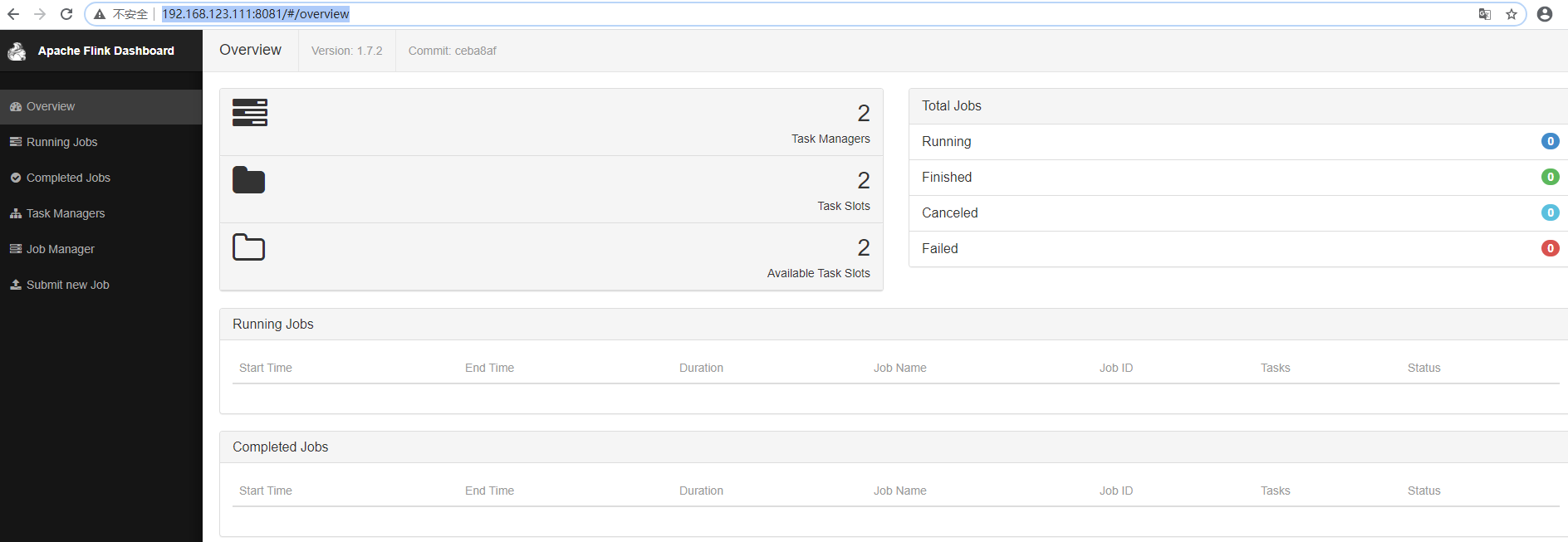
7. WebUI查看
http://192.168.123.111:8081


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~