

嵌入式linux cpu相关
UMA1(Uniform Memory Access, 一致性内存访问 ):总线模型保证了 CPU 的所有内存访问都是一致的,不必考虑不同内存地址之间的差异。
NUMA2(Non-Uniform Memory Access, 非一致性内存访问)
1.命令:numactl --hardware
root@OK8MP:/sys/devices/system/cpu# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3
node 0 size: 921 MB
node 0 free: 316 MB
node distances:
node 0
0: 10
root@OK8MP:/sys/devices/system/cpu# cat /proc/cpuinfo
processor : 0
BogoMIPS : 16.00
Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid
CPU implementer : 0x41
CPU architecture: 8
CPU variant : 0x0
CPU part : 0xd03
CPU revision : 4
processor : 1
BogoMIPS : 16.00
Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid
CPU implementer : 0x41
CPU architecture: 8
CPU variant : 0x0
CPU part : 0xd03
CPU revision : 4
processor : 2
BogoMIPS : 16.00
Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid
CPU implementer : 0x41
CPU architecture: 8
CPU variant : 0x0
CPU part : 0xd03
CPU revision : 4
processor : 3
BogoMIPS : 16.00
Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid
CPU implementer : 0x41
CPU architecture: 8
CPU variant : 0x0
CPU part : 0xd03
CPU revision : 4
root@OK8MP:/sys/devices/system/cpu# lscpu
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: ARM
Model: 4
Model name: Cortex-A53
Stepping: r0p4
CPU max MHz: 1600.0000
CPU min MHz: 1200.0000
BogoMIPS: 16.00
NUMA node0 CPU(s): 0-3
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Not affected
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid
root@OK8MP:/sys/devices/system/cpu/cpu2# cat online
1
root@OK8MP:/sys/devices/system/cpu/cpu2# echo 0 > /sys/devices/system/cpu/cpu2/online
[ 5215.836217] CPU2: shutdown
[ 5215.838932] psci: CPU2 killed (polled 0 ms)
root@OK8MP:/sys/devices/system/cpu/cpu2# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 3
node 0 size: 921 MB
node 0 free: 316 MB
node distances:
node 0
0: 10
root@OK8MP:/sys/devices/system/cpu/cpu2# echo 1 > /sys/devices/system/cpu/cpu2/online
[ 5304.404259] Detected VIPT I-cache on CPU2
[ 5304.404282] GICv3: CPU2: found redistributor 2 region 0:0x00000000388c0000
[ 5304.404320] CPU2: Booted secondary processor 0x0000000002 [0x410fd034]
root@OK8MP:/sys/devices/system/cpu/cpu2# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3
node 0 size: 921 MB
node 0 free: 316 MB
node distances:
node 0
0: 10
root@OK8MP:/sys/devices/system/cpu/cpu2#
root@OK8MP:/sys/devices/system/cpu/cpu2# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq
1600000
root@OK8MP:/sys/devices/system/cpu/cpu2# cat /sys/devices/system/cpu/cpu1/cpufreq/scaling_cur_freq
1600000
root@OK8MP:/sys/devices/system/cpu/cpu2# cat /sys/devices/system/cpu/cpu1/cpufreq/scaling_cur_freq
1600000
root@OK8MP:/sys/devices/system/cpu/cpu2# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq
1600000
root@OK8MP:/sys/devices/system/cpu/cpu2# cat /sys/devices/system/cpu/cpu2/cpufreq/scaling_cur_freq
1200000
root@OK8MP:/sys/devices/system/cpu/cpu2# cat /sys/devices/system/cpu/cpu3/cpufreq/scaling_cur_freq
1600000
root@OK8MP:/sys/devices/system/cpu/cpu2# cat /sys/devices/system/cpu/cpu2/cpufreq/scaling_cur_freq
1600000
root@OK8MP:/sys/devices/system/cpu/cpu2# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq
每个程序员都应该知道的 CPU 知识:NUMA - 知乎 (zhihu.com)
十年后数据库还是不敢拥抱NUMA? - 知乎 (zhihu.com)
讲解CPU之NUMA硬件体系以及机制(lscpu查看相关信息) - jinzi - 博客园 (cnblogs.com)
从基本理解到深入探究 Linux动态频率调节系统cpufreq
文章目录
- 概述
-
- 1. 管中窥豹——sysfs接口
- 2. 刨根问底——软件架构
-
- 1. cpufreq_policy
- 2. cpufreq_governor
- 3. cpufreq_driver
- 4. cpufreq notifiers
- 核心(core)架构与API
-
- 1. CPUFreq子系统的初始化
- 2. 注册cpufreq_governor
- 3. 注册一个cpufreq_driver驱动
- 4. 为每个cpu建立频率调整策略(policy)
- 5. 其它API
- governor
-
- 1. 数据结构
- 2. 定义一个governor
- 3. 初始化一个governor
- 4. 启动一个governor
- 5. 系统负载的检测
- 更多资料
-
- 5种Governors说明
- 详细介绍governor
-
- 1. Ondemand governor
- 2. Interactive governor
- IBM 开发者网站
- 内核代码网站
概述
随着人民日益增长的美好生活需要,人民对美好生活的向往,我们对芯片的处理能力提出了越来越高的需求,芯片厂家也对制造工艺不断地提升。现在的高端智能手机的中央处理器已经可以工作在2.8GHz以上,而主流的PC处理器的主频能达到5GHz左右,可是我们并不是想让CPU时时刻刻都工作在最高的主频上,尤其是移动设备和笔记本电脑,大部分时间里,CPU其实工作在轻负载状态下,由文章《集成电路的功率和能耗》我们知道:主频越高,功耗也越高。为了节省CPU的功耗和减少发热,我们有必要根据当前CPU的负载状态,动态地提供刚好足够的主频给CPU。在Linux中,内核的开发者定义了一套框架模型来完成这一目的,它就是CPUFreq系统。
1. 管中窥豹——sysfs接口
我们先从CPUFreq提供的sysfs接口入手,先在kernel 外面划来划去直观地看看它提供了那些功能再深入刨根问底源码。以下是我的adb shell 输出的结果(输出粗体是高通他家特有的,斜体是其他家特有的):
android:/sys/devices/system/cpu $ ls
core_ctl_isolated cpu4 cpuidle kernel_max power
cpu0 cpu5 hang_detect_gold modalias present
cpu1 cpu6 hang_detect_silver offline uevent
cpu2 cpu7 hotplug online
cpu3 cpufreq isolated possible probeandroid:/sys/devices/system/cpu $ ls -l
-r–r--r-- 1 root root 4096 1970-01-01 00:06 core_ctl_isolated
drwxr-xr-x 9 root root 0 1970-01-01 00:00 cpu0
drwxr-xr-x 8 root root 0 1970-01-01 00:00 cpu1
drwxr-xr-x 8 root root 0 1970-01-01 00:00 cpu2
drwxr-xr-x 8 root root 0 1970-01-01 00:00 cpu3
drwxr-xr-x 8 root root 0 1970-01-01 00:00 cpu4
drwxr-xr-x 8 root root 0 1970-01-01 00:00 cpu5
drwxr-xr-x 8 root root 0 1970-01-01 00:00 cpu6
drwxr-xr-x 8 root root 0 1970-01-01 00:00 cpu7
drwxr-xr-x 4 root root 0 1970-01-01 00:00 cpufreq
drwxr-xr-x 2 root root 0 1970-01-01 00:00 cpuidle
drwxr-xr-x 2 root root 0 1970-01-01 00:00 hang_detect_gold
drwxr-xr-x 2 root root 0 1970-01-01 00:00 hang_detect_silver
drwxr-xr-x 2 root root 0 1970-01-01 00:00 hotplug
-r–r--r-- 1 root root 4096 1970-01-01 00:06 isolated
-r–r--r-- 1 root root 4096 1970-01-01 00:06 kernel_max
-r–r--r-- 1 root root 4096 1970-01-01 00:06 modalias
-r–r--r-- 1 root root 4096 1970-01-01 00:06 offline
-r–r--r-- 1 root root 4096 1970-01-01 00:00 online
-r–r--r-- 1 root root 4096 1970-01-01 00:06 possible
drwxr-xr-x 2 root root 0 1970-01-01 00:00 power
-r–r--r-- 1 root root 4096 1970-01-01 00:06 present
-rw-r–r-- 1 root root 4096 1970-01-01 00:00 uevent
所有与CPUFreq相关的sysfs接口都位于:/sys/devices/system/cpu下面,我们可以看到,8个cpu分别建立了一个自己的目录,从cpu0到cpu7,我们再看看offline和online以及present的内容:
- online 代表目前正在工作的cpu,输出显示编号为0-7这8个cpu在工作,
- offline 代表目前被关掉的cpu,
- present 表示主板上已经安装的cpu,
android:/sys/devices/system/cpu $ cat online
0-7
android:/sys/devices/system/cpu $ cat offline
android:/sys/devices/system/cpu $ cat present
0-7
android:/sys/devices/system/cpu $ cat kernel_max
7
如果使用了类似intel的超线程技术,我们能看到输出kernel_max是15(即16个CPU,其下标0开始),第8-15号cpu处于关闭状态(实际上不存在,因为present只有0-7),其实物理上只是8个。
接着往下看:
android:/sys/devices/system/cpu/cpu0 $ ls
cache cpuidle isolate online regs sched_load_boost topology
cpufreq hotplug of_node power rq-stats subsystem uevent
crash_notes node0 microcode thermal_throttleandroid:/sys/devices/system/cpu/cpu0 $ ls -l
drwxr-xr-x 6 root root 0 1970-01-01 00:00 cache
lrwxrwxrwx 1 root root 0 1970-01-01 00:00 cpufreq -> …/cpufreq/policy0
drwxr-xr-x 5 root root 0 1970-01-01 00:00 cpuidle
drwxr-xr-x 2 root root 0 1970-01-01 00:00 hotplug
-r–r--r-- 1 root root 4096 1970-01-01 00:00 isolate
lrwxrwxrwx 1 root root 0 1970-01-01 00:35 of_node -> …/…/…/…/firmware/devicetree/base/cpus/cpu@0
-rw-r–r-- 1 root root 4096 1970-01-01 00:00 online
drwxr-xr-x 2 root root 0 1970-01-01 00:00 power
drwxr-xr-x 3 root root 0 1970-01-01 00:00 regs
drwxr-xr-x 2 root root 0 1970-01-01 00:00 rq-stats
-rw-r–r-- 1 root root 4096 1970-01-01 00:00 sched_load_boost
lrwxrwxrwx 1 root root 0 1970-01-01 00:35 subsystem -> …/…/…/…/bus/cpu
drwxr-xr-x 2 root root 0 1970-01-01 00:00 topology
-rw-r–r-- 1 root root 4096 1970-01-01 00:00 uevent
android:/sys/devices/system/cpu/cpu0/cpufreq $ ls
affected_cpus related_cpus scaling_governor
cpuinfo_cur_freq scaling_available_frequencies scaling_max_freq
cpuinfo_max_freq scaling_available_governors scaling_min_freq
cpuinfo_min_freq scaling_cur_freq scaling_setspeed
cpuinfo_transition_latency scaling_driver bios_limit statsandroid:/sys/devices/system/cpu/cpu0/cpufreq $ ls -l
-r–r--r-- 1 root root 4096 1970-01-01 00:35 affected_cpus
-r-------- 1 root root 4096 1970-01-01 00:35 cpuinfo_cur_freq
-r–r--r-- 1 root root 4096 1970-01-01 00:00 cpuinfo_max_freq
-r–r--r-- 1 root root 4096 1970-01-01 00:35 cpuinfo_min_freq
-r–r--r-- 1 root root 4096 1970-01-01 00:35 cpuinfo_transition_latency
-r–r--r-- 1 root root 4096 1970-01-01 00:35 related_cpus
-r–r--r-- 1 root root 4096 1970-01-01 00:00 scaling_available_frequencies
-r–r--r-- 1 root root 4096 1970-01-01 00:35 scaling_available_governors
-r–r--r-- 1 root root 4096 1970-01-01 00:35 scaling_cur_freq
-r–r--r-- 1 root root 4096 1970-01-01 00:35 scaling_driver
-rw-r–r-- 1 root root 4096 1970-01-01 00:00 scaling_governor
-rw-rw---- 1 system system 4096 1970-01-01 00:00 scaling_max_freq
-rw-rw-r-- 1 system system 4096 1970-01-01 00:00 scaling_min_freq
-rw-r–r-- 1 root root 4096 1970-01-01 00:35 scaling_setspeed
android:/sys/devices/system/cpu/cpu0/cpufreq $
- 前缀cpuinfo 代表的是cpu硬件上支持的频率
- 前缀scaling 代表的是可以通过CPUFreq系统用软件进行调节时所支持的频率
- cpuinfo_cur_freq 代表通过硬件实际上读到的频率值,而scaling_cur_freq则是软件当前的设置值,多数情况下这两个值是一致的,但是也有可能因为硬件的原因,有微小的差异.
比如下面数据,我的cpu0的最低运行频率是0.6GHz,最高是1.8GHz,目前正在运行的频率是0.6GHz。
cpuinfo_cur_freq: 652800
cpuinfo_max_freq: 1804800
cpuinfo_min_freq: 652800
scaling_cur_freq: 652800
scaling_max_freq: 1804800
scaling_min_freq: 652800
- scaling_available_frequencies 会输出当前软件支持的频率值,下面输出,从0.6GHz到1.8GHz,一共支持5挡的频率可供选择。
android:/sys/devices/system/cpu/cpufreq/policy0 # cat scaling_available_fre*
cat scaling_available_fre*
652800 1036800 1401600 1689600 1804800
- scaling_available_governors 则会输出当前可供选择的频率调节策略
android:/sys/devices/system/cpu/cpufreq/policy0 # cat scaling_available_governors
conservative ondemand userspace powersave performance schedutil
- scaling_governor 一共有6中策略供我们选择,那么当前系统选用那种策略?让我们看看:
android:/sys/devices/system/cpu/cpu0/cpufreq # cat scaling_governor
schedutil
OK,我的系统当前选择schedutil这种策略,这是高通自加的策略,详细的情况我们留在后面的章节中讨论。
- ondemand: 只要cpu的负载超过某一个阀值,cpu的频率会立刻提升至最高,然后再根据实际情况降到合适的水平。
- userspace:我们可以通过scaling_setspeed手工设置需要的频率
- powersave:简单地使用最低的工作频率进行运行
- performance:一直选择最高的频率进行运行
- scaling_driver 则会输出当前使用哪一个驱动来设置cpu的工作频率。
android:/sys/devices/system/cpu/cpu0/cpufreq # cat scaling_driv
msm
2. 刨根问底——软件架构
通过上一节的介绍,我们可以大致梳理出CPUFreq系统的构成和工作方式。
- 首先,CPU的硬件特性决定了这个CPU的最高和最低工作频率,所有的频率调整数值都必须在这个范围内,它们用cpuinfo_xxx_freq来表示。
- 然后,我们可以在这个范围内再次定义出一个软件的调节范围,它们用scaling_xxx_freq来表示。
- 同时,根据具体的硬件平台的不同,我们还需要提供一个频率表,这个频率表规定了cpu可以工作的频率值,当然这些频率值必须要在cpuinfo_xxx_freq的范围内。
有了这些频率信息,CPUFreq系统就可以根据当前cpu的负载轻重状况,合理地从频率表中选择一个合适的频率供cpu使用,已达到节能的目的。至于如何选择频率表中的频率,这个要由不同的governor来实现,目前的原生的内核版本提供了5种governor供我们选择。选择好适当的频率以后,具体的频率调节工作就交由scaling_driver来完成。
CPUFreq系统把一些公共的逻辑和接口代码抽象出来,这些代码与平台无关,也与具体的调频策略无关,内核的文档把它称为CPUFreq Core(/Documents/cpufreq/core.txt)。另外一部分,与实际的调频策略相关的部分被称作cpufreq_policy,cpufreq_policy又是由频率信息和具体的governor组成,governor才是具体策略的实现者,当然governor需要我们提供必要的频率信息,governor的实现最好能做到平台无关,与平台相关的代码用cpufreq_driver表述,它完成实际的频率调节工作。最后,如果其他内核模块需要在频率调节的过程中得到通知消息,则可以通过cpufreq notifiers来完成。由此,我们可以总结出CPUFreq系统的软件结构如下:
1. cpufreq_policy
一种调频策略governor的各种限制条件的组合称之为policy,代码中用cpufreq_policy这一数据结构来表示:
struct cpufreq_policy {cpumask_var_t cpus; cpumask_var_t related_cpus; unsigned int shared_type; unsigned int cpu; unsigned int last_cpu; struct cpufreq_cpuinfo cpuinfo;unsigned int min; /* in kHz */unsigned int max; /* in kHz */unsigned int cur; unsigned int policy; struct cpufreq_governor *governor; void *governor_data;struct work_struct update; struct cpufreq_real_policy user_policy;struct kobject kobj;struct completion kobj_unregister;
};
其中的各个字段的解释如下:
- cpus和related_cpus 这两个都是cpumask_var_t变量,cpus表示的是这一policy控制之下的所有还出于online状态的cpu,而related_cpus则是online和offline两者的合集。主要是用于多个cpu使用同一种policy的情况,实际上,我们平常见到的大多数系统中都是这种情况:所有的cpu同时使用同一种policy。我们需要related_cpus变量指出这个policy所管理的所有cpu编号。
- cpu和last_cpu 虽然一种policy可以同时用于多个cpu,但是通常一种policy只会由其中的一个cpu进行管理,cpu变量用于记录用于管理该policy的cpu编号,而last_cpu则是上一次管理该policy的cpu编号(因为管理policy的cpu可能会被plug out,这时候就要把管理工作迁移到另一个cpu上)。
- cpuinfo 保存cpu硬件所能支持的最大和最小的频率以及切换延迟信息。
min/max/cur 该policy下的可使用的最小频率,最大频率和当前频率。 - policy 该变量可以取以下两个值:CPUFREQ_POLICY_POWERSAVE和CPUFREQ_POLICY_PERFORMANCE,该变量只有当调频驱动支持setpolicy回调函数的时候有效,这时候由驱动根据policy变量的值来决定系统的工作频率或状态。如果调频驱动(cpufreq_driver)支持target回调,则频率由相应的governor来决定。
- governor和governor_data 指向该policy当前使用的cpufreq_governor结构和它的上下文数据。governor是实现该policy的关键所在,调频策略的逻辑由governor实现。
- update 有时在中断上下文中需要更新policy,需要利用该工作队列把实际的工作移到稍后的进程上下文中执行。
- user_policy 有时候因为特殊的原因需要修改policy的参数,比如溫度过高时,最大可允许的运行频率可能会被降低,为了在适当的时候恢复原有的运行参数,需要使用user_policy保存原始的参数(min,max,policy,governor)。
- kobj 该policy在sysfs中对应的kobj的对象。
2. cpufreq_governor
所谓的governor,我把它翻译成:调节器。governor负责检测cpu的使用状况,从而在可用的范围中选择一个合适的频率,代码中它用cpufreq_governor结构来表示:
struct cpufreq_governor {char name[CPUFREQ_NAME_LEN];int initialized;int (*governor) (struct cpufreq_policy *policy,unsigned int event);ssize_t (*show_setspeed) (struct cpufreq_policy *policy,char *buf);int (*store_setspeed) (struct cpufreq_policy *policy,unsigned int freq);unsigned int max_transition_latency; /* HW must be able to switch tonext freq faster than this value in nano secs or wewill fallback to performance governor */struct list_head governor_list;struct module *owner;
};
其中的各个字段的解释如下:
- name 该governor的名字。
- initialized 初始化标志。
- governor 指向一个回调函数,CPUFreq Core会在不同的阶段调用该回调函数,用于该governor的启动、停止、初始化、退出动作。
- list_head 所有注册的governor都会利用该字段链接在一个全局链表中,以供系统查询和使用。
3. cpufreq_driver
上一节提到的gonvernor只是负责计算并提出合适的频率,但是频率的设定工作是平台相关的,这需要cpufreq_driver驱动来完成,cpufreq_driver的结构如下:
struct cpufreq_driver {struct module *owner;char name[CPUFREQ_NAME_LEN];u8 flags;bool have_governor_per_policy;/* needed by all drivers */int (*init) (struct cpufreq_policy *policy);int (*verify) (struct cpufreq_policy *policy);/* define one out of two */int (*setpolicy) (struct cpufreq_policy *policy);int (*target) (struct cpufreq_policy *policy,unsigned int target_freq,unsigned int relation);/* should be defined, if possible */unsigned int (*get) (unsigned int cpu);/* optional */unsigned int (*getavg) (struct cpufreq_policy *policy,unsigned int cpu);int (*bios_limit) (int cpu, unsigned int *limit);int (*exit) (struct cpufreq_policy *policy);int (*suspend) (struct cpufreq_policy *policy);int (*resume) (struct cpufreq_policy *policy);struct freq_attr **attr;
};
相关的字段的意义解释如下:
- name 该频率驱动的名字。
- init 回调函数,该回调函数必须实现,CPUFreq Core会通过该回调函数对该驱动进行必要的初始化工作。
- verify 回调函数,该回调函数必须实现,CPUFreq Core会通过该回调函数检查policy的参数是否被驱动支持。
- setpolicy/target 回调函数,驱动必须实现这两个函数中的其中一个,如果不支持通过governor选择合适的运行频率,则实现setpolicy回调函数,这样系统只能支持CPUFREQ_POLICY_POWERSAVE和CPUFREQ_POLICY_PERFORMANCE这两种工作策略。反之,实现target回调函数,通过target回调设定governor所需要的频率。
- get 回调函数,用于获取cpu当前的工作频率。
- getavg 回调函数,用于获取cpu当前的平均工作频率。
4. cpufreq notifiers
CPUFreq的通知系统使用了内核的标准通知接口。它对外提供了两个通知事件:policy通知和transition通知。
policy通知用于通知其它模块cpu的policy需要改变,每次policy改变时,该通知链上的回调将会用不同的事件参数被调用3次,分别是:
- CPUFREQ_ADJUST 只要有需要,所有的被通知者可以在此时修改policy的限制信息,比如温控系统可能会修改在大允许运行的频率。
- CPUFREQ_INCOMPATIBLE 只是为了避免硬件错误的情况下,可以在该通知中修改policy的限制信息。
- CPUFREQ_NOTIFY 真正切换policy前,该通知会发往所有的被通知者。
transition通知链用于在驱动实施调整cpu的频率时,用于通知相关的注册者。每次调整频率时,该通知会发出两次通知事件:
- CPUFREQ_PRECHANGE 调整前的通知。
- CPUFREQ_POSTCHANGE 完成调整后的通知。
- CPUFREQ_RESUMECHANGE 当检测到因系统进入suspend而造成频率被改变时,该通知消息会被发出
核心(core)架构与API
上一面中,我们大致地讲解了一下CPUFreq在用户空间的sysfs接口和它的几个重要的数据结构,同时也提到,CPUFreq子系统把一些公共的代码逻辑组织在一起,构成了CPUFreq的核心部分,这些公共逻辑向CPUFreq和其它内核模块提供了必要的API,像cpufreq_governor、cpufreq_driver等模块通过这些API来完成一个完整的CPUFreq体系。这一节我们就来讨论一下核心架构的代码架构以及如何使用这些公共的API接口。
核心部分的代码都在:/drivers/cpufreq/cpufreq.c中,本系列文章我使用的内核版本是3.10.0.
1. CPUFreq子系统的初始化
先看看具体的代码:
static int __init cpufreq_core_init(void)
{int cpu;if (pufreq_disabled())return -ENODEV;for_each_possible_cpu(cpu) {per_cpu(cpufreq_policy_cpu, cpu) = -1;init_rwsem(&per_cpu(cpu_policy_rwsem, cpu));}cpufreq_global_kobject = kobject_create_and_add("cpufreq", &cpu_subsys.dev_root->kobj);BUG_ON(!cpufreq_global_kobject);register_syscore_ops(&cpufreq_syscore_ops);return 0;
}
core_initcall(cpufreq_core_init);
可见,在系统的启动阶段,经由initcall机制,cpufreq_core_init被调用,由它来完成核心部分的初始化工作,其中:
cpufreq_policy_cpu 是一个per_cpu变量,在smp的系统下,每个cpu可以有自己独立的调频policy,也可以所有的cpu都是用一种policy,这时候就有可能出现其中一个cpu管理着某个policy,而其它cpu因为也使用同一个policy,这些cpu的policy的就交由那个管理cpu代管,这个per_cpu变量就是用来记录各个cpu的policy实际上是由那个cpu进行管理的。初始化时都被初始化为-1了,代表现在还没有开始进行policy的管理。
接下来的kobject_create_and_add函数在/sys/devices/system/cpu这个节点下建立了一个cpufreq节点,该节点的下面以后会用来放置当前governor的一些配置参数。参数cpu_subsys是内核的一个全局变量,是由更早期的初始化时初始化的,代码在drivers/base/cpu.c中:
struct bus_type cpu_subsys = {.name = "cpu",.dev_name = "cpu",
};
EXPORT_SYMBOL_GPL(cpu_subsys);void __init cpu_dev_init(void)
{if (subsys_system_register(&cpu_subsys, cpu_root_attr_groups))panic("Failed to register CPU subsystem");cpu_dev_register_generic();
}
这将会建立一根cpu总线,总线下挂着系统中所有的cpu,cpu总线设备的根目录就位于:/sys/devices/system/cpu,同时,/sys/bus下也会出现一个cpu的总线节点。cpu总线设备的根目录下会依次出现cpu0,cpu1,… cpux节点,每个cpu对应其中的一个设备节点。CPUFreq子系统利用这个cpu_subsys来获取系统中的cpu设备,并在这些cpu设备下面建立相应的cpufreq对象,这个我们在后面再讨论。
这样看来,cpufreq子系统的初始化其实没有做什么重要的事情,只是初始化了几个per_cpu变量和建立了一个cpufreq文件节点。下图是初始化过程的序列图:
图 1.1 核心层初始化
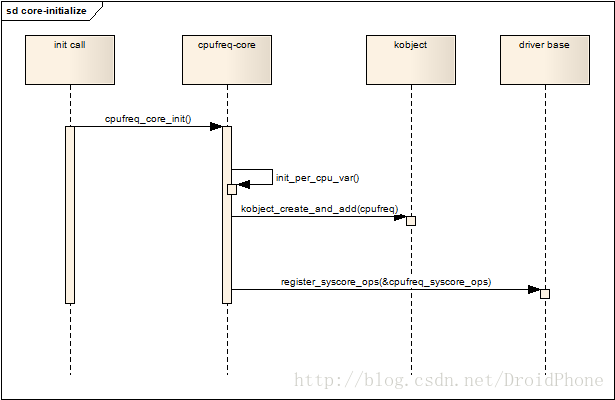
2. 注册cpufreq_governor
系统中可以同时存在多个governor策略,一个policy通过cpufreq_policy结构中的governor指针和某个governor相关联。要想一个governor被policy使用,首先要把该governor注册到cpufreq的核心中,我们可以通过核心层提供的API来完成注册:
int cpufreq_register_governor(struct cpufreq_governor *governor)
{int err;......governor->initialized = 0;err = -EBUSY;if (__find_governor(governor->name) == NULL) {err = 0;list_add(&governor->governor_list, &cpufreq_governor_list);}......return err;
}
核心层定义了一个全局链表变量:cpufreq_governor_list,注册函数首先根据governor的名称,通过__find_governor()函数查找该governor是否已經被注册过,如果没有被注册过,则把代表该governor的结构体添加到cpufreq_governor_list链表中。在上一篇中我们提到,目前的内核版本提供了5种governor供我们使用,我们可以通过内核的配置項来选择需要编译的governor,同时需要指定一个默认的governor。在cpufreq.h中,将会根据配置項的选择,把CPUFREQ_DEFAULT_GOVERNOR宏指向默认governor结构体变量的地址,在注册cpufreq_driver的阶段需要使用这个宏来设定系统默认使用的governor。
3. 注册一个cpufreq_driver驱动
与governor不同,系统中只会存在一个cpufreq_driver驱动,根据上一面Linux动态频率调节系统CPUFreq之一:概述的介绍,cpufreq_driver是平台相关的,负责最终实施频率的调整动作,而选择工作频率的策略是由governor完成的。所以,系统中只需要注册一个cpufreq_driver即可,它只负责知道如何控制该平台的时钟系统,从而设定由governor确定的工作频率。注册cpufreq_driver驱动会触发cpufreq核心的一系列额外的初始化动作,第一节所说的核心初始化工作非常简单,实际上,更多的初始化动作在注册cpufreq_driver阶段完成。核心提供了一个API:cpufreq_register_driver来完成注册工作。下面我们分析一下这个函数的工作过程:
int cpufreq_register_driver(struct cpufreq_driver *driver_data)
{......if (cpufreq_disabled())return -ENODEV;if (!driver_data || !driver_data->verify || !driver_data->init ||((!driver_data->setpolicy) && (!driver_data->target)))return -EINVAL;
该API只有一个参数:一个cpufreq_driver指针,driver_data,该结构事先在驱动的代码中定义,调用该API时作为参数传入。函数先判断系统目前是否禁止了调频功能,然后检查cpufreq_driver的几个回调函数是否被实现,由代码可以看出,verify和init回调函数必须要实现,而setpolicy和target回调则至少要被实现其中的一个。这几个回调的作用请参考本系列的第一篇文章。接下来:
write_lock_irqsave(&cpufreq_driver_lock, flags);if (cpufreq_driver) {write_unlock_irqrestore(&cpufreq_driver_lock, flags);return -EBUSY;}cpufreq_driver = driver_data;write_unlock_irqrestore(&cpufreq_driver_lock, flags);
检查全局变量cpufreq_driver是否已经被赋值,如果没有,则传入的参数被赋值给全局变量cpufreq_driver,从而保证了系统中只会注册一个cpufreq_driver驱动。然后:ret = subsys_interface_register(&cpufreq_interface);............ register_hotcpu_notifier(&cpufreq_cpu_notifier);
通过subsys_interface_register给每一个cpu建立一个cpufreq_policy,最后注册cpu hot plug通知,以便在cpu hot plug的时候,能够动态地处理各个cpu policy之间的关系(比如迁移负责管理的cpu等等)。这里要重点讨论一下subsys_interface_register的过程,回到第一节的内容,我们知道初始化阶段,cpu_subsys被建立,从而每个cpu都会在cpu总线设备下建立一个属于自己的设备:sys/devices/system/cpu/cpux。subsys_interface_register负责在cpu_subsys子系统的子设备下面注册公共的接口。我们看看参数cpufreq_interface的定义:
static struct subsys_interface cpufreq_interface = {.name = "cpufreq",.subsys = &cpu_subsys,.add_dev = cpufreq_add_dev,.remove_dev = cpufreq_remove_dev,
};
subsys_interface_register函数的代码我就不再展开了,它的大致作用就是:遍历子系统下面的每一个子设备,然后用这个子设备作为参数,调用cpufrq_interface结构的add_dev回调函数,这里的回调函数被指向了cpufreq_add_dev,它的具体工作方式我们在下一节中讨论。
driver注册完成后,驱动被保存在全局变量cpufreq_driver中,供核心层使用,同时,每个cpu也会建立自己的policy策略,governor也开始工作,实时地监控着cpu的负载并计算合适的工作频率,然后通过driver调整真正的工作频率。下图是cpufreq_driver注册过程的序列图:
图 3.1 cpufreq_driver的注册过程
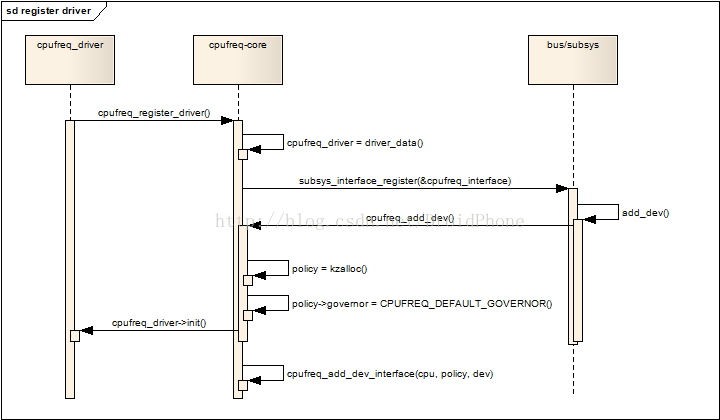
4. 为每个cpu建立频率调整策略(policy)
为每个cpu建立频率调整策略实在注册cpufreq_driver阶段的subsys_interface_registe函数中完成的,上一节已经提到,该函数最终会调用cpufreq_add_dev回调函数,现在展开这个函数分析一下:
因为subsys_interface_registe会枚举各个cpu设备,不管该cpu处于offline还是online状态,cpufreq_add_dev都会被调用,所以函数的一开始,判断如果cpu处于offline状态,直接返回。
static int cpufreq_add_dev(struct device *dev, struct subsys_interface *sif)
{......if (cpu_is_offline(cpu))return 0;
如果是smp系统,本cpu的policy可能和其他cpu共同使用同一个policy,并委托另一个叫做管理cpu的cpu进行管理,下面的代码判断这种情况,如果已经委托别的cpu管理,则直接返回,核心层定义了另一个per_cpu变量:cpufreq_cpu_data,用来保存各个cpu所使用的cpufreq_policy结构的指针,cpufreq_cpu_get函数实际上就是通过这个per_cpu变量,获取该指针,如果该指针非0,代表该cpu已经建立好了它自身的policy(可能是在他之前的管理cpu建立policy期间一并建立的)。
policy = cpufreq_cpu_get(cpu);if (unlikely(policy)) {cpufreq_cpu_put(policy);return 0;}
因为cpu hot plug期间,cpufreq_add_dev也会被调用,下面的代码片段检测该cpu之前是否被hot-unpluged过,如果是,找到其中一个相关的cpu(这些相关的cpu都委托给同一个托管它cpu进行管理,调用cpufreq_add_policy_cpu函数,该函数只是简单地建立一个cpufreq链接,链接到管理cpu的cpufreq节点。
for_each_online_cpu(sibling) {struct cpufreq_policy *cp = per_cpu(cpufreq_cpu_data, sibling);if (cp && cpumask_test_cpu(cpu, cp->related_cpus)) {read_unlock_irqrestore(&cpufreq_driver_lock, flags);return cpufreq_add_policy_cpu(cpu, sibling, dev);}}
当这是系统初始化阶段第一次调用cpufreq_add_dev时(subsys_interface_register枚举到的第一个cpu,通常就是cpu0),cpufreq_cpu_data应该为NULL,所以我们要为这样的cpu分配一个cpufreq_policy结构,并初始化该policy所管理的cpu,包括online的cpus字段和online+offline的cpu_related字段,并把自己设置为这个policy的管理cpu,使用默认governor初始化policy->governor字段,同时吧自己加入到online的cpus字段中:
policy = kzalloc(sizeof(struct cpufreq_policy), GFP_KERNEL);if (!policy)goto nomem_out;if (!alloc_cpumask_var(&policy->cpus, GFP_KERNEL))goto err_free_policy;if (!zalloc_cpumask_var(&policy->related_cpus, GFP_KERNEL))goto err_free_cpumask;policy->cpu = cpu;policy->governor = CPUFREQ_DEFAULT_GOVERNOR;cpumask_copy(policy->cpus, cpumask_of(cpu));/* Initially set CPU itself as the policy_cpu */per_cpu(cpufreq_policy_cpu, cpu) = cpu;
接下来初始化一个供kobject系统注销时使用的同步变量,初始化一个workqueue,某些时候不能马上执行对该policy的更新操作,可以使用该workqueue来延迟执行。
init_completion(&policy->kobj_unregister);INIT_WORK(&policy->update, handle_update);
接着,调用cpufreq_driver的init回调,进一步初始化该policy:
ret = cpufreq_driver->init(policy);if (ret) {pr_debug("initialization failed\n");goto err_set_policy_cpu;}
在上述驱动的初始化内部,应该完成以下工作:
- 设定该cpu的最大和最小工作频率
- 设定该policy的最大和最小工作频率
- 设定该policy可供调节的频率档位
- 设定cpu调节频率时的延迟时间特性
该policy可以管理的cpu个数(policy->cpus)
继续:
/* related cpus should atleast have policy->cpus */cpumask_or(policy->related_cpus, policy->related_cpus, policy->cpus);
注释已经写的很清楚了,把online的cpu加到代表online+offline的related字段中。接着,剔除offline的cpu:
cpumask_and(policy->cpus, policy->cpus, cpu_online_mask);
然后,发出CPUFREQ_START通知:
blocking_notifier_call_chain(&cpufreq_policy_notifier_list,CPUFREQ_START, policy);
如果是hot-plug加入的cpu,找出它上次使用的governor:
#ifdef CONFIG_HOTPLUG_CPUgov = __find_governor(per_cpu(cpufreq_cpu_governor, cpu));if (gov) {policy->governor = gov;pr_debug("Restoring governor %s for cpu %d\n",policy->governor->name, cpu);}
#endif
最后,建立cpu设备下的sysfs文件节点:cpufreq,它的完整路径是:/sys/devices/system/cpu/cpux/cpufreq,同时,在他的下面,相应的sysfs节点也同时被建立,节点的内容请参考本系列的第一篇文章:Linux动态频率调节系统CPUFreq之一:概述:
ret = cpufreq_add_dev_interface(cpu, policy, dev);
至此,一个cpu的policy建立完成,它的频率限制条件、使用的governor策略,sysfs文件节点都已经建立完成。需要注意点是,系统中有多少个cpu,cpufreq_add_dev函数就会被调用多少次,最后,每个cpu都会建立自己的policy,当然,也有可能只有部分cpu建立了真正的policy,而其它cpu则委托这些cpu进行policy的管理,关于这一点,一开始读代码的时候可能有点困扰,为了搞清楚他们之间的关系,我们再跟入cpufreq_add_dev_interface函数看看:
static int cpufreq_add_dev_interface(unsigned int cpu,struct cpufreq_policy *policy,struct device *dev)
{....../* prepare interface data */ret = kobject_init_and_add(&policy->kobj, &ktype_cpufreq,&dev->kobj, "cpufreq");....../* set up files for this cpu device */drv_attr = cpufreq_driver->attr;while ((drv_attr) && (*drv_attr)) {ret = sysfs_create_file(&policy->kobj, &((*drv_attr)->attr));if (ret)goto err_out_kobj_put;drv_attr++;}
函数的一开始,建立cpufreq文件节点,然后在它的下面再建立一系列节点,用户可以通过这些文件节点控制该policy的一些参数。这不是我们的重点,我们看下面这一段代码:
for_each_cpu(j, policy->cpus) {per_cpu(cpufreq_cpu_data, j) = policy;per_cpu(cpufreq_policy_cpu, j) = policy->cpu;}
前面的代码已经设定了该policy所管理的online cpu:policy->cpus,通过两个per_cpu变量,这里把每个online cpu的policy都设置为了本cpu(管理cpu)的policy,并且把所有online的cpu的管理cpu也指定为了本cpu。接下来,cpufreq_add_dev_symlink被调用,所有policy->cpus指定的cpu会建立一个cpufreq链接,指向本cpu(管理cpu)的真实cpufreq节点:
ret = cpufreq_add_dev_symlink(cpu, policy);
注意,假如这时的cpu是cpu0,也就是说,其它cpu的cpufreq_add_dev还没有被调用,但是在cpufreq_cpu_data中,与之对应的policy指针已经被赋值为cpu0所对应的policy,这样,回到cpufreq_add_dev函数的开头部分,当接下其它被认为使用cpu0托管他们的policy的cpu也会进入cpufreq_add_dev函数,但是,因为cpufreq_cpu_data中对应的policy已经在cpu0的建立阶段被赋值,所以这些cpu他们不会走完所有的流程,在函数的开头的判断部分,判断cpufreq_cpu_data中cpu对应的policy已经被赋值,就直接返回了。
接着往下看cpufreq_add_dev_interface的代码:
memcpy(&new_policy, policy, sizeof(struct cpufreq_policy));
/* assure that the starting sequence is run in __cpufreq_set_policy */
policy->governor = NULL;
/* set default policy */ret = __cpufreq_set_policy(policy, &new_policy);policy->user_policy.policy = policy->policy;policy->user_policy.governor = policy->governor;
通过__cpufreq_set_policy函数,最终使得该policy正式生效。到这里,每个cpu的policy已经建立完毕,并正式开始工作。关于__cpufreq_set_policy的代码这里就不展开了,我只给出它的序列图:
图 4.1 设置一个cpufreq_policy
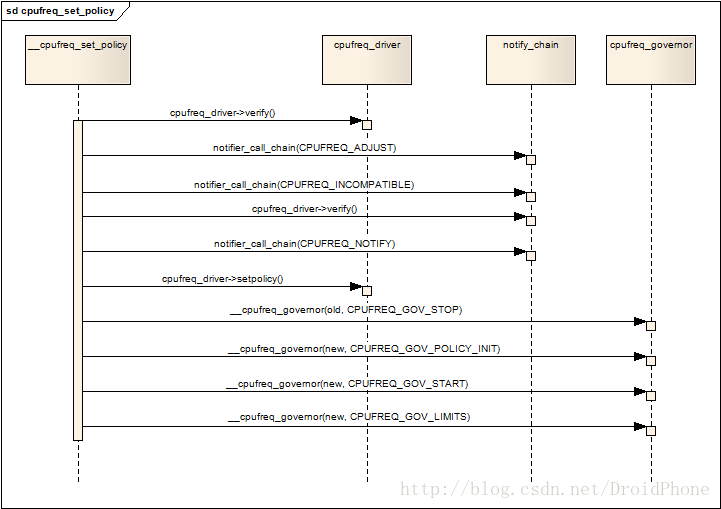
5. 其它API
cpufreq的核心层除了提供上面几节讨论的注册governor,注册cpufreq_driver等API外,还提供了其他一些辅助的API,以方便其它模块的使用。
int cpufreq_register_notifier(struct notifier_block *nb, unsigned int list);
int cpufreq_unregister_notifier(struct notifier_block *nb, unsigned int list);
以上两个API用于注册和注销cpufreq系统的通知消息,第二个参数可以选择通知的类型,可以有以下两种类型:
- CPUFREQ_TRANSITION_NOTIFIER 收到频率变更通知
- CPUFREQ_POLICY_NOTIFIER 收到policy更新通知
int cpufreq_driver_target(struct cpufreq_policy *policy,unsigned int target_freq,unsigned int relation);int __cpufreq_driver_target(struct cpufreq_policy *policy,unsigned int target_freq,unsigned int relation);
以上两个API用来设置cpu的工作频率,区别在于cpufreq_driver_target是带锁的版本,而__cpufreq_driver_target是不带锁的版本,如果确定是在governor的上下文中,使用不带锁的版本,否则需要使用带锁的版本。
void cpufreq_verify_within_limits(struct cpufreq_policy *policy, unsigned int min, unsigned int max);
这个API用来检查并重新设定policy的最大和最小频率。
int cpufreq_update_policy(unsigned int cpu);
这个API用来触发cpufreq核心进行policy的更新操作
governor
在上一篇文章中,介绍了cpufreq的core层,core提供了cpufreq系统的初始化,公共数据结构的建立以及对cpufreq中其它子部件提供注册功能。core的最核心功能是对policy的管理,一个policy通过cpufreq_policy结构中的governor字段,和某个governor相关联,本章的内容正是要对governor进行讨论。
通过前面两篇文章的介绍,我们知道,governor的作用是:检测系统的负载状况,然后根据当前的负载,选择出某个可供使用的工作频率,然后把该工作频率传递给cpufreq_driver,完成频率的动态调节。内核默认提供了5种governor供我们使用,在之前的内核版本中,每种governor几乎是独立的代码,它们各自用自己的方式实现对系统的负载进行监测,很多时候,检测的逻辑其实是很相似的,各个governor最大的不同之处其实是根据检测的结果,选择合适频率的策略。所以,为了减少代码的重复,在我现在分析的内核版本中(3.10.0),一些公共的逻辑代码被单独抽象出来,单独用一个文件来实现:/drivers/cpufreq/cpufreq_governor.c,而各个具体的governor则分别有自己的代码文件,如:cpufreq_ondemand.c,cpufreq_performance.c。下面我们先从公共部分讨论。
1. 数据结构
cpu_dbs_common_info 该结构把对计算cpu负载需要使用到的一些辅助变量整合在了一起,通常,每个cpu都需要一个cpu_dbs_common_info结构体,该结构体中的成员会在governor的生命周期期间进行传递,以用于统计当前cpu的负载,它的定义如下:
/* Per cpu structures */
struct cpu_dbs_common_info {int cpu;u64 prev_cpu_idle;u64 prev_cpu_wall;u64 prev_cpu_nice;struct cpufreq_policy *cur_policy;struct delayed_work work;struct mutex timer_mutex;ktime_t time_stamp;
};
- cpu 与该结构体相关联的cpu编号。
- prev_cpu_idle 上一次统计时刻该cpu停留在idle状态的总时间。
- prev_cpu_wall 上一次统计时刻对应的总工作时间。
- cur_policy 指向该cpu所使用的cpufreq_policy结构。
- work 工作队列,该工作队列会被定期地触发,然后定期地进行负载的更新和统计工作。
dbs缩写,实际是:demand based switching,通常,因为cpu_dbs_common_info只包含了经过抽象后的公共部分,所以,各个governor会自己定义的一个包含cpu_dbs_common_info的自定义结构,例如对于ondemand,他会定义:
struct od_cpu_dbs_info_s {struct cpu_dbs_common_info cdbs;struct cpufreq_frequency_table *freq_table;unsigned int freq_lo;unsigned int freq_lo_jiffies;unsigned int freq_hi_jiffies;unsigned int rate_mult;unsigned int sample_type:1;
};
而对于Conservative,他的定义如下:
struct cs_cpu_dbs_info_s {struct cpu_dbs_common_info cdbs;unsigned int down_skip;unsigned int requested_freq;unsigned int enable:1;
};
把它理解为类似于C++语言的基类和子类的概念就是了。
common_dbs_data 各个独立的governor,需要和governor的公共层交互,需要实现一套公共的接口,这个接口由common_dbs_data结构来提供:
struct common_dbs_data {/* Common across governors */#define GOV_ONDEMAND 0#define GOV_CONSERVATIVE 1int governor;struct attribute_group *attr_group_gov_sys; /* one governor - system */struct attribute_group *attr_group_gov_pol; /* one governor - policy *//* Common data for platforms that don't set have_governor_per_policy */struct dbs_data *gdbs_data;struct cpu_dbs_common_info *(*get_cpu_cdbs)(int cpu);void *(*get_cpu_dbs_info_s)(int cpu);void (*gov_dbs_timer)(struct work_struct *work);void (*gov_check_cpu)(int cpu, unsigned int load);int (*init)(struct dbs_data *dbs_data);void (*exit)(struct dbs_data *dbs_data);/* Governor specific ops, see below */void *gov_ops;
};
主要的字段意义如下:
- governor 因为ondemand和conservative的实现部分有很多相似的地方,用该字段做一区分,可以设置为GOV_ONDEMAND或GOV_CONSERVATIVE的其中之一。
- attr_group_gov_sys 该公共的sysfs属性组。
- attr_group_gov_pol 各policy使用的属性组,有时候多个policy会使用同一个governor算法。
- gdbs_data 通常,当没有设置have_governor_per_policy时,表示所有的policy使用了同一种
- overnor,该字段指向该governor的dbs_data结构。
- get_cpu_cdbs 回调函数,公共层用它取得对应cpu的cpu_dbs_common_info结构指针。
- get_cpu_dbs_info_s 回调函数,公共层用它取得对应cpu的cpu_dbs_common_info_s的派生结构指针,例如:od_cpu_dbs_info_s,cs_cpu_dbs_info_s。
- gov_dbs_timer 前面说过,cpu_dbs_common_info_s结构中有一个工作队列,该回调通常用作工作队列的工作函数。
- gov_check_cpu 计算cpu负载的回调函数,通常会直接调用公共层提供的dbs_check_cpu函数完成实际的计算工作。
- init 初始化回调,用于完成该governor的一些额外的初始化工作。
- exit 回调函数,governor被移除时调用。
- gov_ops 各个governor可以用该指针定义各自特有的一些操作接口。
dbs_data 该结构体通常由governor的公共层代码在governor的初始化阶段动态创建,该结构的一个最重要的字段就是cdata:一个common_dbs_data结构指针,另外,该结构还包含一些定义governor工作方式的一些调节参数。该结构的详细定义如下:
struct dbs_data {struct common_dbs_data *cdata;unsigned int min_sampling_rate;int usage_count;void *tuners;/* dbs_mutex protects dbs_enable in governor start/stop */struct mutex mutex;
};
几个主要的字段:
- cdata 一个common_dbs_data结构指针,通常由具体governor的实现部分定义好,然后作为参数,通过公共层的API:cpufreq_governor_dbs,传递到公共层,cpufreq_governor_dbs函数在创建好dbs_data结构后,把该指针赋值给该字段。
- min_sampling_rate 用于记录统计cpu负载的采样周期。
- usage_count 当没有设置have_governor_per_policy时,意味着所有的policy采用同一个governor,该字段就是用来统计目前该governor被多少个policy引用。
- tuners 指向governor的调节参数结构,不同的governor可以定义自己的tuner结构,公共层代码会在governor的初始化阶段调用common_dbs_data结构的init回调函数,governor的实现可以在init回调中初始化tuners字段。
如果设置了have_governor_per_policy,每个policy拥有各自独立的governor,也就是说,拥有独立的dbs_data结构,它会记录在cpufreq_policy结构的governor_data字段中,否则,如果没有设置have_governor_per_policy,多个policy共享一个governor,和同一个dbs_data结构关联,此时,dbs_data被赋值在common_dbs_data结构的gdbs_data字段中。
cpufreq_governor 这个结构在本系列文章的第一篇已经介绍过了,请参看Linux动态频率调节系统CPUFreq之一:概述。几个数据结构的关系如下图所示:
图 1.1 governor的数据结构关系
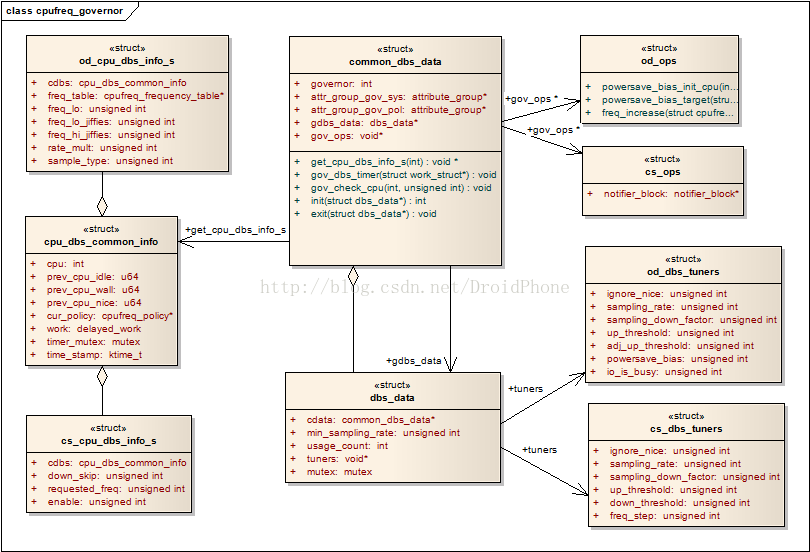
下面我们以ondemand这个系统已经实现的governor为例,说明一下如何实现一个governor。具体的代码请参看:/drivers/cpufreq/cpufreq_ondemand.c。
2. 定义一个governor
要实现一个governor,首先要定义一个cpufreq_governor结构,对于ondeman来说,它的定义如下:
struct cpufreq_governor cpufreq_gov_ondemand = {.name = "ondemand",.governor = od_cpufreq_governor_dbs,.max_transition_latency = TRANSITION_LATENCY_LIMIT,.owner = THIS_MODULE,
};
其中,governor是这个结构的核心字段,cpufreq_governor注册后,cpufreq的核心层通过该字段操纵这个governor的行为,包括:初始化、启动、退出等工作。现在,该字段被设置为od_cpufreq_governor_dbs,我们看看它的实现:
static int od_cpufreq_governor_dbs(struct cpufreq_policy *policy,unsigned int event)
{return cpufreq_governor_dbs(policy, &od_dbs_cdata, event);
}
只是简单地调用了governor的公共层提供的API:cpufreq_governor_dbs,关于这个API,我们在后面会逐一进行展开,这里我们注意到参数:&od_dbs_cdata,正是我们前面讨论过得common_dbs_data结构,作为和governor公共层的接口,在这里它的定义如下:
static struct common_dbs_data od_dbs_cdata = {.governor = GOV_ONDEMAND,.attr_group_gov_sys = &od_attr_group_gov_sys,.attr_group_gov_pol = &od_attr_group_gov_pol,.get_cpu_cdbs = get_cpu_cdbs,.get_cpu_dbs_info_s = get_cpu_dbs_info_s,.gov_dbs_timer = od_dbs_timer,.gov_check_cpu = od_check_cpu,.gov_ops = &od_ops,.init = od_init,.exit = od_exit,
};
这里先介绍一下get_cpu_cdbs和get_cpu_dbs_info_s这两个回调,前面介绍cpu_dbs_common_info_s结构的时候已经说过,各个governor需要定义一个cpu_dbs_common_info_s结构的派生结构,对于ondemand来说,这个派生结构是:od_cpu_dbs_info_s。两个回调函数分别用来获得基类和派生类这两个结构的指针。我们先看看od_cpu_dbs_info_s是如何定义的:
static DEFINE_PER_CPU(struct od_cpu_dbs_info_s, od_cpu_dbs_info);
没错,它被定义为了一个per_cpu变量,也就是说,每个cpu拥有各自独立的od_cpu_dbs_info_s,这很正常,因为每个cpu需要的实时负载是不一样的,需要独立的上下文变量来进行负载的统计。前面也已经列出了od_cpu_dbs_info_s的声明,他的第一个字段cdbs就是一个cpu_dbs_common_info_s结构。内核为我们提供了一个辅助宏来帮助我们定义get_cpu_cdbs和get_cpu_dbs_info_s这两个回调函数:
#define define_get_cpu_dbs_routines(_dbs_info) \
static struct cpu_dbs_common_info *get_cpu_cdbs(int cpu) \
{ \return &per_cpu(_dbs_info, cpu).cdbs; \
} \\
static void *get_cpu_dbs_info_s(int cpu) \
{ \return &per_cpu(_dbs_info, cpu); \
}
所以,在cpufreq_ondemand.c中,我们只要简单地使用上述的宏即可定义这两个回调:
define_get_cpu_dbs_routines(od_cpu_dbs_info);
经过上述这一系列的定义以后,governor的公共层即可通过这两个回调获取各个cpu所对应的cpu_dbs_common_info_s和od_cpu_dbs_info_s的结构指针,用来记录本次统计周期的一些上下文参数(idle时间和运行时间等等)。
3. 初始化一个governor
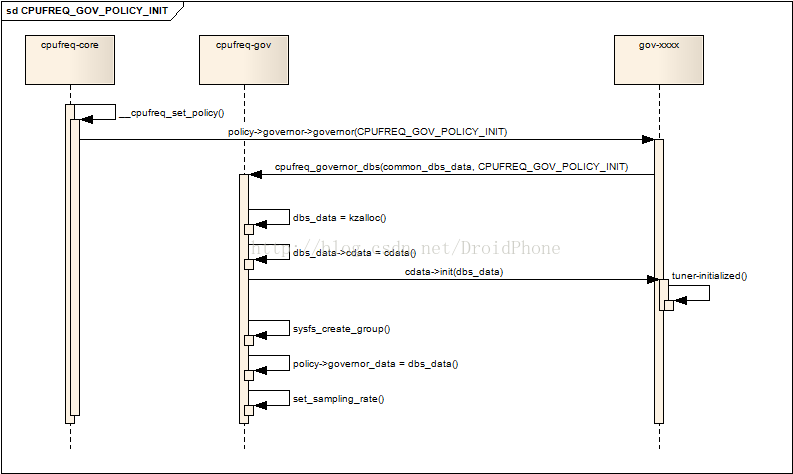
当一个governor被policy选定后,核心层会通过__cpufreq_set_policy函数对该cpu的policy进行设定,参看 Linux动态频率调节系统CPUFreq之二:核心(core)架构与API中的第4节和图4.1。如果policy认为这是一个新的governor(和原来使用的旧的governor不相同),policy会通过__cpufreq_governor函数,并传递CPUFREQ_GOV_POLICY_INIT参数,而__cpufreq_governor函数实际上是调用cpufreq_governor结构中的governor回调函数,在第2节中我们已经知道,这个回调最后会进入governor公共API:cpufreq_governor_dbs,下面是它收到CPUFREQ_GOV_POLICY_INIT参数时,经过简化后的代码片段:
case CPUFREQ_GOV_POLICY_INIT:......dbs_data = kzalloc(sizeof(*dbs_data), GFP_KERNEL);......dbs_data->cdata = cdata;dbs_data->usage_count = 1;rc = cdata->init(dbs_data);......rc = sysfs_create_group(get_governor_parent_kobj(policy),get_sysfs_attr(dbs_data));......policy->governor_data = dbs_data;....../* Bring kernel and HW constraints together */dbs_data->min_sampling_rate = max(dbs_data->min_sampling_rate,MIN_LATENCY_MULTIPLIER * latency);set_sampling_rate(dbs_data, max(dbs_data->min_sampling_rate,latency * LATENCY_MULTIPLIER));if ((cdata->governor == GOV_CONSERVATIVE) &&(!policy->governor->initialized)) {struct cs_ops *cs_ops = dbs_data->cdata->gov_ops;cpufreq_register_notifier(cs_ops->notifier_block,CPUFREQ_TRANSITION_NOTIFIER);}if (!have_governor_per_policy())cdata->gdbs_data = dbs_data;return 0;
首先,它会给这个policy分配一个dbs_data实例,然后把通过参数cdata传入的common_dbs_data指针,赋值给它的cdata字段,这样,policy就可以通过该字段获得governor的操作接口(通过cdata的一系列回调函数)。然后,调用cdata的init回调函数,对这个governor做进一步的初始化工作,对于ondemand来说,init回调的实际执行函数是:od_init,主要是完成和governor相关的一些调节参数的初始化,然后把初始化好的od_dbs_tuners结构指针赋值到dbs_data的tuners字段中,它的详细代码这里就不贴出了。接着,通过sysfs_create_group函数,建立该governor在sysfs中的节点,以后我们就可以通过这些节点对该governor的算法逻辑进行微调,ondemand在我的电脑中,建立了以下这些节点(sys/devices/system/cpu/cpufreq/ondemand):
sampling_rate;
io_is_busy;
up_threshold;
sampling_down_factor;
ignore_nice;
powersave_bias;
sampling_rate_min;
继续,把初始化好的dbs_data结构赋值给policy的governor_data字段,以方便以后的访问。最后是通过set_sampling_rate设置governor的采样周期,如果还有设置have_governor_per_policy,把dbs_data结构指针赋值给cdata结构的gdbs_data字段,至此,governor的初始化工作完成,下面是整个过程的序列图:
图 3.1 governor的初始化
4. 启动一个governor
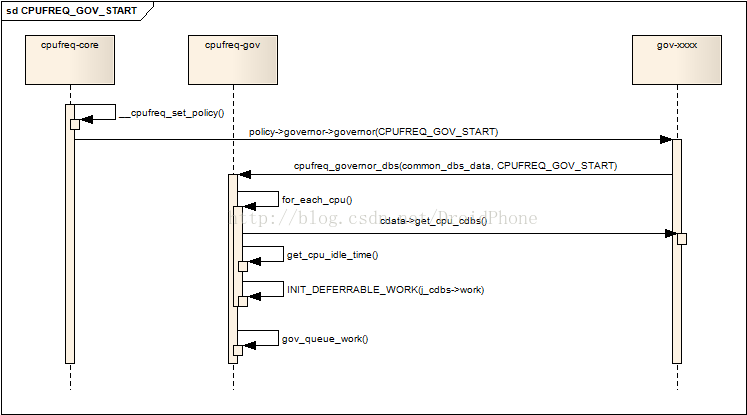
核心层会通过__cpufreq_set_policy函数,通过CPUFREQ_GOV_POLICY_INIT参数,在公共层的API:cpufreq_governor_dbs中,完成了对governor的初始化工作,紧接着,__cpufreq_set_policy会通过CPUFREQ_GOV_START参数,和初始化governor的流程一样,最终会到达cpufreq_governor_dbs函数中,我们看看它是如何启动一个governor的:
case CPUFREQ_GOV_START:if (!policy->cur)return -EINVAL;mutex_lock(&dbs_data->mutex);for_each_cpu(j, policy->cpus) {struct cpu_dbs_common_info *j_cdbs =dbs_data->cdata->get_cpu_cdbs(j);j_cdbs->cpu = j;j_cdbs->cur_policy = policy;j_cdbs->prev_cpu_idle = get_cpu_idle_time(j,&j_cdbs->prev_cpu_wall, io_busy);if (ignore_nice)j_cdbs->prev_cpu_nice =kcpustat_cpu(j).cpustat[CPUTIME_NICE];mutex_init(&j_cdbs->timer_mutex);INIT_DEFERRABLE_WORK(&j_cdbs->work,dbs_data->cdata->gov_dbs_timer);}
首先,遍历使用该policy的所有的处于online状态的cpu,针对每一个cpu,做以下动作:
- 取出该cpu相关联的cpu_dbs_common_info结构指针,之前已经讨论过,governor定义了一个per_cpu变量来定义各个cpu所对应的cpu_dbs_common_info结构,通过common_dbs_data结构的回调函数可以获取该结构的指针。
- 初始化cpu_dbs_common_info结构的cpu,cur_policy,prev_cpu_idle,prev_cpu_wall,prev_cpu_nice字段,其中,prev_cpu_idle,prev_cpu_wall这两个字段会被以后的负载计算所使用。
- 为每个cpu初始化一个工作队列,工作队列的执行函数是common_dbs_data结构中的gov_dbs_timer字段所指向的回调函数,对于ondemand来说,该函数是:od_dbs_timer。这个工作队列会被按照设定好的采样率定期地被唤醒,进行cpu负载的统计工作。
然后,记录目前的时间戳,调度初始化好的工作队列在稍后某个时间点运行:
/* Initiate timer time stamp */cpu_cdbs->time_stamp = ktime_get();gov_queue_work(dbs_data, policy,delay_for_sampling_rate(sampling_rate), true);
下图表达了启动一个governor的过程:
图 4.1 启动一个governor
工作队列被调度执行后,会在工作队列的执行函数中进行cpu负载的统计工作,这个我们在下一节中讨论。
5. 系统负载的检测
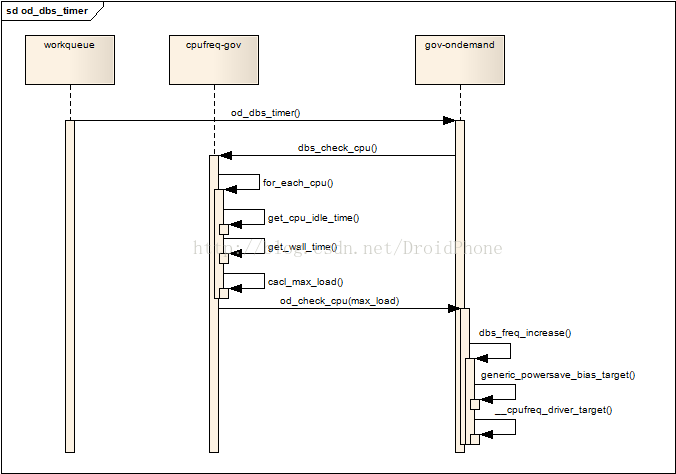
上一节我们提到,核心层启动一个governor后,会在每个使用该governor的cpu上建立一个工作队列,工作队列的执行函数是在common_dbs_data中gov_dbs_timer字段所指向的函数,理所当然,该函数由各个governor的具体代码来实现,对于ondemand governor,它的实现函数是od_dbs_timer。governor的公共层代码为我们提供了一个API:dbs_check_cpu,该API用来计算两个统计周期期间某个cpu的负载情况,我们先分析一下dbs_check_cpu:
void dbs_check_cpu(struct dbs_data *dbs_data, int cpu)
{struct cpu_dbs_common_info *cdbs = dbs_data->cdata->get_cpu_cdbs(cpu);......policy = cdbs->cur_policy;/* Get Absolute Load (in terms of freq for ondemand gov) */for_each_cpu(j, policy->cpus) {struct cpu_dbs_common_info *j_cdbs;......j_cdbs = dbs_data->cdata->get_cpu_cdbs(j);......cur_idle_time = get_cpu_idle_time(j, &cur_wall_time, io_busy);wall_time = (unsigned int)(cur_wall_time - j_cdbs->prev_cpu_wall);j_cdbs->prev_cpu_wall = cur_wall_time;idle_time = (unsigned int)(cur_idle_time - j_cdbs->prev_cpu_idle);j_cdbs->prev_cpu_idle = cur_idle_time;......load = 100 * (wall_time - idle_time) / wall_time;......load *= cur_freq; /* 实际的代码不是这样,为了简化讨论,精简为实际的计算逻辑*/if (load > max_load)max_load = load;}dbs_data->cdata->gov_check_cpu(cpu, max_load);
}
由代码可以看出,遍历该policy下每个online的cpu,取出该cpu对应的cpu_dbs_common_info结构,该结构中的prev_cpu_idle和prev_cpu_wall保存有上一次采样周期时记录的idle时间和运行时间,负载的计算其实很简单:
- idle_time = 本次idle时间 - 上次idle时间;
- wall_time = 本次总运行时间 - 上次总运行时间;
- 负载load = 100 * (wall_time - idle_time)/ wall_time;
- 把所有cpu中,负载最大值记入max_load中,作为选择频率的依据;
计算出最大负载max_load后,调用具体governor实现的gov_check_cpu回调函数,对于ondemand来说,该回调函数是:od_check_cpu,我们跟进去看看:
static void od_check_cpu(int cpu, unsigned int load_freq)
{struct od_cpu_dbs_info_s *dbs_info = &per_cpu(od_cpu_dbs_info, cpu);struct cpufreq_policy *policy = dbs_info->cdbs.cur_policy;struct dbs_data *dbs_data = policy->governor_data;struct od_dbs_tuners *od_tuners = dbs_data->tuners;dbs_info->freq_lo = 0;/* Check for frequency increase */if (load_freq > od_tuners->up_threshold * policy->cur) {/* If switching to max speed, apply sampling_down_factor */if (policy->cur < policy->max)dbs_info->rate_mult =od_tuners->sampling_down_factor;dbs_freq_increase(policy, policy->max);return;}
当负载比预设的阀值高时(od_tuners->up_threshold,默认值是95%),立刻选择该policy最大的工作频率作为接下来的工作频率。如果负载没有达到预设的阀值,但是当前频率已经是最低频率了,则什么都不做,直接返回:
if (policy->cur == policy->min)return;
运行到这里,cpu的频率可能已经在上面的过程中被设置为最大频率,实际上我们可能并不需要这么高的频率,所以接着判断,当负载低于另一个预设值时,这时需要计算一个合适于该负载的新频率:
if (load_freq < od_tuners->adj_up_threshold* policy->cur) {unsigned int freq_next;freq_next = load_freq / od_tuners->adj_up_threshold;/* No longer fully busy, reset rate_mult */dbs_info->rate_mult = 1;if (freq_next < policy->min)freq_next = policy->min;if (!od_tuners->powersave_bias) {__cpufreq_driver_target(policy, freq_next,CPUFREQ_RELATION_L);return;}freq_next = od_ops.powersave_bias_target(policy, freq_next,CPUFREQ_RELATION_L);__cpufreq_driver_target(policy, freq_next, CPUFREQ_RELATION_L);}
对于ondemand来说,因为传入的负载是乘上了当前频率后的归一化值,所以计算新频率时,直接用load_freq除以想要的负载即可。本来计算出来的频率直接通过__cpufreq_driver_target函数,交给cpufreq_driver调节频率即可,但是这里的处理考虑了powersave_bias的设置情况,当设置了powersave_bias时,表明我们为了进一步节省电力,我们希望在计算出来的新频率的基础上,再乘以一个powersave_bias设定的百分比,作为真正的运行频率,powersave_bias的值从0-1000,每一步代表0.1%。实际的情况比想象中稍微复杂一点,考虑到乘以一个powersave_bias后的新频率可能不在cpu所支持的频率表中,ondemand算法会在频率表中查找,分别找出最接近新频率的一个区间,由高低两个频率组成,低的频率记入od_cpu_dbs_info_s结构的freq_lo字段中,高的频率通过od_ops.powersave_bias_target回调返回。同时,od_ops.powersave_bias_target回调函数还计算出高低两个频率应该运行的时间,分别记入od_cpu_dbs_info_s结构的freq_hi_jiffies和freq_low_jiffies字段中。原则是,通过两个不同频率的运行时间的组合,使得综合结果接近我们想要的目标频率。详细的计算逻辑请参考函数:generic_powersave_bias_target。
讨论完上面两个函数,让我们回到本节的开头,负载的计算工作是在一个工作队列中发起的,前面说过,ondemand对应的工作队列的工作函数是od_dbs_timer,我们看看他的实现代码:
static void od_dbs_timer(struct work_struct *work)
{....../* Common NORMAL_SAMPLE setup */core_dbs_info->sample_type = OD_NORMAL_SAMPLE;if (sample_type == OD_SUB_SAMPLE) {delay = core_dbs_info->freq_lo_jiffies;__cpufreq_driver_target(core_dbs_info->cdbs.cur_policy,core_dbs_info->freq_lo, CPUFREQ_RELATION_H);} else {dbs_check_cpu(dbs_data, cpu);if (core_dbs_info->freq_lo) {/* Setup timer for SUB_SAMPLE */core_dbs_info->sample_type = OD_SUB_SAMPLE;delay = core_dbs_info->freq_hi_jiffies;}}max_delay:if (!delay)delay = delay_for_sampling_rate(od_tuners->sampling_rate* core_dbs_info->rate_mult);gov_queue_work(dbs_data, dbs_info->cdbs.cur_policy, delay, modify_all);mutex_unlock(&core_dbs_info->cdbs.timer_mutex);
}
如果sample_type是OD_SUB_SAMPLE时,表明上一次采样时,需要用高低两个频率来模拟实际的目标频率中的第二步:需要运行freq_lo,并且持续时间为freq_lo_jiffies。否则,调用公共层计算负载的API:dbs_check_cpu,开始一次新的采样,当powersave_bias没有设置时,该函数返回前,所需要的新的目标频率会被设置,考虑到powersave_bias的设置情况,判断一下如果freq_lo被设置,说明需要用高低两个频率来模拟实际的目标频率,高频率已经在dbs_check_cpu返回前被设置(实际的设置工作是在od_check_cpu中),所以把sample_type设置为OD_SUB_SAMPLE,以便下一次运行工作函数进行采样时可以设置低频率运行。最后,调度工作队列在下一个采样时刻再次运行,这样,cpu的工作频率实现了在每个采样周期,根据实际的负载情况,动态地设定合适的工作频率进行运行,既满足了性能的需求,也降低了系统的功耗,达到了cpufreq系统的最终目的,整个流程可以参考下图:
图 5.1 负载计算和频率选择
更多资料
5种Governors说明
1.Performance governor: Highest frequency
- 设置当前处理的频率到最高频率,后一直保持在这个频率
- 这个Governors目标就是让系统输出最高performance
2.Powersave Governor:Lowest Frequency
- 设置当前处理器频率在最低的频率,然后保持在这一频率
- 目标就是设置当设置当前处理器的频率在最低的频率,不管系统有多忙都不提高处理器频率。
- 这个Governor看着会省电,但实际并不会省。因为performance降低,处理task时间变长,所以相比其他,其进入睡眠的时间也最慢
3.Userspace governor: Manual frequencies
- 允许用户手动选择一组频率
- 这种模式通常与运行在userspace的daemon进程配合,去控制处理器频率
4.Ondemand governor: Frequency change based on processor use
- 在2.6.10内核开始使用,这也是第一个根据cpu使用状况来动态调整cpu频率的governor
- Ondemand governor会检查当前cpu使用情况,如果其load超过某一阈值(threshold),就会把当前cpu频率设定到最高的频率。然后发现load低于阈值就会逐步降低cpu频率。
5.Conservative governor: A more gradual ondemand
- 这个governor基于ondemand governor,从2.6.12内核开始导入
- 它会检查cpu load高于或者低于某一阈值,如果cpu load比阈值高,则逐步提高cpu频率,如果发现cpu load比阈值低,则逐步减小cpu频率
6.interactive governor : 看后面具体的介绍
详细介绍governor
CPU Load计算方法:
load_freq = load * current frequency
if (load_freq > (up_threshold * current frequency)) next_freq = max_frequency (CPUFREQ_RELATION_H)
if (load_freq < ((up_threshold - down_differential) * current frequency))next_freq = load_freq / (up_threshold - down_differential) (CPUFREQ_RELATION_L)
Ex) if load=30, current frequency=800MHz
next_freq= (30 * 800MHz) / (80 - 10) = 342MHz
CPUFREQ_RELATION_L means higher than or equal target frequency
Select 500MHz
1. Ondemand governor
- 如果cpu load超过某一阈值(up_threashould),ondemand governor会把cpu频率提高到最高(scaling_max_freq)。up_threshold的默认值为80.
- 如果cpu load低于up_threshold,ondemand governor会把cpu频率降低一档。最低可以到scaling_min_freq。
- 每个sampling_rate(默认40ms),每个cpu load都会被重新计算
- ignore_nice: 有正数nice值的cpu的load,将不会被计入到整个cpu load当中去。
- powersave_bias: 有些更强调省电的场景下,设置这个值(0.1~100%)可以减小cpu频率以达到省电的目的。
2. Interactive governor
- Designed for latency-sensitive, interactive workloads
- It is more aggressive about scaling the CPU speed up in response to CPU-intensive activity.
- Instead of sampling the CPU at a specified rate, the interactive governor will check whether to scale the CPU frequency up soon after coming out of idle.
- min_sample_time: The minimum amount of time to spend at the current frequency before ramping down. This is to ensure that the governor has seen enough historic CPU load data to determine the appropriate workload. Default is 80000 us.
- go_maxspeed_load: The CPU load at which to ramp to max speed. Default is 85.
The relation between NO_HZ and timer used on CPUFREQ
- If NO_HZ is enabled, PERIODIC Timer(periodic tick, tick_sched_timer()) isn’t happened during IDLE state. But, If user registers ONESHOT Timer on each device, ONESHOT Timer is happened during IDLE state.
- If CPUFREQ governor uses the work-queue to check CPU load periodically, work-queue is executed during IDLE with NO_Hz. Because work-queue is not Timer.
cpufreq 五种模式和手动提升性能脚本
https://blog.csdn.net/melody157398/article/details/79481016
IBM 开发者网站
减少 Linux 电耗,第 1 部分 CPUfreq 子系统
https://www.ibm.com/developerworks/cn/linux/l-cpufreq-1/
减少 Linux 耗电,第 2 部分 一般设置和与调控器相关的设置
https://www.ibm.com/developerworks/cn/linux/l-cpufreq-2/
减少 Linux 耗电,第 3 部分 调优结果
https://www.ibm.com/developerworks/cn/linux/l-cpufreq-3/
内核代码网站
https://code.woboq.org/linux/linux/kernel/sched/cpufreq_schedutil.c.html
https://elixir.bootlin.com/linux/v4.9.152/source/kernel/sched


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话
2021-04-07 linux 开发板内存卡复制