Python基础复习(第一天)
变量
什么是变量?
变量就是可以变化的量,量指的是事物的状态,比如人的年龄、性别,游戏角色的等级、金钱等等
为什么要有变量?
程序执行的本质就是一系列状态的变化,变是程序执行的直接体现,所以我们需要有一种机制能够反映或者说是保存下来程序执行时状态,以及状态的变化。
怎么使用变量?
1.三大组成部分:变量名,赋值符号,变量值
2.命名规范:字母、数字、下划线,建议使用_配合命名(age_of_name)
3.变量名的第一个字符不能是数字,关键字不能使用
4.三大特性:id,type,value
基本数据类型
数字类型
int:用来记录人的年龄,出生年份,学生人数等整数相关的状态
float:用来记录人的身高,体重,薪资等小数相关的状态
字符串类型
""
''
''' '''
列表list
l1 = ['jason',18,'study',]
字典dict
d1 =
布尔值
True
False:None,0,''
垃圾回收机制(GC)
什么是GC
垃圾回收机制(简称GC)是Python解释器自带的一种机制,专门用来回收不可用的变量值所占用的内存空间
为什么要有GC
程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间如果不即使清理的话会导致内存使用殆尽(内存溢出),导致程序崩溃,因此管理内存是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来
GC原理
1.堆区与栈区:变量名与值内存地址的关联关系存放与栈区;变量值存放与堆区,内存管理回收的则是堆区的内容
2.直接引用与间接引用:直接指的是从栈区出发直接引用到的内存地址;间接值得是从栈区出发引用到堆区后,再通过及你不引用才能到达的内存地址
3.Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题,并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
4.标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除
5.分代指的是根据存活时间来为变量划分不同等级(也就是不同的代),回收依然是使用引用计数作为回收的依据
Python语法
与用户交互
input('请输入用户名:')
print()
格式化输出
"hello world{}".format('lili')
"hello world%s,%d" % ('lili',18)
运算符
+,-,,/
//,%,**
==,!=
+=,=,/=,-=
and,or,not
in,not in
链式赋值
x=y=z=10
交叉赋值
x,y = y,x
解压赋值
a,b = ['egon',18]
注意,上述解压赋值,等号左边的变量名个数必须与右面包含值的个数相同,否则会报错,但如果我们只想取头尾的几个值,可以用*_匹配
字符串、字典、元组、集合类型都支持解压赋值
流程控制之if
if a > b:
print(1)
elif a = b:
print(2)
else:
print(3)
循环结构之while
a = 0
res = 0
while a < 101:
res += a
a += 1
if a == 99:
break
if a == 80:
continue
针对嵌套多层的while循环,如果我们的目的很明确就是要在某一层直接退出所有层的循环,其实有一个窍门,就让所有while循环的条件都用同一个变量,该变量的初始值为True,一旦在某一层将该变量的值改成False,则所有层的循环都结束
在while循环的后面,我们可以跟else语句,当while 循环正常执行完并且中间没有被break 中止的话,就会执行else后面的语句,所以我们可以用else来验证,循环是否正常结束
循环结构之for,又叫迭代循环
for i in [1,2,3,4,5,6,7,8]:
print(i)
for i in range(1,10):
for j in range(1,i+1):
print("%s*%s=%s" %(i,j,i*j,end='')
print('')
基本数据类型及内置方法
数字类型
int
float
bin,oct,hex,int
字符串
str()
'hello world'[0]
'hello world'[0:5]
len()
strip('*')
split('//',2)
for line in 'hello world!':pirnt(line)
lower(),upper()
title(),capitalize(),swapcase()
startwith(),endwith()
join(),replace()
isdigit()
最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景,如果要判断中文数字或罗马数字,则需要用到isnumeric
列表list
l1 = [1,2,3,4,5,6,7,8]
l1[0:6:2]
len()
l1.append(9)
l1.extend([11,22,33]
l1.insert(2,333)
l1.pop()
del l1
l1.remove(2)
l1.reverse()
l1.sort()
for循环取值
l1[2::]
l1[::-1]
元组tuple
t1 = (1,2,3,4,5)
元组与列表类似,也是可以存多个任意类型的元素,不同之处在于元组的元素不能修改,即元组相当于不可变的列表,用于记录多个固定不允许修改的值,单纯用于取
字典dict
d1 = {'key':value,……}
d2 = dict(name='egon',age=18……)
{}.fromkeys(('name','age','hobby'),None)
d1['key']
对于赋值操作,如果key原先不存在于字典,则会新增key:value
对于赋值操作,如果key原先存在于字典,则会修改对应value的值
len()
pop('key'),popitem()
d1.keys(),d1.values()
d1.items()
默认遍历的是字典的key
d1.get('key'),这样不会报错
update(),用新字典更新旧字典,有则修改,无则添加
setdefault(),key不存在则新增键值对,并将新增的value返回;key存在则不做任何修改,并返回已存在key对应的value值
集合
s = {1,2,3,4,5}
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序
合集/并集(|)
交集(&)
差集(-)
对称差集(^)
只能针对不可变类型
集合本身是无序的,去重之后无法保留原来的顺序
可变类型与不可变类型
可变数据类型:值发生改变时,内存地址不变,即id不变,证明在改变原值
不可变类型:值发生改变时,内存地址也发生改变,即id也变,证明是没有在改变原值,是产生了新的值
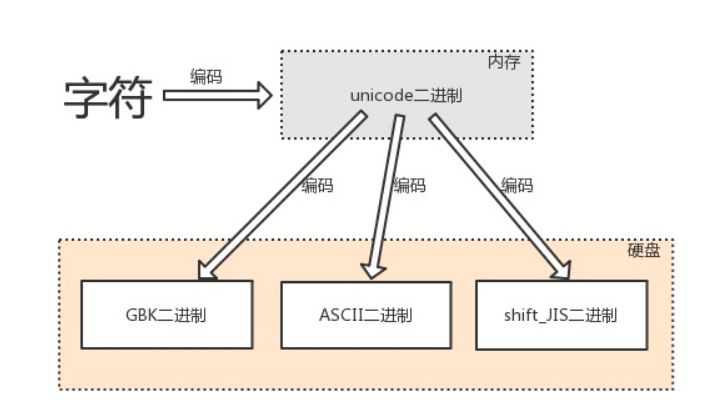
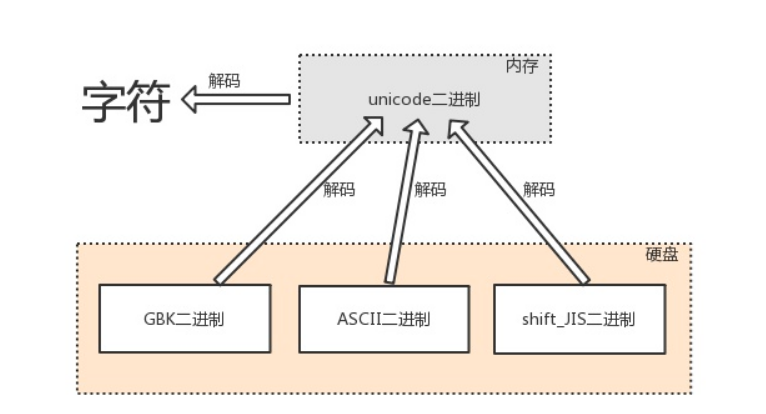
字符编码
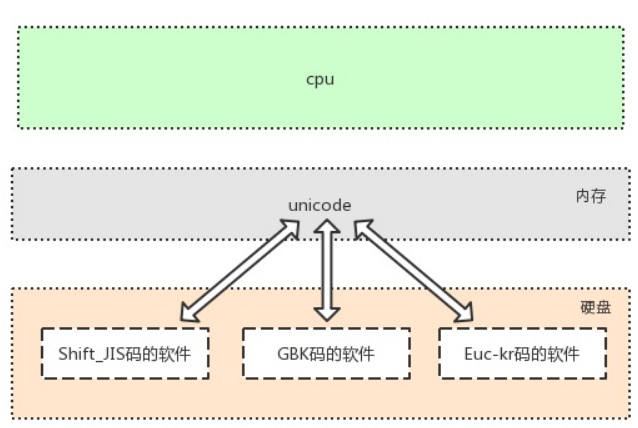
三大核心硬件
1、软件运行前,软件的代码及其相关数据都是存放于硬盘中的
2、任何软件的启动都是将数据从硬盘中读入内存,然后cpu从内存中取出指令并执行
3、软件运行过程中产生的数据最先都是存放于内存中的,若想永久保存软件产生的数据,则需要将数据由内存写入硬盘
文件处理
with open(url,mode='',encoding='uft8') as f:
f.read()
f.write('1212121')
mode:r,w,a
r只读模式: 在文件不存在时则报错,文件存在文件内指针直接跳到文件开头
w只写模式: 在文件不存在时会创建空文档,文件存在会清空文件,文件指针跑到文件开头
w模式:在文件不关闭的情况下,连续的写入,后写的内容一定跟在前写内容的后面
w模式:如果重新以w模式打开文件,则会清空文件内容
a只追加写模式: 在文件不存在时会创建空文档,文件存在会将文件指针直接移动到文件末尾
读写内容的模式:t,b
t(默认的):文本模式,必须指定encoding参数
b(二进制模式),一定不能指定encoding参数
操作文件的方法
f.read() # 读取所有内容,执行完该操作后,文件指针会移动到文件末尾
f.readline() # 读取一行内容,光标移动到第二行首部
f.readlines() # 读取每一行内容,存放于列表中
f.read()与f.readlines()都是将内容一次性读入内容,如果内容过大会导致内存溢出,若还想将内容全读入内存,则必须分多次读入
f.readable() # 文件是否可读
f.writable() # 文件是否可读
f.closed # 文件是否关闭
f.encoding # 如果文件打开模式为b,则没有该属性
f.flush() # 立刻将文件内容从内存刷到硬盘
f.name
主动控制文件指针的移动
f.seek(指针移动的字节数,模式控制):
模式控制:
0: 默认的模式,该模式代表指针移动的字节数是以文件开头为参照的
1: 该模式代表指针移动的字节数是以当前所在的位置为参照的
2: 该模式代表指针移动的字节数是以文件末尾的位置为参照的
强调:其中0模式可以在t或者b模式使用,而1跟2模式只能在b模式下用
