蓝帽杯2020-Misc-熟悉的解密
蓝帽杯2020-MISC-熟悉的解密
前言
怎么说呢,我觉得对我一个不懂加解密算法的人来说,应该算是Crypto,不过对于专业人员来说可能TEA、AES、RSA、LCG这种应该都比较ez(like 编码?)
一、题目
IyEvdXNyL2Jpbi9lbnYgcHl0aG9uDT==
Iy0qLSBjb2Rpbmc6IHV0Zi04IC0qLQ0=
aW1wb3J0IHN5cw3=
ZnJvbSBjdHlwZXMgaW1wb3J0ICoN
ZGVmIGVuY2lwaGVyKHYsIGspOg1=
ICAgIHkgPSBjX3VpbnQzMih2WzBdKQ2=
ICAgIHogPSBjX3VpbnQzMih2WzFdKQ0=
ICAgIHN1bSA9IGNfdWludDMyKDApDc==
ICAgIGRlbHRhID0gMHg5ZTM3NzliOQ3=
ICAgIG4gPSAzMg0=
ICAgIHcgPSBbMCwwXQ0=
ICAgIHdoaWxlKG4+MCk6DT==
ICAgICAgICBzdW0udmFsdWUgKz0gZGVsdGEN
ICAgICAgICB5LnZhbHVlICs9ICggei52YWx1ZSA8PCA0ICkgKyBrWzBdIF4gei52YWx1ZSArIHN1bS52YWx1ZSBeICggei52YWx1ZSA+PiA1ICkgKyBrWzFdDT==
ICAgICAgICB6LnZhbHVlICs9ICggeS52YWx1ZSA8PCA0ICkgKyBrWzJdIF4geS52YWx1ZSArIHN1bS52YWx1ZSBeICggeS52YWx1ZSA+PiA1ICkgKyBrWzNdDT==
ICAgICAgICBuIC09IDEN
ICAgIHdbMF0gPSB5LnZhbHVlDS==
ICAgIHdbMV0gPSB6LnZhbHVlDW==
ICAgIHJldHVybiB3DW==
ZGVmIGVuY29kZXN0cih0ZXh0LCBrZXkpOg1=
ICAgIGNpcGhlckxpc3QgPSBbXQ2=
ICAgIHRleHQgKz0gKDggLSBsZW4odGV4dCkgJSA4KSAqIGNocigwKQ0=
ICAgIGZvciBpIGluIHJhbmdlKGxlbih0ZXh0KS84KToN
ICAgICAgICB2MSA9IDAN
ICAgICAgICB2MiA9IDAN
ICAgICAgICBmb3IgaiBpbiByYW5nZSg0KToN
ICAgICAgICAgICAgdjErPSBvcmQodGV4dFtpKjgral0pIDw8ICg0LWotMSkqOA1=
ICAgICAgICAgICAgdjIrPSBvcmQodGV4dFtpKjgrais0XSkgPDwgKDQtai0xKSo4DT==
ICAgICAgICBjaXBoZXJMaXN0LmFwcGVuZChlbmNpcGhlcihbdjEsdjJdLGtleSkpDX==
ICAgIHJldHVybiBjaXBoZXJMaXN0DX==
Dd==
aWYgX19uYW1lX18gPT0gIl9fbWFpbl9fIjoN
ICAgIGtleSA9IFsxMSwyMiwzMyw0NF0N
CWZsYWcgPSA/DQ==
ICAgIGNpcGhlciA9IGVuY29kZXN0cihmbGFnMSxrZXkpDQ==
CSNjaXBoZXIgPSBbWzQwMTgyODkyMzNMLCAyOTUwMzIwMTUxTF0sIFsxNzcxODI3NDc4TCwgNDkzOTgwODc2TF0sIFsxODYzMjg0ODc5TCwgMTEzNzc5NzU5OUxdLCBbMjc1OTcwMTUyNUwsIDM5NTc4ODUwNTVMXSwgWzI2MDA4NjY4MDVMLCA3ODg1MDcyNExdXQ0=
二、解题
1、解码
看着base,上cyberchef
base64成功,python源码
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import sys
from ctypes import *
def encipher(v, k):
y = c_uint32(v[0])
z = c_uint32(v[1])
sum = c_uint32(0)
delta = 0x9e3779b9
n = 32
w = [0,0]
while(n>0):
sum.value += delta
y.value += ( z.value << 4 ) + k[0] ^ z.value + sum.value ^ ( z.value >> 5 ) + k[1]
z.value += ( y.value << 4 ) + k[2] ^ y.value + sum.value ^ ( y.value >> 5 ) + k[3]
n -= 1
w[0] = y.value
w[1] = z.value
return w
def encodestr(text, key):
cipherList = []
text += (8 - len(text) % 8) * chr(0)
for i in range(len(text)/8):
v1 = 0
v2 = 0
for j in range(4):
v1+= ord(text[i*8+j]) << (4-j-1)*8
v2+= ord(text[i*8+j+4]) << (4-j-1)*8
cipherList.append(encipher([v1,v2],key))
return cipherList
if __name__ == "__main__":
key = [11,22,33,44]
flag = ? #"flag{57735e0c-6d02-11ea-8072-040e3c032fa7}" 放这里了,后面调试才看懂
cipher = encodestr(flag1,key)
#cipher = [[4018289233L, 2950320151L], [1771827478L, 493980876L], [1863284879L, 1137797599L], [2759701525L, 3957885055L], [2600866805L, 78850724L]]
2、加密解析
可以看到加密算法内外两层,将 flag 和 key 进行 encipher() 和 encodestr() 双重加密得到五组由两个整数组成的列表
(1)内层encipher()
TEA算法,主要依托黄金分割delta = 0x9e3779b9进行32层加密,每次加密key是(33-n)*delta这种(直到不满足n>0)
(2)外层encodestr()
将每次计算的一组数分别通过移位运算按照每8位进行分组排列拆分转换为字符
3、解密思路
(1)内层encipher()
TEA算法解密较为简单,整体算法结构基本不变
①将初始sum改为32*delta 即0xc6ef3720,循环处理方式改为递减
② [y,z]两组数改为迭减,计算顺序反向先计算z,再通过z计算y
③n改为递加
解密后得到5组数据
from ctypes import c_uint32
def decipher(v, k):
y = c_uint32(v[0])
z = c_uint32(v[1])
delta = 0x9e3779b9
sum = c_uint32(delta * 32) # This is the sum after 32 rounds of encryption
n = 32
w = [0, 0]
while n > 0:
z.value -= ((y.value << 4) + k[2]) ^ (y.value + sum.value) ^ ((y.value >> 5) + k[3])
y.value -= ((z.value << 4) + k[0]) ^ (z.value + sum.value) ^ ((z.value >> 5) + k[1])
sum.value -= delta
n -= 1
w[0] = y.value
w[1] = z.value
return w
# 本题用法
vs = [[4018289233, 2950320151], [1771827478, 493980876], [1863284879, 1137797599], [2759701525, 3957885055], [2600866805,78850724]] # 加密后的数据
for v in vs:
k = [11, 22, 33, 44] # 密钥
decrypted = decipher(v, k)
print(decrypted) # 解密后的数据
#[1718378855, 2067085111]
#[859137328, 1663907428]
#[808594737, 828727597]
#[942683954, 758133808]
#[1694498816, 0]
(2)外层encodestr()
外层相对简单,进行位移操作每次取8位转换成字符
#方法一
List = [
[1718378855, 2067085111],
[859137328, 1663907428],
[808594737, 828727597],
[942683954, 758133808],
[1694498816, 0]
]
def int_to_string(val):
result = ""
for j in range(4):
char = chr(val >> (8 * (3 - j)) & 0xFF)
result += char
val -= (val >> (8 * (3 - j))) << (8 * (3 - j))
return result
def main():
for i in range(5):
now = List[i][0]
print(int_to_string(now), end='')
now = List[i][1]
print(int_to_string(now), end='')
if __name__ == "__main__":
main()

当然也可以直接调n2s实现,除了格式需要调整,没啥异常
from libnum import n2s
List = [
[1718378855, 2067085111],
[859137328, 1663907428],
[808594737, 828727597],
[942683954, 758133808],
[1694498816, 0]
]
for i in range(4):
x,y = List[i]
print(n2s(x), n2s(y))

4、base64隐写
🔥这个是第一次了解,做个记录,师傅写的很详细
https://www.tr0y.wang/2017/06/14/Base64steg/#%E8%A7%A3%E5%AF%86
(1)原理
简单来说就是base64补位的==位置存在不大于2*2的隐写空间

引用原文:
例如:直接解密
VHIweQ==与VHIweR==',得到的结果都是'Tr0y'注意红色的 0,我们在解码的时候将其丢弃了,所以这里的值不会影响解码. 所以我们可以在这进行隐写。为什么等号的那部分 0 不能用于隐写?因为修改那里的二进制值会导致等号数量变化,解码的第 1 步会受影响。自然也就破坏了源字符串。而红色部分的 0 是作为最后一个字符二进制的组成部分,还原时只用到了最后一个字符二进制的前部分,后面的部分就不会影响还原。
唯一的影响就是最后一个字符会变化。
如果你直接解密
VHIweQ==与VHIweR==',得到的结果都是'Tr0y'。当然,一行 base64 顶多能有 2 个等号,也就是有
2*2位的可隐写位。所以我们得弄很多行,才能隐藏一个字符串,这也是为什么题目给了一大段 base64 的原因。接下来,把要隐藏的 flag 转为 8 位二进制,塞进去就行了。
也有简单的判断方法,比如出现大段base64密文,同时cyberchef自动解密时,整段复制进去无法自动解密,但手动拖入base64仍可成功解密,此时就可以测试base64隐写


(2)解密
#加密
# -*- coding: cp936 -*-
import base64
flag = 'Tr0y{Base64isF4n}' #flag
bin_str = ''.join([bin(ord(c)).replace('0b', '').zfill(8) for c in flag])
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('0.txt', 'rb') as f0, open('1.txt', 'wb') as f1: #'0.txt'是明文, '1.txt'用于存放隐写后的 base64
for line in f0.readlines():
rowstr = base64.b64encode(line.replace('\n', ''))
equalnum = rowstr.count('=')
if equalnum and len(bin_str):
offset = int('0b'+bin_str[:equalnum * 2], 2)
char = rowstr[len(rowstr) - equalnum - 1]
rowstr = rowstr.replace(char, base64chars[base64chars.index(char) + offset])
bin_str = bin_str[equalnum*2:]
f1.write(rowstr + '\n')
#解密
import base64
b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('1.txt', 'rb') as f:
flag = ''
bin_str = ''
for line in f.readlines():
stegb64 = str(line, "utf-8").strip("\n")
rowb64 = str(base64.b64encode(base64.b64decode(stegb64)), "utf-8").strip("\n")
offset = abs(b64chars.index(stegb64.replace('=','')[-1]) - b64chars.index(rowb64.replace('=','')[-1]))
equalnum = stegb64.count('=') #no equalnum no offset
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
print([chr(int(bin_str[i:i + 8], 2)) for i in range(0, len(bin_str), 8)])
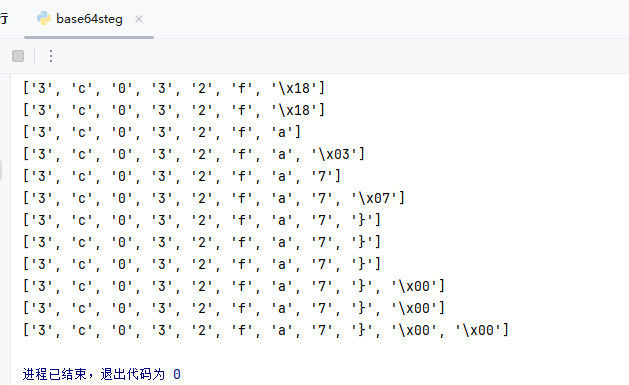
补充到解密出来的第一段flag后面就行(见加密代码内flag注释),不再说明了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?