Flask 03
Flask 框架03
蓝图的使用(blueprint )
作用:
平时我们在开发一个项目的时候,本就是耗费时间和精力,如果我们将所有的Flask请求方法都写在一个同一个文件下,会非常不便于我们对于代码的管理和后期功能代码的添加,这样会使得我们对代码的维护性变得困难。
这时候我们就可以使用蓝图来解决这个问题,蓝图对于视图方法模块化、大项目协同开发过程中的一个很好的工具.
蓝图的使用步骤:
-第一步:导入蓝图
from flask import Blueprint
-第二步:实例化得到蓝图对象
us=Blueprint('user',__name__)
-第三步:在app中注册蓝图
app.register_blueprint(us)
-第四步:在不同的views.py中使用蓝图注册路由
@us.router('/login')
-补充:蓝图可以有自己的静态文件和模板
-补充:注册蓝图时,可以使用前缀,必须以/ 开头
# 使用蓝图,划分大型项目目录 多个app,像django一样
big_blueprint # 项目名
-src # 核心文件
-admin # admin的app
-static # 静态文件
-1.jpg # 图片
-templates # 模板文件目录
-admin_home.html # 模板文件
-__init__.py # 包
-models.py # 表模型
-views.py # 视图函数
-home # home app
-order # orderapp
-__init__.py # 包
-settings.py # 配置文件
-manage.py # 启动文件
g对象
g对象是什么?
-它是global的缩写,在python中是以个关键字,不能以关键字最为变量名
-g对象,在整个请求的全局都可以放值,可以取值
-它是一个全局变量,可以在任意的位置导入使用即可
- 它为什么不学django使用request做为上下文管理呢?
-因为使用request,可能会造成request的数据污染,会不小心改了request的属性,但是自己不知道
-建议使用g是因为它是空的。放入之后在当次请求中是全局优先
# 之后想在当次的请求中,放入一些数据,在后面使用,就可以使用g对象。
g对象和session的区别?
-g对象只针对当次请求
-session 针对与多次请求
from flask import Flask, g, request
app = Flask(__name__)
app.debug = True
@app.before_request
def before():
if 'home' in request.path:
g.xx = 'xx'
def add(a, b):
# print('---',g.name)
print('---', request.name)
return a + b
@app.route('/')
def index():
print(g.xx)
name = request.args.get('name')
# g.name = name
request.method = name
res = add(1, 2)
print(res)
return 'index'
@app.route('/home')
def home():
print(g.xx)
return 'index'
if __name__ == '__main__':
app.run()
数据库链接池
# 在flask 中操作mysql
- 使用pymysql
-在视图函数中,创建pymysql的链接,进行查数据,查完返回给前端
-那么问题来了,来了一个请求,创建一个链接,请求结束,链接关闭(django就是这样)
-我们将链接对象做成全局的,在视图函数中,使用全局的链接,查询,返还给前端
- 多个人查询,会出现一个问题,(数据错乱)如下图。
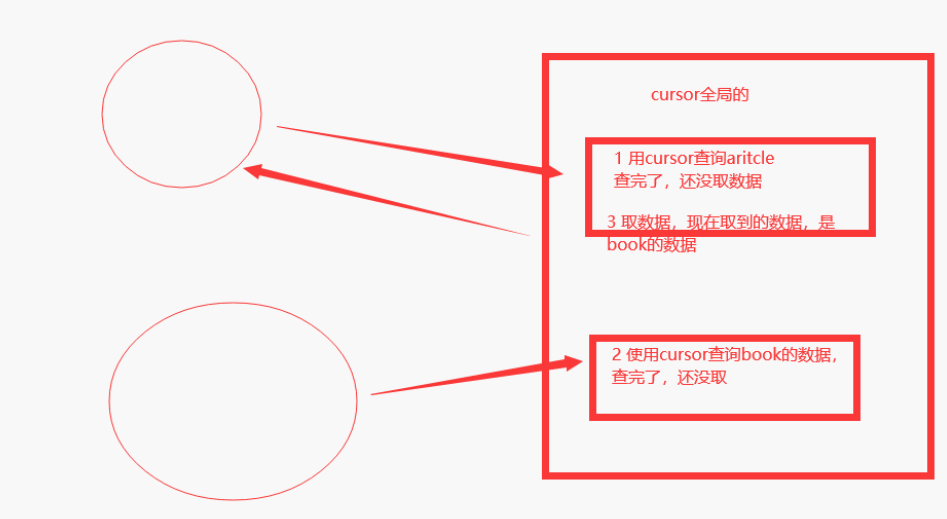
解决方式:
-创建一个数据链接池
-创建一个全局的连接诶池
--每次进入视图函数,就从池中取一个连接使用,使用完成后放回到池中,只要控制好池的大小,就能控制mysql的链接数
# 使用第三方数据库链接池的步骤:
1.安装 pip install dbutils
2.使用:实例化得到一个池对象
3.在视图函数中导入使用
conn=pool.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute('select id,title,author_img from aritcle limit 2')
res = cursor.fetchall()
# 带池的代码
@app.route('/article_pool')
def article_pool():
conn = pool.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute('select id,title,author_img from aritcle limit 2')
res = cursor.fetchall()
print(res)
return jsonify(res)
# 不带池的代码
@app.route('/article')
def article():
conn = pymysql.connect(user='root',
password="",
host='127.0.0.1',
database='cnblogs',
port=3306)
cursor = conn.cursor(pymysql.cursors.DictCursor)
time.sleep(random.randint(1,3))
cursor.execute('select id,title,author_img from aritcle limit 2')
res = cursor.fetchall()
cursor.close()
conn.close()
return jsonify(res)
# 压力测试代码
from threading import Thread
import requests
def task():
res = requests.get('http://127.0.0.1:5000/article_pool')
print(len(res.text))
if __name__ == '__main__':
for i in range(500):
t = Thread(target=task)
t.start()
## 效果是:
使用池的连接数明显小
不使用池连接数明显很大
查看数据库链接数指令
show status like 'Threads%'
