网络爬虫
网络爬虫
爬虫介绍:
什么是爬虫?
- 网络爬虫又称之为:网络蜘蛛,它是一中按照一定的规则自动的抓取网络上(万维网)的信息的程序或者脚本。
- 换句话来说,它可以根据网页的链接地址自动捕获到网页的内容。
- 如果将互联网比作是一个大的蜘蛛网,它就是一个个网页组成的,网络蜘蛛就能在这一片网上获取到想要的页面内容。
- 重点:爬虫是一个模拟请求网站行为,并批量下载网站资源 的一种程序或自动化脚本
举个例子:
百度:
百度其实也就可以比作是一个大型爬虫
-百度爬虫一刻不停的脚互联网中爬取各个页面的数据,爬取到数据后将数据存放到自己的数据库中
-当我们在百度的搜索引擎上搜索信息时,百度通过自己的数据库查询关键字,然后返回给我们。
-我们打开返回的页面,就会跳转到那个真正的网站上。学习流程
-
模拟发送http 请求
- requests 模块
- selenium
- 反爬:
封IP,IP代理,封账号,cookie池 -
解析数据:bs4
-
入库:mysql,redis ,文件
-
爬虫框架:scrapy
requests模块
模块介绍:
简介:
- requests 模块是 python 基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。Requests 的哲学是以 PEP 20 的习语为中心开发的,所以它比 urllib 更加 Pythoner
安装:
pip install requests爬虫案例:
# 导包
import requests
# step_1 : 指定url
url ='https://www.sogou.com/'
# step_2 : 发起请求:
# 使用get 方法发起get 请求, 该方法会返回一个响应对象。参数url 表示请求对应的url
response = requests.get ( url = url )
# step_3 : 获取响应数据:
# 通过调用响应对象的text 属性, 返回响应对象中存储的字符串形式的响应数据( 页面源码数据)
page_text = response . text
# step_4 : 持久化存储
with open ('sogou.html','w',encoding ='utf -8') as fp:
fp.write (page_text)
print ('爬取数据完毕! ! !')小知识:
http协议:
- http:超文本传输协议,是互联网上应用最为广泛的一支能够网络协议。所有的www 文件都必须要遵守这个标准,最早设计出http的目的就是为了提供一种发布和接受HTML页面的方法,http是一种基于 请求与响应的 模式、无状态的 应用层协议。 http协议采用URL作为网络资源的标识符
https协议:
- https(SSL/TLS):是计算机网络知识,主要是为了对HTTP协议传输的文本进行加密,提高安全性的一种协议
- http协议是明文传输,所以可能会产生中间人攻击(获取并篡改传输在客户端的信息不被人发觉),所以就有了https
URL:
- 统一资源定位符:是一种互联网上标准的资源地址。互联网上的每一个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该该怎么处理它
语法格式:
protocol://host[:port]/path/[?query]#fragment
http://www.itcast.cn/index.html?name=andy&age=18#link
requests请求携带参数:
import reqests
# 方式一:直接通过?拼接在路径上
res = requests.get('https://www.baidu.com/?name=xy&age=18')
# 方式二:使用params
res=requests.post('https://www.baidu.com/',params={'name':'fs','age':'18'})
print(res.text)
requests模块发送post请求
- 登录注册( 在web工程师看来POST 比 GET 更安全,url地址中不会暴露用户的账号密码等信息)
- 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
post 请求的方法:
response = requests.post(url, data)
data参数接收一个字典
requests模块发送post请求函数的其它参数和发送get请求的参数完全一致携带请求头
反爬的措施之一就是在请求头
- 请求头中会有一个很重要的参数 User-Agent
- headers 的参数接受是 k:Y 的字典形式
- 请求字段名为key ,字段对应的值是value
- 从浏览器中复制User-Agent,构造headers字典
import requests
url = 'https://www.baidu.com'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
print(response.content)
# 打印请求头信息
print(response.request.headers)
headers参数中携带cookie
- 网站通常会利用请求头中的cookie字段来做用户的访问状态的保持,那么我们也可以在请求头的参数中加入Cookie,模拟普通用户发送请求
# 在浏览器中复制需要的字段构造字典;
# 构造请求头字典
headers = {
# 从浏览器中复制过来的User-Agent
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
# 从浏览器中复制过来的Cookie
'Cookie': '这里是复制过来的cookie字符串'
}
我们在发送请求的时候还能在请求头中携带编码格式
headers={
'content-type':'application/json'
}cookies参数:
cookies参数形式:
{"cookie的name":"cookie的value"}
该字典对应请求头中Cookie字符串,以分号、空格分割每一对字典键值对使用方法:
注意:cookie一般是有过期时间的,一旦过期的话是需要重新获取的
1.cookies参数使用
res=requests.get(url,cookies)
2.将cookies字符串转换成cookies参数所需要的字典
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
3.Cookiejar对象代码:
import requests
url = 'https://github.com/USER_NAME'
# 构造请求头字典
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'
}
# 构造cookies字典
cookies_str = '从浏览器中copy过来的cookies字符串'
cookies_dict = {cookie.split('=')[0]: cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers, cookies=cookies_dict)
print(resp.text)cookiejar对象转为cookie字典:
使用requests获取的resposne对象,具有cookies属性。该属性值是一个cookieJar类型,包含了对方服务器设置在本地的cookie。
1.转换方法
cookies_dict = requests.utils.dict_from_cookiejar(response.cookies)
2.其中response.cookies返回的就是cookieJar类型的对象
3.requests.utils.dict_from_cookiejar函数返回cookies字典
requests响应请求
编码解码:
- 在执行代码的时候我们会发现有的实行结果中会有很多的乱码的问题。
- 这是因为早期的编解码使用字符集不同早成的,,我们可以使用一下几种办法来解决中文的乱码问题:
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
# print(response.text)
print(response.content.decode()) # 注意这里!- requests.text是requests模块按照chardet模块推测出的编码字符集进行解码的结果
- 网络传输的字符串都是bytes类型的,所以response.text = response.content.decode('推测出的编码字符集')
两者的区别:
.text :
是字符串类型 str
.content
是bytes类型通过对response.content进行decode,来解决中文乱码
response.content.decode() # 默认utf-8
response.content.decode('GBK') # 编码格式响应的属性或方法:
response.url响应的url;有时候响应的url和请求的url并不一致
response.status_code 响应状态码
response.request.headers 响应对应的请求头
response.headers 响应头
response.request._cookies 响应对应请求的cookie;返回cookieJar类型
response.cookies 响应的cookie(经过了set-cookie动作;返回cookieJar类型
response.json()自动将json字符串类型的响应内容转换为python对象(dict or list)
代码:
# 导入模块
import requests
# 目标url
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
# print(response.text)
# print(response.content.decode()) # 注意这里!
print(response.url) # 打印响应的url
print(response.status_code) # 打印响应的状态码
print(response.request.headers) # 打印响应对象的请求头
print(response.headers) # 打印响应头
print(response.request._cookies) # 打印请求携带的cookies
print(response.cookies) # 打印响应中携带的cookies利用session进行状态保持
- requests模块中的session类能够自动处理发送的请求和获取响应过程中产生的cookie,进而达到保持保持的目的
- 自动处理cookie,是为了下一次请求会带上前一次的cookie
- 自动处理连续多次请求过程中产生的cookie
session = requests.session() # 实例化session对象
response = session.get(url, headers, ...)
response = session.post(url, data, ...)
import requests
import re
# 构造请求头字典
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
}
# 实例化session对象
session = requests.session()
# 访问登陆页获取登陆请求所需参数
response = session.get('https://github.com/login', headers=headers)
authenticity_token = re.search('name="authenticity_token" value="(.*?)" />', response.text).group(1) # 使用正则获取登陆请求所需参数
# 构造登陆请求参数字典
data = {
'commit': 'Sign in', # 固定值
'utf8': '✓', # 固定值
'authenticity_token': authenticity_token, # 该参数在登陆页的响应内容中
'login': input('输入github账号:'),
'password': input('输入github账号:')
}
# 发送登陆请求(无需关注本次请求的响应)
session.post('https://github.com/session', headers=headers, data=data)
# 打印需要登陆后才能访问的页面
response = session.get('https://github.com/1596930226', headers=headers)
print(response.text)超时参数 timeout 的使用
- 在爬虫中,一个请求很久没有结果,就会让一个项目的效率很低,此时就需要对请求进行强制的要求,让他必须在一定的时间内返回结果,负责就报错。
response = requests.get(url, timeout=3)
timeout =3 表示:发送请求之后,3秒中国返回响应,否则抛出异常小案例:
# 下载一个视屏
res = requests.get('https://vodpub6.v.news.cn/yqfbzx-original/20230310/c9f3a4a901bf45a4be9b2c942921ea69.mp4')
with open('视频.mp4', 'wb') as f:
for line in res.iter_content():
f.write(line)
异常处理
import requests
from requests.exceptions import * #可以查看requests.exceptions获取异常类型
try:
r=requests.get('http://www.baidu.com',timeout=0.00001)
except ReadTimeout:
print('===:')
# except ConnectionError: #网络不通
# print('-----')
# except Timeout:
# print('aaaaa')
except RequestException:
print('Error')上传文件
# 3 上传文件
import requests
files={'file':open('lucky.jpg')}
res=requests.post('https://www.pearvideo.com/',files=files)
print(res.status_code)解析json
# 发送http 请求,返回的数据会有xml 格式,也会有json格式
import requests
data={
'prod': 'pc_his',
'from': 'pc_web',
'json': '1',
'_t': '1678954931565',
'req': '2',
'csor': '0'
}
res=requests.post('https://www.baidu.com/',data=data)
# print(res.text)
print(type(res.json())) # 转成对象 字典对象
# 将json格式的数据转换成json好看的格式: json.cnssl认证(了解即可)
- SSL(Secure Socket Layer,安全套接字层):1994年为 Netscape 所研发,SSL 协议位于 TCP/IP 协议与各种应用层协议之间,为数据通讯提供安全支持。
- TLS(Transport Layer Security,传输层安全):其前身是 SSL,它最初的几个版本(SSL 1.0、SSL 2.0、SSL 3.0)由网景公司开发,1999年从 3.1 开始被 IETF 标准化并改名,发展至今已经有 TLS 1.0、TLS 1.1、TLS 1.2 三个版本。SSL3.0和TLS1.0由于存在安全漏洞,已经很少被使用到。TLS 1.3 改动会比较大,目前还在草案阶段,目前使用最广泛的是TLS 1.1、TLS 1.2
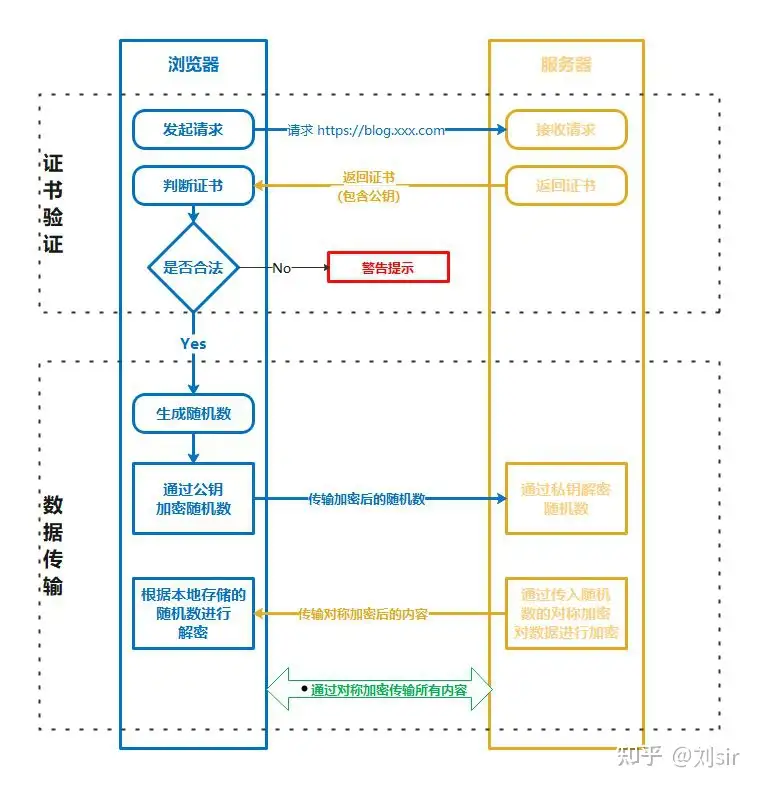
# 以后在报错的时候出现 ssl 。。。 就是证书有问题
# 不验证证书,出现了警告 返回结果为200
res=requests.get('https://www.12306.cn',verify=False)
print(res.status_code)
# 关闭了警告,直接返回的就是200 状态码
import requests
from requests.packages import urllib3
urllib3.disable_warnings() # 关闭警告
res=requests.get('https://www.12306.cn')
print(res.status_code)
# 自己携带证书 cert :一个是证书,一个是公钥
res=requests.get('https://www.12306.cn',cert=('/path/server.crt','/path/key'))
print(res.status_code)
proxy代理
- proxy代理参数通常指定的是代理IP,让代理IP对应的正向代理服务器转发我们发送的请求
- 代理IP指向的是一个代理服务器
- 代理服务器能够帮我们向目标服务器转发请求

使用:
如果我们使用爬虫,用的是我们自身的IP地址去访问,很有可能会别封禁IP地址,以后就不能访问了,所以我们使用到了代理IP
代理IP有两种:免费和收费
requests.post('https://www.cnblogs.com',proxies={'http':'地址+端口'}) 正向代理和反向代理的区别:
1.从发送请求的角度,来区分正向或反向代理
2.为浏览器或客户端(发送请求的一方)转发请求的,叫做正向代理,
浏览器知道最终处理请求的服务器的真实IP地址,例如VPN
3.不为浏览器或客户端(发送请求的一方)转发请求,而是为了最终处理请求的服务器转发请求的叫做反向代理
浏览器不知道服务器的不知道服务器的真实地址,例如Nginx代理IP(代理服务器)的分类
根据代理ip的匿名程度,代理IP可以分为下面三类:
1.透明代理(Transparent Proxy):透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Your IP
2.匿名代理(Anonymous Proxy):使用匿名代理,别人只能知道你用了代理,无法知道你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = proxy IP
HTTP_VIA = proxy IP
HTTP_X_FORWARDED_FOR = proxy IP
3.高匿代理(Elite proxy或High Anonymity Proxy):高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。毫无疑问使用高匿代理效果最好。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP
HTTP_VIA = not determined
HTTP_X_FORWARDED_FOR = not determined
2.根据网站所使用的协议不同,需要使用相应协议的代理服务。从代理服务请求使用的协议可以分为:
http代理:目标url为http协议
https代理:目标url为https协议
socks隧道代理(例如socks5代理)等:
socks 代理只是简单地传递数据包,不关心是何种应用协议(FTP、HTTP和HTTPS等)。
socks 代理比http、https代理耗时少。
socks 代理可以转发http和https的请求
proxies代理参数的使用
- 为了让服务器以为不是同一个客户端在发送请求
- 为了防止频繁向一个域名发送请求被封ip,所以我们需要使用代理IP
proxies 的形式:字典
proixes={
{'http':'地址+端口'}
}
PS:如果proixes字典中包含有多个键值对,发送请求时按照url地址的协议来选择使用相应的代理IP后端拿到的客户端IP地址:
http 请求头中,
X-Forwarded-For: client1, proxy1, proxy2, proxy3代理池搭建
-
了解到代理IP及其端口的价值后,我们知道必须拥有一定数目的可用IP才能够完成大量数据的爬取。
- 付费从代理网站上获得相应服务
- 搭建自身的免费IP代理池
-
自身搭建的IP代理池能够满足绝大部分需求了
倘若需要做专业性较强的爬虫,建议还是去找一些优质的网站购买稳定服务。
-
几个免费的代理IP地址:
https://www.kuaidaili.com/
http://www.66ip.cn/index.html
http://www.ip3366.net/
https://www.89ip.cn/index_1搭建步骤
1. https://github.com/jhao104/proxy_pool
python: 爬虫+ flask 写的
2.将项目克隆/下载下来
git clone https://github.com/jhao104/proxy_pool.git
3.使用pychram打开
4.安装依赖:pip install -r requirements.txt
5.修改配置文件(redis的地址)
6.启动爬虫程序
python proxyPool.py schedule
7.启动服务端
python proxyPool.py server
8.使用随机一个免费的代理IP
在地址栏中输入:代理IP