python(函数参数与名称空间)
今日内容概要
-
函数参数
-
名称空间与作用域
位置参数,关键字参数,默认参数,可变长参数,命名关键字参数 -
名字的查找顺序
今日内容详细

函数参数之位置参数
在调用函数时,python中必须将函数调用中每个实参都关联到函数的相应形参,最简单的关联方式是基于实参的顺序,这种关联方式被称为位置实参。
结构说明:
位置形参
函数定义阶段括号内从左往右依次填写的变量名
def func(a,b,c):pass (*)
* 补充:当子代码只有一行并且很简单的情况下,可以直接在冒号后面编写,可以不用换行
位置实参
函数调用阶段括号内从左往右依次填写的数据值
func1(1,2,3)
def func1(a,b):
print(a,b)
func1(1,2) #得按照位置一一对应传值
func1(1)# 少一个不行,会直接报错
func1(1,2,3) # 多一个也不行
func1(b=1,a=2)# 关键字传参(指名道姓的传,变量名是什么就只能传相应的值给该变量名)
func1(b=1,2)#关键字传参一定要跟在位置传参的后面,否则就会 报错
func1 (2,b=1)# 可以
func1(1,a=2,b=3)# 同一个形参在调用有的时候不能多次赋值 报错
name='Jason'
pwd = 123
func1(name,pwd)# 实参没有固定的定义,可以传数据值也可传绑定了数据值的变量名
func1(a=name,b=pwd) # 实参没有固定的定义,可以传数据值,也可以传绑定了数据值的变量名
关键字参数:
- 关键字实参是传递参数时使用“名称–值”对的方式,在实参中将名称和值关联起来。
- 关键字实参让开发者无需考虑函数调用中的实参顺序,清楚地指出了函数调用中各个值的用途。
重点: 越短的越简单的数据就越靠前 越长的越复杂的数据越靠后,但是下列这种情况下除外 同一个形参在调用的时候不能多次赋值

默认参数
在编写函数时给每个形参指定一个默认值,如果形参提供了实参就将指定的实参值;否则将使用形参的默认值。给形参指定默认值后,可在函数中省略相应的实参。使用默认值可简化函数的调用,还可以清楚的指出函数的典型用法。
def describe_student(person_name, student_age='18'):
"函数功能:显示学生的信息"
print("my name is ", person_name)
print(person_name + "is" + student_age + "years old")
describe_student('Jack')
describe_student('Jack', '18')
结果:
my name is Jack
Jackis18years old
my name is Jack
Jackis18years old
PS:要注意的是,设置默认参数时,必须参数在前,默认参数在后,否则python解释器就会出现报错。
默认参数的本质其实就是关键字形参,别名叫默认参数:提前就已经给了,用户可以传,也可不传。
'''
默认参数的定义也遵循短的简单的靠在前面,长的复杂的靠在后面
'''
def regist(name,age,gender='male'):
print(f"""
--------学员信息----------
姓名:{name}
年龄:{age}
性别:{gender}
-------------------------
""")
register('jack',18)
register('kevin',28)
register('kimi',28,'female')
register('kiki',24,gebder='female')
结果:
register('jack',18,'male')
register('kevin',28,'male')
register('kimi',28,'female')
register('kiki',24,'female')
可变长形参
*号在形参中:用于接收多余位置参数,组织成元组赋值给*号后面的变量名
def func1(*a);
print(a)
func1 ()#() 如果没有调用的参数就直接打印一个空元组括号
func1(1)#(1,)
func1(1,2) # (1,2,)
def func2(b,*a):
print(a,d)
func2()# 会报错,因为函数至少需要一个参数给到b
func2(1) # () 1
func2(1,2,3,4) # (2,3,4)1
**号在形参中:用于接收多余的关键字参数,并组织成字典的形式赋值给**号后面的变量名
def func3(**k)
print(k)
func3() # {} 实参没有值传给函数的情况下打印空字典
func3(a=1) #{'a':1}
func3(a=1 ,b=2,c=3) # {'a':1,'b':2,'c':3}
def func4(a,**k)
print(a,k)
func4() # 报错 函数至少需要一个参数给到a
func4(a=1) # 1 {}
func4(a=1, b=2, c=3) # 1 {'b': 2, 'c': 3}
func4(a=1, b=2, c=3, x='jason', y='kevin') # 1 {'b': 2, 'c': 3, 'x': 'jason', 'y': 'kevin'}
由于 *和**在函数的形参中使用的频率很高,后面跟的变量名推荐使用 :def index(*args,**kwargs):pass
*arge
**kwargs
def func5(*a, **k):
print(a, k)
func5() # () {}
func5(1, 2, 3) # (1, 2, 3) {}
func5(a=1, b=2, c=3) # () {'a': 1, 'b': 2, 'c': 3}
func5(1, 2, 3, a=1, b=2, c=3) # (1, 2, 3) {'a': 1, 'b': 2, 'c': 3}
def func5(n, *a, **k):
print(n,a, k)
func5() # 报错 函数至少需要一个参数给到n
func5(1, 2, 3) # 1 (2, 3) {}
func5(111,a=1, b=2, c=3) # 111 () {'a': 1, 'b': 2, 'c': 3}
func5(n=111,a=1, b=2, c=3) #111 () {'a': 1, 'b': 2, 'c': 3}
func5(a=1, b=2, c=3, n=111) #111 () {'a': 1, 'b': 2, 'c': 3}
func5(1, 2, 3, a=1, b=2, c=3) # 1 (2, 3) {'a': 1, 'b': 2, 'c': 3}
可变长实参
*在实参中:
类似于for循环,将所有循环遍历出来的数据按照位置参数一次性传给函数
def index(a, b, c):
print(a, b, c)
l1 = [11, 22, 33]
t1 = (33, 22, 11)
s1 = 'tom'
se = {123, 321, 222}
d1 = {'username': 'jason', 'pwd': 123, 'age': 18}
'''将列表中三个数据值取出来传给函数的三个形参'''
index(l1[0], l1[1], l1[2])
index(*l1) # index(11, 22, 33)
index(*t1) # index(33, 22, 11)
index(*s1) # index('t','o','m')
index(*se) # index(321 123 222)
index(*d1) # index('username','pwd','age')
**在实参中:
== 将字典打散成关键字参数的形式传递给函数==
def index(username, pwd, age):
print(username, pwd, age)
d1 = {'username': 'jason', 'pwd': 123, 'age': 18}
index(username=d1.get('username'), pwd=d1.get('pwd'), age=d1.get('age')) # jason 123 18
index(**d1) # jason 123 18
index(username='jason',pwd=123,age=18) # jason 123 18
def index(*args, **kwargs):
print(args) # (11, 22, 33, 44)
print(kwargs) # {}
index(*[11, 22, 33, 44])
结果:#(11, 22, 33, 44) {}
index(11, 22, 33, 44)
index(*(11, 22, 33, 44))
index(11, 22, 33, 44)

命名关键字参数(了解即可)
如果要限制关键字参数的名字,可以用命名关键字参数。和关键字参数**kw不同,如果没有可变参数,命名关键字参数就必须加一个“ ”号作为特殊分隔符。如果缺少“ ”,Python语言解释器将无法识别位置参数和命名关键字参数
形参必须按照关键字参数传值>>>:命名关键字参数
def index(name, *args, gender='male', **kwargs):
print(name, args, gender, kwargs)
index('jason',1,2,3,4,a=1,b=2)
结果:# jason (1, 2, 3, 4) male {'a': 1, 'b': 2}
index('jason', 1, 2, 3, 4, 'female', b=2)
结果: # jason (1, 2, 3, 4, 'female') male {'b': 2}
名称空间
什么是名称空间?
名称空间就是用来存储变量名与数据值绑定关系的地方(也可以简单的理解为就是存储变量名的地方)
名称空间有什么意义?
名称空间最大的作用就是防止名字重复造成的引用不当,
我们可以在全局名称空间中定义一个a = 1同时也可以在局部名称空间中定义一个a = 2,这两者之间是不会产生任何冲突的,
这就是名称空间最大的作用,防止名字重复造成的引用不当。
名称空间共有以下几种类型:
1:内置名称空间
作用范围:解释器级别的全局有效
解释器运行自动产生的,里面包含了很多的名字
用于存放各种内置函数(built-in functions)、内置模块(built-in modules),例如abs()就是内置函数,内置名称空间可以在Python任何一处使用;
eg:len print input
2.全局名称空间
作用范围:全局名称空间中的名字可以在同一个模块中任意处使用
py文件运行产生,里面存放的文件级别的名字,并且在py文件级别的全局有效
列如:在文件里开头定义的名字
eg:name = 'jaosn'
3.局部名称空间
作用范围:局部名称空间中的名字仅仅只能够在函数内部使用。
函数体代码\类体代码运行产生的空间
if name:
age = 18
while True:
gender = 'male'
def index():
pass
class MyClass(object):
pass
name\age\gender\index\MyClass
名称空间存活周期
==内置名称空间==
python解释器启动则创建 关闭则销毁 python解释器启动则创建 关闭则销毁**
==全局名称空间==
py文件执行则创建 运行结束则销毁
==局部名称空间==
函数体代码运行创建 函数体代码结束则销毁(类暂且不考虑)
名字的查找顺序
涉及到名字的查找,一定要先搞明白自己在哪个空间
1.当我们在局部名称空间的时候
局部名称空间>>>全局名称空间>>>内置名称空间
2.当我们在全局名称空间的时候
全局名称空间>>>内置名称空间
PS:其实名字的查找顺序是可以打破的
查找顺序案列
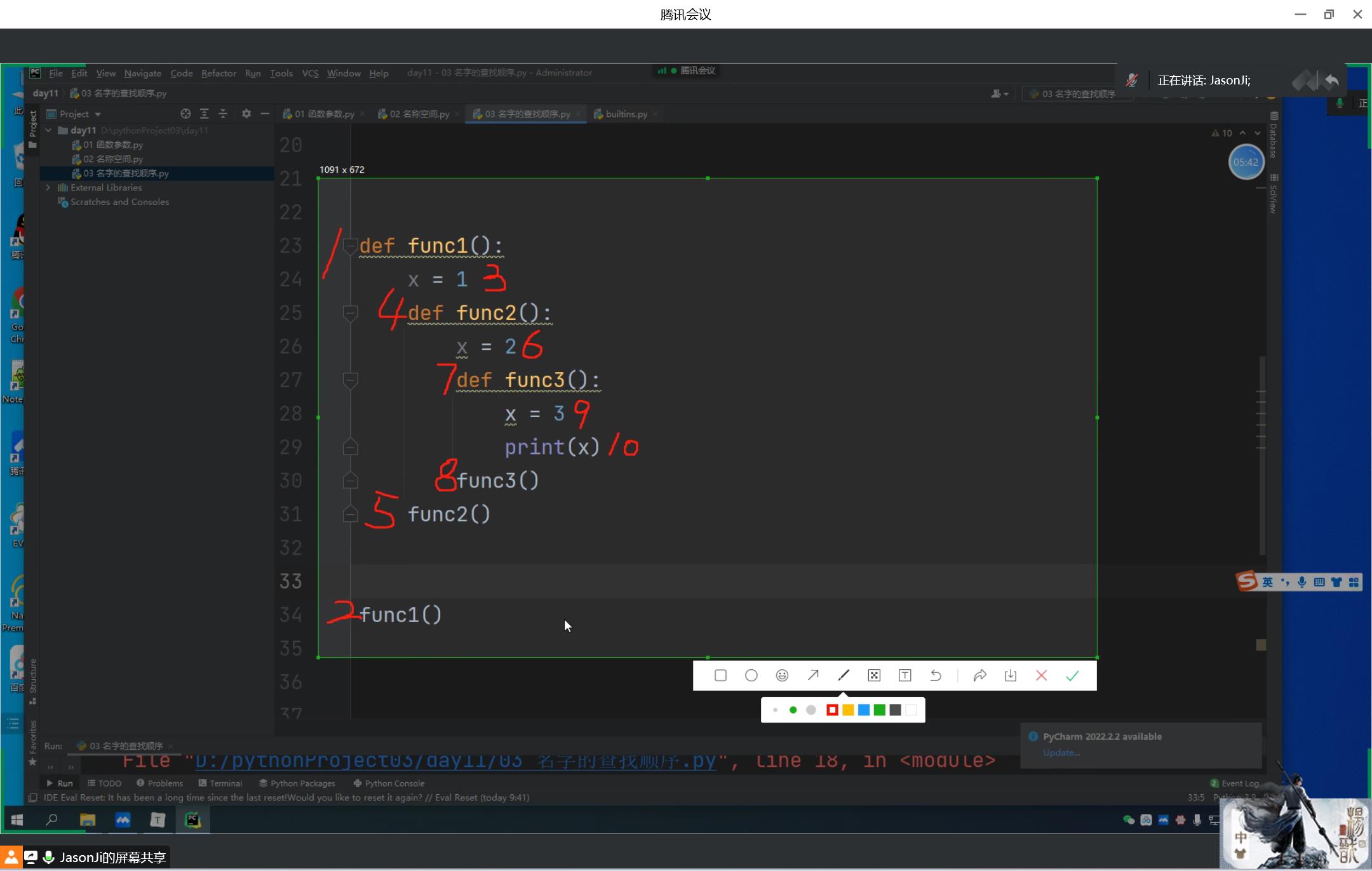
1.相互独立的局部名称空间默认不能够互相访问
def func1():
name = 'jason'
print(age)
def func2():
age = 18
print(name)
2.局部名称空间嵌套
先从自己的局部名称空间查找 之后由内而外依次查找
"""
函数体代码中名字的查找顺序在函数定义阶段就已经固定死了
x = '嘿嘿嘿'
def func1():
x = 1
def func2():
x = 2
def func3():
print(x)
x = 3
func3()
func2()
func1()
"""


