总结
总结
常量与变量
1、什么是变量
变量是 Python 程序用来保存计算结果的存储单元,为了方便访问这块存储单元,Python 给这块存储单元命名,该名称即为变量名,在 Python 中通过变量名来访问保存计算结果的存储单元
变量就是一个赋值语句的过程
通过给变量名赋值可以进行变量值的改变
变量名可以不变,变量值可以随时改变
一个拥有变量值的变量名就是变量
1.一旦看到赋值符号,那么一定要线看赋值符号的右侧
2.在内存空间中申请一块内存数据值
3.给数据绑定一个变量名
4.有了变量名了以后就可以通过变量名访问到该数据值
注意事项:
1。同一个数据值能绑定多个变量名
2.赋值符号也可能是变量名,如果是的话就应该先找该变量名绑定的数据值
3.一个变量名同一时间只能绑定一个数据值2.什么是常量
记录固定(可能不会经常发生改变)的事物状态数据类型
1.什么是数据类型?
在日常生活中数据的表现形式有多种多样,在程序中也是如此。
如何查看数据值的数据类型
tpye(数据值)\ tpye(变量名)
数据类型:
1.整型 int
2.浮点型 float
3.字符串类型 str
4.列表 list
5.字典 dict
6.布尔值 bOOl
7.元组 tuple
8.集合 set
9.文件类型
占位符:%s(可以给任意的数据占位),%d(只能给数字占位)
解压赋值:
==解压赋值在使用的时候 正常情况下需要保证左边的变量名与右边的数据值个数一致==
当需要解压的数据个数特别多 并且我们只需要使用其中的几个 那么可以打破上述的规则**
a, *b = name_list # *会自动接收多余的数据 组织成列表赋值给后面的变量名
当数据值不准备使用的时候 可以使用下划线作为变量名绑定
a, *_, c = name_list逻辑运算符: and or no
员运算符
判断一个个体在不在一个群体内 in
身份运算符
id() 返回一串数字 该数字可以看成是内存地址
is 判断内存地址是否相同
== 判断数据值是否相同
相同的内存地址,值肯定相同
值相同,内存地址不一定相同
垃圾回收机制:
1.引用计数你 (在Python中默认使用)
2.标记清除
3.分代回收流程控制
1.顺序结构
从上往下的依次执行,(最开始我们所编写的代码都是属于这种结构
2.分支结构
事物的执行会根据条件的变化而做出相应决策,不是固定的(随事物状态的变化而变化)
3.循环结构
事物的执行会根据某个条件而出现重复
PS:在学习控制流程的时候,建议做到代码和图形相结合流程控制必备知识
1.Python中使用代码的缩进来表示代码的从属关系,一般在看到代码的后面跟着( :)就需要缩进
分支结构:
if 关键字
1.单if分支结构
2.if...else...分支结构
3.if...elif...else分支结构

循环结构:
代码反复的执行
1.while 条件:
条件成立之后执行的子代码(循环体代码)
break 强行结束循环体
continue直接跳1到条件判断处
1.2.死循环
1.3.嵌套及全局标志位
2.for循环
1.擅长遍历取值
2.不需要结束条件,就会自动结束(遍历完成过后)
for循环的遍历类型:
目标可以是字符串、文件、range()函数或组合数据类型等;
循环变量用于保存本次循环中访问到的遍历结构中的元素;
for循环的循环次数取决于遍历的目标元素个数。
range方法:
range可以简单的理解为是帮我们产生一个内部有多个数字的数据
数据类型的内置方法
字符串:
1. 索引取值 (起始位置从0开始,超出范围的话直接报错)
2.切片操作 # (s1[1:5]) #ello
3.修改切片方向[间隔取值]
4.统计字符串中有多少个字符 len
5.移除字符串首位指定的字符 .strip
6.切割字符串中的指定字符 split(切割完的处理结果是列表)
7.字符串格式化输出 format
8.大小写相关 upper(转大写) lower(转小写)
9.判断字符串中是否是纯数字 isdigit()
10.字符串的拼接 join (拼接)
11.统计指定字符出现的次数 count
12.判断字符串的开头和结尾 startswith(开头) endswith(结尾)
13.index()索引
14.find ()索引不到值就默认返回-1列表:
1. 索引取值 (起始位置从0开始,超出范围的话直接报错)
2.切片操作 # (s1[1:5]) #ello
3.修改切片方向[间隔取值]
4.统计字符串中有多少个字符 len
5.列表添加数据值
5.1.append 尾部追加数据值 (不管添加多少的数据值,都会被列表当做一个数据添加进去)
5.2.任意位置插入 insert #(0,'jason')把索引0的位置让出来给jason
5.3.扩展列表(合并列表)extend
6.删除数据
6.1.通用的删除关键字del
6.2.remove() 直接删除 删除数据不存在返回 None
6.3.pop(索引) 弹出元素 用的最多(暂时弹出,但是还能付一个变量名能使用 (没有索引默认弹出最后一个)
7.排序
7.1..sort() # 默认是升序
7.2..sort(reverse=True) # 降序(从大到小)
8..统计列表中某个数据值 出现的次数 count()
9.clear 清空列表
10.颠倒列表的顺序 rever字典:
1.按k取值(不推荐使用)
2.按内置方法get取值(推荐使用)键不存在默认返回none,可以通过第二个参数自定义
3.修改值数据 键存在则修改对应的值
4.新增键值对 键不存在则新增键值对
5.删除数据 del pop
6.len 统计字典中键值对的个数
7.字典三剑客
7.1.keys() #一次性获取字典所有的键
7.2.values() #一次性获取字典所有的值
7.3.items() #一次性获取字典的键值对数据
8.fromkeys(['键','键','键'],值) # 快速生成值相同的字典
9.添加键值对 ['name'].append('jason')
10.setdefault()键存在则不修改,结果是键对应的值
键不存在则新增键值对,接过是新增的值
11..popitem() #弹出键值对,后进先出元组:
teple()支持for循环的数据类型都可以转成元组
1.索引取值
2.切片操作
3.间隔,方向
4.统计元组内数据的个数
5.统计元组内某个数据值出现的次数 len()
6.统计元组内指定数据值的索引值 index()
7.元组内如果只有一个数据值那么逗号不能少
8.元组内索引绑定的内存地址不能被修改(注意区分,可变与不可变)
9.元组不能新增或删除数据
集合:
1.类型转换
set()
1.1.集合内数据必须是不可变类型(整型,浮点型,字符串,元组)
1.2.集合内数据也是无序的,没有索引的概念
1.3.空集合的时候只能用set()函数定义,不能使用{}否则会被看成是字典
2.去重 去重无法保留原先数据的排列顺序
3.关系运算
3.1.交集:set1 & set2 单独
3.2.并集:set1 | set2 你我皆有
3.3.差集:set1 - set2表示属于set1但不属于set2的集合
3.4.对称集:set1 ^ 各自独有的
4.添加元素
4.1..add(x), 元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作
4.2..update( x ),x可以有多个,用逗号分开
可以添加元素,且参数可以是列表,元组,字典等
5.移除元素
5.1.remove( x ) 将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误
5.2.discard( x ) 另一种方法也是能移除集合中的元素,且如果元素不存在,但是不会发生错误
5.3.pop() 可以设置随机删除集合中的一个元素
6.清空集合 clear()字符编码
编码与解码:
编码:就是将人类的字符按照指定的编码编成计算机能够读懂的0101组成的二进数
语法 结构
字符串.encode()
解码:将计算机能够读懂的数据按照人类能够读懂的数据进行解密
语法结构
bytes数据类型。decode()
Python2默认的编码是ASCLL
1.文件头
2.字符串前面加u
python3默认编码是Unicode(万国码)文件操作
1.文件的概念
就是操作系统暴露给用户操作硬盘的快捷方式
2.代码打开文件的两种方式
方式一:
f = open(文件路径,读写模式,encoding ='utf8'
方式二:
with open(文件路径,读写模式,encoding ='utf8')
子代码块
3.with还支持一次性打开多个文件
with open ()as f1,open() as f2:
open 方法的第一参数是文件路径,并且撬棍和一些字母的组合会产生一些特殊的含义导致路径查找混乱,为了解决该问题可以在字符串的路径前面加字母r
PS:with上下文管理好处在于子代码运行结束自动调用close方法关闭资源文件读写模式:
1.'r' 只读模式:只能读不能写
1.1.文件路径不存在:会直接报错
1.2.文件路径存在:正常读取文件内容
2.'w' 只写模式:只能写不能看
2.1.文件路径不存在:自动创建
2.2.文件路径存在:先清空文件内容,然后再写进去
3.'a' 只追加模式:文件末尾添加数据
3.1.文件路径不存在:自动创建
3.2.文件路径存在:自动在末尾等待追加内容
文件的操作模式:
t 文本模式
默认的模式,我们上面所写的r w a 其实全称是rt wt at
1.只能操作文本文件
2.读写都是以字符作为单位
3.需要指定encoding参数,如果不知道则会采用计算机默认的编码
b 二进制模式(bytes模式)
不是默认的模式,需要自己指定 rb wb ab
1.可以操作任意类型的文件
2.读写都是以bytes为单位
3.不需要指定的encoding参数,因为它已经是二进制模式了,不需要编码
r+ : 可读、可写,文件不存在也会报错,写操作时会覆盖
w+ : 可读,可写,文件不存在先创建,会覆盖
a+ : 可读、可写,文件不存在先创建,不会覆盖,追加在末尾
而进制模式与文本模式针对文件路径是否存在的情况下规律是一样的文件的方法:
1.read() 一次性读取文件内容,并且光标停留在文件末尾
2.for循环
一行行读取文件内容,避免内存溢出现象的产生
3.readline() 一次只读一行内容
4.readlines() 一次性读取文件内容,会按照行数组织成列表的一个个数据值
5.readable() 判断文本是否具备读数据的能力
6.write() 写入数据
7.writeable() 判断文件是否具备写数据的能力
8.writelines()接受一个列表一次性将列表中所有的数据值写入
9.flush()将内存中文件数据立刻刷到硬盘, 相当于 Ctrl+s
光标的移动:
tell() # 返回光标距离文件开头产生的字节数
seek(0,0)
seek(offset, whence)
offset是位移量 以字节为单位
whence是模式 0 1 2
0是基于文件开头
文本和二进制模式都可以使用
1是基于当前位置
只有二进制模式可以使用
2是基于文件末尾
只有二进制模式可以使用
seek(0,2) # 这里的意思是光标移动的数量是0,起始位置是在末尾
time.sleep(0.5)#光标就停留0.5文件内容的修改:
修改文件内容的方式1;:覆盖写
修改文件内容的方式2:换地方写
“先在另一个地方写入内容,然后将源文件删除,将新文件命名成源文件(底层原理就是这样只是太快了,我们感觉不到)”
import os # 引入模块
os.remove('a.txt') # 删除a.txt
os.rename('.a.txt.swap', 'a.txt') # 重命名文件
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。函数
循环
相同的代码在相同的位置反复执行
函数
相同的代码在不同的位置反复执行(省代码)
而函数的存在就相当于是一个具备一些功能的工具
语法结构:
def 函数名(参数):
“函数注释”
函数体代码
return 返回值
1.def
定义函数关键字
2.函数名
命名方式与变量名相同
3.参数
可有可无,主要是使用函数的时候规定要不要外界传数据进来
4.函数注释
类似于使用函数的说明书
5.函数体代码
是整个函数的核心,这个主要就取决于程序员的编写
6.return
使用函数之后可以返回给使用者的数据,也是可有可无的,但是在执行函数的子代码的时候遇到return就会立即结束函数体代码
函数的定义与调用:
1.函数在定义阶段只检测语法,不执行代码
2.函数在调用阶段才会执行函数体代码 func()
3.函数必须先定义然后才能调用,函数名后的一对括号是不能省略的。在实际应用中,稍复杂的函数通常都会包含一个或多个参数。
4.函数定义使用关键字def函数调用使用:函数名加括号
如果有参数则需要在括号内按照相应的规则传递参数
函数的分类:
1.空函数
函数体代码为空,使用pass或者...进行补全
空函数主要用于前期的功能框架搭建
2.无参函数
定义函数的时候括号内没参数
3.有参函数
定义函数的时候括号内写参数,调用函数的时候括号传参数函数的返回值:
1.什么是返回值
函数的返回值是函数执行完成后,系统根据函数的具体定义返回给外部调用者的值。
2.如何获取返回值
变量名 赋值符号 函数的调用
res = func()# 先执行func函数,然后将返回值赋给变量res
3.函数返回值的多种情况
3.1 函数体代码中没有return关键字,就会返回默认值None
3.2.函数体代码有return,如果后面没有写任何的东西还是会返回默认值None
3.3函数体代码return,后面写什么就返回什么
3.4函数体代码有return并且后面有多个数据值,则自动组织成元组返回
3.5 函数体代码遇到return就会立刻结束函数参数:
在编程语言中,函数定义时用的是形式参数,调用时用的是实际参数,他们的功能就是数据的传输
形式参数
形式参数是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传入的参数。,简称“形参”
实际参数
在调用时传递给函数的参数。实际参数可以是常量、变量、表达式、函数等。无论实际参数是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。简称“实参”
在调用函数时,实参将赋值给形参。必须注意实参的个数、类型应与形参要一一对应,并且实参必须要有确定的值。形参的作用域一般仅限函数体内部,而实参的作用域根据实际设置而定。
形参与实参的关系
形参类似于变量名 在函数定义阶段可以随便写 最好见名知意
def register(name,pwd):
pass
实参类似于数据值 在函数调用阶段与形参临时绑定 函数运行结束立刻断开
register('jason',123) 形参name与jason绑定 形参pwd与123绑定位置参数:
在调用函数时,python中必须将函数调用中每个实参都关联到函数的相应形参,最简单的关联方式是基于实参的顺序,这种关联方式被称为位置实参。
位置形参
函数定义阶段括号内从左往右依次填写的变量名
位置实参
函数调用阶段括号内从左往右依次填写的数据值关键字参数:
1.关键字实参是传递参数时使用“名称–值”对的方式,在实参中将名称和值关联起来。
2.关键字实参让开发者无需考虑函数调用中的实参顺序,清楚地指出了函数调用中各个值的用途。
重点: 越短的越简单的数据就越靠前,越长的越复杂的数据越靠后,但是下列这种情况下除外,同一个形参在调用的时候不能多次赋值默认参数
在编写函数时给每个形参指定一个默认值,如果形参提供了实参就将指定的实参值;否则将使用形参的默认值。给形参指定默认值后,可在函数中省略相应的实参。使用默认值可简化函数的调用,还可以清楚的指出函数的典型用法
要注意的是,设置默认参数时,必须参数在前,默认参数在后,否则python解释器就会出现报错。
可变长形参
\*号在形参中:用于接收多余位置参数,组织成元组赋值给*号后面的变量名
**号在形参中:用于接收多余的关键字参数,并组织成字典的形式赋值给**号后面的变量名
*args **kwargs名称空间:
什么是名称空间?
名称空间就是用来存储变量名与数据值绑定关系的地方(也可以简单的理解为就是存储变量名的地方)
名称空间有什么意义?
名称空间最大的作用就是防止名字重复造成的引用不当,
我们可以在全局名称空间中定义一个a = 1同时也可以在局部名称空间中定义一个a = 2,这两者之间是不会产生任何冲突的,
这就是名称空间最大的作用,防止名字重复造成的引用不当。名称空间共有以下几种类型
1:内置名称空间
作用范围:解释器级别的全局有效 解释器运行自动产生的,里面包含了很多的名字
2.全局名称空间
作用范围:全局名称空间中的名字可以在同一个模块中任意处使用
3.局部名称空间
作用范围:局部名称空间中的名字仅仅只能够在函数内部使用。
名字的查找顺序
1.当我们在局部名称空间的时候
局部名称空间>>>全局名称空间>>>内置名称空间
2.当我们在全局名称空间的时候
全局名称空间>>>内置名称空间global nonlocal
global用于局部名称空间修改全局名称空间(改变的是不可变类型)
nonlocal内层局部名称空间该外层局部名称空间函数名的多种用法:
函数名其实绑定的也是一内存地址,只不过该地址里面存放的不是数据值而是一段代码,函数加括号就会找到该代码并执行
1.可以当做变量名赋值
2.可以当做函数的参数
3.可以当函数的返回值
4.可以当做容器类型(可以存放多个数据的数据类型)的数据闭包函数
定义: 在函数内部的函数,并且用到了外部函数名称空间中的名字闭包就是能够读取其他函数内部变量的函数
作用:保存外部函数的变量,不会随着外部函数调用完而销毁
闭包的形成条件:
1. 函数嵌套
2. 内部函数必须使用了外部函数的变量或者参数
3. 外部函数返回内部函数 这个使用了外部函数变量的内部函数称为闭包
1.定义在函数内容
闭包函数实际应用:其实就是另外一种函数体代码传参的方式。
2.用到外部函数名称空间中的名字
给函数体代码传参的方式:
1.代码里面缺什么变量名形参里面就补什么变量名
2.闭包函数装饰器:
概念:
1.不修改已有函数的源代码
2.不修改已有函数的调用方式
3.给已有函数增加额外的功能装饰器的本质:
并不是一门新的技术,而是由函数参数、名称空间、函数多种用法、闭包函数组合到一起的结果。实质上也是一个闭包函数,也就是说,他也是一个函数嵌套。
注意与闭包函数的区别:装饰器实质上是一个闭包函数,但是装饰器这个闭包函数。他的参数有且只有一个并且是函数类型的话,他才是装饰器,否则他就是闭包函数!
口诀:
对修改封闭 对扩展开放装饰器推导流程
1.直接在调用index函数的前后添加代码
2.index调用的地方比较多,代码不可能反复拷贝:这时候就用到了一个能相同的代码在不同的位置反复执行>>>==函数==
3.函数体代码写死了,只能统计index的执行时间,如何才能做到统计更多的函数运行时间,直接传参变统计函数
4.虽然实现了一定的兼容性,但是并不符合装饰器的特征,第一种传参不写,只能考虑闭包
5.调用的方式还是不对,使用变量名赋值绑定(*****)
6.上述装饰器只能装饰无参函数 兼容性太差
7.被装饰的函数不知道有没有参数以及有几个参数 如何兼容
8.如果被装饰的函数有返回值装饰器模块:
def outer(func):
def inner(*args, **kwargs):
# 执行被装饰对象之前可以做的额外操作
res = func(*args, **kwargs)
# 执行被装饰对象之后可以做的额外操作
return res
return inner多层语法糖:
定义:指计算机语言中添加的某种语法。这种语法对语言的功能并没有影响,但是更方便程序员使用
层语法糖的加载顺序都是由下往上推的,每次执行之后如果上面还有语法糖,则直接将返回值函数传给上面的语法糖;如果上面没有语法糖了则变形 index = outter1(wrapper2)有参装饰器:
是为装饰器提供多样功能的选择的实现而提供的,实现的原理是三层闭包
有参装饰器的模板:
def outer(a):
def outer1(func):
def wrapper(*args,**kwargs):
print('流程推对了吗')
res = func(*args,**kwargs)
return res
return wrapper
return outer1
@outer('mySQL')
def func():
pass
通过第三层进行传值,使得有参装饰器可以使用其他参数,实现其他功能。无参装饰器模板:
def outer(func):
def inner(*args,**kwargs):
pass
res = func(*args,**kwargs)
return res
return inner
@outer
def index():
pass递归函数:
1.函数的递归调用
函数直接或者间接的调用函数自身
直接调用
间接调用
官网提供的最大递归深度为1000,我们在测试的时候可能会出现996 997 998 每个人电脑不同结果也会不同
1.直接或者间接调用自己
2.每次调用都必须比上一次简单,并且需要有一个明确的结束条件
递推:一层层往下
回溯:基于明确的结果一层层往上三元表达式:
代码简单并且只有一行,那么可以直接在冒号后面编写
'''
数据1 if 条件 else 数据值2条件成立则使用数据值1
条件不成立则使用数据值2
当结果是二选一的情况下,使用三元表达式较为简便
并且不推荐多个三元表达式嵌套
'''
列表生成式:
# 先看for循环,每次for循环之后再看for关键字前面的操作
new_list = [name + 'NB' for name in name_list ]
print(new_list)
# 结果:['jasonNB', 'kevinNB', 'oscarNB', 'tonyNB', 'jerryNB']
匿名函数:
所谓匿名函数,即不再使用def语句这样标准形式定义的函数。Python语言经常使用lambda来创建匿名函数。lambda 只是一个表达式,函数体比def定义的函数体要简捷。lambda函数的语法如下所示。
简单来说就是没有名字的函数,需要使用关键字lambda
lambda 表达式也叫做匿名函数,在定义它的时候,没有具体的名称,一般用来快速定义单行函数,直接看一下基本的使用:
fun = lambda x:x+1 print(fun(1)) lambda [参数列表]:表达式可迭代对象:
1.什么是可迭代对象?
对象内置有__iter__方法的都称为可迭代对象
2.可迭代对象范围
不可迭代对象
int float bool 函数对象
是可迭代对象
str list dict tuple set 文件对象
3.可迭代的含义
迭代:更新换代(每次更新都必须依赖上一次的结果)迭代对象:
1.迭代器对象
是由可迭代对象调用__iter__方法产生的
迭代器对象判断的本质是看是否内置有__iter__和__next__
2.迭代器对象的作用
提供了一种不需要依赖索引取值的方式
正因为有迭代器的存在,我们的字典,集合才能够被for循环
3.迭代对象实操
s1 = 'hello' # 可迭代对象
res = s1.__iter__() # 迭代器对象
print(res.__next__()) # 迭代取值 for循环的本质
一旦__next__取不到值 会直接报错
4.注意事项
可迭代对象调用__iter__会成为迭代器对象,迭代器对象如果还调用__iter__不会有任何变化,还是迭代器对象本身
for循环的本质
循环体代码
1.先将in后面的据调用__iter__转变成迭代器对象
2.依次让迭代器对象调用__next__取值
3.一旦__next__取不到值就会报错,for循环会自动捕获并处理不会造成报错现象影响整个代码的运行。异常捕获/处理
1.异常
Y异常就是代码运行报错,行业术语叫bug
代码运行中一旦遇到异常就会直接结束占、整个整个程序的运行,写程序不出错是不可能发生的事情,而程序员要做的事情就是及时的捕获错误,修改错误
2.异常分类
语法错误
不允许出现,一旦出现立刻改正,否则就等着玩完
逻辑错误
是允许出现的,因为它一眼是发现不了的,代码运行之后才可能会出现异常处理语法结构:
1.基本语法结构
try:
待检测的代码(可能会出错的代码)
except 错误类型:
针对上述错误类型制定的方案
2.查看错误的信息
try:
待检测的代码(可能会出错的代码)、
except 错误类型 as e:# e就是系统提示的错误信息
针对上述错误类型制定的方案
注意 except 后面异常对象使用 as 关键字起了一个别名叫做 e,然后直接输出 e 就是 Python 内置好的错误信息了。这里的 e 可以为任意名称,遵循变量命名规则即可
3.针对不同错误类型制定不同的解决方案
try:
待检测的代码(可能会出错的代码)
except 错误类型1 as e:# e就是系统提示的错误信息
except 错误类型2 as e:# e就是系统提示的错误信息
针对上述错误类型制定的方案
except 错误类型3 as e:# e就是系统提示的错误信息
针对上述错误类型制定的方案
4.万能异常 Exception/Basception
try:
待检测的代码(可能会出错的代码)
except Exception as e:# e 就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
5.结合else使用
try:
待检测的代码(可能会出错的代码)
except Exception as e: e 就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
else:
try的子代码正常运行结束没有任何的报错后,在执行else子代码
6.结合finally使用
try:
待检测的代码(可能会出错的代码)
except Exception as e: e 就是系统提示的错误信息
针对各种常见的错误类型统一处理
else:
try的子代码正常运行结束没有任何的报错后,再执行else子代码
finally:
无论try的子代码是否报错,最后都要执行finally子代码异常处理补充:
1.断言
hon 断言,即 Python assert 语句,简单理解就是简易版的 if 语句,
用于判断某个表达式的值,结果为 True,程序运行,否则,程序停止运行,抛出 AssertionError 错误
assert 表达式
name = 'jason'
#assert isinstance(name ,int) #结果肯定是False
assert isinstance(name,str)
print('猜对了就是字符串,嘿嘿嘿')
主动抛出异常
ame = 'jason'
if name == 'jason':
raise Exception(‘错了就不干了,提桶跑路’)
else:
print(‘正常走’)
断言主要为调试辅助而生,为的是程序自检,并不
是为了处理错误,程序 BUG 还是要依赖
try… except 解决。生成器对象
1、本质
还是内置__iter__的迭代器对象
2.区别
迭代器对象是解释器自动提供的
数据类型\文件对象>>>:迭代器对象
生成器对象是程序员编写出来的
代码、关键字>>>:迭代器对象(生成器)
Iterable(可迭代对象)、Iterator(迭代器)、genetator(生成器)关系如下:
1.可迭代对象 有 __iter__方法
2.迭代器继承了可迭代对象,有 iter、next 这两个方法
3.生成器又继承了迭代器,有 send、close、 iter、next 等方法
生成器是一种特殊的迭代器,具备迭代器所有的特性,生成器内部不存储数据,只保存生成数据的计算规则,在存储大量数据的时候,能够节约内存的开销
生成器表达式:
print((i for i in range(100)))
执行结果:
<generator object <genexpr> at 0x0000021698BC5510>生成器函数:
原理概述“
生成器函数 用于创建 生成器迭代器 (generator iterator)。
与普通函数的 区别 在于:普通函数 使用 return 返回结果,而生成器函数使用 yield 返回结果
使用了 yield 表达式 的生成器函数 返回一个迭代器对象,以便于通过 for 循环或 next() 函数等逐项获取元素/数据/值/成员 (以下统称 元素)。换言之,使用了 yield 表达式的函数就是生成器函数。
生成器函数的使用:
1.函数体代码中如果有yield关键字,那么函数名加括号并不会执行函数体代码,会生成一个生成器(迭代器对象)
2.使用加括号之后的结果调用__netx__才会执行函数体代码
3.每次执行完__next__代码都会停在yield位置继续往下找第二个yield案例:
自定义生成器对标range功能(一个参数,两个参数,三个参数 迭代器对象)
def my_range(star_num,end_num,None,step= 1):
#判断end_num是否有值,没有值说明用户只给了一个值,起始位置的数字应该是0,终止位置应该是传的值
if not end:
end = start
start = 0
while start < end:
yield start
start +=step
res = my_rang (1,10).__iter__()
while True:
try:
i = res.__next__()
print(i)
except StopIteration:
break
# 传三个参数:(间隔)
for i in my_range(1,10,2):
print(i)yield冷门用法:
def eat(name,food=None):
print(f'{name}准备吃饭')
while True:
food = yield
print(f'{name}在吃{food}')
res = eat(‘Jason’)
res.__next__()
res.send('汉堡')
1.将括号内的数据传给yield前面的变量名
2.在自动调用__next__
res.send('包子')
优点:
生成器对内存使用的提升
生成器的缺点:
只能依次往下迭代一轮,而不能回退和重复迭代。
生成式表达式:
说白了就是生成器的简化写法
l1 = [i**2 for i in range(10)]
print(l1)
结果:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]迭代器和生成器的区别:
生成器属于迭代器的一种
1、迭代器类型是Iterator类型,生成器是Generator类型。
2、生成器内部不存储数据,只保存生成数据的计算规则
3、生成器比迭代器多了3个方法
send方法:在生成数据的同时,可以和生成器内部进行数据交互
close: 生成可以调用close方法进行关闭
throw: 可以在生成器内部上一次暂停的yield处引发一个指定的异常类型。生成器内部可以通过捕获的异常类型来做不同的处理
案例:
使用while循环+异常处理+迭代器对象 完成for循环迭代取值的功能
l1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
# 1.先将列表调用__iter__转变成迭代器对象
iter_l1 = l1.__iter__()
# 2.while循环让迭代器对象反复执行__next__
while True:
try:
print(iter_l1.__next__())
except StopIteration as e:
bre面试题:
def add(n, i):
# 普通函数 返回两个数的和 求和函数
return n + i
def test(): # 生成器
for i in range(4):
yield i
g = test() # 激活生成器
for n in [1, 10]:
g = (add(n, i) for i in g)
""" 第一次for循环
g = (add(n, i) for i in g)
第二次for循环
g = (add(10, i) for i in (add(10, i) for i in g))
"""
res = list(g)
print(res)
#A. res=[10,11,12,13]
#B. res=[11,12,13,14]
#C. res=[20,21,22,23]
#D. res=[21,22,23,24]
'''
不用深入研究 大致知道起始数即可'''迭代取值与索引取值的差异
l1 = [11,22,33,44,55]
1.索引取值
可以在任意的位置任意的次数取值
不支持无序类型的数据取值
2.迭代取值
只能从前往后依次取值,无法后退
支持所有类型的数据取值(有序,无序皆可)
PS:两者的使用都需要结合实际的应用场景
模块

1.模块的本质
内部具有一定的功能(代码)的py文件
2.python模块的表现形式
2.1.py文件(py文件也可以称之为是模块文件)
2.2.含有多个py文件的文件夹(按照模块功能的不同划分不同文件夹来进行储存)
2.3.已被编译为共享库或DLL的C或C++扩展(了解即可)
2.4.使用C编写并链接到python解释器的内置模块(了解)
注:
1 自定义模块的时候要注意命名的规范,使用小写,不要使用大写,不要使用中文,不要使用特殊字符等。
2 不要与内置模块冲突 sys 等。 模块分类:
1.自定义模块
就是自己写的模块文件
2.内置模块
python解释器提供的模块
Python提供了一个强大的标准库,内置了许多非常有用的模块,可以直接使用(标准库是随python一起安装的),不用单独安装。
3.第三方模块
别人写好的模块文件(python背后真正的大佬)
官网:https://docs.python.org/zh-cn/3/library/index.html
https://www.cnblogs.com/jiangchunsheng/p/9275881.html
一个模块无论导入多少次,这个模块在做整个解释器进程内有且有有一个实例对象。导入模块的两种句式:
1.import句式
import 模块名 # 导入一个模块
import 模块1,模块2. # 导入多个模块
import 模块名 as 模块别名 # 导入模块并使用新名字
过程:
1、先产生执行文件的名称空间
2、执行被导入文件的代码将产生的名字放入被导入文件的名称空间中
3、将执行文件代码执行过程中产生的名字放于模块名称空间中
4、在执行文件中使用该模块名点的方式使用模块名称空间中所有的名字
2.from ...import....句式
如果进行类比的话,import导入的是“文件”,我们要使用该“文件”下的内容,必须前面加“文件名称”。from import 导入的是文件下的“内容”,直接使用这些“内容”即可
过程:
1、先产生执行文件的名称空间
2、执行被导入文件的代码将产生的名字放入被导入文件的名称空间
3、在执行文件的名称空间中产生的名字绑定模块名称空间中对应的名字
4、在执行文件中直接使用名字就可以访问名称空间中对应的名字
import导入的是模块。from...import导入的是模块中的一个函数/一个类。
3.import 与 from...import...两者优缺点
import句式
由于使用模块名称空间中的名字都需要模块名点的方式才可以用,所以不会轻易的被执行文件中的名字替换掉,但是每次使用模块名称空间中的名字都必须使用模块名点才可以
from ... import ...句式
指名道姓的导入模块名称空间中需要使用的名字,不需要模块名点,但是容易跟执行文件中名字冲突
PS:重复导入多个模块python解释器只会执行一个
4.起别名
import 需要改的模块名 as 改之后的模块名
from 需要改的模块名 import 需要改的模块名 as 改之后的模块名
from a import name as n,func1 as f1
5.多个模块的导入
如果模块的功能相似度不高,就一个一个导
反之:
import 模块一,模块二
循环导入:
1、循环导入
两个文件彼此之间导入彼此并且相互使用各自名称空间中的名字,是极其容易出错的
2、如何解决循环导入问题
1.确保名字在使用之前就已经准备完毕
2、我们在以后编写代码的过程中应该尽可能避免出现循环导入判断文件类型:
所有的py文件都是可以直接打印__name__对应的值
当py文件是执行文件的时候__name__对应的值是__main__
当py文件是被导入文件的时候__name__对应的值是模块名
if __name__ == '__main__':
os.getcwd()
"这是python脚本的执行入口"
代码 中 if 的意思就是:如果运行的程序是你自己,那么就执行 os.getcwd() 与 "这是python脚本的执行入口"
使用场景:
模块开发阶段,项目的启动文件
from a import *
*默认是将模块名称空间中所有的名字导入
__all__ = ['名字1', '名字2'] 针对 * 可以限制拿的名字模块的查找顺序:
1.内存
2.内置 自定义模块的时候尽量不要与内置模块名冲突
3.执行文件所在的sys.path(系统环境变量)
ps:一定要已执行文件为准!!!!
我们可以将模块所在的路径也添加到执行文件的sys.path中即可
当导入某个模块文件时,Python解释器只有找到文件时,才能读取,装载运行该模块文件。它一般按照如下路径寻找模块文件(按顺序寻找,找到即停不继续往下寻找)如下:
1.内置模块
2.当前目录
3.程序的主目录
4.pythonpath目录(如果已经设置好了)
5.标准链接库目录
6.第三方库目录(site-packages目录)
7.pth文件的内容(如果存在的话)
8.sys.path.append()临时添加的目录
当任何一个python程序启动时,就将上面这些搜索路径(除内置模
块以外的路径)进行收集,放在sys模块的path属性中(sys.path).绝对导入与相对导入:
再次强调:一定要分清楚谁是执行文件!!!
模块的导入全部以执行文件为准
绝对导入:
from aa.bb.cc import name 精确到变量名
from aa.bb.cc import dd 精确到模块名
PS:反正套路就是按照项目的根目录一层层的往下查找
相对导入:
.在路径中表示当前目录
..在路径中表示上层目录
..\..在路径中表示上上一层目录
不在依据执行文件所在的sys.path ,而是一模块自身路径为准
form . import b
相对导入只能用于模块文件中,不能在执行文件中使用
‘‘相对导入使用频率较低,一般用绝对导入即可,结构更加清晰’包:
通俗来讲就是多个py文件的集合>>>>:文件夹
专业的讲:内部含有__init__.py文件的文件夹(python2必须要求,python3无所谓)
ps:虽然python3对包的要求降低了,不需要__init__.py也可以识别,但是考虑到兼容性问题最好还是加上__init__.py
包的定义:
1.简单粗暴的解释,当一个文件夹内容里含有一个__init__.py文件时我们就可以认为它就是一个包;如果改文件下还有子文件且该子文件中也有一个__init__.py文件,我们就可以认为它就是一个包中还有包。
2.一个包里可以有一个或者多个模块;通过调用包下面某个模块的某个函数取执行,这就是我们使用python包或模块的目的。
包的概念:
__init__.py文件是每一个python包必须存在的文件,只有存在__init__.py文件的目录,python解释器才会认为这是一个包,如果没有这个文件,解释器只会认为这是一个普
通的文件夹
包的使用
1.怎么打开包?
1.1.如果只是想用包中某几个模块,那么还是按照之前的导入方式即可
from aaa import md1,md2
1.2.如果直接导入包名
import aaa
导入包名其实就是导包名下面的__init__.py文件,该文件内有什么名字就可以通过包名点什么名字
如何创建包:
首先创建一个文件夹,然后再文件夹中创建一个python包的身份证。文件__init__.py文件即可,即使__init__.py 文件里什么也没写是空的,只要文件名的名字是__init__.py,解释器也会认为这是一个包,之后我们就可以在包里书写任意的模块功能了。
软件开发目录规范
1.文件目录的名字可以转换,但是核心思想是不变的
2.目录规范的主要作用是规定在开发程序中针对不同的文件功能需要做不同的分类
my_project项目文件夹:
1.bin 主要存放项目启动文件
start.py
2.conf 主要存放项目的配置文件
settings.py 存放项目的默认配置,一般都是全大写
3.core 主要存放项目核心配置
src.py
4.interface 主要存放项目接口文件
goods.py 根据具体业务逻辑划分对应的王文件
user.py
account.py
5.db 主要存放项目的相关数据
userinfo.txt,db_handler.py 存放数据库相关的操作代码
6.log 主要存放项目日志文件
log.log
7.lib文件夹 主要存放项目公共功能
common.py
8.readme文件 主要存放项目的相关说明
9.requirements.txt文件 主要存放项目所需模块级版本常用内置模块名
collection模块
1.namedtuple内置模块 具名元组
表示二维坐标系
point = namedtuple('点',['x','y']) # 生成点信息
p1 = point(1,2)
print(p1) # 点(x=1,y=2)
2.队列 queue
队列与堆栈
队列:先进先出
堆栈:先进后出
1.先进先出队列 queue.Queue
2.后进先出队列 queue.LifoQueue (Queue的基础上进行的封装)
3.优先级队列 queue.PriorityQueue (Queue的基础上进行的封装) 优先级队列,第一个值传数字,代表优先级,第二个是值,优先取出的是优先级高的;
4.双向队列 queue.deque
3.有序字典 (OrderedDict)
读取数据创建n个键值对,将其排序后放入有序字典并输出。
3.1.有序字典和普通的dict基本上是相似的,只有一点不同,那就是有序字典中键值对的顺序会保留插入时的顺序。
3.2.有序字典的创建方法和普通的dict类似,不过由于多了保留顺序的功能,因此在使用可迭代对象创建有序字典时,可以对它先排个序,让创建出来的字典元素也是有序的
4.计数器 count()时间模块:
时间的三种表现形式:
1.时间戳
秒数
2.结构化时间
主要是给计算机看的
3.格式化时间
主要是给人看的
time模块:
1.time 函数 生成时间戳
2.localtime函数 获取本地时间函数
3.sleep函数 暂停/等待 程序暂停执行一段时间
4.strftime函数 将时间转换成字符串
5.strptime函数 将时间字符串转换为时间对象
注意:每个语言返回的时间戳格式都不太一样,有的是返回秒级别,有的是返回毫秒级别。无论哪一种,时间都是一样的,只是 秒 与 毫秒 之间的转换而已。
datetime时间包:
datetime模块
1.date:日期;time:时间 所以datetime就是日期与时间的结合体
2.使用datetime我们就可以获取当前时间和时间间隔
3.可以将时间对象转换成时间字符串
4.也可以将字符串转换成时间类型(把字符串转成时间对象也是有格式要求的)
获取时间间隔
其实获取时间间隔本身没有什么用,它需要配合我们刚刚提到的 datetime 模块的 now() 函数来配合使用。
# 导入包
from datetime import datetime
from datetime import timedelta
#这里的timedelta 并不是模块,而是一个函数至于为什么不是模块,可以猜测一下timedelta可能是写在datetime包下
使用方法:
timeobj = timedelta(days=0, seconds = 0 ,microseconds = 0, minutes = 0, hours = 0,weeks = 0)
print(timeobj)
# 0:00:00
间隔20分钟
import datetime
ctime = datetime.datetime.today()
print(ctime)
# 2022-10-19 17:02:42.601075
time_del = datetime.timedelta(minutes=20)
print(ctime + time_del)
# 2022-10-19 17:23:42.183877
通过上面的小案例我们知道,时间对象之间我们可以做 加法与减法 的操作
days:间隔的天数
seconds:间隔的秒数
microseconds:间隔的毫秒数
milliseconds:间隔的微秒数
minutes:间隔的分钟数
hours:间隔的小时数
weeks:间隔的周数
这些参数我们可以全部传,也可以只传一个;像间隔一天、两天这种情况,我们就可以使用 hours 或 days
传入类型为 整型 ,支持整数与负数,一般我们建议使用正数。

随机数模块 random
1.random.random() 随机生成浮点数
2.random.uniform()
产生一个 区间 的随机浮点数
3.random.randint() 随机生成整数
4.random.randrange(1,100,2) 随机生成指定的整数
5.random.choies()随机抽取一个样本
6.random.sample((样本),(样本的个数)) 随机抽取规定的样本数
7. random.shuffle()随机打乱数据集
案例:
产生图片验证码:每一位都可以是大写字母,小写小字母,数字 4位组成
def get_code(n):
code = ''
for i in range(n):
# 先产生随件的大小字母,数字
random_upper =chr(random.randint(65, 90))
random_lower = chr(random.randint(97, 122))
random_int = str(random.randint(0,9))
# 随机三选一
temp = random.choice([random_upper,random_lower,random_int])
code +=temp
return code
res = get_code(10)
print(res)
res = get_code(4)
print(res)
# 0pNBZ23n94
# 1pf7os模块
os模块主要和操作系统打交道
sys模块主要与python解释器打交道
讲解:
os是python解释器的内置包--->os包,os包拥有这普遍的操作系统功能,拥有着各种各样的函数来操作系统的驱动功能。其中最常用的就是对路径与文件的操作,比如检查某个路径下是不是存在某个文件,某个路径是否存在等。也可以创建文件、删除文件等;接下来就一起仔细的看一下os中对于文件的操作功能与用法吧。
1.os.getcwd() 返回当前文件路径
2.创建目录(文件夹)
os.mkdir() 执行文件所在的路径下创建目录 可以创建单级目录
os.makedirs() #可以创建单机目录
3.删除目录
os.rmdir(r'd1') # 删除单级目录 而且是空目录
os.removedirs()#只能删除空的多级目录
4.列举指定路径下的文件名
os.listdir(r'd:\\')
5.删除\重命名文件
os.rename()重命名文件
os.remove() 删除文件
6.获取/切换当前工作目录
os.getcwd() 当前目录
os.chdir('..') # 切换到上一级目录
7.动态获取项目根路径(重点)
os.path.abspath(__file__)# 获取执行文件的绝对路径
os.path.dirname(__file__) # 获取执行文件所在的目录路径
8.判断路径是否存在
os.path.exists(r'01.py') # 判断文件路径是否存在
os.path.isfile() #判断目录是否存在 是否是文件
os.path.isdir() #判断路径是否是文件夹
9.路径拼接
os.path.join(拼接的路径,需要拼接的文件名)
10.获取文件大小(字节)
os.path.getsize()path模块

sys模块
sys模块与os包一样,也是对系统资源进行调用
1.sys.path 获取执行文件的环境变量
2.sys.getrecursionlimit() # 获取python解释器默认最大的递归深度
3.sys.setrecursionlimit(2000) # 官方的递归深度在1000,但是也是可以修改的
4.sys.version 平台信息
5.一个只对终端才能使用功能:
sys.argv#argv 是获取程序外部的参数,返回值是一个列表。
可以在终端进行输入,从而进行判断解密
json模块
1.Json模块也称为序列化模块,序列化可以打破语言之间限制实现不同编程语言之间的数据语言交互
2.json模块是一个通用的序列化模块,通过它可以完成通用化的序列化与反序列化操作。为什么说是通用的,那是因为几乎所有的编程语言都有json模块,而且他们序列化与反序列化的规则是统一的。
json的顶层支持的三种类型的值:
简单值:数字,字符串(不支持单引号),布尔值类型,null类型
对象值:由key、value组成,key是字符串类型,并且必须添加双引号,值可以是简单值、对象值、数据值。
数据组:数据的值可以是简单值、对象值、数据值
json 相关的操作:
针对数据:
json.dumps()
json.loads()
针对文件:
json.dump()
json.load()正则表达式:
概念:正则表达式是一门独立的技术,所有编程语言都可以使用它的作用可以简单的概括为:利用一些特殊符号(也可以直接写需要查找的具体字符)的组合产生一些特殊的含义然后去字符串中筛选出符合条件的数据
正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则。
简单来说就是筛选数据(匹配数据)
ps:很多时候,很多的问题前人已经弄好了,而我们应该做的就是花时间去找(百度)
eg:编写邮箱
编写身份证号
编写手机号
编写校验用户QQ号.....字符组:
'''字符组默认匹配方式是一个接着一个的匹配'''
[0123456789] 匹配0到9任意一个数(全写)
[0-9] 匹配0到9任意一个数(缩写)
[a-z] 匹配26个小写英文字母
[A-Z] 匹配26个大写英文字母
[0-9a-zA-Z] 匹配数字或者小写字母或者大写字母
ps:字符组内所有的数据默认都是或的关系特殊符号:
'''特殊符号默认匹配方式是挨个挨个匹配'''
. 匹配除换行符以外的任意字符
\w 匹配数字、字母、下划线
\W 匹配非数字、非字母、非下划线
\d 匹配数字
^ 匹配字符串的开头
$ 匹配字符串的结尾
两者组合使用可以非常精确的限制匹配的内容
a|b 匹配a或者b(管道符的意思是或)
() 给正则表达式分组 不影响表达式的匹配功能
[] 字符组 内部填写的内容默认都是或的关系
[^] 取反操作 匹配除了字符组里面的其他所有字符
注意上尖号在中括号内和中括号意思完全不同量词:
''''正则表达式默认情况下都是贪婪匹配>>>:尽可能多的匹'''
* 匹配零次或多次 默认是多次(无穷次)
+ 匹配一次或多次 默认是多次(无穷次)
? 匹配零次或一次 作为量词意义不大主要用于非贪婪匹配
{n} 重复n次
{n,} 重复n次或更多次 默认是多次(无穷次)
{n,m} 重复n到m次 默认是m次
ps:量词必须结合表达式一起使用 不能单独出现 并且只影响左边第一个表达式
jason\d{3} 只影响\d
贪婪与非贪婪:
"""所有的量词都是贪婪匹配如果想要变为非贪婪匹配只需要在量词后面加问号"""
待匹配的文本
<script>alert(123)</script>
待使用的正则(贪婪匹配)
<.*>
请问匹配的内容
<script>alert(123)</script> 一条
# .*属于典型的贪婪匹配 使用它 结束条件一般在左右明确指定
待使用的正则(非贪婪匹配)转义符:
"""斜杠与字母的组合有时候有特殊含义"""
\n 匹配的是换行符
\\n 匹配的是文本\n
\\\\n 匹配的是文本\\n
ps:如果是在python中使用 还可以在字符串前面加r取消转义re模块
在python中如果想要使用正则,可以考虑re模块
1. re.findall()# 查找所有符合正则表达式要求的数据 结果直接是一个列表
2.re.finditer()# 查找所有符合正则表达式要求的数据 结果直接是一个迭代器对象
3.res.group() #匹配到一个符合条件的数据就立刻结束
4.re.match()#匹配字符串的开头 如果不符合后面不用看了
5.re.compile('\d{3}') # 当某一个正则表达式需要频繁使用的时候 我们可以做成模板
6. re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
7.re.sub('\d', 'H', 'eva3jason4yuan4', 1) # 将数字替换成'H',参数1表示只替换1个
8.re.subn('\d', 'H', 'eva3jason4yuan4') # 将数字替换成'H',返回元组(替换的结果,替换了多少次)
9.findall(优先级查询)分组优先展示:优先展示括号内正则表达式匹配到的内容
10.分组别名
res = re.search('www.(?P<content>baidu|oldboy)(?P<hei>.com)', 'www.oldboy.com')
print(res.group()) # www.oldboy.com
print(res.group('content')) # oldboy
第三方模块的下载与使用
第三方模块含义:
第三方模块就是所谓别人写的模块,别人写好的模块一般情况功能都比较强大,而如果我们想要使用第三方模块的话,就需要先下载,之后就能反复使用能了(就相当于是内置模块)
下载第三方模块的方式:
1.pip工具
需要注意每个解释器都有pip工具,如果我们的电脑上有多个版本的解释器的话,那么我们在使用pip的时候一定要注意到底使用的是哪一个,否则极其任意出现使用的A版本,然后却使用到B版本的pip来进行下载模块。
为了避免pip这一冲突,我们在使用的时候可以添加对应的版本号
下载第三方模块的句式:
pip,install 模块名
下载第三方模块指定版本(不指定的话,默认是最新版)
pip install 模块名 == 版本号 -i 仓库地址
2.pycharm提供的快捷方式:
settings
project
project interprter
双击或者加号
点击右下方manage管理添加源地址即可
下载第三方的模块可能会出现的问题:
1.报错并有警告信息
WARNING: You are using pip version 20.2.1;
原因:pip的版本过低,只需要拷贝后面的命令执行更新操作即可
d:\python38\python.exe -m pip install --upgrade pip
措施:更新完成后在执行下载第三方模块的命令即可
2.报错的提示信息中含有关键字timeout
原因:说明当前计算机网络不稳定
措施:再次尝试 或者切换更加稳定的网络
3.找不到pip命令
环境变量问题
4.没有任何的关键字 不同的模块报不同的错
原因:模块需要特定的计算机环境
措施:拷贝报错信息 打开浏览器 百度搜索即可
pip下载某个模块报错错误信息:pip下载XXX报错
5.下载速度很慢
pip默认下载的仓库地址是国外的 python.org
我们可以切换下载的地址
pip install 模块名 -i 仓库地址
pip的仓库地址有很多,百度查询即可
pip命令默认下载的渠道是国外的python官网(有时候会非常的慢)
我们可以切换下载的源(仓库)
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:
http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:
http://pypi.hustunique.com/
豆瓣源:
http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
网络爬虫之requersts模块

requersts支持的请求方式:
1.朝指定网址发送请求获取页面数据(等价于:浏览器地址栏输入网址回车访问)
requests.get('http://www.redbull.com.cn/about/branch')
2.res.coutent 获取bytse类型的网页数据(二进制)
3. res.encoding='utf8' # 指定编码
4.res.text 获取字符串类型的网页数据 默认计算机的字符编码 utf8自动化办公领域之openpyxl模块
1.excel文件的后缀名问题
03版之前 20年前 .xls
03版之后 .xlsx
2. 2.操作excel表格的第三方模块
xlwt往表格中(写)入数据、wlod从表格中(读)取数据
兼容所有版本的excel文件
openpyxl最近几年比较火热的操作Excel表格的模块
03版本之前的兼容性较差
PS:还有很多操作Excel表格的模块,甚至涵盖了上述的模块>>>>>pands
3.openpyxl 操作
小提示:在接触新的东西的时候记得看官方文档
from openpyxl import Workboo
3.1.创建一个Excel文件
wb=Workbook()
3.2.创建工作簿(可以创建多个)
wb.creata_sheet(工作簿名字)
3.3.修改工作簿名字
wb.title = 修改的名字
3.4.修改工作簿的位置
wb.creata_sheet(工作簿名字,改的位置(0))
3.5.修改颜色
wb.sheet_properties.tabColor = '颜色的名字'
3.6 填写数据的方式1
wb['f4'] =666
3.7 方式2
wb4.cell(row=3, column=1, value='jason')
3.8 方式3
wb.append(['编号', '姓名', '年龄', '爱好']) # 表头字段
wb4.append([1, 'jason', 18, 'read'])
3.9 填写数学公式
wb4.cell(row=1, column=1, value=12321)
# wb4['A5'] = '=sum(A1:A4)'
# wb4.cell(row=8,column=3,value='=sum(A1:A4)')
4.保存Excel文件
wb.save()
openpyxl主要用于数据的写入 至于后续的表单操作它并不是很擅长 如果想做需要更高级的模块pandaspandas模块
Pandas提供了三种基本数据结构
Series:带标签的一维数组
DataFrame:带标签的二维数组(即表格)
Panel:带标签的三维数组(若干表格的叠加面板)
主要使用Series和DataFrame。与NumPy数组相比,Pandas最重要的改进是增加了标签(也称轴索引),可以实现自动的按索引对齐运算。
具体请到网址:https://aistudio.baidu.com/aistudio/projectdetail/1758982?hmsr=aladdin
import pandas
data_dict = {
"公司名称": comp_title_list,
"公司地址": comp_address_list,
"公司邮编": comp_email_list,
"公司电话": comp_phone_list
}
# 将字典转换成pandas里面的DataFrame数据结构
df = pandas.DataFrame(data_dict)
# 直接保存成excel文件
df.to_excel(r'pd_comp_info.xlsx')
excel软件正常可以打开操作的数据集在10万左右 一旦数据集过大 软件操作几乎无效
需要使用代码操作>>>:pandas模块hashlib模块
1.什么是加密?
将明文数据处理成密文数据,让人无法看懂
2.为什么要加密?
保证数据的安全防止被人看懂盗用
3.如何判断数据是否是加密数据?
加密的密文都是由一串没有规律的字符串(数字,字母,符号)组成
4.密文的长短有什么讲究?
密文越长表示使用的加密算法(数据的处理过程)越复杂
5.常见的加密算法有哪些?
md5、base64、hmac、sha系列
6.加密算法的基本操作
import hashlib
# 1.选择加密的算法
md5 = hashlib.md5()
# 2.传入明文数据
md5.update(b'hello')
# 3.获取加密密文
res = md5.hexdigest()
print(res)
补充说明:
1.加密算法不变,内容如果相同的话,那么结果肯定相同
数据可分一次或多次传入,最后的结果都是一样的
2.加密之后的的结果是无法反解密的
只能丛明文到密文正向推导,无法从密文到明文的反向推导,常见的解密过程其实就是有的程序员因为太闲了提前记录下一些简单的明文的密文,提前猜测的一些结果。
3.加盐处理
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
在明文里面添加一些额外的干扰项
3.1选择加密算法
md5 = hashlib.md5()
3.2.传入明文数据
md5.update('为项目文件设置的干扰项'.encode('utf8'))
md5.update(b'hello ppython') # 一次性传可以
3.3.获取加密密文
res = md5.hexdigest()
print(res) # e53024684c9be1dd3f6114ecc8bbdddc
3.4.动态加盐
干扰项是随机变化的
比较常用的有:当前时间、用户的用户名的一部分。。。
3.5.加密实战操作
1.用户密码加密
2.文件安全性校验
3.文件内容加密
4.大文件内容加密
截取部分内容加密即可subprocass模块
模拟操作系统终端,执行命令并获取执行结果
import subprocess
res =subprocess.Popen(
'asdas', # 操作系统要执行的命令
shell= True,# 固定配置
stdin = subprocess.PIPE, # 输入命令
stdout = subprocess.PIPE # 输出结果
)
print('正确结果',res.stdout.read().decode('gbk')) # 获取操作系统执行命令之后的正确结果
print('错误结果',res.stderr) # 获取操作系统执行命令之后的错误结果
# 正确结果
# 错误结果 None
# 'asdas' �����ڲ����ⲿ���Ҳ���ǿ����еij���
# ���������ļ��logging日志模块
1.如何理解日志模块
简单的理解为就是记录行为的一种操作员(就像古时候记录历史的史官)
日志的级别:
import logging
logging.debug('debug message') 调试错误
logging.info('info messge') # 信息
logging.warning('warning messge') #警告,
logging.error('error messge') #错误
logging.critical('critical messge') #严重的,危机的
日志的组成:
1.产生日志,过滤日志,日志格式,输出日志
小提示:过滤日志基本不怎么使用,因为在日志产生阶段就可以控制想要的日志内容
logging参数配置
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
复制代码点击查看代码
import logging
# 1.日志的产生(准备原材料)
logger对象logger = logging.getLogger('购物车记录')
# 2.日志的过滤(剔除不良品) filter对象>>>:可以忽略 不用使用
# 3.日志的产出(成品) handler对象
hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到文件中
hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 输出到文件中
hd3 = logging.StreamHandler() # 输出到终端
# 4.日志的格式(包装) format对象
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)fm2 = logging.Formatter( fmt='%(asctime)s - %(name)s: %(message)s', datefmt='%Y-%m-%d',)
# 5.给logger对象绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.给handler绑定formmate对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级logger.setLevel(10) # debug
# 8.记录日志logger.debug('写了半天 好累啊 好热啊')配置日志字典
点击查看代码
import logging
import logging.config
# 定义日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
logfile_path = 'a3.log'
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置 动态获取日志名称
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '购物车记录': {
# 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
# logger1 = logging.getLogger('购物车记录')
# logger1.warning('尊敬的VIP客户 晚上好 您又来啦')
# logger1 = logging.getLogger('注册记录')
# logger1.debug('jason注册成功')
logger1 = logging.getLogger('登录记录')
logger1.debug('Andy登录成功')
面向对象
编程思想:
面向过程:
过程就是流程,而面向过程就是按照固定的流程解决问题
比如说,做饭,就是一个步骤一个步骤的操作,有理由条的。
面向过程:是一种以事件为中心的编程思想,更关注过程。简单的问题可以用面向过程的思路来解决,直接有效,但是当问题的规模变得更大时,用面向过程的思想是远远不够的。所以慢慢就出现了面向对象的编程思想。
PS:随着执行的过程中,提出问题,发现问题,然后指定出问题的解决方案
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
缺点:不易维护、复用和拓展面向对象:
世界上的每个人或事务都能看成一个对象,每个对象都有自己的属性和行为,对象与对象之间通过方法来交互。面向对象是一种以“对象”为中心的编程思想,把要解决的问题分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个对象在整个解决问题的步骤中的属性和行为。
在python中对象即容器,是数据与功能的结合体
面向对象编程有点类似于造物主的感觉 我们只需要造出一个个对象,至于该对象将来会如何发展跟程序员没关系 也无法控制
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护
缺点:性能比面向过程低上述的这两种编程思想没有优劣之分,使用还是需要结合实际情况需求而定
eg:需求是登录注册,人脸识别肯定是面向过程更合适
需求是游戏人物肯定是面向对象更合适
实际编程的这两种思想是彼此交融的,只不过是占比不同罢了
类与对象的概念
1.对象:数据与功能的结合体,对象才是核心
2.类:类就是一个变量和函数的集合
①定义:类是抽象的,在使用的时候通常会找到这个类的一个具体的存在,使用这个具体的存在。一个类可以找到多个对象(即多个对象相同数据和功能的结合体)
现实中一般是先有对象再有类
程序中如果想要产生对象 必须要先定义出类
3.语法结构:
类的名称:class 类名:
类的属性:一组数据(对象公共的数据)
类的方法(行为):允许对其进行操作的方法(对象公共的功能)
1.class是定义类的关键字
2.类名的命名与变量名几乎一致 需要注意的时候首字母推荐大写用于区分
3.数据:变量名与数据值的绑定 功能(方法)其实就是函数
2.类的定义与调用
类在定义阶段就会执行类体代码 但是属于类的局部名称空间 外界无法直接调用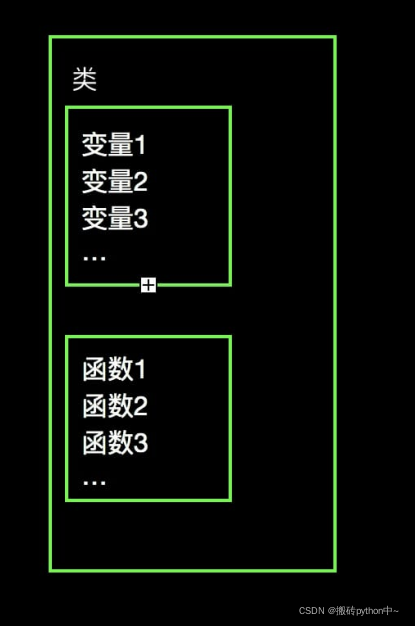
这张图很好的诠释了类,就是把变量和函数包装在一起。
当然我们包装也不是毫无目的的包装,我们会把同性质的包装在一个类里,这样就方便我们重复使用。
所以学到现在,你会发现很多编程的设计,都是为了我们能偷懒,重复使用。
我们定义了类之后,那么我们怎么调用类里面的属性和方法呢?
直接看下图:

下列浅试一下:
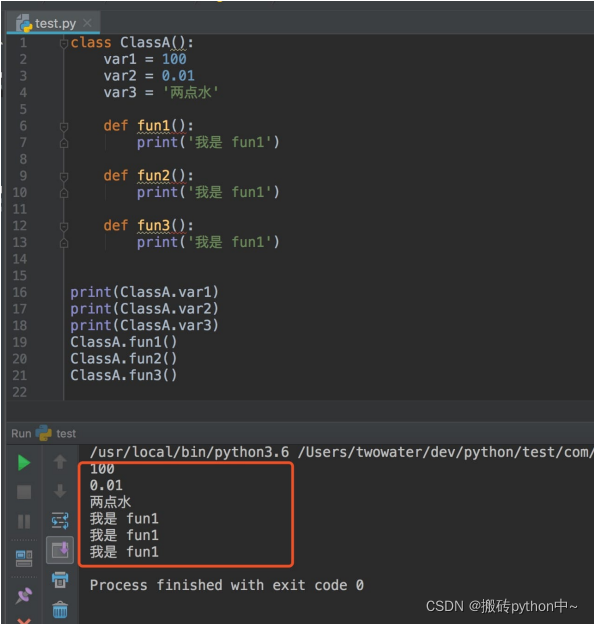
1、类和对象之间的关系
这部分内容主要讲类和对象,我们先来说说类和对象之间的关系。
类是对象的模板
我们得先有了类,才能制作出对象。
类就相对于工厂里面的模具,对象就是根据模具制造出来的产品。
从模具变成产品的过程,我们就称为类的实例化。
类实例化之后,就变成对象了。也就是相当于例子中的产品。类的实例化:
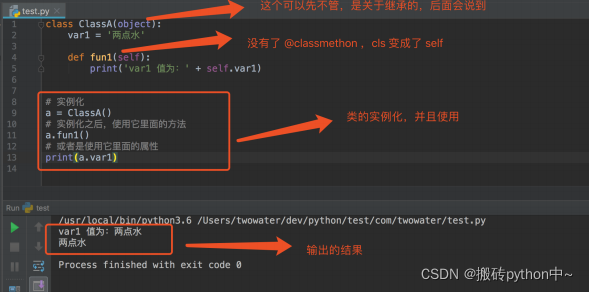
主要的不同点有:
1.类方法里面没有了 @classmethod 声明了,不用声明他是类方法
2.类方法里面的参数 cls 改为 self
3.类的使用,变成了先通过 实例名 = 类() 的方式实例化对象,为类创建一个实例,然后再使用 实 例名.函数() 的方式调用对应的方法,使用 实例名.变量名 的方法调用类的属性
这里说明一下,类方法的参数为什么 cls 改为 self ?
其实这并不是说一定要写这个,你改为什么字母,什么名字都可以。
试一下: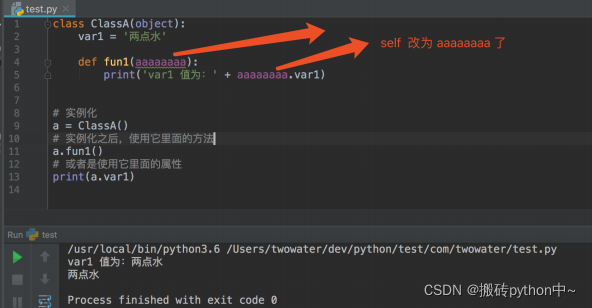
这里把self该为aaaa还是一样可以运行,只不过使用 cls 和 self 是编程习惯,这也是编程规范。
因为 cls 是 class 的缩写,代表这类 , 而 self 代表这对象的意思。
所以在这里我们实例对象的时候就是使用self
而且 self 是所有类方法位于首位、默认的特殊参数。
除此之外,在这里,还要强调一个概念,当你把类实例化之后,里面的属性和方法,就不叫类属性和类
方法了,改为叫实例属性和实例方法,也可以叫对象属性和对象方法。
为什么要这样强调呢?
因为一个类是可以创造出多个实例对象出来的。
类与对象的代码实操:
class Student:
pass
obj = Student()
1.如何查看类或者对象名称空间中可以使用的名字
类/对象.__dict__
2.面向对象访问名字统一采用句点符
类/对象.名字
3.类名加括号一定会产生一个新的对象
obj1 = Student()
obj2 = Student()
obj3 = Student()对象独有数据:
1.直接利用对象点名字的方式
obj1 = Student()
obj1.__dict__['name'] = 'jason'
2.将添加对象独有数据的代码封装成函数
def init(obj,name,age):
obj.name = name
# obj.__dict__['name'] = name
obj.age = age
# obj.__dict__['age'] = age
3.将上述方法绑定给特定类的对象
class Student:
def init(obj,name,age):
obj.name = name
# obj.__dict__['name'] = name
obj.age = age
# obj.__dict__['age'] = age
4.自动触发的方法:
class Student:
def __init__(self,name,age):
self.name = name
# obj.__dict__['name'] = name
self.age = age
# obj.__dict__['age'] = age
5.类中如果有双下init方法 意味着类加括号需要传参数
obj = Student('jason', 18)对象的独有方法:
1.也是直接在全局定义函数 然后给对象
def func():pass
obj = Student()
obj.func = func
2.面向对象的思想 放到类中
3.对象的绑定方法
类中定义的方法既可以说是对象公共的方法 也可以是对象独有的方法
哪个对象来调用 谁就是主人公python面向对象的重要术语:
1、多态(polymorphism):一个函数有多种表现形式,调用一个方法有多种形式,但是表现出的方法是不一样的。
2、继承(inheritance)子项继承父项的某些功能,在程序中表现某种联系(使用的频率高,比较重要)
3、封装(encapsulation)把需要重用的函数或者功能封装,方便其他程序直接调用
4、类:对具有相同数据或者方法的一组对象的集合
5、对象:对象是一个类的具体事例
6、实例化:是一个对象事例话的实现
7、标识:每个对象的事例都需要一个可以唯一标识这个事例的标记
8、实例属性:一个对象就是一组属性的集合
9、事例方法:所有存取或者更新对象某个实例一条或者多条属性函数的集合。
10、类属性:属于一个类中所有对象的属性,
11、类方法:那些无须特定的对性实例就能够工作的从属于类的函数函数和面向对象编程的区别:
相同点:都是把程序进行封装、方便重复利用,提高效率。
不同点:函数重点是用于整体调用,一般用于一段不可更改的程序。仅仅是解决代码重用性的问题。
而面向对象除了代码重用性。还包括继承、多态等。使用上更加灵活。2继承、封装、多态
1.继承
继承,面向对象中的继承和现实生活中的继承相同,表示人与人之间资源的从属关系 即:子可以继承父的内容。
1. 继承的含义:
1.在现实生活中继承表示人与人之间资源的从属关系
2.在编程世界中继承表示类与类之间资源的从属关系
2.继承的目的
1.一个类继承了父类后,可以直接调用父类的方法的
2.也可以重写父类的方法
3.继承的实操
class Son(Father):
pass
1.在定义类的时候类名后面可以加括号填写其他类名 意味着继承其他类
2.在python支持多继承 括号内填写多个类名彼此逗号隔开即可
class Son(F1, F2, F3):
pass
"""
1.继承其他类的类 Son
我们称之为子类、派生类
2.被继承的类 Father F1 F2 F3
我们称之为父类、基类、超类
ps:我们最常用的就是子类和父类
"""
4.继承的本质
对象:数据和功能的结合体
类(子类):多个对象数据和功能的结合体
父类:多个类(子类)相同数据和功能的结合体
PS:继承的本质应该分为两个部分:
抽象:将多个类相同的东西抽取出去形成一个新的类
继承:将多个类继承刚刚抽取出来的新的类
1.2名字的查找顺序
1.不继承情况下名字的查找顺序
对象查找自己的名字的顺序
1.1.先从自己的名称空间中查找
1.2.自己没有再去产生该对象的类中查找
1.3.如果类中也没有 那么直接报错
对象自身 >>> 产生对象的类
2.单继承情况下名字的查找顺序
1.先找对象自身的
2.产生对象的类
3.继承的父类
PS:对象点名字,永远是从对象自身开始一步步的开始查找的,以后在看到 self.名字的时候,一定要搞清楚self指代的是哪个对象
3.多继承情况下名字的查找顺序
菱形继承
广度优先(最后才会找闭环的定点)
非菱形继承
深度优先(从左往右每条道走完为止)
ps:mro()方法可以直接获取名字的查找顺序
1.对象自身
2.产生对象的类
3.父类(顺序从左往右)
多继承有一点需要注意的:若是父类中有相同的方法名,而在子类使用时未指定,python 在圆括号中父类的顺序,从左至右搜索 , 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
那么继承的子类可以干什么呢?
继承的子类的好处:
会继承父类的属性和方法
可以自己定义,覆盖父类的属性和方法1.3 经典类与新式类:
经典类:不继承object或者其子类的类
新式类:继承object或者其子类的类
在python2中有经典类和新式类
在python3中只有新式类(所有类默认都继承object)
class Student(object):pass
ps:以后我们在定义类的时候 如果没有其他明确的父类 也可能习惯写object兼容子类的类型判断
对于 class 的继承关系来说,有些时候我们需要判断 class 的类型,该怎么办呢?
可以使用 isinstance() 函数
isinstance() 不仅可以告诉我们,一个对象是否是某种类型,也可以用于基本类型的判断。类的派生
类可以派生出自己新的属性,在进行属性查找时,子类中的属性名会优先于父类被查找例如定义一个类,产生一个属性,我们就需要再这个类中定义该类自己的__init__覆盖父类的方法。
如上列:
如果想在子类派生的方法内重用父类的功能,有两种实现的方式:
方式一:
'指名道姓'地调用某一个类的函数
class Teacher(People):
def __init__(self,name,sex,age,title):
People.__init__(self,name,age,sex) #调用的是函数,因而需要传入self
self.title=title
def teach(self):
print('%s is teaching' %self.name)
方式二: super()
调用super会得到一个特殊的对象,该对象专门用来引用类的父类属性,且严格按照 MRO规定的顺序向后查找
class Teacher(People) :
def __init__(self,name,sex,arg,title):
#调用的是绑定方法,自动传入self
super().__init__(name,agr,sex)
self.title =title
def teacher(self):
print(f"{self.name} is teaching")
提示:在python2中super的使用需要完整的写成super(自己的类名,self),而在python3中可以简写为super()。总结:
这两种方式的区别是:方式一是继承没有关系的,而方式二的所super()依赖继承的,并且即使没有直接继承关系,super()仍然会按照MRO继续往后查找。类的多态
多态的概念其实不难理解,它是指对不同类型的变量进行相同的操作,它会根据对象(或类)类型的不同而表现出不同的行为。
eg:
a=1+2
print(a) # 3
a='a'+"b"
print(a) # 'ab'
可以看到,我们对两个整数进行 + 操作,会返回它们的和,对两个字符进行相同的 + 操作,会返回拼接后的字符串。
也就是说,不同类型的对象对同一消息会作出不同的响应。
要注意喔,有了继承,才有了多态,也会有不同类的对象对同一消息会作出不同的相应类的封装
有以下几个概念:
封装:就是将数据和功能 "封装" 起来
隐藏:将数据和功能隐藏起来不让用户直接调用,而是开放一些接口抵用从而可以直接在接口添加额外的操作
伪装:将类里面的方法伪装成类里面的数据
注意:
以后我们在编写代码面向对象类定义时,也会看到很多单下划线开头的名字,表达的意思就是隐藏对象,我们就不要直接访问了,可以查找以下下面可能定义的接口
面向对象之反射
反射
什么是反射?
反射的概念是由Smith在1982年首次提出来的,主要是指程序可以访问、检测和修改它本身状态或行为的一种能力(自省)。这一概念的提出很快就引发了计算机科学领域关于反射性的研究。他首先就被程序语言的设计领域采用,并在Lisp和面向对象方面取得了成绩。反射的好处:
1.实现可插拔机制
可以事先定义好接口,接口只有在被完成后才会被真正执行,这实现了即插即用,这其实是一种"后期绑定",什么意思呢?就是你可以事先把最主要的罗家集写好(值定义接口),然后后期再去实现接口的功能。2.动态导入模块(基于反射当前模块成员)

-
在python中,反射指得是通过字符串来操作对象的属性。设计到四哦个内置函数的使用(python中一切皆对象,雷和对象都可以用下面的四个方法)
-
利用字符串操作对象的数据和方法:
1.hasattr() 重点 判断对象是否含有某个字符串对应的属性名或方法名 2.getattr()重点 判断字符串获取对象对应的属性名(值)或方法(函数体代码) 3.setattr() 根据字符串给对象设置或者修改数据 4.delattr() 根据字符串删除对象里面的名字
代码演示:
class Teacher: def __init__(self,full_name): self.full_name =full_name t=Teacher('jason Lin') # hasattr(object,'name') hasattr(t,'full_name') # 按字符串'full_name'判断有无属性t.full_name # getattr(object, 'name', default=None) getattr(t,'full_name',None) # 等同于t.full_name,不存在该属性则返回默认值None # setattr(x, 'y', v) setattr(t,'age',18) # 等同于t.age=18 # delattr(x, 'y') delattr(t,'age') # 等同于del t.age反射实战案例:
1.什么时候应该考虑使用反射 只要需求中出现了关键字 对象....字符串.... # 模拟cmd终端 class WinCmd: def tasklist(self): print(""" 1.学习编程 2.学习python 3.学习英语 """) def ipconfig(self): print( """ 地址:127.0.0.1 地址:上海浦东新区 """) def get(self,target_file): print('获取指定文件',target_file) def put(self,target_file): print('上传指定文件',target_file) def server_run(self): print('欢迎进给简易版cmd终端') while True: target_cmd = input('输入您的指令>>>:').strip() res = target_cmd.split(' ') if len(res) == 1: if hasattr(self,res[0]): getattr(self,res[0]) else: print(f"{res[0]}不是内部或外部指令") elif len(res) == 2: if hasattr(self, res[0]): getattr(self, res[0]) else: print(f"{res[0]}不是内部或外部的指令") obj = WinCmd() obj.server_run() # 2.一切皆对象 # 利用反射保留某个py文件中所有的大写变量名及对应的数据值 import settings print(dir(settings)) # dir列举对象可以使用的名字 useful_dict = {} for name in dir(settings): if name.isupper(): useful_dict[name] = getattr(settings, name) print(useful_dict) #{'NAME': '水水', 'PASSWORD': 'momo'} while True: target_name = input('请输入某个名字') if hasattr(settings, target_name): print(getattr(settings, target_name)) else: print('该模块文件中没有该名字') -
面向对象的魔法方法
魔法方法的特征:
1.都是双下划线开头,双下划线结尾
2.都是python 内部事先定义好的,是对象相关行为的底层实现方法
3.都是在特定情况下'自动'触发的,一般不会直接去调用。魔法方法有哪些:
1.__init__
添加对象独有数据的时候自动触发
2.__str__
对象被执行打印操作的时候自动触发,该方法返回什么就打印什么,并且该方法必须返回一个字符串类型
3.__call__ 即:对象()或者 类 ()()
对象加括号调用的时候自动触发,该方法返回什么,对象调用之后的返回值就是什么
4.__getattr__
对象点不存在的名字的时候就会自动触发,该方法返回点不存在的名字就可以得到什么
5.__getattribute__
对象点名字就会自动触发,有它的存在就不会执行上面的__getattr__(不管点的名字是否存在都会触发)
6.__setattr__
给对象添加或者修改数据的时候自动触发(对象. (点) 名字 = 值)
7.__enter__
当对象被当做with 上下文管理操作的开始自动触发,并且该方法返回什么 as 后面的变量就会接受到什么
8.__exit__
with 上下文管理语法运行完毕之后自动触发(子代码结束)
9.__del__
对象被(执行(被动,主动)删除操作)之后自动执行
python中自带垃圾回收机制
10.___new__
创建一个新的对象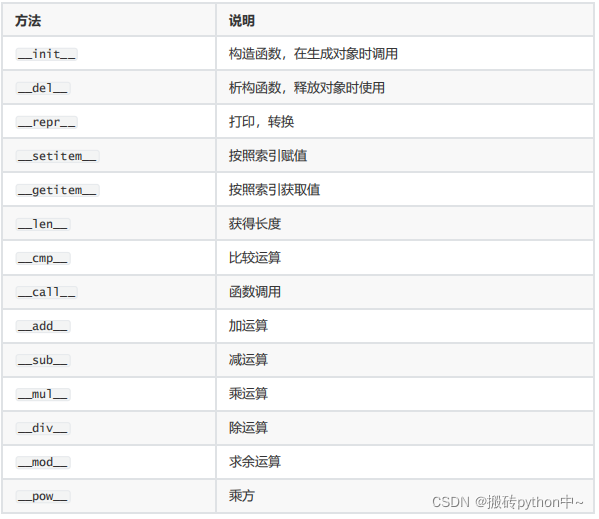
元类
什么是元类?
在python中,一切皆对象,那么类的本质也是一个对象,既然所有的对象都是调用类的到的,那么产生这个类的就是被称为元类(type)>>>>元类就是产生类的类
元类的含义:
- Mate类就是元类一类的类,在python中定义类的关键字class也是一个对象,那么实例化class对象的类就是元类。元类的目的就是为了控制类的创建行为。
元类的生产:
- type作为Python的内建元类,用来控制类的生成的,class对象就是type实例化生成的
python中创建类的方法:
- 1.使用class关键字
- 2.通过type关键字

魔法方法之__new__方法
new方法是为了创建一个新的空对象
概念
触发实机:在对象实例化后触发
参数:至少有一个cls,接收当前的类
返回值:必须返回一个对象
作用:实例化对象
PS:实例化对象是object类底层实现,其他类继承了object 的 __new__ 方法才能够实现实例化对象,没事别碰这个魔法方法,在调用类的时候,会首先自动触发__new__执行里面的代码,才会触发__init__设计模式之单例模式
设计模式
前人通过大量的验证创建出来解决一些问题的固定高效的方法
3.单列模式
定义:确保一个类最多只有一个实例,并提供一个全局访问点(无论类加括号执行多少次,只会产生一个对象)
目的:
当类中有很多非常强大的方法,我们在程序中很多地方都需要使用
1.优点
1.1.单例模式可以保证内存里只有一个实例,减少了内存的开销。
1.2.可以避免对资源的多重占用。
1.3.单例模式设置全局访问点,可以优化和共享资源的访问。
2.缺点
2.1.单例模式一般没有接口,扩展困难。
2.2.单例模式的功能代码通常写在一个类中,如果功能设计不合理,则很容易违背单一职责原单例模式实现的方法:
#单例模式
class C1:
__instance = None
def __init__(self,name,age):
self.name = name
self.age = age
@classmethod
def singleton(cls):
if not cls.__instance:
cls.__instance = cls('水水',100)
return cls.__instance
obj =C1.singleton()
obj2 = C1.singleton()
obj3 = C1.singleton()
print(id(obj),id(obj2),id(obj3)) #id 相同 1981485794784 1981485794784 1981485794784
obj4 = C1('momo',18)
obj5=C1('思思',18)
print(id(obj4),id(obj5)) # 2785972462832 2785972462784pickle序列化模块
Python 中有个序列化过程叫作 pickle,它能够实现任意对象与文本之间的相互转化,也可以实现任意对象与二进制之间的相互转化。也就是说,pickle 可以实现 Python 对象的存储及恢复。
pickle 模块提供了以下 4 个函数供我们使用:
- dumps():将 Python 中的对象序列化成二进制对象,并返回;
- loads():读取给定的二进制对象数据,并将其转换为 Python 对象;
- dump():将 Python 中的对象序列化成二进制对象,并写入文件;
- load():读取指定的序列化数据文件,并返回对象。
dumps() 和 loads() 是基于内存的python对象与二进制互转
dump() 和 load() 是基于文件的python对象与二进制互转
软件开发架构
什么是软件开发架构?
规定程序的请求逻辑,功能的分块
专业:软件架构为软件系统提供了一个结构、行为和属性的高级抽象,由构件的描述、构件的相互作用、指导构件集成的模式以及这些模式的约束组成
软件架构是一种思想,一个系统蓝图,是对软件结构组成的规划和职责设定。一个软件里有处理数据存储的处理业务逻辑的、处理页面交互的、处理安全的等许多可逻辑划分出来的部分。
软件开发架构有两种:
1.c/s 架构 Client (客户端) Sever(服务端)
2.b/s 架构 Browser(浏览器) Sever (服务器、端)两者的区别:
c/s架构
一般我们使用计算机下载的一个个APP的本质就是个大互联网公司的客户端软件
通过这些客户端软件我们就可以体验到各个互联网公司给我们提供的服务
b/s架构
浏览器可以充当所有服务端的客户端
PS:B/s架构本质还是C/s架构
两者的优劣:
C/s架构
优势:不同公司的客户端有不同的互联网公司独立开发的,所以能够高度定制客户端功能
劣势:需要下载才能使用
B/s架构
优势:不需要下载,直接在浏览器访问
劣势:无法高度定制化,并且需要遵守浏览器的很多规则网络编程
什么是网络编程?
基于网络来进行编写代码,能够实现数据的远程交互
网络编程的起源:
基于远程传输数据的技术最早诞生于美国军方(前沿技术通常都是由军事产生)
想要实现计算机之间数据的交互
因为最早的时候只能用硬盘拷贝来进行数据的传输
之后就发明了网络编程网络编程必备的条件:
实现数据之间的远程交互
1.最早期的电话
交互方式:电话线
2.早期的大屁股电脑
交互方式:网线
3.后来的笔记本、移动电话
交互方式:网卡总结:网络编程从大的方面来说就是信息的发送和接受,中间传输为物理线路的作用,所以实现数据交互的必备的基础条件就是物理介质的链接。
网络基础
1.一程序如何在网络上找到另一个程序?
首先,程序必须要启动,其次,必须有这台机器的地址,我们都知道我们人的地址大概就是国家\省\市\区\街道\楼\门牌号这样字。那么每一台联网的机器在网络上也有自己的地址,它的地址是怎么表示的呢?
就是使用一串数字来表示的,例如:100.4.5.6
什么是IP地址?
IP地址是指互联网协议地址(英语:Internet Protocol Address,又译为网际协议地址),是IP Address的缩写。IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
IP地址是一个32位的二进制数,通常被分割为4个“8位二进制数”(也就是4个字节)。IP地址通常用“点分十进制”表示成(a.b.c.d)的形式,其中,a,b,c,d都是0~255之间的十进制整数。例:点分十进IP地址(100.4.5.6),实际上是32位二进制数(01100100.00000100.00000101.00000110)。
IP地址可以精确到具体的一台电脑OSI七层模型
一台完整的计算机系统是由硬件、操作系统、应用软件三者组成,具备了这三个条件。一台计算机系统就可以自己和自己玩了(比如打个单级游戏,玩个扫雷)
如果想要和别人玩,那就需要上网,什么是互联网呢?
互联网的核心就是由一堆协议组成,协议就是标准,比如全世界人通信的标准就是英语,如果把计算机比作是人,互联网协议就是计算机界的英语,所有的计算机都学会了互联网协议,那就是所有的计算机都可以按照统一的标准去收发信息从而完成通信。
osi七层协议:
OSI(Open System Interconnect),即开放式系统互联。 这个开放
式系统互联,是ISO(国际标准化组织)在1985年研究的网络模型。
ISO为了更好的使网络应用更为普及,推出了OSI参考模型。其含义就是
推荐所有公司使用这个规范来控制网络。这样所有公司都有相同的规范,就能互联。OSI七层协议:规定了计算机在远程数据交互的时候必须经过相同的处理流程、在制造的过程中必须拥有相同的功能硬件
七层协议有:应用层,表示层,会话层,传输层,网络层,数据链路层,物理链接层
之后又对七层协议进行了整合
五层协议:应用层,传输层,网络层,数据链路层,物理链接层
四层协议:应用层,传输层,网络层,网络接口层
数据的接受:数据由上往下传递
数据的发送:数据由下往上传递OSI 七层协议 功能
- 应用层:为用户程序提供网路服务,使用的协议有
HTTP、TFTP, FTP, NFS, WAIS、SMTP - 表示层:对信息进行语法处理,可确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取,使用的协议有
Telnet, Rlogin, SNMP, Gopher - 会话层:通过传输层(端口号:传输端口与接收端口)建立不同的会话请求,主要是在系统之间里建立对话以及接收对话。使用的协议为
SMTP, DNS - 传输层:接受上一层的数据,将上层的数据进行分割操作,在当到达目的地址的时候再进行重组,常常把这个数据叫做段。使用的协议
TCP,UDP - 网络层:对在不同地理位置的网络中的两个主机系统提供连接和路径选择,使用的协议有
IP,IPv6, ICMP, ARP, RARP, AKP, UUCP - 数据链路层:定义了数据化格式化传输,如何控制对物理介质的访问,这层提供信息的检测和纠正,以确保数据的可靠性传输,使用的协议有
FDDI, Ethernet, Arpanet, PDN, SLIP, PPP - 物理层:主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流(就是由1、0转化为电流强弱来进行传输,到达目的地后在转化为1、0,也就是我们常说的数模转换与模数转换)。这一层的数据叫做比特,使用的协议有
IEEE 802.1A, IEEE 802.2到IEEE 802.11

网络的专业名词:
1.交换机
能够使接入该机器的所有计算机之间彼此互联
2.广播
就是链接在交换机上的计算机,首次想要和另一台计算机进行交互,到交换机里面去喊一嗓子
3.单播
首次查找的计算机回应查找它的计算机,并附带上自己的Mac地址
4.局域网
可以简单的理解为有交换机组成的网络
在局域网内可以直接使用Mac地址通信
5.广域网
就是范围更大的局域网
6.互联网
可以理解为对个局域网之间彼此互联
7.广播风暴
接入同一台交换机的计算机同一时刻发广播
8.路由器
能够链接多个局域网并实现局域网之间的数据传输传输层:
TCP协议 UDP协议
端口协议
范围:0~65535
特性:动态分配
eg:第一次运行微信 系统随机取一个端口号2022
然后关闭微信重新启动 系统随机取一个端口号
端口号基本使用
0~1024系统默认需要使用的端口号
1024~8000常见软件端口号
以后我们开发的软件最后使用8000之后的端口号
端口号(port):能够唯一标识一台计算机上面正在运行的一款应用程序
IP+PORT:能够定位全世界独一无二的一台计算机上面的某一个应用程序
PS:端口号在同一台计算机同一时刻是不能重复的
我们知道,一台拥有IP地址的主机可以提供许多服务,比如Web服务、FTP服务、SMTP
服务等,这些服务完全可以通过1个IP地址来实现。那么,主机是怎样区分不同的网络
服务呢?显然不能只靠IP地址,因为IP 地址与网络服务的关系是一对多的关系。实际
上是通过“IP地址+端口号”来区分不同的服务的
总结:
Ip+Port 127.0.0.1:8080(用冒号链接)
能够唯一标识世界上某一台接入互联网的计算机上面的某一个正在运行的应用程序TCP协议
流式协议 可靠协议
当应用程序想通过TCP协议实现远程通信时,彼此之间必须先先建立双向通信通道,基于该双向通道实现数据的远程交互,该双向通道直到任意一方主动断开才会失效
三次握手 建立链接
重要状态
listen监听态:等待对方发请求
syn_rcvd态:忙于恢复确认建立请求
# 洪水攻击:服务端在同一时间接收到了大量的要求建立链接的请求
1.TCP协议称为可靠协议(数据不容易丢失)
造成数据不容易丢失的原因不是因为有双向通道,而是因为有反馈机制
给对方发送消息之后会保留一个副本,直到对方对方回应已经收到消息了才会删除
否则会在一定的时间内反复发送
2.洪水攻击
同一时间被大量的客户端请求建立链接,会导致服务端一致处于SYN_RCVD状态
3.服务端如何区分客户端建立链接的请求
可以对请求做唯一标识
四次挥手 断开链接
不能合并成三次:因为中间需要确认消息是否已经发完(TIMS_WAIT)
建立一个连接需要三次握手,而终止一个连接要经过四次握手
当服务端或者客户端不想再与对方进行通信之后,双方任意一方都可以主动发起断开链接的请求,我们还是以客户端主动发起为例
总结:挥手必须是四次,中间的两次不能合并成一次,原因就在于需要检查是否还有数据需要给对方发送

UDP协议
被称为数据报协议,不可靠协议
当应用程序希望通过UDP与一个应用程序通信时,传输数据之前源端和终端不建立连接。
当它想传送时就简单地去抓取来自应用程序的数据,并尽可能快地把它扔到网络上。
数据发送没有通道的概念 发送出去了就不管了
无连接:通信不需要建立连接,只要知道对方地址就可以发送数据
不可靠:不能保证数据是否可以安全、有序的到达对端
面向数据报:一个数据报的最大大小为64k,加上udp数据报头部信息一共64位还要占8个字节,因此数据大小不能超过64k-8。
优点:
快,比 TCP 稍安全。
UDP 没有 TCP 的握手、确认、窗口、重传、拥塞控制等机制,UDP 是一个无状态的传输协议,所以它在传递数据时非常快。没有 TCP 的这些机制,UDP 较 TCP 被攻击者利用的漏洞就要少一些。但 UDP 也是无法避免攻击的,比如:UDP Flood 攻击。
缺点:
不可靠,不稳定。
因为 UDP 没有 TCP 那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。socket模块
简介:
如果我们需要编写基于网络来进行数据交互的程序,那就意味着我们需要通过自己的代码来控制我们之前所学习的OSI七层协议(太过繁琐、复杂,类似于让我们自己编写操作系统)
这时候就可以用到 socket
socket 类似于操作系统,将哪些繁琐复杂的接口进行封装,提供简单快捷的接口
socket 也叫套接字
基于文件类型的套接字家族(单机)
AF_UNIX
基于网络类型的套接字家族(联网)
AF_INET
socket模块的使用
1.socket 接口
socket结构体关键域有so_type,so_pcb。so_type常见的值有:
SOCK_STREAM 提供有序的、可靠的、双向的和基于连接的字节流服务,当使用Internet地址族时使用TCP。
SOCK_DGRAM 支持无连接的、不可靠的和使用固定大小(通常很小)缓冲区的数据报服务,当使用Internet地址族使用UDP。
SOCK_RAW 原始套接字,允许对底层协议如IP或(ICMP)进行直接访问,可以用于自定义协议的开发。
2.bind 接口(绑定一个固定地址)
bind 函数是给 so_pcd 结构中的地址赋值的接口
sockfd 是调用socket()函数创建的socket描述符
addr 是具体的地址
addrlen 表示addr的长度
3.connect 接口
connect就是拿来建立链接的函数(需要相互链接的IP)
只有面向连接、提供可靠服务的协议才需要建立连接
4.listen 接口(半连接池)
这个事描述监听是否有链接的到来,并设置同时能完成的最大连接数。
5.accept 接口(等待接客)
在使用listen函数告知内核监听的描述符后,内核就会建立两个队列,一个SYN队列,表示接受到请求,但未完成三次握手的连接;另一个是ACCEPT队列,表示已经完成了三次握手的队列。
而accept函数就是从ACCEPT队列中拿一个连接,并生成一个新的描述符,新的描述符所指向的结构体so_pcb中的请求端ip地址、请求端端口将被初始化。
6.recv(字节数)
接受客户端发送过来的消息
7.send()
向客户端发送消息,(消息必须是bytes类型)
8.close()
关闭双向通道
PS:以后在写带带码,多看看代码的源码,来养成写带码的思路半连接池的概念:
server.listen(5) # 半连接池
当有多个客户端来链接的情况下 我们可以设置等待数量(不考虑并发问题)
假设服务端只有一个人的情况下
在测试半连接池的时候 可以不用input获取消息 直接把消息写死即可 黏包现象:
1.服务端连续执行三次recv
2.客户端连续执行send
问题: 服务端一次性收到了客户端的三次信息 该现象就被称为“黏包现象”
黏包产生的原因
1.不知道每次接受的数据到底有多大
2.TCP也称为流式协议:数据就像流水 一样绵绵不绝没有间隔(TCP会根据数据量较小且发送间隔较短的多条数据一次性合并打包发走)
避免/解决思路:
如何知道数据具体的大小。
如何将长度变化的数据全部制作成固定的长度的数据
这就要用到 struct模块struct模块
将数据的大小打包成固定的长度并且能够解析回到打包前的大小
struct.pack('i',len(打包的数据)) 打包数据
struct.unpack('i',len(解包的数据)) 解包的数据解决黏包思路:
客户端:
1.制作真实数据的信息字典(数据强度,数据简介,数据名称)
2.利用struct模块制作字典的报头
3.发送固定的长度报头(解析出来是字典的长度)
4.发送字典数据
5.发送真实数据
服务端:
1.接受固定长度的字典报头
2.解析出字典的长度并接受
3.通过字典获取到真实数据的各项信息
4.接收真实数据长度
并发编程理论及操作系统发展史
并发编程理论:
并发编程其实就是在研究计算机底层原理的发展史因为
计算机中真正干活的人就是CPU
除了CPU计算机中的操作系统也是不能少的,从最早的手工操作——穿孔卡片,到后来的批处理系统,再到后来的多道技术,这些发展都是为了能够提升CPU的利用用率。
进程理论及调度算法
什么是进程?
其实进程一直都贯穿着我们的周围,无论是我们使用的智能手机还是电脑,其实都与进程息息相关。比如我们打开某短视频软件,其实就是打开该短视频的一个进程。我们甚至可以说进程就是一个软件的本身,再专业一些的话就是 进程就是程序执行的载体。
对于操作系统来说一个任务就是一个进程,比如打开一个APP就是启动一个APP进程,打开一个浏览器就是启动一个浏览器进程。
总结:进程就是正在执行的程序代码
程序就是一堆还没有执行的代码进程的特征:
1.动态性,是进程最基本的特性,可表现为由创建而产生,由调度而执行,因得不到资源而暂停执行,以及由撤销而消亡,因而进程由一定的生命期。
2.并发性,是进程的重要特征,同时也是OS的重要特征。引入进程的目的正是为了使其程序能和其它建立了进程的程序并发执行。
3.独立性,是指进程实体是一个能独立运行的基本单位,同时也是系统中独立获得资源和独立调度的基本单位。进程的调度算法:(知识点)
1.FCFC(先来先服务)
对于短作业不友好
2.短作业优先调度
对于长作业不友好
3.时间片轮转法+多级反馈队列(目前还在用)
时间片轮转法:先公平的将CPU分给每个人执行
多级反馈队列:根据作业长短的不同再合理分配CPU执行时间
等级越靠下就表示需要耗时的时长就越多,但是优先级就越低
'''目的就是为了能够让单核的计算机也能够做到运行多个程序'''

进程的并行与并发:
并行:
是指多个进程同时执行,必须要有多个CPU同时参与,单个CPU是无法实现并行的(必须是同一时间I运行的才可以被称之为并行)
并发:
是指多个进程看上去狭隘难过时同一时刻执行,单个CPU可以实现,多个CPU也可以。
两者的处理方式:
并发相比并行,处理方式不同,并发是一个处理器同时处理多个任务,并行是多个处理器同时处理多个任务,并发是逻辑同时,并行是物理同时。
并发相比并行,在宏微观上由于处理器的利用方式不同,并发同时轮换多个进程,宏观上保持了进程同时进行,而并行不论宏观微观都是真正的同时进行。
并发执行的特点是使得多个进程在逻辑上同时执行,将多个进程的指令轮换执行,表现为多个进程的执行挂起再执行,在宏观上似乎是同时执行了多个进程。
并发执行类似于时分复用的特点,将CPU处理器进行不同时间利用,达到同时执行多个进程的目的进程的三种状态:
1.就绪态:进程已经获取除了CPU外所有必要的资源,只等待CPU时的状态。系统将多个处于就绪态的进程排成就绪队列。
2.运行态:进程已经获的CPU的权限,正在运行中。单机处理系统中,处于执行状态的进程只有一个,多处理系统中,有多个处于执行状态的进程。
3.阻塞态:正在执行的进程由于某种原因暂时无法执行,变放弃处理机,而处于暂停状态,即进程执行受阻(这种状态又被称为等待状态或封锁状态)

同步与异步
同步:
同步就是一个任务的完成需要依赖另一个任务,只有被依赖的任务完成之后,依赖的任务才能算完成,这是一种可靠的任务序列。
异步:
异步就是不需要等待依赖的任务是否完成,知识通知被依赖的任务工作是什么,就离开,等我那个那个被通知的任务对象完成自己的时候,再向自己反馈,这是一种不可靠的任务序列。
阻塞与非阻塞
阻塞与非阻塞一共有四种形式,分别是以下:
1.同步阻塞形式:
效率最低,拿上面的例子来说,喊了人啥也不做,就干巴巴的站在原地等人。
2.异步阻塞形式:
异步操作是可以被阻塞住的,只不过它不是在处理消息的时候被阻塞,而是在等消息通知的时候被阻塞。
3.同步非阻塞形式:
实际上是效率低下的。
想象一下你一边打着电话一边还需要抬头看到底队伍排到你了没有,如果把打电话和观察排队的位置看成是程序的两个操作的话,这个程序需要在这两种不同的行为之间来回的切换,效率可想而知是低下的。
4.异步阻塞形式:
效率是最高的
例子:
假如在银行办业务,如果是采用的异步阻塞形式的方式,就是自己去领了一个号码,在等待的过程中有自己的事情要做,就告诉大堂经理让他在叫到自己的号码的时候通知你,自己就不会被阻塞在这个等待上面,这就是 异步 +阻塞 的形式注意:
因为很多时候同步操作会以阻塞的形式表现出来,同样的,很多人也会把异步和非阻塞混淆,因为异步操作一般都不会在真正的IO操作处被阻塞。
创建进程的多种方法:
1.鼠标双击程序的图标
2.使用pyhon代码创建进程
创建一个进程(Process类)
创建类需要用到multiprocess,multiprocess不是一个模块而是python中一个操作、管理进程的包。
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)
强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
使用的参数说明:
1. group参数未使用,值始终为None
2 .target表示调用对象,即子进程要执行的任务
3 .name为子进程的名称
4 .args表示调用对象的位置参数元组,args=(1,2,'anne',)
5 .kwargs表示调用对象的字典,kwargs={'name':'anne','age':18}
start() 函数:通过调用它,可以直接启动我们创建的进程。它会马上执行我们进程中传入的函数,start 函数没有任何参数,也没有返回值。join方法
join主要的功能就是用于主线程等待子线程停止运行进程间通信之IPC机制
为了进程安全起见,两个进程之间的数据是不能够互相访问的(默认情况下),进程与进程之间的数据是不可以互相访问的,而且每一个进程的内存是独立的。多进程的资源是独立的,不可以互相访问,如果想多个进程之间实现数据交互就必须通过中间件实现。
进程队列(Queue)通信:
Queue([maxsize]):建立一个共享的队列(其实并不是共享的,实际是克隆的,内部维护着数据的共享),多个进程可以向队列里存/取数据。其中,参数是队列最大项数,省略则无限制。
Queue方法:
from multiprocessing import Queue
q = Queue(3) # 括号内可以指定存储数据的个数
q.put() # 往消息队列中添加数据
q.full() # 判断队列是否已满
q.get() # 从消息队列中取数据
q.empty() # 判断队列是否为空
# 队列为空, 使用get会等待,直到队列有数据以后再取值
q.get()
# 队列为空,取值的时候不等待,但是取不到值那么直接崩溃了
q.get_nowait()
# 建议: 获取队列的数据统一get,因为不能保证代码不会有问题
"""
full() empty() 在多进程中都不能使用!!!因为多进程中不确定性
"""进程对象诸多方法
-
start ()函数:通过调用它,可以直接启动我们创建的进程。它会马上执行我们进程中传入的函数,start 函数没有任何参数,也没有返回值。
-
join ()函数:我们说过,主进程和子进程的程序会同时运行,互不影响。这样就会有一个问题,有可能是 子进程 先执行完它的业务,也有可能是 主进程 先执行完它的业务逻辑。如果有的时候我们必须要先执行完 子进程的业务 再执行 主进程的业务 。则通过调用 join 函数,在这一函数下面执行的主进程业务要等待子进程完成之后才会继续执行。我们将 join 这样的函数叫做 等待/阻塞函数。join 函数没有任何参数,也没有返回值。
-
kill ()函数:如果我们在执行子进程的过程中发现不需要这个子进程继续运行了,就可以使用 kill 函数杀死当前的这个子进程,杀死的这个子进程不会在执行子进程中函数的业务逻辑。kill 函数没有任何参数,也没有返回值。
-
is_alive ()函数:通过调用这个函数可以(判断当前的进程是否是存活状态),它返回一个 bool 值。True 表示当前进程还在,程序还在继续执行;如果是 False 则代表当前进程已经结束了
-
terminate()函数:终止进程
PS:计算机操作系统都有相对应的命令可以直接杀死进程
-
如何查看进程号:
from multiprocessing import Process, current_process current_process() current_process().pid import os os.getpid() os.getppid()

守护进程:
主进程创建守护进程:
1.守护进程会在主进程代码执行结束后就终止
2.守护进程内无法在开启子进程,否则就抛出异常:AssertionError: daemonic processes are not allowed to have children。
注意:进程之间都是相互独立的,主进程代码运行结束,守护进程随即也会终止,但是当有多个子进程时,只有设置了守护进程的子进程才会随着主进程的结束而结束,其他的子进程不受到影响。
互斥锁
通过刚刚的学习,我们千方百计实现了程序的异步,让多个任务可以同时在几个进程中并发处理,他们之间的运行没有顺序,一旦开启也不受我们控制。尽管并发编程让我们能更加充分的利用IO资源,但是也给我们带来了新的问题。
#加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。
虽然可以用文件共享数据实现进程间通信,但问题是:
1.效率低(共享数据基于文件,而文件是硬盘上的数据)
2.需要自己加锁处理
#因此我们最好找寻一种解决方案能够兼顾:
1、效率高(多个进程共享一块内存的数据)
2、帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:
队列和管道
队列和管道都是将数据存放于内存中
队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来,我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。互斥锁代码实操
点击查看代码
import os
import time
import multiprocessing
# 定义一个work函数,打印输出,每次执行的次数与 该次数的进程号,增加线程锁
def work(count,lock):
lock.acquire() # 上锁
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
lock.release() # 解锁
return '\'work\' 函数 result 返回值为:{}, 进程ID为:{}'.format(count, os.getpid())
if __name__ == '__main__':
# 定义进程池的进程数量,同一时间每次执行最多3个进程
pool = multiprocessing.Pool(3)
manger = multiprocessing.Manager()
lock =manger.Lock()
results = [] # 产生的结果放在列表中
for i in range(21):
# ## 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
result = pool.apply_async(func=work,args = (i,lock))
results.append(result)
pool.close()
pool.join()在代码的执行过程中,可以知道每一次只有一个任务会执行。由于每一个进程会被阻塞三秒钟,所以我们的进程执行的非常慢,这是因为每一个进程进入到work()函数中,都会执行上锁,阻塞3秒,解锁的过程,这样就完成了一个进程的工作。下一个进程任务开始,重复这个过程,这就是互斥锁。
多进程实现tcp服务端开发
代码实现:
点击查看代码
import socket
from multiprocessing import Process
def get_sever():
sever = socket.socket()
sever.bind(('127.0.0.1',8080))
sever.listen(5)
return sever
def get_talk(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
if __name__ == '__main__':
sever = get_sever()
while True:
sock,addr =sever.accept()
# 开设多进程去聊天
p = Process(target=get_talk,args = (sock,))
p.start()线程
线程与多线程的概念
在上面讲到了进程和多进程的概念及一些使用的方法,这让我们知道了,平时我们使用的软件就是进程,但是使用进程需要内存和CPU来执行,如过启动过多的进程,就会影响到操作系统的执行效率,有什么办法能解决这一问题呢?就是线程
什么是线程呢:
线程就是进程启动执行任务的 “人”
线程和进程的区别?
进程:是资源单位 ,表示的就是一个内存空间
线程:是执行单位 ,就是真正执行代码指令的
注意:一个进程内可以开设多个线程,同一个进程下的线程的资源是共享的;而创建进程的资源消耗是远远高于线程的
PS:线程是操作系统最小的执行单位,一个进程至少由一个线程组成。
总结: 线程是依赖进程的,先有进程,才会有线程。并且进程中的主线程,还可以在创建多个线程。那我们该如何区分主线程与子线程的呢?其实很好理解,我们正常执行的脚本就是通过一个主进程下的主线程去完成的。
我们说过,在主进程下通过创建一些进程去做一些业务。那是主进程生成的子进程,其实严格的说也这是主进程下的主线程来帮助完成创建的。
多线程:
上面说过一个进程可以开设多个线程,只不过在一个进程下的多个线程只会共享当前进程的内存资源。
所以我们想一下,在一个进程中创建多个线程是否会比创建多个进程更加的节省资源呢?在某些情况下是的。我们作为初学先不要考虑太多的复杂场景,当下我们先只要认为多线程要比多进程更加的节省资源即可。
python中的多线程有什么作用?
计算密集型:
所谓的计算密集型,就是要进行大量的计算,消耗CPU资源
IO密集型:
涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少, 任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。 对于IO密集型任务,任务越多,CPU效率越高.
需要分情况
1.单个CPU、多个CPU
2.IO密集型(有IO)、计算密集型(代码没有IO)
1.1单CPU
IO 密集型
多进程
申请额外的空间,消耗更多的资源
多线程
消耗资源相比较较少,通过多道技术
PS:多线程更有优势
计算密集型
多进程
申请额外的空间,消耗更多的资源(总耗时+申请空间+拷贝代码+切换)
多线程
消耗资源相较小,通过多道技术(总耗时+切换)
PS:多线程有优势
2.1多个CPU
IO密集型
多进程:总耗时(单个进程的耗时+IO+申请空间+拷贝代码)
多线程:总耗时(单个进程的耗时+IO)
ps:多线程有优势!!!
计算密集型
多进程:总耗时(单个进程的耗时)
多线程:总耗时(多个进程的综合)
ps:多进程完胜!!!代码演示:
点击查看代码
from threading import Thread
from multiprocessing import Process
import os
import time
def work():
# 计算密集型
res = 1
for i in range(1, 100000):
res *= i
if __name__ == '__main__':
# print(os.cpu_count()) # 12 查看当前计算机CPU个数
start_time = time.time()
# p_list = []
# for i in range(12): # 一次性创建12个进程
# p = Process(target=work)
# p.start()
# p_list.append(p)
# for p in p_list: # 确保所有的进程全部运行完毕
# p.join()
t_list = []
for i in range(12):
t = Thread(target=work)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print('总耗时:%s' % (time.time() - start_time)) # 获取总的耗时
"""
计算密集型
多进程:5.665567398071289
多线程:30.233906745910645
"""
def work():
time.sleep(2) # 模拟纯IO操作
if __name__ == '__main__':
start_time = time.time()
# t_list = []
# for i in range(100):
# t = Thread(target=work)
# t.start()
# for t in t_list:
# t.join()
p_list = []
for i in range(100):
p = Process(target=work)
p.start()
for p in p_list:
p.join()
print('总耗时:%s' % (time.time() - start_time))
"""
IO密集型
多线程:0.0149583816528320
多进程:0.6402878761291504
"""创建线程的方式
在python中有很多的多线程模块,在这里我们将使用threading模块进行创建。
threading模块
Thread 的动能介绍:通过调用 threading 模块的 Thread 类来实例化一个线程对象;它有两个参数: target 与 args (与创建进程时,参数相同)。target 为创建线程时要执行的函数,而 args 为是要执行这个函数时需要传入的参数。代码演示:
点击查看代码
方式一:
from threading import Thread
from multiprocessing import Process
import time
def task(name):
print(f'{name} is running')
time.sleep(0.1)
print(f'{name} is over')
# 进程运行时间
# if __name__ == '__main__':
# star_time = time.time()
# p_list = []
# for i in range(100):
# p = Process(target=task,args=('用户%s'%i,))
# p.start()
# p_list.append(p)
# for p in p_list:
# p.join()
# print(time.time() - star_time) # 结果:2.506303071975708
# 线程运行时间
star_time = time.time()
t_list = []
for i in range(100):
t=Thread(target=task,args=('用户%s'%i,))
t.start()
t_list.append(t)
for t in t_list:
t.join()
print(time.time()-star_time) # 结果:0.12558937072753906
t = Thread(target=task,args=('水水',))
t.start()
print('主线程')
# 输出结果:
0.12558937072753906
水水 is running
主线程
水水 is over
方式二:
class MyThread(Thread):
def run(self):
print('run is running')
time.sleep(1)
print('run is over')
obj = MyThread()
obj.start()
print('主线程')
#输出结果:
run is running
主线程
run is over
总结:通过上面的代码,我们可以发现线程的使用方法和进程方法是一模一样的,他们都可以互不干扰的执行程序,也可以使主线程的程序不需要等待子线程的任务之后在去执行,只不过在上面的代码中我们使用了join()函数进行了阻塞,这里可以把join()去掉看看效果。
与进程一样,线程也存在着一些问题:
线程执行的函数,也同样是无法获取返回值的
当多个线程同时修改文件一样会 造成被修改的文件的数据错乱 的错误(因为都是并发去操作一个文件,特别是在处理交易场景的时候尤为注意)。
关于线程中存在的问题同样是可以解决的,在面的 线程池与全局锁 我们会有详细的介绍
线程的诸多方法:
-
start 函数:启动一个线程;没有任何返回值和参数。
-
join 函数:和进程中的 join 函数一样;阻塞当前的程序,主线程的任务需要等待当前子线程的任务结束后才可以继续执行;参数为 timeout:代表阻塞的超时时间。
-
getName 函数:获取当前线程的名字。
-
setName 函数:给当前的线程设置名字;参数为 name:是一个字符串类型
-
is_alive 函数:判断当前线程的状态是否存活
-
setDaemon 函数:它是一个守护线程;如果脚本任务执行完成之后,即便进程池还没有执行完成业务也会被强行终止。子线程也是如此,如果希望主进程或者是主线程先执行完自己的业务之后,依然允许子线程继续工作而不是强行关闭它们,只需要设置 setDaemon() 为 True 就可以了。
-
current_thread() 查看线程号
-
active_count() 返回正在运行的线程数量
守护线程:
对于主进程来说:运行完毕值的是主进程代码运行完毕
对于主线程来说:运行完毕指的是主线程所在是的进程内所有非是守护线程统统运行完毕后主线程运行才算运行完毕。
1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束,
2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
PS:无论是进程还是线程,都遵循守护 会等待 主 运行完毕后被销毁。需要强调的是:运行完毕并非终止运行PS:通过上面的介绍,会发现其实线程对象里面的函数几乎和进程对象中的函数非常相似,它们的使用方法和使用场景几乎是相同的。
全局解释器锁
在官方的文档中,对它的解释是:
在CPython中,全局解释器锁(GIL)是一个互斥量,它可以防止多个本机线程同时执行Python字节码。这个锁是必要的,主要是因为CPython的内存管理不是线程安全的。(然而,由于GIL的存在,其他特性已经发展到依赖于GIL强制执行的保证。解释器锁的本质就是互斥锁,就是用来阻止同一个进程内多个线程同时执行,而且GIL的存在是因为python解释器中内存管理不是线程安全的(垃圾回收机制)
GIL的作用
因为有GIL锁使得python的多线程无法在多个CPU上去执行任务,他只能在单一的CPU上进行工作。
这也限制了多线程的性能,毕竟 Python 的多线程只能在一条跑道上运行。跑道满了,运行速度依然会慢。而在多个跑道上运行的任务必然是要比单一跑道效率会高很多。
之所以保留 GIL 锁,其实也是为了线程之间的安全。
GIL与互斥锁的区别:
上面讲到,cpython解释器中有GIL,那么是不是代表以后我们写代码就不需要操作锁了,
答案是否定的,因为GIL只能确保同进程内多线程数据不会被来及回收机制弄乱,并不能保证程序里面的数据是否安全。
死锁现象
锁 的使用可以让我们对某个任务在同一时间只能对一个进程进行开发,但是是锁也不是可以随便用的。以为如果某些原因造成锁解不开,就会造成死锁的现象,这样就会无法在进行操作了。
死锁: 就是至两个或者两个及以上的进程或线程在执行的过程中,因为争夺资源而造成的一种互相等待的现象,若是没有外力作用,他们就会无法推进下去。此时称系统处于死锁状态或操作系统产生了死锁。
代码演示:
点击查看代码
# acquire()
# release()
from threading import Thread,Lock
import time
mutexA = Lock() # 产生一把锁
mutexB = Lock() # 产生一把锁
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print(f'{self.name}抢到了A锁')
mutexB.acquire()
print(f'{self.name}抢到了B锁')
mutexB.release()
print(f'{self.name}释放了B锁')
mutexA.release()
print(f'{self.name}释放了A锁')
def func2(self):
mutexB.acquire()
print(f'{self.name}抢到了B锁')
# time.sleep(1) # 若是这里不添加阻塞就会顺利的所有的人都能拿到所
mutexA.acquire()
print(f'{self.name}抢到了A锁')
mutexA.release()
print(f'{self.name}释放了A锁')
mutexB.release()
print(f'{self.name}释放了B锁')
for i in range(10):
obj = MyThread()
obj.start()
# 输出结果:这里是添加了time.sleep(1)
# Thread-1抢到了A锁
# Thread-1抢到了B锁
# Thread-1释放了B锁
# Thread-1释放了A锁
# Thread-1抢到了B锁
# Thread-2抢到了A锁
进程池与想成池
进程和线程能否无限制的创建 答案是当然不可以
因为引荐的发展赶不上软件,有物理极限,如果我们在编写代码的过程中无限制的创建进程或者线程可能会导致计算机奔溃
“什么是池”
有池的存在,能降低程序的执行效率,但是你保障了计算机的硬件的安全
进程池:
就是提前建好固定数量的进程供后续程序的调用,超出则等待
线程池:
就是提前创建好固定的的数量的线程供后续程序的调用,超出则等待
比如这个红色矩形阵列就代表一个进程池子,在这个池子中有6个进程。这6个进程会伴随进程池一起被创建,不仅如此,我们在学习面向对象的生命周期的时候曾经说过,每个实例化对象在使用完成之后都会被内存管家回收。
我们的进程也会伴随着创建与关闭的过程而被内存管家回收,每一个都是如此,创建于关闭进程的过程也会消耗一定的性能。而进程池中的进程当被创建之后就不会被关闭,可以一直被重复使用,从而避免了创建于关闭的资源消耗,也避免了创建于关闭的反复操作提高了效率。
当然,当我们执行完程序进程池关闭的时候,进程也随之关闭。
当我们有任务需要被执行的时候,会判断当前的进程池当中有没有空闲的进程(所谓空闲的进程其实就是进程池中没有执行任务的进程)。有进程处于空闲状态的情况下,任务会找到进程执行该任务。如果当前进程池中的进程都处于非空闲状态,则任务就会进入等待状态,直到进程池中有进程处于空闲状态才会进出进程池从而执行该任务。
进程池的创建模块 - multiprocessing
创建进程池函数- Pool
image
Pool功能介绍:通过调用 "multiprocessing" 模块的 "Pool" 函数来帮助我们创建 "进程池对象" ,它有一个参数 "Processcount" (一个整数),代表我们这个进程池中创建几个进程。
进程池的常用方法:

- apply_async 函数:它的功能是将任务加入到进程池中,并且是通过异步实现的。它有两个参数:func 与 agrs , func 是加入进程池中工作的函数;args 是一个元组,代表着签一个函数的参数,这和我们创建并使用一个进程是完全一致的。
- close 函数:当我们使用完进程池之后,通过调用 close 函数可以关闭进程池。它没有任何的参数,也没有任何的返回值。
- join 函数:它和我们上面节学习的 创建进程的 join 函数中方法是一致的。只有进程池中的任务全部执行完毕之后,才会执行后续的任务。不过一般它会伴随着进程池的关闭(close 函数)才会使用。
apply_async 函数演示案例
点击查看代码
定义一个函数,打印输出该函数 每次被执行的次数 与 该次数的进程号
定义进程池的数量,每一次的执行进程数量最多为该进程池设定的进程数
import os
import time
import multiprocessing
def work(count): # 定义一个 work 函数,打印输出 每次执行的次数 与 该次数的进程号
print('\'work\' 函数 第 {} 次执行,进程号为 {}'.format(count, os.getpid()))
time.sleep(3)
# print('********')
if __name__ == '__main__':
pool = multiprocessing.Pool(3) # 定义进程池的进程数量,同一时间每次执行最多3个进程
for i in range(21):
pool.apply_async(func=work, args=(i,)) # 传入的参数是元组,因为我们只有一个 i 参数,所以我们要写成 args=(i,)
time.sleep(15) # 这里的休眠时间是必须要加上的,否则我们的进程池还未运行,主进程就已经运行结束,对应的进程池也会关闭。
线程池的创建——concurrent
concurrent 是 Python 的内置包,使用它可以帮助我们完成创建线程池的任务。
通过调用 concurrent 包的 futures 模块的 ThreadPoolExecutor 类,通过实例化 ThreadPoolExecutor 实现创建线程池的对象,它有一个参数来设置 线程池的数量。这和创建进程池设置的数量是完全相同的。
线程的常用方法:

- submit 函数:通过 submit 函数将参数传入;该函数传入的参数也是传入要执行的函数与该函数的参数,由于它的参数并不用需要通过赋值语句的形式传入,只需要把相应的值传入就可以了(稍后会进行一个练习)。
- done 函数:判断当前线程是否执行完成;返回值是 bool 类型。
- result 函数:返回当前线程池中线程任务的执行结果,通过这种方法就可以获取线程池的返回值了。
代码演示:
点击查看代码
1、定义一个函数实现循环的效果
2、定义一个线程池,设置线程的数量
import time
from concurrent.futures import ThreadPoolExecutor
def work(i):
print('第 {} 次循环'.format(i))
time.sleep(1) # 之所以每次都要使用 sleep 函数,是因为函数执行太快;通过 sleep 尝试模拟一下长时间的执行一个任务
if __name__ == '__main__':
thread_poor = ThreadPoolExecutor(4) # 实例化一个线程池,设置线程数量为4
for i in range(20):
thread_poor.submit(work, (i,)) # 利用 submit 函数将任务添加至 work 函数
PS: 需要注意的是,运行结果有可能是出现将两个或者多个任务的结果在同一行打印输出,
这是因为在同一时间处理了多个线程的任务,这也叫 "并发"。
协程:
进程:资源单位
线程:执行单位
协程:单线程下实现并发(效率极高)
在代码层面欺骗CPU 让CPU觉得我们的代码里面没有IO操作
实际上IO操作被我们自己写的代码检测 一旦有 立刻让代码执行别的
(该技术完全是程序员自己弄出来的 名字也是程序员自己起的)
核心:自己写代码完成切换+保存状态
如何不断的提升程序的运行效率
多进程下开多线程 多线程下开协程
点击查看代码
import time
from gevent import monkey;
monkey.patch_all() # 固定编写 用于检测所有的IO操作(猴子补丁)
from gevent import spawn
def func1():
print('func1 running')
time.sleep(3)
print('func1 over')
def func2():
print('func2 running')
time.sleep(5)
print('func2 over')
if __name__ == '__main__':
start_time = time.time()
# func1()
# func2()
s1 = spawn(func1) # 检测代码 一旦有IO自动切换(执行没有io的操作 变向的等待io结束)
s2 = spawn(func2)
s1.join()
s2.join()
print(time.time() - start_time) # 8.01237154006958 协程 5.015487432479858MySQL数据库
为什么会有数据库的出现?
数据库的出现统一了数据路径,统一了数据的操作方式,降低了学习成本,提高了开发效率
数据库简介
官方的定义:数据库是 "按照数据结构来组织、存储和管理数据的仓库"。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
数据库的用途:
共享数据:数据包括所有用户可同时存取数据库中的数据,也包括使用者可以通过接口使用数据库获取的数据。
减轻冗余程度:和文件系统相比避免了使用者各自建立各种文件。减少了大量重复数据,减少了冗余的数据。
集中控制数据:文件管理中,数据分散,不同的用户或同一用户在不同处理中其文件之间无关。数据库可对数据进行集中控制,管理。
确保数据的安全可靠:安全性控制,完整性控制,并发性控制,在同一时间周期内,可对数据实现多路存取,防止用户之间的不正常交互作用。
恢复故障: 及时发现故障并修复,防止数据被破坏。数据库能尽快恢复数据库系统运行时出现的故障。
数据库的本质
1.站在底层原理的角度
数据库指得是操作数据的进程(就是一堆代码)
2.站在实际应用的角度
数据库指的是可视化操作界面(就是一些软件)
PS:以后在不做特殊情况的说明下,讲数据库其实就是指数据库软件
数据库的本质也是CS架构的数据库的分类
数据库被分为两类:关系型数据库,非关系型数据库。
关系型数据库
关系型数据库的定义:关系型数据库是数据库的一种类型,是指使用了关系模型的数据库系统。
其实很简单,数据库是用来存放数据的,如果将数据都写到一个数据文件里,比如说既有人员信息,又有交易记录等等,这样的数据文件就不是那么的好管理。数据乱七八糟的,数据库要经常去判断数据的归属类型,这样一来的话数据的读取速度就会变慢。
例:
人员基本信息保存到名为 user_info 的文件里
交易消费信息保存到 transaction 的文件里
亲属关系信息保存到 mail_list 的文件里以上数据分开单独存放,但是数据之间还是会有关联关系的。比如说 “人员信息” 与 “亲属关系” 就是有关联关系的,需要的时候可以从数据库多个数据文件里联合提取出数据,并不是数据拆分完之后就无法联合提取信息了。
所以 "关系型数据" 总结成一句话:数据分类存放在不同的文件里,数据之间是可以有关联关系的。
关系数据库的特征:
1.拥有固定的表结构(字段名,字段类型)
2.数据之间可以建立数据库层面的关系
关系型数据库软件有哪些:
1.MySQl:这个数据库是我们接下来要学习的内容之一;它是一款开源免费的产品,使用最广,性价比还很高
2.Oracle:收费,使用的成本较高,但是安全性也是最高
3.PostgreSQL:这也是一款开源免费的产品,支持二次开发,兼容性是极高的
4.MariaDB:跟MySQL是一个作者,开源免费。因为担心以后MySQL会收费导致一些小公司用不起,就编写这个软件。
5.sqlite:小型数据库 主要用于本地测试
6.SQL server :这款数据库是 微软出品,图形界面做的挺不错,而且在教育领域是让大家免费使用的。(很多大学在将数据库课程的时候用的就是这款数据库)上面几种数据库都是跨平台的,在各个操作系统上都能安装,唯独 SQL server 很特殊。早期微软出品的数据库只能安装在 Windows 系统。所以也就造成了在生产领域没人会去使用,不建议使用。虽然说最近的 SQL server 也支持了 Linux 系统,但是长期没有人使用,当你遇到问题的时候在查找资料时也会遇到很多的困难,所以…非关系型数据库
因为 SQL语句是来操作关系型数据库的,所以大家常常将非关系型数据库也叫做 NoSQL数据库。
什么是非关系型数据库?
NoSQL 数据库也是把数据分类存储到不同的数据文件里面, 但是数据之间是没有关联关系的,这是因为 NoSQL 数据库根本就没有提供 SQL语言 从多个数据库问价提取关键数据。
非关系型数据库特征:
1.没有固定的表结构,数据的存储采用的是k:v键值对的形式
2.数据之间无法建立数据库层面的关系,可以自己编写代码建立逻辑层面的关系
非关系型数据库使用的软件:
Redis:一种用内存来保存数据的 NoSQL 数据库,新浪微博用它来保存很多大V用户的热点信息,内存的速度是远远超过硬盘的,所以 Redis 的读写速度要比硬盘快很多。(缓存数据库)
MemCache:也是一种使用内存来保存数据的 NoSQL 数据库。(已经被Redis淘汰了)
MongoDB: 是一种使用硬盘保存数据的 NoSQL 数据库(文档型数据库,最像关系型数据库的非关系型数据库),保存海量低价值的数据是非常适合的;比如说新闻、留言、回帖等等。
"""
虽然数据库软件有很多 但是操作方式大差不差 学会了一个几乎就可以学会所有
其中以MySQL最为典型
"""MySQL的基本使用(cmd)
首先打开cmd窗口,建议以管理员的身份打开
1.切换到mysql的bin目录下县启动服务端
mysqld
2.保持窗口不关闭,重新打开一个新的cmd窗口
3.切换到mysql的bin 目录下启动客户端
mysql
直接使用mysql命令默认是游客模式,权限和功能与管理员相比少了很多
登录方式:
mysql -u用户名 -p密码
管理员默认是没有密码的,连续回车就可以了
登录方式:
mysql -uroot -p
PS:有的计算机在启动服务端的时候可能会出现报错,不必惊慌,将报错信息拷贝到百度进行搜索解决问题。
系统服务的制作
1.先把bin目录添加到环境变量中
清空之前打开的cmd窗口,一定要把之前使用cmd启动的服务端关闭(Ctrl + c)
2.将MySQL添加到系统服务中
1.如何查看系统服务
鼠标右键任务栏选择服务
cmd输入 service.msc 回车
2.以管理员身份打开cmd窗口
mysqld --install
3.首次添加不会自动启动,需要认为操作一下
1.鼠标右键点击启动
2.命令行启动
net start mysql
如果想要卸载的话,可以按照
1.关闭服务端
set stop mysql
2.移除系统服务
mysqld --remove密码的相关操作:
1.修改密码
方式一:mysqladmin
mysqladmin -u用户名 -p原密码 password 新密码
方式二:
直接修改存储用户数据的表
方式三:比较冷门,有的版本可能还不支持
set password = password('新密码') #只是修改当前用户的密码
2.忘记密码处理方式:
1.卸载重新装
2.把data目录删除,拷贝其他人的目录
3.小技巧
1.关闭正常的服务端
2.以跳过授权表的方式重启服务端(不校验密码)
3.以管理员的身份进入然后修改mysql.user表数据即可
net stop mysql
mysql --skip-grant-table
mysql -uroot -p
update mysql.user set
password = password('111') wher host='localhost'and User='root';
4.关闭服务端,然后以正常方式启动即可数据库的相关概念
什么是数据:
事物的状态
什么数记录
由一组数据所构成一条记录,在文件中的内容
什么是表
简单来说就是文件夹里的文件
什么是库
就是指文件夹
什么是数据库管理系统
管理数据的套接字软件,cs架构
常见的SQL语句
温馨小提示:
sql语句必须以分号作为结尾(;)
SQL语句编写错误之后不用担心,可以直接执行报错即可
查看数据库:
1.查看所有库名称
show database;
2.查看所有表名称
show tables;
3.查看所有的记录
select * from mysql.user;基于库的增删改查
1.创建库
create database 库名;
2.查看库
show databases; '查看所有的库的名称'
show create database 库名;;'查看指定库的信息'
3.编辑库
alter database 库名 charset='utf8';
4.删除库
drop database 库名;
基于表的增删改查
操作表之前需要先确定库
create database '操作的库名';
切换操作库
user db1;
1.创建表
create table 表名(字段名 字段类型,字段名 字段类型);
2.查看表
show tables; 查看库下所有的表名称
show create table 表名;查看指定表信息
describe 表名;查看表结构
desc 表名;
PS;如果想跨库看其他表,只需要在表名前加上库名即可
desc mysql.user;
3.编辑表
alter table 表名 rename 新表名;
4.删除表
drop table 表名;
基于记录的增删改查
1.插入数据
insert into 表名 values(数据值1,数据值2);
2.查询数据
select * from 表名; '查询表中所有的数据'
3.编辑数据
update 表名 set 字段名=新数据 where 筛选条件;
4.删除数据
delete from 表名;
delete from 表名 where id=2;字符编码与配置文件
在配置文件中,我们可以设置MySQL的各种配置,例如,字符集,端口号,目录地址、、、配置很多,但是我们按照功能来进行区域划分,主要分为三块:
- client:第三方客户端的配置信息,配置的是图形界面设置。
- mysql:客户端配置信息,配置的是命令行及客户端的一些设置。
- mysqld:服务端也就是数据库的配置信息,配置的是服务端的一些信息。
配置文件的操作
1.\s查看MySQL相关信息
当前的用户。版本。编码、端口号
MySQL5.6及之前的版本编码是需要人文统一的,但之后的版本已经全部默认统一了。
想要永久的修改编码配置,需要操作配置文件
2.默认的配置文件名是 my-default.ini
拷贝上述文件并重命名为my.ini
直接拷贝字符编码相关配置即可(以下的代码)
[mysqld]
character-set-serever=utf8mb4
collation-server=utf8mb4_general_ci
[client]
default-character-set=utf8mb4
[mysql]
deffault-character-set=utf8mb4
我们也可以将我们的登录账号和密码也直接写在配置文件中,之后使用的时候直接mysql登录即可
[mysql]
user ='root'
password =123
重新修改配置文件
1.临时修改
在当前客户端内有效
set session sql_mode = 'strict_trans_tables';
在当前服务端有效
set global sql_mode='strict_trans_tables';
2.永久修改
将下面的代码添加到mysqld配置文件中,然后回到cmd终端,退出服务端,重新启动即可
sql_mode=STRICT_TRANS_TABLES
小知识点:
1.utf8mb4能够存储一些表情,功能更多
2.utf8与邨-8是有一定的区别的,MySQL中只有utf8数据库的存储引擎
存储引擎: 存取数据,为存储的数据建立索引,更新。查询数据。
因为在关系型数据库中数据是以表的形式存储,所以存储引擎也称为表类型。
查看常见的存储引擎的方式:
show engines;或者show variablkes like 'have%';
了解的四个存储引擎:
MyISAM 、InnoDB、Memory 、BlackHole
Myisam:
MySQL 5.5 之前默认存储引擎,具有检查和修复表的大多数工具,mysql表可以被压缩,而且还支持全文索引。
缺点:不支持事务安全,不支持外键,安全性较低。
InnoDB:
MYSQL 5.5 之后默认的存储引擎,支持事物、行锁、外键等操作,存取速度相较MyISAM慢一点,但是安全性更高了,InnoDB存储引擎的表支持全文索引,大幅提升了InnoDB存储引擎的文本检索能力。
InnoDB表空间分为共享表空间、独享表空间。
适用场景:需要事务支持、行级锁定对高并发有很好地适应能力,但需要确保查询是通过索引完成、数据更新较为频繁。
Memory
将表中的数据存放在内存中,如果数据库重启或发生崩溃,表中的数据都将消失。
适用于存储临时数据的临时表,以及数据仓库中的纬度表。
MySQL数据库使用MEMORY存储引擎作为临时表来存放查询结果集。
默认使用哈希索引,而不是通常熟悉的 B+ 树索引。
只支持表锁,并发性能较差。
不支持text和blob列类型。
会浪费内存,比如:存储变长字段(varchar)时是按照定长字段(char)的方式进行(基于内存存取数据,仅用于历史表数据存取)
BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库;任何写入进去的数据都会立刻丢失
SQL 语句是不区分大小写,但是字符串内容是区分大小写的(见下面的例句,可以先不用理解什么意思),比如下面这条SQL语句:
SELECT * from mysql.USER WHere USER = 'dev';
-- 该SQL语句的 SELECT 、from 、WHere 三个关键字 就是大小写不区分或混着编写的,但是并不影响它的执行与查询结果;
-- 但是 字符串的 'dev' 就需要明确的区分大小写了,因为它是作为一个 '值' 传入到数据库进行数据比对结果查询的。
创建表的完整语法
create table 表名(
字段名 字段类型(数字) 约束条件,
字段名 字段类型(数字) 约束条件,
字段名 字段类型(数字) 约束条件
);
1.字段名和字段类型是必须的
2.数字和约束条件是可选的
3.约束条件也可以写多个 空格隔开即可
4.SQL 语句中的空白和换行是没有限制的,但是不能破话语句的语法结构
5.SQL 语句必须以英文的分号结尾, ";"
"约束" 是对该列的一个条件约束,比如说某字段为 "姓名" 一栏,"约束" 姓名字段不能为空
ps:编写SQL语句报错之后不要慌 仔细查看提示 会很快解决
eg;near ')' at line 7
MySQL字段基本数据类型
字段类型之数值类型

说明:
- 在MySQL中,数值类型都可以指定是有符号的还是无符号的,默认是有符号的。可以在数值类型后面加unsigned来说明某个字段是无符号的。
- 不要因为范围的原因而使用unsigned。比如对于int类型可能存放不下的数据,int unsigned同样可能存放不下,与其如此,还不如设计时,将int类型提升为bigint类型。
- MySQL对于数据的存储,本身具有很严格的约束。说准确点,MySQL数据类型本身就是一种约束。
字段类型之浮点型
语法:
float(m, d) [unsigned]: M指定显示长度,d指定小数位数,占用空间4个字节空间。
float(20,10)
总共存储20位数 小数点后面占10
double(20,10)
总共存储20位数 小数点后面占10
decimal(20,10)
总共存储20位数 小数点后面占10
create table t7(id float(60,20));
create table t8(id double(60,20));
create table t9(id decimal(60,20));
insert into t7 values(1.11111111111111111111);
insert into t8 values(1.11111111111111111111);
insert into t9 values(1.11111111111111111111);
三者的核心区别在于精确度不同
float < double < decimal字段类型之字符类型
char (固定长度字符串)
语法:
char(len): 固定长度字符串,len表示可以存储的字符长度,最大值可为255
char(4) 意思是最多存储四个字符超出就报错,不够四个就用空格填充至四个
ps;默认情况下,MySQL针对char的存储会自动填充和删除空格
varchar(可变长度字符串)
语法:
varchar(len):可变长度字符串,len表示最大允许存储的字符长度,规定最大允许存储65535个字节大小的字符,具体最大字符个数由字符集种类决定。
varchar(4) 最多存储四个字符,超出就报错,不够的话有几位就存几位
create table 表名1 (id int, name char(4));
craete table 表名2 (id int,name varchar(4));
insert into 表名1 values(1,'Andy');
insert into 表名2 values(1,'andy');
PS:我们想要查看到字段的存储的具体长度,可以使用:
char_length()
两者的优缺点:
char 定长
优势:整存整取,速度快
缺点:浪费存储空间
varchar 变长
优势:节省存储空间
缺点:存取数据的速度相较char较慢
总结:两者的使用场景还需结合具体的场景和具体的业务来进行具体的使用
数字的含义
数字在很多的地方都是用来表示限制存储数据的长度,但是在整型中数字却不是用来限制存储长度的。
🐠: 平时没有在定义整数的时候没有特殊指定的情况下,一般都是默认使用 int 类型。
🐠:单精度浮点数与双精度浮点数在表示数字的时候并不是很精确,是有误差的。在保存精度不是很高的情况下,可以使用 float、double。
🐠:在对浮点数精度要求非常高的情况下,比如涉及到金额的时候,就需要使用到 "decimal" 了,该数据类型表示的是 "精确的数字类型"
🐠:float和double在不指定精度时,默认会按照实际的精度(由计算机硬件和操作系统决定),decimal如果不指定精度,默认为(10,0);
🐠:浮点数相对于定点数的优点是在长度一定的情况下,浮点数能够表示更大的范围;缺点是会引起精度问题。

最后再强调一下: 在 MySQL 中,定点数以字符串形式存储,在对精度要求比较高的时候(如货币、科学数据),使用 decimal的类型比较好;另外两个浮点数进行减法和比较运算时也容易出问题,所以在使用浮点数时需要注意,并尽量避免做浮点数比较。
字段类型之枚举与集合
枚举:
enum:枚举,“单选”类型。该设定提供了若干个选项的值,最终一个单元格中实际只存储了其中一个值。出于效率考虑,这些值实际存储的是“数字”,因为这些选项中每个选项的值依次对应如下数字:1,2,3,…最多65535个,所以我们在添加枚举值时,也可以用数字编号去代替具体的选项值。
枚举语法:enum(‘选项1’, ‘选项2’, ‘选项3’,…);
集合:
set:集合,“多选”类型。该设定提供了若干个选项的值,最终一个单元格中可存储其中任意多个值。出于效率考虑,这些值实际存储的仍是“数字”;最后按顺序每个选项值依次对应到如下数字:1,2,4,8,16,32,… 最多64个。
集合语法:set(‘选项值1’, ‘选项值2’, ‘选项值3’, …);
PS:在向set类型的字段插入数据时,把需要的选项统一写到一个共同的单引号中用逗号隔开,且逗号后面不能有空格。
🐳总结:
如果你给出了enum的范围,那在插入时只能多选一,且插入的字段必须在enum中出现。
如果你限定了set的范围,那么可以多选多,插入的字段必须在set中出现。
实践:
点击查看代码
枚举 多选一
create table 表名(
id int,
name varchar(32),
gender enum('male','femle','others')
);
insert into 表名 values(1,'tony','猛男');
结果:报错
insert into 表名 values(2,'jason','male');
结果:添加成功
insert into 表名 values(3,'kevin','others');
结果;添加成功
PS:名字的长度要按照规定写,名字没有按照规定写会报错,选择的属性必须是存在的,要是不存在就会直接报错,
集合 多选多(多选一)
crate table 表名(
id int,
name varcvhar(16),
hobbies set ('read','drawing','sing')
);
insert into 表名 values(1,'write');
结果:报错
insert into 表名 values(2,'read','sing');
结果:添加成功
insert into 表名 values(3,'read','drawing','sing');
结果:添加成功
PS:添加的属性必须是提前规定好,选择的属性不存在就会报错,全选或者选其中的几个都是可以的字段类型之时间
datetime 用于表示 年月日时分秒
date 用于表示 年月日
time 用于表示 时分秒
year 用于表示 年
create table t17(
id int,
name varchar(32),
birthday datetime,
this_year date,
study_tiem time,
work_time year
);
insert into 表名 values(1,'andy','2000-1-1-12:00:00','2022-11-23','12:00:00','2019')
ps:以后涉及到日期相关的字段一般都是系统自动会去处理,无需我们操作字段约束条件
MySQL之查询关键字
MySQL数据库
初识数据库
什么是数据库?数据库DB(DataBase)
概念:数据库就是指数据仓库,是一款软件,安装在操作系统之上的
作用:用于数据的存储,进行数据的的管理
数据库的分类
关系型数据库:SQL
软件:MySQL、Oracle、SqlServer、DB2、SQLlite
作用:
1.通过表与表之间,行和列之间的关系进行数据的存储
2.通过外键关联来建立表与表之间的关系
非关系型数据库:NOSQL
软件:Redis、MongoDB
作用:指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定
相关概念
DBMS(数据库管系统)
数据库的管理软件,科学有效的管理,维护和获取我们的数据
MySQL就是数据库管理系统
MySQL及其安装
网址: https://bareth.blog.csdn.net/article/details/107369405
基本命令
所有的语句都有以分号结尾
show datebasesl; 查看当前所有的数据库
use 数据库名; 打开指定数据库
show tables; 查看所有的表
describe/desc 表名; 显示表的信息
create database 数据库名; 创建一个数据库
exit 退出链接
-- 单行注释
# 单行注释
/**/ 多行注释操作数据库
操作数据库
1.创建数库
create datebase[if not exists]数据库名;
2.删除数据库
drop database[if exists]数据库名;
3.使用数据库
如果表名或者字段名是特殊字符,则需要带``
use 数据库名;
4.查看数据库
show databases;
数据库的列类型
数值
tinyint 十分小的数据
smallint 较小的数据
mediumint 中等大小的数据
int 标准的整数
bigint 较大的数据
float 浮点数
double 稍微精确浮点数
decimal 精确浮点数,一般用于金融计算
浮点数的精确程度
float < double < decimal
字符串
char 字符串固定长度 0~255
varchar 可变长字符串 0~65535
tinytext 微型文本 2^8-1
text 文本串 2^16-1
时间日期
date 日期格式 Y-M-D
time 时间格式 H:M:S
datetime 常用时间格式 Y-M-D H:M:S
timestarmp 时间戳
year 年份
null
没有值,未知
PS:不要使用NULL值进行计算
数据库的字段属性
unsigned
无符号的
生命了这一例不能为负数
zerofill
0填充的
不足位数的用0来填充 eg:int(5),5 则为005
auto_incarement
1.通常理解为自增,自动在上一条记录的基础上默认+1
2.通常用来设计唯一的主键,必须是整数类型
3.可定义其实值和步长
当前表设置步长(auto_increment = 100):只会影响当前表
set @@auto_increment_increment = 5;影响所有使用自增的表(全局)
null和not null
默认为null,即没有插入该列的数值
如果设置为not null,则该列必须有值
default
默认的,用于设置默认值
列如:性别字段,默认为“男”,否则为“女”;若无指定该列的值,则默认值为“男”的值。
拓展:每个表,都必须要存在下面的五个字段
id 主键
version 乐观锁
is_delete 伪删除
gmt_create 创建时间
gmt_update 修改时间
创建数据库表
create table 表名(字段名 字段类型 primary key auto_increment comment"主键",
字段名2 字段类型 约束条件)
注意点:
auto_incremennt 表示自增
所有的语句后面都要加逗号,最后一个不加
不设置字符集编码的话,会使用MySQL默认的字符集编码Latin1,不支持中文,可以在my.ini里修改
格式:
CREATE TABLE IF NOT EXISTS `student`(
'字段名' 列类型 [属性] [索引] [注释],
'字段名' 列类型 [属性] [索引] [注释],
......
'字段名' 列类型 [属性] [索引] [注释]
)[表的类型][字符集设置][注释]
数据库存储引擎
innodb
mysql默认的存储引擎,安全性高,支持事物的处理,多表用户操作
myisam
mysql5.5之前的默认引擎,节约空间,速度较快
memory
基于内存存取数据,仅用于历史表数据存取
black hole
任何写入进去的数据都会立刻丢失
修改数据库
修改
修改表名:
alter table 旧表名 rename as 新表名;
eg:alter table t1 rename as t2;
添加字段:
alter table 表名 add 字段名 列属性(属性);
eg:alter table t1 add age int(11);
修改字段:
alter table 表名 modify 字段名 列类型[属性];
alter table 表名 change 旧字段名 新字段名 列属性[属性];
eg:alter table t1 modify age varchar(32); 修改约束
eg:alter table t2 change age age1 int(12); 字段重命名
删除字段:
alter table 表名 drop 字段名;
eg:alter table t1 drop age1;
删除
语法:
drop table [if exists] 表名
eg:drop table if exists t2;
if exists 为可选,判断是否存在数据表
如删除不存在的数据表会抛出错误
MySQL数据管理
外键
概念:如果公共关键在一个关系中是主关键字,那么这个关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键做主关键字的表被称为主表,具有此外键的表被称为主表的从表。
在实际操作中,将一个表的值放入第二个表来表示关联,所使用的值是第一个表的主键值(在必要时可包括复合主键值)。此时第二个表中保存着些值的属性称之为外键。
外键作用:
保持数据一致性,完整性,主要目的是控制存储在外键表中的数据(约束)。使两张表形成关联,外键只能引用外表中的列的值或使用空值。
最佳实践:
数据库就是用来单纯的表,只用来存数据,只有行(数据)和列(属性)
我们想使用多张表的数据,使用外键,使用程序去实现
DML语言
数据库的意义:数据存储,数据管理
Data Manipulation Luaguge; 数据操作语言
添加 insert
语法:
insert into 表名 ([字段1,字段2、、])values(值1,值2、、),[(值1,值2、、、)、、];
普通用法
insert into 表1(字段) values('zsr');
插入多条数据
insert into 表1(字段1,字段2)values(值1,值1),(值2,值2);
省略字段
insert into 表名 values(值1,值2,值3,值4、、)
修改 update
语法:update 表名 set 字段1=值1,[字段2=值2、、]where 条件[];
删除 delete
语法:
delete from 表名 [where 条件]
删除数据(避免这样写,会全部删除)
delete from 表名;
删除指定数据
delete from 表名 where id =1;
关于delete删除的问题,重写数据库现象:
innodb自增列会从1开始(存在内存当中,断电即失)
myisam继续从上一个子增量开始(存在内存中,不会丢失)
作用:完全请空一个数据库表,表的结构和索引约束不会变
DQL查询数据
查询语句: data querylanguage 数据查询语言
基础查询
语法:select 查询列表 from 表名;
查询列表可以是:
表中的(一个或多个)字段,常量,变量,表达式,函数
查询结果是一个虚拟的表格
条件查询
where 条件字句:检索数据中符合条件的值
语法:
select 查询列表 from 表名 where 筛选条件;
分组查询
语法:
select 分组函数,分组后的字段
from 表名
[where 筛选条件]
group by 分组的字段
[having 分组后的筛选]
[order by 排序列表];
分组前的筛选
where 原始表 group by的前面
分组后的筛选
having 分组后的结果 group by 的后面
排序和分页
排序:
select 查询列表 from 表
where 筛选条件 order by 排序列表 asc/desc;
order by 的位置一般放在查询语句的最后(除limit语句外)
asc:升序,如果不写默认升序
desc:降序
分页:
select 查询列表 from 表 limit offset,pagesize;
offset代表的是起始的条目索引,默认从0开始
size代表的是显示的条目数
offset= (n-1)*pagesize
子查询
本质:就是在where字句中嵌套一个子查询的语句
将指依据的查询结果用括号括起来,给下个查询的语句当做条件
MySQL函数
常用函数
1.数学运算
select ABS(-8) 绝对值
select ceil 向上取整
select ceiling 向上取整
select rand() 返回一个字符,0~1之间的随机数
select sign(-10);返回一带数的符号;0返回0;整数返回1,负数返回-1
2.字符串函数
select char_length() 字符串长度
select concat('','','') 拼接字符
select insert()
select lower()转小写
select upper()转大写
select instr('zroe','z')返回第一次出现字符串索引的位置
select replace ()替换出现的指定符号
select substr ()返回指定的字符串(源字符串,截取位置,截取长度)
select reverse('rez') 反转字符
3.时间函数
select current_date(); 获取当前日期
select curdate();获取当前日期
select NOW();获取当前时间
select localtime(); 本地时间
select sysdate();系统时间
select year(NOW())
select moth(now())......
系统信息
select system_user();
select user();
select version();
聚合函数
max 最大值
min 最小值
sum 总和
avg 平均值
count 计算个数
连接查询:

数据库级别的MD5加密
MD5信息摘要算法
- MD5是由MD4、MD3、MD2改进而来,主要增强算法复杂度和不可逆性
- MD5破解网站的原理,背后有一个字典,MD5加密后的值,加密前的值
CREATE TABLE `testMD5`(
`id` INT(4) NOT NULL,
`name` VARCHAR(20) NOT NULL,
`pwd` VARCHAR(50) NOT NULL,
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET =utf8;
-- 明文密码
INSERT INTO `testMD5` VALUES(1,'zsr','200024'),
(2,'gcc','000421'),(3,'bareth','123456');
-- 加密
UPDATE `testMD5` SET `pwd`=MD5(pwd) WHE RE id=1;
UPDATE `testMD5` SET `pwd`=MD5(pwd); -- 加密全部的密码
-- 插入的时候加密
INSERT INTO `testMD5` VALUES(4,'barry',MD5('654321'));
-- 如何校验:将用户传递进来的密码,进行MD5加密,然后对比加密后的值
SELECT * FROM `testMD5` WHERE `name`='barry' AND `pwd`=MD5('654321');
事物
要么成功,要么失败
sql执行 :A转账给B
SQL执行:B收到a的钱将一组SQL放在一个批次中去执行
- 例如银行转账:只有A转账成功且B成功到账,该事件才算结束,如果一方不成功,则该事务不成功
事物原则:ACID
四大特性:
原子性:
指事物是一个不可分割的工作单位,事务中的操作要么都发生,要么不发生。
PS:原子性表示,这两个步骤一起成功,或者一起失败,不能只发生一种
一致性:
事务前后数据的完整性必须保持一致。
PS:针对一个事务操作前与操作后的状态一致
隔离性:
事物的隔离性是多个用户并发访问数据时,数据库为每一个用户开启的事务,不能被其他事物的数据所干扰,多个并发事物之间要相互隔离。
PS:针对多个用户用同时操作,主要是排除其他事务对本次事务的影响。
持久性:
是指一个事物一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发送故障也不应该对其有任何影响。
PS:表示事务结束后的数据不随着外界原因导致数据丢失
事物并发导致事物问题
脏读:指一个事务读取到另一个事务未提交的数据
不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同。
幻读:是指在一个事务内读取到了别的事务插入的数据,导致前后读取一致
隔离级别
在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别
1.读未提交:一个事务读取到其他数据到其他事务未提交的数据,这种隔离级别下,查询不后加锁,一致性最差,会产生脏读、不可重复读、幻读的问题
2.读已提交:一个事务只能读取到其他事务已经提交的数据,该隔离级别避免了脏读问题的产生,但是不可重复读和幻读的问题仍然存在;
读提交事务隔离级别是大多数流行数据库默认事务隔离级别,比如:Oracle,但是不是MySQL的默认隔离界别
3.可重复读:事务在执行过程中可以读取到其他事务已提交的新插入的数据,但是不能读取其他事务对数据的修改,也就是说多次读取同一记录的结果相同,该个里级别避免了脏读、不可重复读的问题,但是仍然无法避免幻读的问题。
可重复读是MySQL默认的隔离级别
串行化:事务串行化执行,事务只能一个接着一个地执行,并且在执行过程中完全看不到其他事务对数据所做的更新;缺点是并发能力差,最严格的事务隔离,完全符合ACID原则,但是对性能影响比较大
执行事物的过程
1.关闭自动提交
set autocommit =0;
2.事务开启
start transaction #标记一个事务的开始,从这个之后的SQL都在同一个事务内
3.成功则提交,失败则回滚
提交:持久化(成功)
commit
回滚:回到原来的样子(失败)
rollback
4.事务结束
set autocommit=1; # 开启自动提交
5.其他操作
savepoint 保存点名;#设置一个事务的保存点
rollback to savepoint 保存点名; #回滚到保存点
release savepoint 保存点名;# 撤销保存点
索引
索引是帮助MySQL高效获取数据的数据结构
- 提高查速度
- 确保数据的唯一性
- 可以加速表和表之间的链接,实现表和表之间的参照完整性
- 使用分组和排序子句进行数据检索 时,可以显著减少分组和排序的时间
- 全文检索字段进行搜索优化
先说结论:
索引不是越多越好,并且jason建议大家最好在提前创建好索引,而不是等火烧眉
索引的分类
主键索引(primary)
唯一的标识,主键不可重复,只有一个列作为主键
最常见的索引类型,不允许为空值
确保数据记录的唯一性
确保特定数据记录在数据库中的位置
语法:
创建表的时候指定主键索引
create table tablename(。。。primary index (columeName))
修改表结构添加主键索引
alter table tablename add primary index (columnName)
普通索引(index \key)
默认的,快速定位特定数据
index和key关键字都可以设置常规索引
应加载查询找条件的字段
不宜添加太多常规索引,影响数据的插入,删除和修改操作
语法:
直接创建普通索引
create index indexname on tablename (columname)
创建表的时候指定普通索引
create table 表名()index[索引名](columename)
修改表结构添加普通索引
alter table 表名 add index 索引名 ()
唯一索引(unique key)
它与前面的普通索引类似,不同的就是:索引列的值比须唯一,但允许有空值
与主键索引的区别:主键索引只能有一个,唯一索引可以有当多个
直接创建唯一索引
create unique index 索引名 on 表名(columnname)
创建表的时候指定唯一索引
create table 表名 (unique index (索引名)(columnname));
修改表结构添加唯一索引
alter table 表名 add uniqex index [索引名](colunmnname)
全文索引 (full text)
快速定位特定数据,(百度搜索就是全文索引)
在特定的数据引擎下才有:myisam
只能用于char varchar text 数据类型
适合大型数据集
语法:
添加一个全文索引
alter table 表名 add fulltext index 表字段 (表字段);
explain 分析SQL执行情况
explain select *from 表名; 非全文索引
explain select *from student where match (studentname) against ('d'); 全文索引
索引的使用
索引的创建
索引的删除
显示索引信息
explain分析SQL执行的情况
测试索引
索引原则
