【要经常更新】C语言一些题目
1.输入一些数,并把比0大的和比0小的区分出来
#include <stdio.h> #include <windows.h> int main(char argc, char * atgv[]) { int ele[10]; printf("请输入数字:\n"); for (int k = 0;; k++) { printf("\n输入第%d个数:",k+1); scanf("%d",&ele[k]); if (k == 9) { Sleep(2); printf("可以了 别输了\n"); break; } } int big = 0; printf("\n比零大的数:\t"); for (int i = 0; i < 10; i++) { if (ele[i] > 0) { big++; printf("%d\t", ele[i]); } } printf("总共有%d个数\n",big); int small_1 = 0; printf("\n比零小的数:\t"); for (int j = 0; j < 10; j++) { if (ele[j] < 0) { small_1++; printf("%d\t", ele[j]); } } printf("总共有%d个数\n", small_1); }
2.用1234四个数,组成每位不重复的三位数
#include <stdio.h> int main(char argc,char * atgv[]) { int element[4] = {1,2,3,4}; int a, b, c; int value; for (int i = 0; i < 4; i++) { a = element[i]; for (int j = 0; j < 4; j++) { b = element[j]; for (int k = 0; k < 4;k++) { c = element[k]; value = a * 100 + b * 10 + c; if(a != b && b != c && a != c) { printf("%d\r\n",value); } } } } }
3.实现strcmp的功能
#include <stdio.h> int main(char argc, char * atgv[]) { /*实现strcmp的功能*/ char str1[100]; char str2[100]; printf("输入第一个字符串:\t"); scanf("%s",str1); printf("输入第二个字符串:\t"); scanf("%s",str2); for (int i = 0; i < 100;i++) { if ((str1[i] - str2[i]) != 0 ) { printf("字符串不一样!\n"); break; } while (i==99) { printf("一样的一样的\n"); break; } } return 0; }
4.判断是否为回文数
#include <stdio.h> #include <string.h> int main(char argc, char * argv[]) { char a[100], b[100]; scanf("%s",&a); //用a数组去储存刚收到的字符串 int len = strlen(a); //要先知道a的长度,才方便倒置 //这里解释一下为什么j = len - 1 比如abcde len = 5 , a[4] = e 所以j要少1 for (int i = 0, j = len - 1; i < len; i++,j--) { b[j] = a[i]; //把a的值倒过来赋给b } if (strcmp(a, b)) { printf("回文数\n"); } else printf("不是回文数\n"); return 0; }
判断下面代码abc输出都是什么
#include <stdio.h> int *sss(); int *sss(int *a,int b) { int s = 10; *a = ~(1 << 2); b = 20; return &s; } int main(int argc, char const *argv[]) { int *c; int a = 1,b = 2; c = sss(&a,b); printf("0x%X %d %d\n",a,b,*c); return 0; }
a = 0xFFFFFFFB b = 2 参数没有传出来 c = 20 因为return出的是地址
二分法查找
给定一个数据,查询再数组中的下标
//参数说明:a[]数组,key要查找的值,high填入数组的长度,表示查找区域上限 int BinarySearchByCircle(int a[],int key,int high) { int low=0; //查找区域下限 int middle; //中间值 while(high>=low) { middle=(high+low)/2; if(key==a[middle]) { return middle; } if(key<a[middle]) { high=middle-1; } if(key>a[middle]) { low=middle+1; } } return -1; }
结构体长度求法
struct name1 { char str; short x; int num; }; struct name2 { char str; int num; short x; }; printf("%d %d\n", sizeof(struct name1), sizeof(struct name2));
本例中计算结果为 8 12
结构体长度求法: 1、成员类型都相同:成员个数 * 单个成员长度
2、成员类型不同: 第一步、计算第一个成员变量大小 //比如本例中name2 char大小为1
第二步、计算第二个成员变量大小 //本例中int为 4
第三步、从结构体开始到第二个成员变量的偏移量应该为第二个变量大小的整数倍
//本例中偏移量应当是4的整数倍,所以我们取4,把第一个变量补上3
第四步、依次计算其余变量 //本例中short 为 2
第五步、计算出所有变量的总大小并判断是否为成员中最大的变量大小的整数倍,如果不是,在最后补位
//本例中目前 4 + 4 + 2 = 10 不是4的整数倍,所以在short后面补2位,最后本例长度为12
数组、指针
求下列输出结果
int a[2][2][3] = {{{1,2,3},{4,5,6}},{{7,8,9},{10,11,12}}}; int *p = (int *)(&a + 1); printf("%d %d\n", *(int *)(a + 1),*(p - 1));
答案:7 12
本例中
int *p = (int *)(&a + 1);
可以写成
int *p = (int *)(&a + 1 * sizeof(a));
所以指针p其实偏移了整个数组的长度,p现在所指向的位置是第12个元素的后一个位置
所以 *(p - 1) 为12
而 *(int *)(a + 1)要对这个数组进行分析 int a[2][2][3] 红色部分是a[2]的数据类型,也就是a[2]这个数组,有2个元素,每个元素占2 * 3 * 4个字节
所以a[0]向后偏移1个长度,其实是走了2 * 3 * 4,变成了a[1][0][0]
宏定义
#define SET_A(value,bit) (value | (1U << (bit - 1))) //将bit位置1 #define CLEAR_A(value,bit) (value & ~(1U << (bit - 1))) //将bit位清零 #define REVER_A(value,bit) (value ^ (1U << (bit - 1))) //bit取反 #define GET_A(value,bit) (value >> (bit - 1) & 1U) //获取bit位值
#define YEAR_SECOND (365*24*60*60)UL //一年有多少秒
#define MUL(x,y) ((x)*(y)) //两个数相乘 //两个数交换 #define SWAP(a.b) {a = a + b; b = a - b; a = a - b;} #define SWAP(a,b) {a = a ^ b; b = a ^ b; a = a ^ b;}
在宏定义中,多用()
宏定义里面如果出现整形数字,看情况加U或者UL,U表示unsigned UL表示 unsigned long
堆、栈、队列
堆、栈、队列之间的区别是?
①堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
②栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来。(后进先出)
③队列只能在队头做删除操作,在队尾做插入操作.而栈只能在栈顶做插入和删除操作。(先进先出)
数组和链表的区别
-
数组是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。但是如果要在数组中增加一个元素,需要移动大量元素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。同样的道理,如果想删除一个元素,同样需要移动大量元素去填掉被移动的元素。如果应用需要快速访问数据,很少或不插入和删除元素,就应该用数组。
-
链表恰好相反,链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起。比如:上一个元素有个指针指到下一个元素,以此类推,直到最后一个元素。如果要访问链表中一个元素,需要从第一个元素开始,一直找到需要的元素位置。但是增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了。如果应用需要经常插入和删除元素你就需要用链表数据结构了。
(1) 从逻辑结构角度来看
a, 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费。
b,链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项)
(2)从内存存储角度来看
a,(静态)数组从栈中分配空间, 对于程序员方便快速,但自由度小。
b, 链表从堆中分配空间, 自由度大但申请管理比较麻烦.
用两个栈实现一个队列
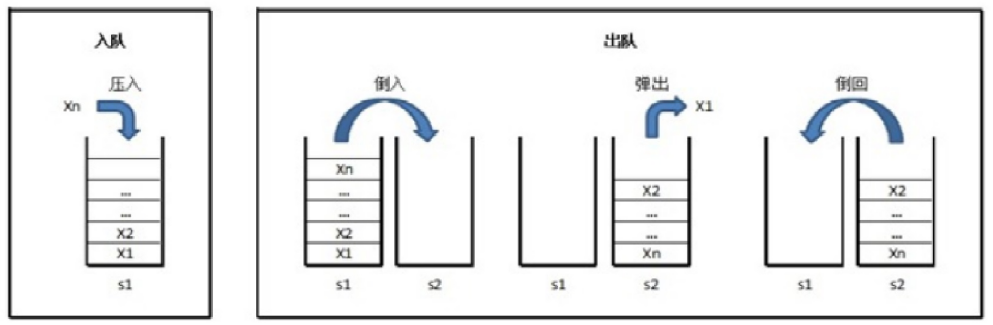
用两个队列实现一个栈
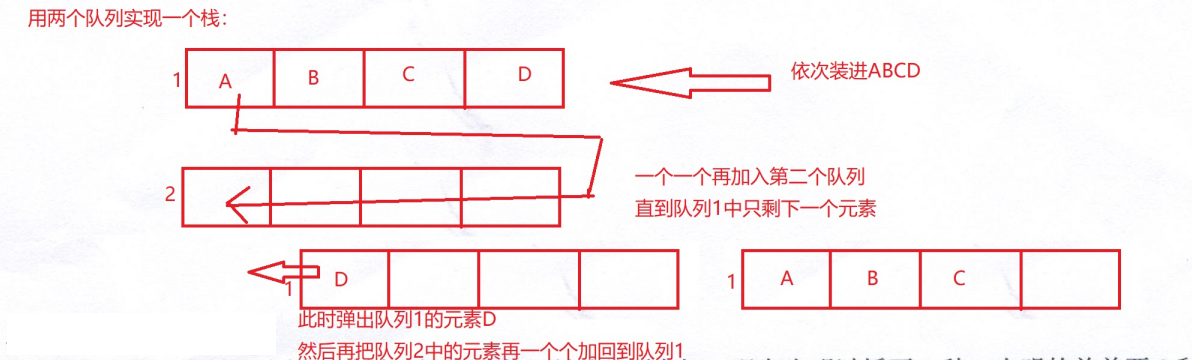
思路和上面的相同,用其中一个栈(队列)用来存取,另外一个当作缓存区
将数组a[1000]的最后一位放到最前面,重复此操作100次
最终达到效果901、902、903.。。。。。1000、1、2、。。。。899、900
int i , j,; int a[100] = {}; for(j = 0 ;j < 100;j++) { for (i = 99; i > 0 ; i--) { change(&a[i],&a[i - 1]); //调换a[i] a[i - 1] } }
static
int sum(int a) { int c = 0; static int b = 3; c += 1; b += 2; return (a + b + c); } int main() { int i = 0; int a = 2; for (i = 0; i < 5; i++) { printf("%d\n", sum(a)); } }
本例中输出为 : 8 10 12 14 16
static修饰的静态局部变量b不会随着函数的反复调用而被重置,每一次调用都保留了上一次的值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号