

Redis-数据结构简介-Set
Set 结构存储值与结构读写能力:
包含字符串的无序收集器(unordered collection), 且数据不重复.
添加,获取,移除单个元素; 检查一个元素是否存在于集合中; 计算交集,并集,差集; 从集合里面随机获取元素. 存储不可以重复的数据
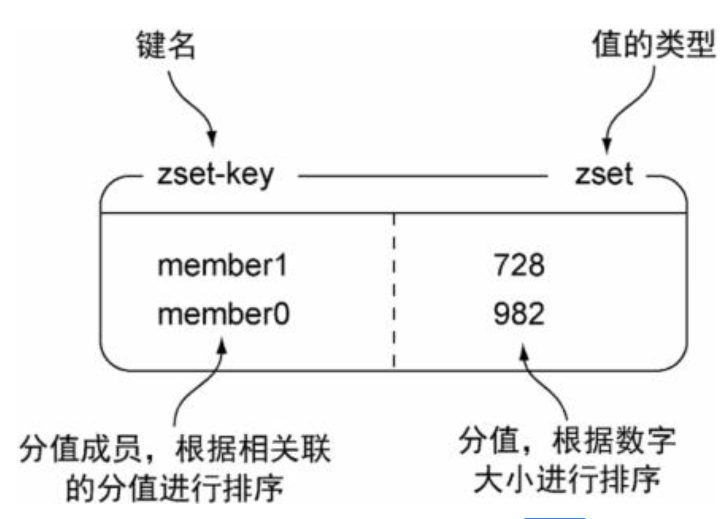
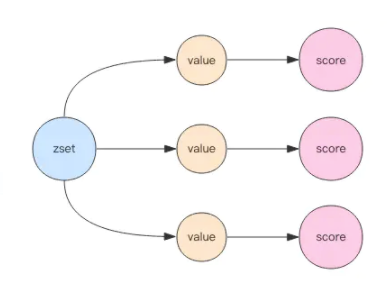
ZSet(有序集合) 结构存储值与结构读写能力:
字符串成员(member)与浮点数分值(score)之间的有序映射, 元素的排列顺序由分值的大小决定.
添加,获取,删除单个元素; 根据分值范围(range)或者成员来获取元素. 存储有序的集合数据(set), Redis的有序集合就和散列一样, 都用于存储键值对: 有序集合的键被称为成员(member), 每个成员都是独一无二的; 而有序集合的值则被称为分值(score), 分值必须为浮点数. 有序集合是Redis里面唯一一个既可以根据成员(这一点和散列一样)访问元素, 又可以根据分值及分值的排列顺序来访问元素的结构.
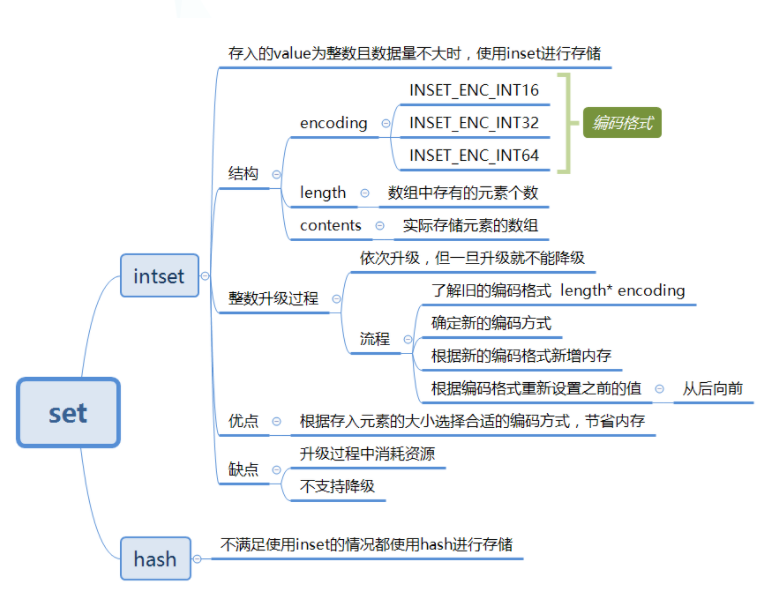
与 Java 中的 HashSet 一样,无序且存储元素不重复。其底层有两种方式实现,当 value是整数值时,且数据量是不大时使用 inset 来存储,其他情况都是用字典 dict(即hash) 来存储。
inset
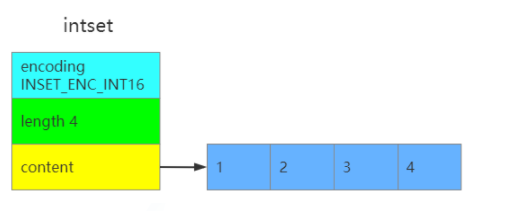
Redis 中 inset 的结构定义如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 | typedf struct inset{ uint32_t encoding;//编码方式 有三种 默认 INSET_ENC_INT16 uint32_t length;//集合元素个数 int8_t contents[];//实际存储元素的数组 //元素类型并不一定是ini8_t类型,柔性数组不占intset结构体大小,并且数组中的元 //素从小到大排列}inset;#define INTSET_ENC_INT16 (sizeof(int16_t)) //16位,2个字节,表示范围-32,768~32,767#define INTSET_ENC_INT32 (sizeof(int32_t)) //32位,4个字节,表示范 //围-2,147,483,648~2,147,483,647#define INTSET_ENC_INT64 (sizeof(int64_t)) //64位,8个字节,表示范//围-9,223,372,036,854,775,808~9,223,372,036,854,775,807 |
编码格式 encoding:共有三种,INTSET_ENC_INT16、INSET_ENC_INT32 和 INSET_ENC_INT64 三种,分别对应不用的范围。Redis 为了尽可能地节省内存,会根据插入数据的大小选择不一样的类型来进行存储。
元素数量 length:记录了保存数据的数组 contents 中共有多少个元素,这样获取多个数的时间复杂度就是 O(1)。
数组 contents:真正存储数据的地方,数组时按照从小到大有序排列的,并且不包含任何重复项。
intset 的示意图如下所示:
intset 中整数的升级过程
1. 了解旧的存储格式,计算出目前已有元素占用内存大小,计算规则是 length * encoding,如4 * 16 = 64。
2. 确定新的编码格式,当原有的编码格式不能存储下新增的数据时,此时就要选择新的合适的编码格式;
3. 根据新的编码格式计算出需要新增的内存大小,然后从尾部将数据插入。
4. 根据新的编码格式重置之前的值,此时 contents 存在两种编码格式设置的值,就需要进行统一,从插入新数据的起始位置开始,从后向前将之前的数据按照新的编码格式进行移动和设置。从后往前是为了防止数据被覆盖。
优点:根据存入的数据大小选择合适的编码方式,且只在必要的时候进行升级操作,节省内存。
缺点:升级过程耗费系统资源,还有就是不支持降级,一旦升级就不可降级。
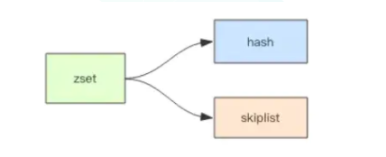
zset 是 Redis 提供的一个非常特殊的数据结构,常用作排行榜等功能,以用户 Id 为 value,关注时间或者分数作为 score 进行排序。与其他数据结构相似,zset也有两种不同的实现,分别是 zipList 和 skipList。
zipList:满足下面两个条件
1. {score, value} 键值对少于 128个
2. 每个元素的长度小于 64 字节
skipList:不满足以上两个条件时使用跳表、hash 和 skipList
1. hash 用来存储 value 到 score 的映射,这样就可以在 O(1) 时间内找到 value 对应的分数
2. skipList 按照从小到大的顺序存储分数。
3. skipList 每个元素的值都是 {score, value} 对。
只用 zipList 的示意图如下所示:
使用跳表时的示意图:
跳表 skipList
跳表 skipList 在 Redis 中的运用场景只有一个,那就是作为有序列表 zset 的底层实现。跳表可以保证增删改查等操作时的时间复杂度为 O(logN),这个性能可以与平衡树相媲美,但实现方式上却更加简单,唯一美中不足的就是跳表占用的空间比较大,其实就是一种空间换时间的思想。跳表的结构如下所示:
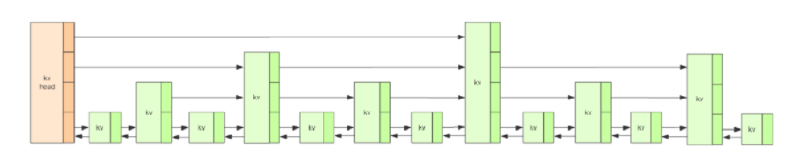
Redis 中的跳表一个节点最高可以达到 64层,一个跳表中最多可以存储 2^64个元素。跳表中,每个节点都是一个 skipListNode,每个跳表的节点也都维护者一个 score 值,这个值在跳表中是按照从小到大的顺序排列好的。
1 2 3 4 5 6 7 8 9 10 | typedf struct zskiplist{ //头节点 struct zskiplistNode *header; //尾节点 struct zskiplistNode *tail; // 跳表中元素个数 unsigned long length; //目前表内节点的最大层数 int level;}zskiplist; |
header:指向跳表的头节点,通过这个指针可以直接找到表头,时间复杂度为 O(1);
tail:指向跳表的尾节点,通过这个指针可以找到表尾,时间复杂度为O(1);
length:记录跳表的长度,即不包括头节点,整个跳表中有多少个元素;
level:记录当前跳表内,所有节点中层数最大的 level;
zskipListNode 的结构定义如下:
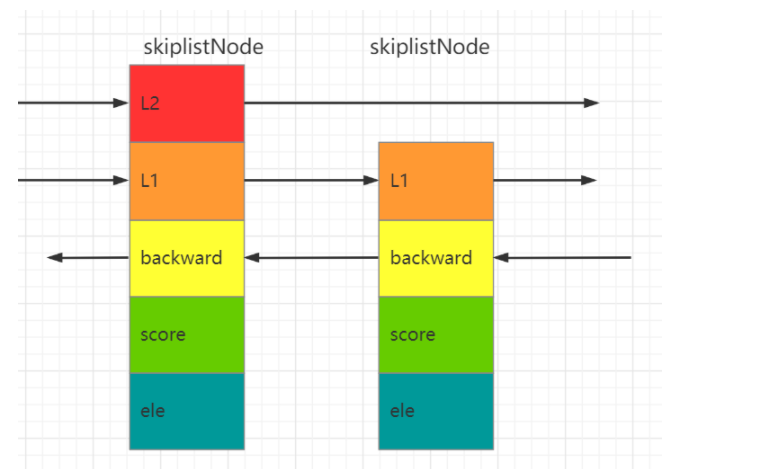
1 2 3 4 5 6 7 8 9 | typedf struct zskiplistNode{ sds ele;// 具体的数据 double score;// 分数 struct zskiplistNode *backward;//后退指针 struct zskiplistLevel{ struct zskiplistNode *forward;//前进指针forward unsigned int span;//跨度span }level[];//层级数组 最大32}zskiplistNode; |
ele:真正的数据,每个节点的数据都是唯一的,但节点的分数 score可以是一样的。两个相同分数 score 的节点是按照元素的字典序进行排序的;
score:各个节点中的数字是节点所保留的分数 score,在条表中,节点按照各自保存的分数从小到大排列;
backward:用于从表尾向表头便利,每个节点只有一个后退指针,即每次只能后退一步;
层级数组:这个数组中的每个节点都有两个属性,forward 指向下一个节点,span 跨度用来计算当前节点在跳表中的一个排名,这就为 zset 提供了一个查看排名的方法。数组中的每个节点中用1、2、3等字样标记节点的各个层,L1 代表第一层,L2代表第二层,L3代表第三次,以此类推;



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)