
Spark理论总结
## 一,Spark专业术语
1,Application
指的是用户编写的Spark应用程序、代码,包含了Driver功能代码和分布在集群中多个节点运行的Executor代码。
Spark应用程序,由一个或者多个job组成(因为代码中可能会调用多次Action)每个job就是一个RDD执行一个Action.
2,Driver Program
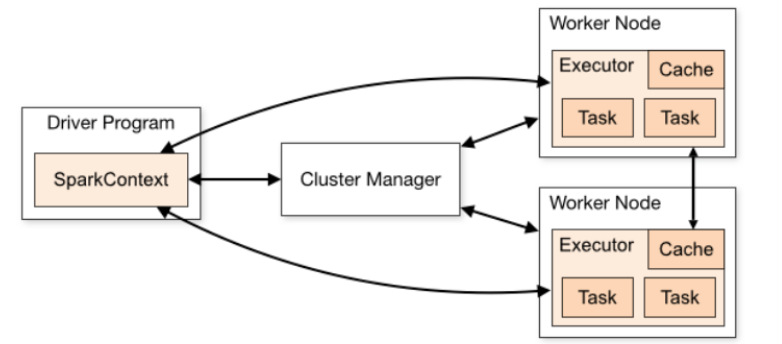
Spark中的Driver即运行在Application的main函数并创建的SparkContext,其中创建SparkContext的目的是为了准备Spark应用的运行环境。
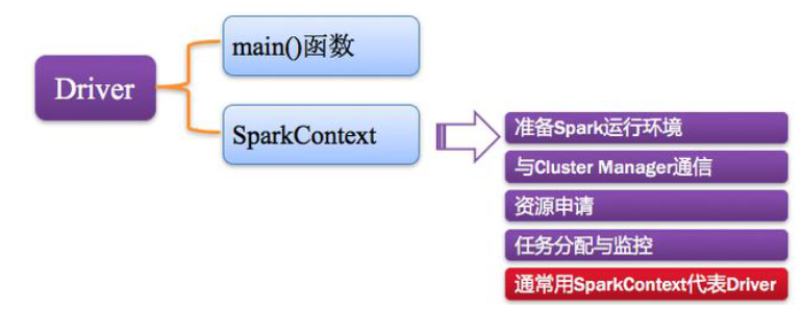
在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请,任务的分配和监控等。
SparkContext向RM或者Master申请资源,运行Executor进程(线程池),当Executor部分运行完成后,Driver负责向SparkContext关闭。
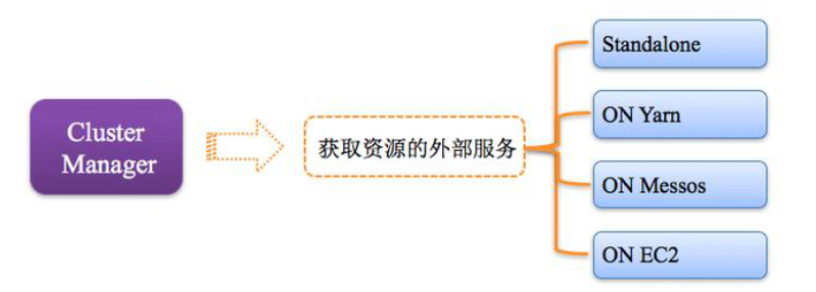
3,Cluster Manager
指的是在集群上获取资源的外部服务,常用的有
-
Standalone,Spark原生的资源管理器,由Master负责资源的分配。
-
Hadoop Yarn,由yarn中的ResourceManager负责资源的分配。
![image-20191114150004585]()
4,Worker计算节点
集群中的节点,可以分配资源并运行Executor进程。
- 在Standalone指的就是slave文件中配置的Worker节点。
- 在Spark on yarn模式中指的就是nodemanager。
5,Executor线程池
Application运行在Worker节点上面的一个进程,该进程负责运行的是Task,并且负责将数据存在内存或者磁盘中。
- 执行Task的进程
- 每个Executor只属于一个Spark Application
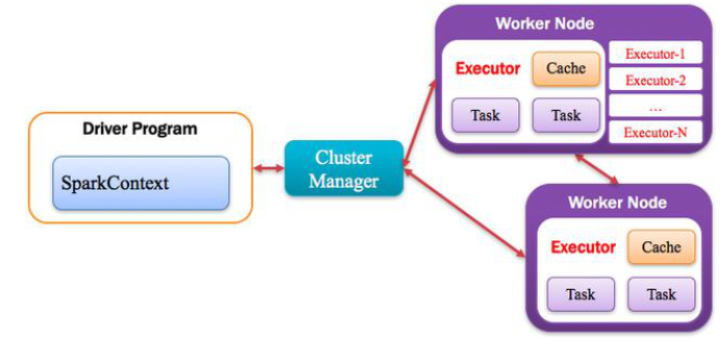
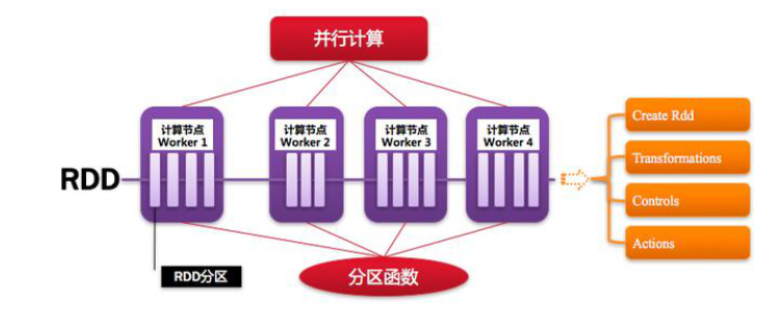
6,RDD
Spark框架的核心数据结构,是一个不可变的,分区的,并行计算的集合。
RDD中的函数
1),Transformaction转换函数
2),Action函数:触发执行job
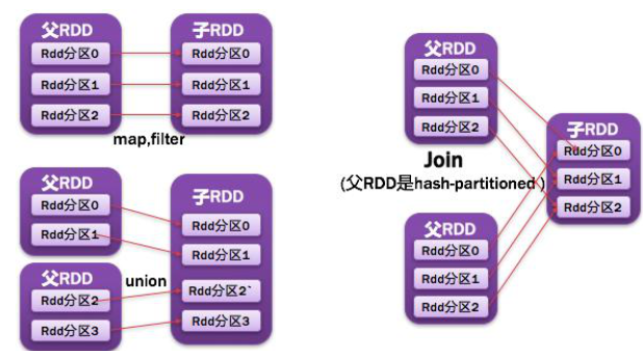
7,RDD依赖
RDD之间是相互依赖的,分为宽依赖有(一对多)和窄依赖(一对一)。
●常见的窄依赖有:
map、filter、union、mapPartitions、mapValues、join、笛卡尔积
●常见的宽依赖有:
groupByKey、partitionBy、reduceByKey、join
1)NarrowDependencyz:父RDD的一个分区被子RDD的一个分区依赖
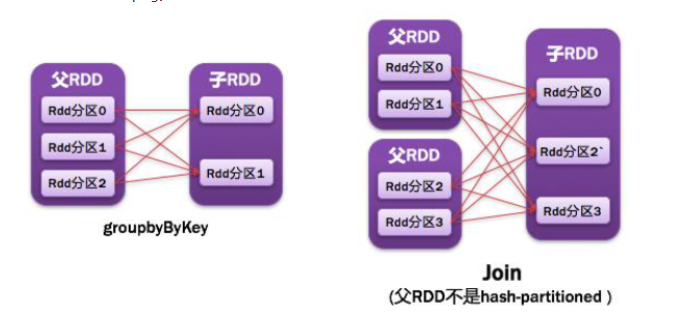
2)ShuffleDependency:父RDD的一个分区被子RDD的多个分区依赖
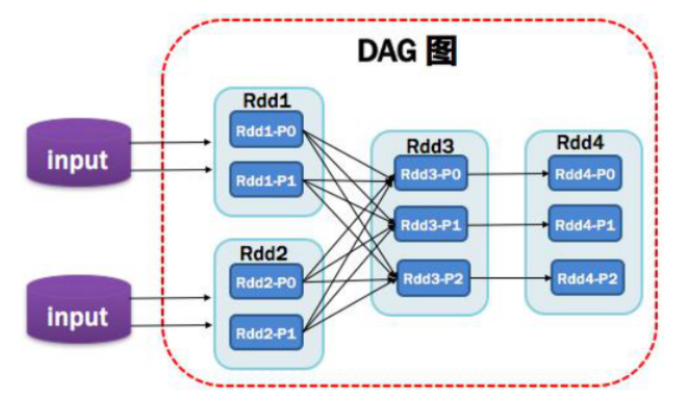
8,DAG有向无环图
由于RDD之间具有依赖关系,在调用RDD的action函数时,根据结果依赖关系构建一个DAG图。它反映了RDD之间的依赖关系,DAG其实就是一个Job。
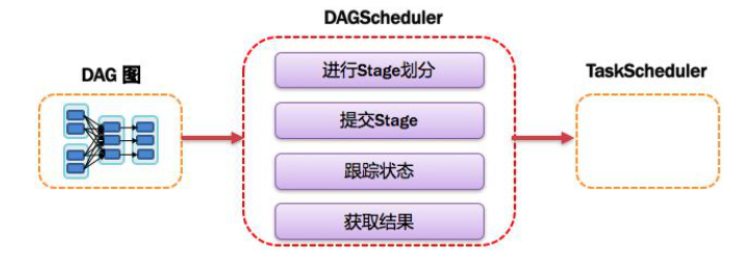
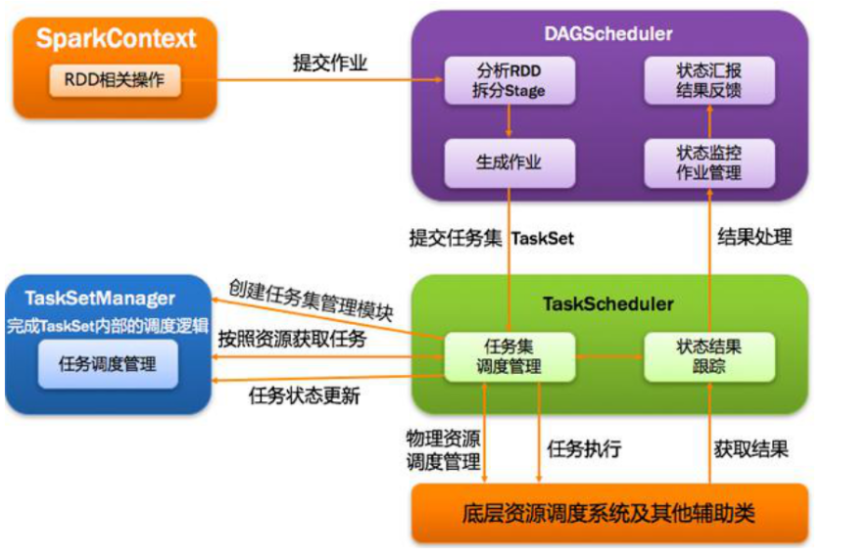
9,DAGScheduler
基于DAG划分stage并以taskset的形式它叫stage给Taskscheduler。负责将任务拆分成不同阶段的具有依赖关系的多批次任务,在SparkContext初始化的过程中实例化,一个SparkContetx对应创建一个DAGScheduler。
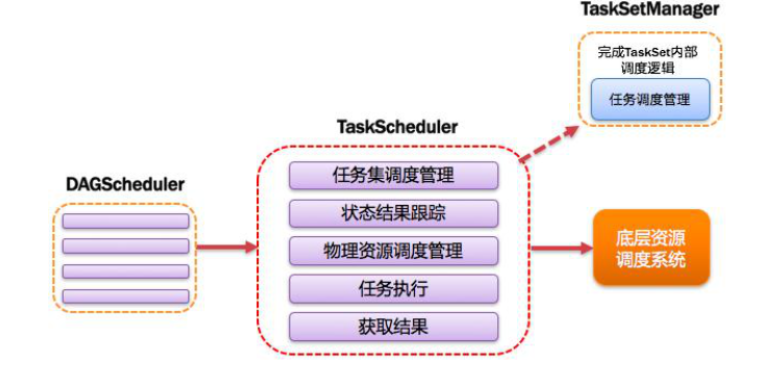
10,TaskScheduler
TaskScheduler将每个Stage中的TaskSet讲给Executor,具体执行每个Task,然后返回结果。
-
为每一个TaskSet构建一个TaskSetManager 实例管理这个TaskSet 的生命周期
-
数据本地性决定每个Task最佳位置(移动计算比移动数据更划算)
-
提交 taskset(一组task) 到集群运行并监控
-
推测执行,碰到 straggle(计算缓慢) 任务需要放到别的节点上重试
-
重新提交Shuffle输出丢失的Stage给DAGScheduler
11,job
在一个Spark Application中有多个Job,每个Job就是一个DAG图,由RDD的action函数触发。
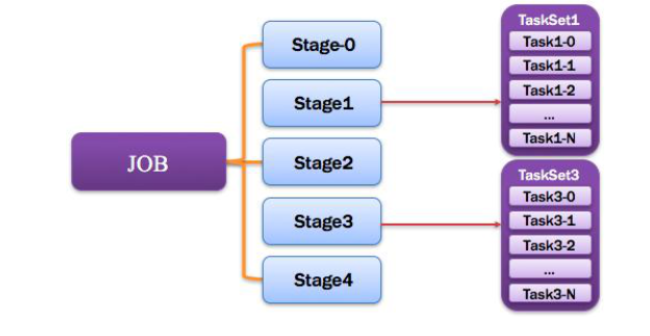
12,Stage
一个任务集对应的调度阶段,一个Job被拆分成多个Stage(TaskSet),一个stage就是一个taskset,DAG会根据宽依赖划分Stage,
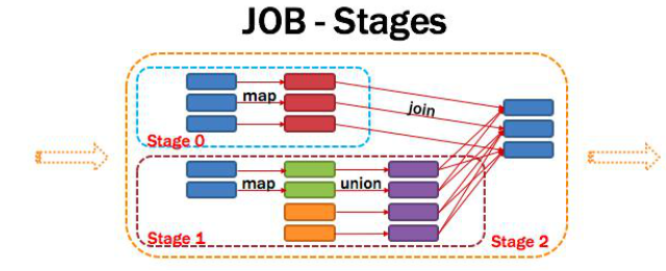
针对Stage来说可以划分成两类:ResultStage和ShuffleStage,除了最后一个Stage意外都是ShuffleStage。

13,TaskSet
一个Stage中所有Task的集合,计算逻辑相同,但是处理的数据不同。
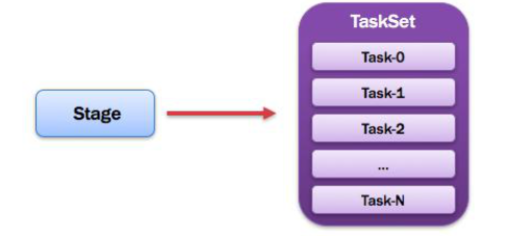
14,Task
由于Stage分为两类所以Task也分为两类,Task被送到某个Executor上的工作任务,单个粪污数据集上的最小处理单元。

15,应用整体运行图
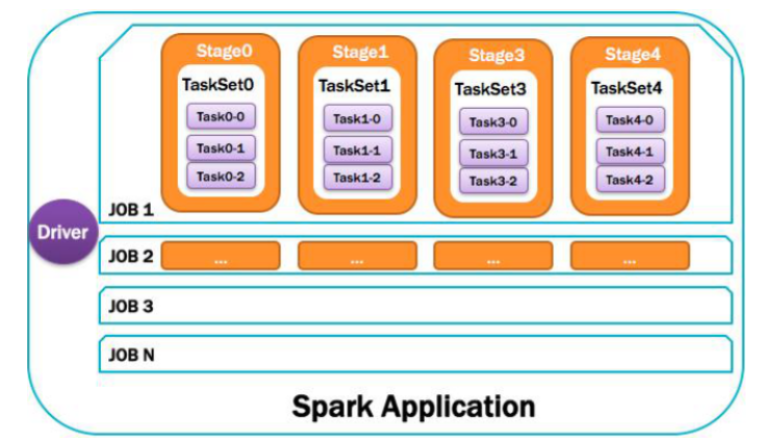
官方术语说明:

Application jar:
当Spark Application使用Scala或者Java语言编写时,提交运行的话,先打成jar包,再spark-submit提交,但是打的jar包注意事项:
1)、A jar containing the user's Spark application.
此jar必须包含Spark Application程序class文件
2)、In some cases users will want to create an "uber jar" containing their application along with its dependencies.
某些应用开发时,依赖第三方的jar包,所以打jar包,将其依赖包包含jar包中。
比如将分析结果存储到MySQL数据库表中,此时依赖mysql驱动包,打成jar包时包含。
但是在实际项目中,不会将依赖jar包打包到用户程序jar包中:
提交应用时spark-submit --jars xx.jar,yyy.jar,zz.jar
3)、The user's jar should never include Hadoop or Spark libraries, however, these will be added at runtime.
用户打成jar包中,坚决不能包含依赖hadoop或者spark相关jar包及依赖包
由于在使用spark-sumit提交应用时,自动将SPARK_HOME/jars中所有jar包添加到classpath中。
二,Spark运行流程
1,计算流程
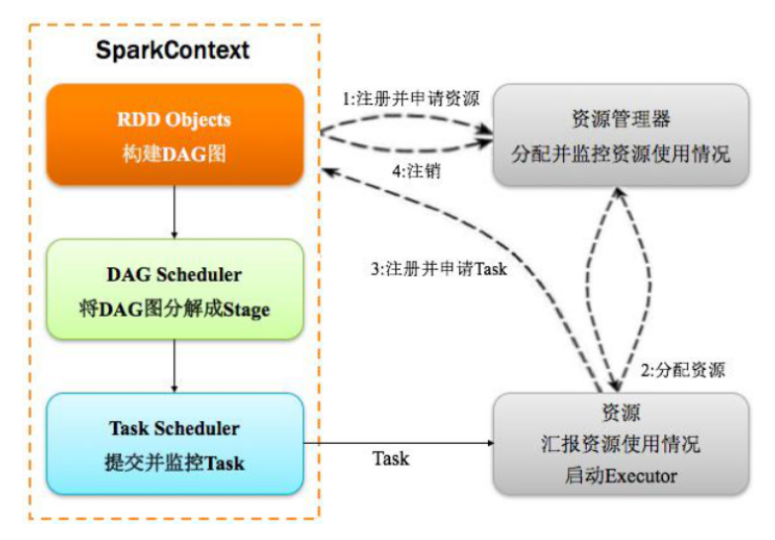
主要分为以下两个方面:
1)构建环境:SparkContext对象创建,申请资源运行Executor,DAGScheduler和TaskScheduler
2)调度Job执行:当RDD#action函数触发job执行,job->DAG->Taskset->Executor
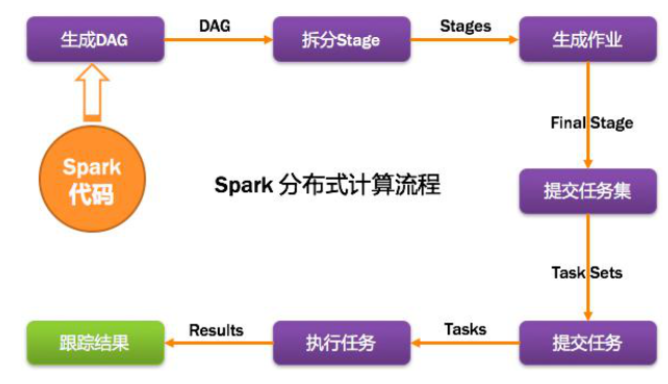
具体计算过程如下:
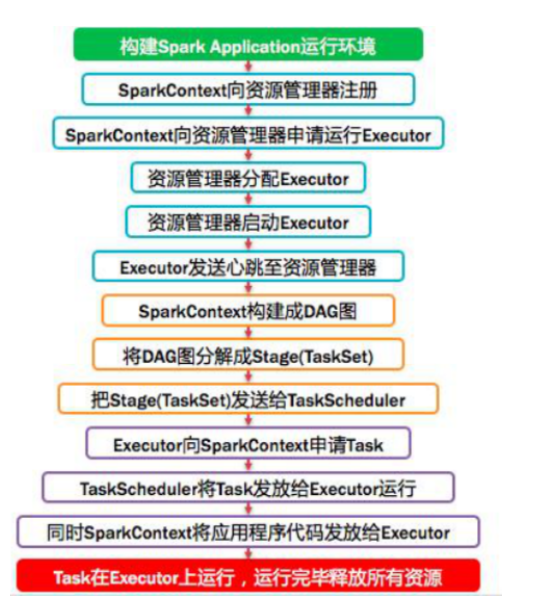
首先构建Spark Application运行环境,SparkContext向资源管理器注册并申请运行Executor,资源管理器分配Executor并运行Executor,Executor发送心跳至资源管理器,SparkContext构建DAG图,将DAG图分解成Stage(Taskset),把Stage(TaskSet)发送给TaskSchduler,当Executor向SparkContext申请Task时,TaskScheduler将Task发放给Executor运行,同时SparkContext将应用程序代码发送给Executor,Task在Executor上运行,运行完毕释放所有资源。
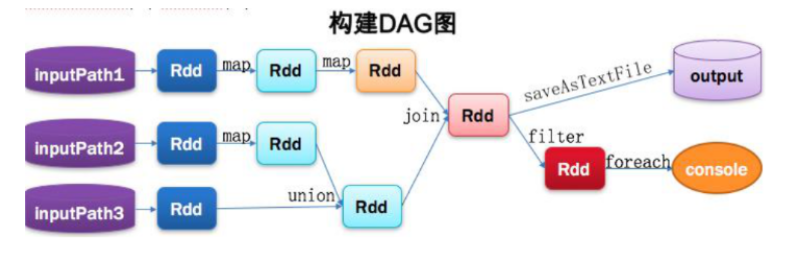
2,从代码构建DAG
// 读取数据
Val lines1 = sc.textFile(inputPath1).map(...).map(...)
Val lines2 = sc.textFile(inputPath2).map(...)
Val lines3 = sc.textFile(inputPath3)
// 处理数据
Val dtinone1 = lines2.union(lines3)
Val dtinone = lines1.join(dtinone1)
// 数据输出
dtinone.saveAsTextFile(...)
dtinone.filter(...).foreach(...)
//Spark内核会在需要计算发生的时刻绘制一张关于计算路径的有向无环图,也就是DAG。
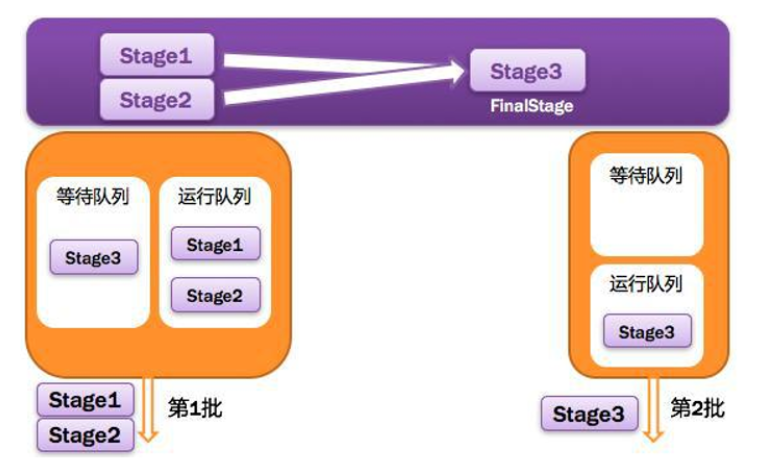
3,将DAG划分为Stage核心算法
一个job由一个或者多个Stage组成,后面的Stage依赖于前面的Stage,也就是说只有前面的Stage执行完成后,后面Stage才会执行。
划分的依据就是宽依赖,何时产生快依赖,reduceByKey,groupByKey等算子会产生宽依赖,核心算法是回溯算法:
从后面往前,遇到窄依赖加入本stage,遇到宽依赖进行stage的划分,Spark的内核会从触发Action操作的那个RDD开始往后推,首先为最后一个RDD创建一个stage,然后继续倒推,如果发现某个RDD是宽依赖,name就会将宽依赖的那个RDD创建一个stage,那个RDD就是stage最后一个RDD,然后以此类推,直到所有RDD全部遍历完成为止。
4,提交stage
调度阶段的提交,最终会被转换成一个任务集Taskset提交。DAGScheduler通过TaskSchduler的接口提交任务集,这个任务集会触发TaskSchduler构建一个TaskManager的实例来管理这个任务集的生命周期。
对于DAGSchduler来说,提交调度阶段的工作到此就完成了,而TaskSchduler的具体实例TaskManager则会在得到计算资源的时候,进一步通过TaskManager调度具体的任务到对应的Executor节点上面运算。
5,监控Job,Task,Executor
1)、运行时WEB UI界面
http://driver-host:4040
如果4040被占用,继续类推4041,4042.。。。
当本地开发应用时,可以在程序最后让线程休眠,查看4040端口,监控信息
2)、运行完成后,启动HistoryServer监控信息
启动Spark HistoryServer服务,并且运行应用时设置保存EventLog日志到HDFS目录
3)、从程序内部来看,DAGScheduler监控Job和Task的执行状况,监控Executor的生命状态
6,获取任务的执行结果
一个具体的任务在Executor执行完毕后,会将结果以某种某种形式返回给DAGSchduler,根据任务类型的不同,返回的结果也不同。
1)、中间结果:Shuffle数据
2)、最终结果:Job分析结果数据
7,任务调度总体诠释
三,Spark框架运行的特点
文档:http://spark.apache.org/docs/2.4.0/cluster-overview.html#components
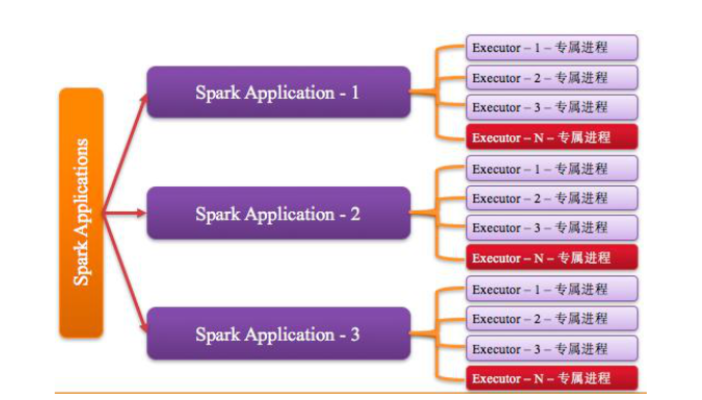
1,Executor进程专属
每个Application获取专属的Executor进程,该进程在Application期间一直驻留,并以多线程的方式运行task。
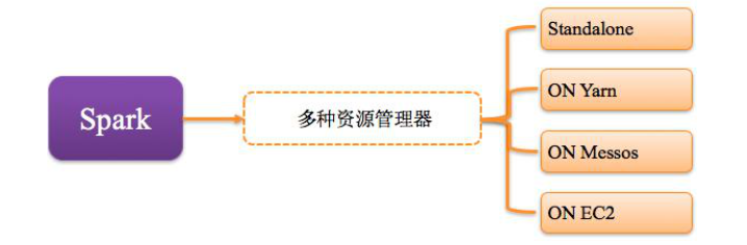
2,支持多种资源管理器
Spark与资源管理器无关,只要能够获取Executor进程,并能保持相互通信就可以,资源管理器有Standalone、On Mesos、On YARN、Or On EC2。
最近几年,云计算的概念再次被提起,很多公司也开始使用云计算平台。
3,Job提交就近原则
提交Job的SparContext的client应该靠近Worker节点(运行Executor的节点),最好在同一个Rack里,因为Spark Application运行过程中SparkContext与Executor有大量的信息交换,如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。

4,数据的本地性
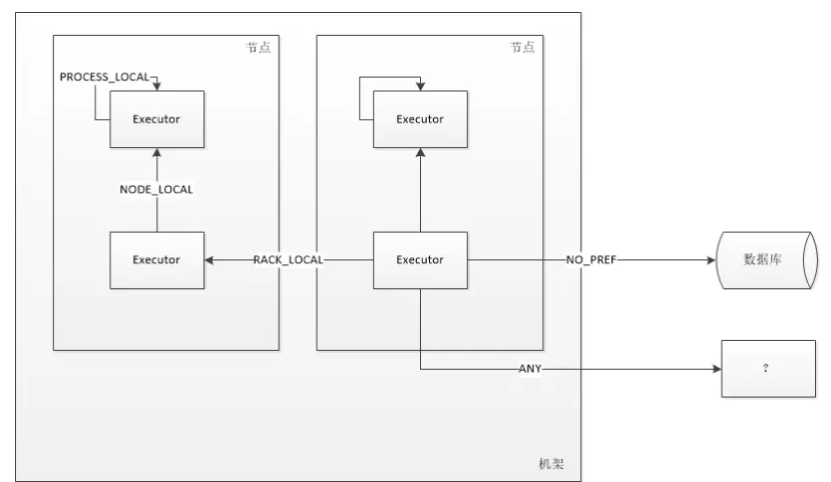
也就是移动数据不如移动计算的,之所以有数据的本地性就是因为数据在网络中传输会有不小的I/O消耗。那我们就要缩小传输距离,数据的本地性分为几个级别。
执行任务的时候查看task的执行情况可以看到这么一列:
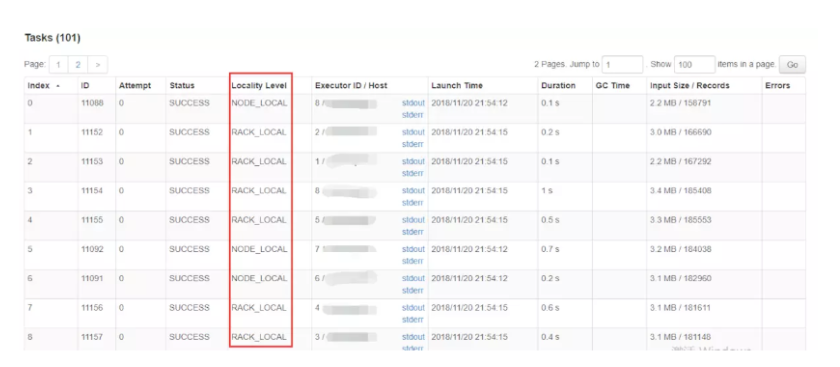
数据的本地性分为五个级别:
| 级别 | 说明 |
|---|---|
| PROCESS_LOCAL | 顾名思义,要处理的数据就在同一个本地进程中,即数据和Task在同一个Executor JVM中,这种情况就是RDD的数据在之前就已经被缓存过了,因为BlockManager是以Executor为单位的,所以只要Task所需要的Block在所属的Executor的BlockManager上已经被缓存,这个数据本地性就是PROCESS_LOCAL,这种是最好的locality,这种情况下数据不需要在网络中传输。 |
| NODE_LOCAL | 数据在同一台节点上,但是并不不在同一个jvm中,比如数据在同一台节点上的另外一个Executor上,速度要比PROCESS_LOCAL略慢。还有一种情况是读取HDFS的块就在当前节点上,数据本地性也是NODE_LOCAL。 |
| NO_PREF | 数据从哪里访问都一样,表示数据本地性无意义,看起来很奇怪,其实指的是从MySQL、MongoDB之类的数据源读取数据 |
| RACK_LOCAL | 数据在同一机架上的其它节点,需要经过网络传输,速度要比NODE_LOCAL慢。 |
| ANY | 数据在其它更远的网络上,甚至都不在同一个机架上,比RACK_LOCAL更慢,一般情况下不会出现这种级别,万一出现了可能是有什么异常需要排查下原因 |
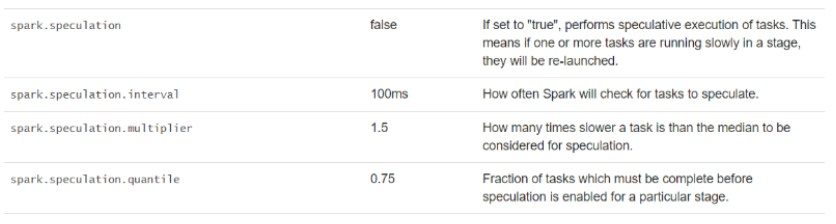
5,推测执行
MapReduce中也有推测执行,
比如100个Task,其中99个Task在5分钟左右执行完成,此时某个Task执行15分钟任然未完成。
当启动推测执行时(true),程序推测此Task运行时,出现问题,可能是资源不足
程序调度DAGSCheduler将会在其他机器上启动相同Task任务计算数据,谁先完成使用的结果。
参数:
spark.speculation,默认值为false,没有启用
四,Spark的部署模式
1,Spark应用运行
1)、Deploy Mode含义
Driver Program所运行地址
如果是提交应用客户端,值为client;如果是集群的从节点中,值为cluster。
2)、应用提交运行到YARN上组成
第一、AppMaster
管理整个应用资源的申请和任务调度执行
第二、进程(MR程序就是MapTask或ReduceTask,Spark程序就是Executor)

集群主要有四个组成部分:
1)Driver:是一个进程,我们编写的Spark应用程序就运行在Driver上,由Driver进程执行;
2)Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;
3)Worker(NM):是一个进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
4)Executor:是一个进程,一个Worker上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作
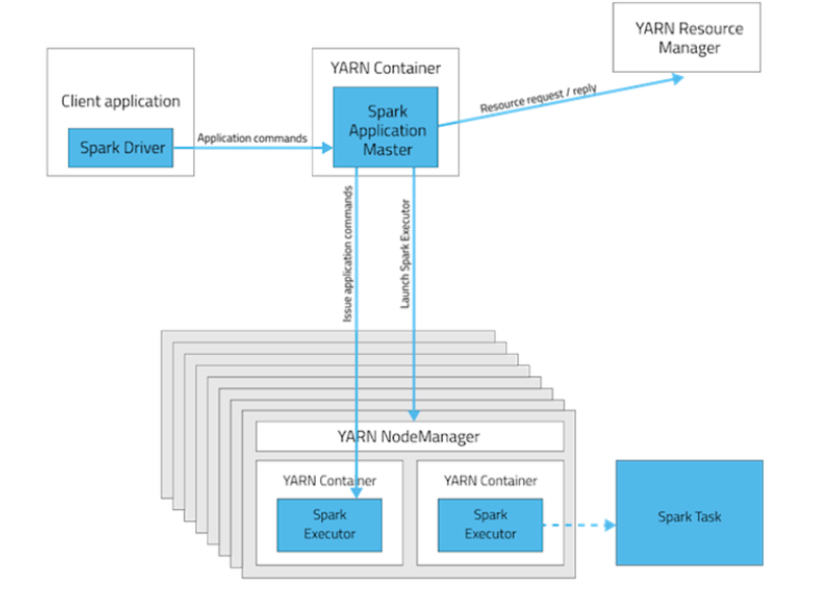
2,Yarn Client模式:Driver运行在客户端
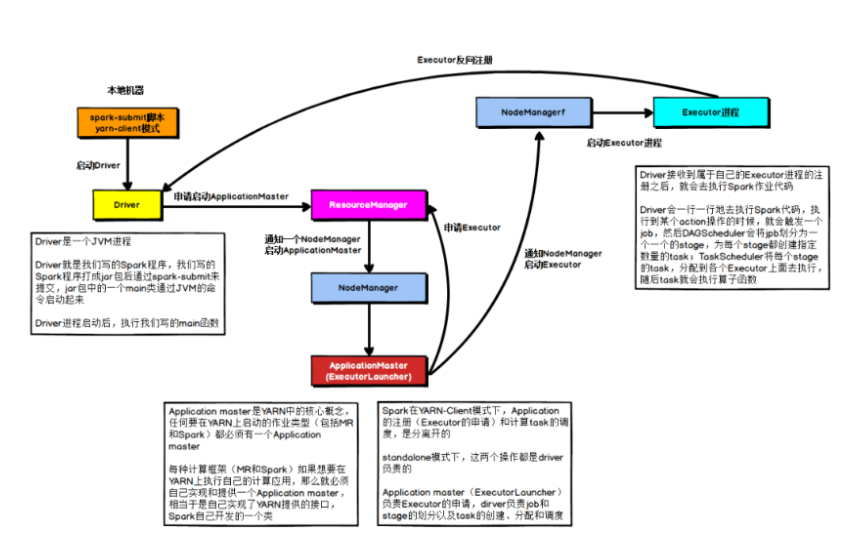
可以发现在此模式下,应用的注册和Job调度时是分离的:
1)、Driver Program管理job的执行,job划分为stage,以及stage中task的执行
2)、AppMaster负责Executor的启动和资源的申请
整个执行流程如下描述
在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
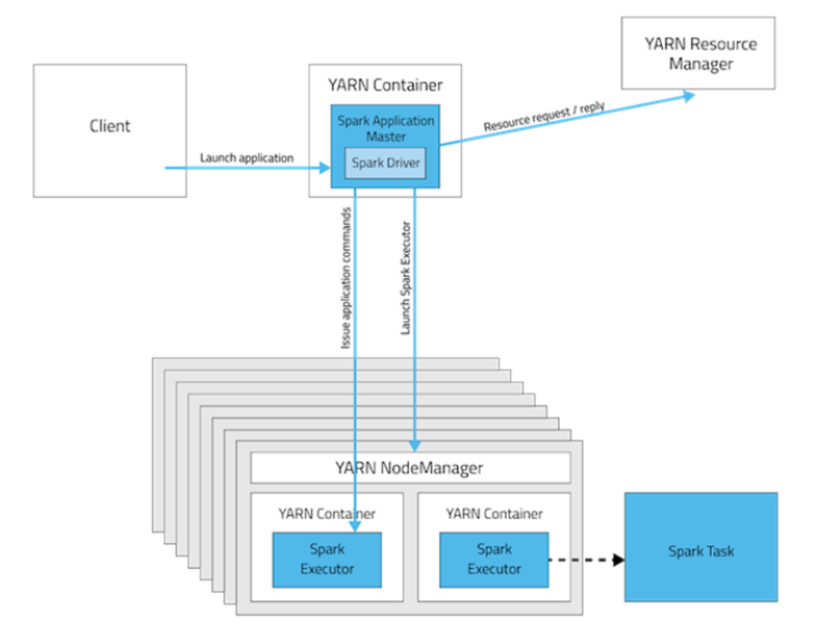
3,Yarn Cluster模式,Driver运行在Yarn
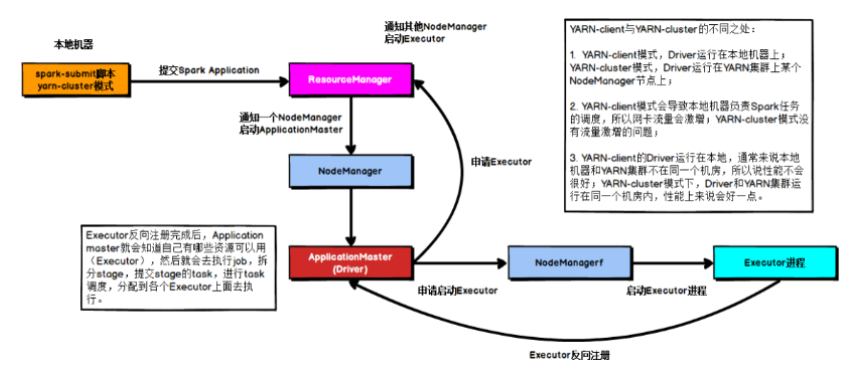
具体的过程描述如下:
在Yarn Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的nodeManager上启动ApplicationMaster,此时Application Master也就是Driver。
Driver启动后会向ResourceManager申请Executor内存,ResourceManager接到资源申请后会分配container,然后在合适的Nodemanager上面启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后,开始执行main函数,之后执行到Action算子时,会触发一个job,并根据宽依赖划分stage,每个stage生成对应的taskset,之后将task发到各个Executor上面执行。
此模式的核心点:AppMaster和Driver合为一体,既进行资源申请,又进行job执行。
yarn-client模式与yarn-cluster模式区别:
1)、client的Driver运行在本机,cluster的Driver在集群中的节点NodeManager的Container中
2)、client要负责调度的执行job,产生网卡流量,cluster则不会。
3)、client的Driver运行在本地,与yarn集群不是在一个机房或者集群,性能会受到影响。
4,综合比较两个部署模式


 浙公网安备 33010602011771号
浙公网安备 33010602011771号