MapReduce-day02
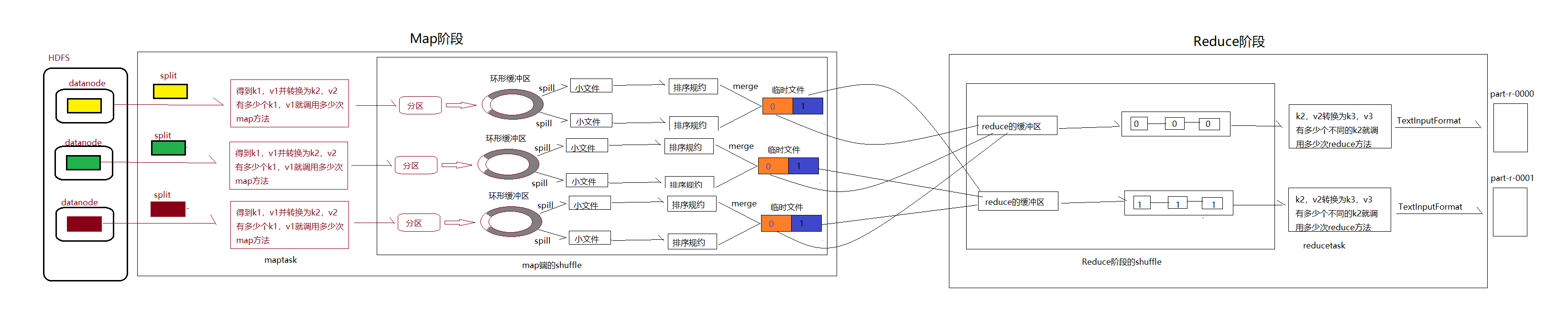
1. MapReduce执行流程详解
- 首先读取数据的组件InputFormat(默认是TextInputFormat)会通过getSplits方法对输入目录中的文件进行逻辑切片得到splits,默认有多少个splits就有多少个maptask,split默认是与block块一对一关系。
- 输入文件切成splits后有RecordReader(默认是LineReader)来进行读取,以/n为分隔符进行读取,默认读取一行,key是首字符的偏移量,v是这一行的文本内容。
- 读取split返回的键值对会进入用户自定义map方法,有多少个键值对就会调用多少次map方法,也就是读取一行就调用一次。
- map进行逻辑处理之后,每条结果都会通过context.write()进行collect数据收集,在collect中,会首先对其进行分区处理,默认是HashPartitioner
- 分区的作用就是根据key或者value以及reduce的数量来决定当前数据由哪个reduce处理,默认是key进行hash后对reduce task进行取模,这样体现了平均处理,用户也可以根据需求设置在job上
- 接下来会将数据写入到内存,这片区域兼做环形缓冲区,本质上是一个数组,它的作用是收集map结果,减少磁盘io的影响,会将key,value,partitioner的结果,写入的是序列化之后的key和value。
- 环形缓冲区本质上是一个数组,里面存储着序列化后的key和value还有key和value的元数据信息,包括partitionner的结果,key和value的起始位置,以及value的长度。环形缓冲区有大小的限制,默认是100mb,当数据过多是会进行spill溢写,默认是0.8,也就是当数据达到80mb后溢写线程会启动spill到磁盘,这里是临时文件,而剩下的20mb还可以继续读入数据互不影响。
- 溢写线程启动后会对80mb进行排序,排序是mapreduce的默认行为。
- 如果设置了combiner,那么就是进行combiner的时候了,将key相同的value加起来,减少到溢写到磁盘中的数量,提高mapreduce的效率。combiner的使用决不能改变最终结果,应该是combiner的输出作为reduce的输入,reduce的输入和输出的key和value类型一致,比如累加或者算最大值。
- 每次溢写都会生成一个临时文件,这些临时文件会进行合并,最终只有一个文件,并为这个文件提供了一个索引文件,记录reduce对应数据的偏移量。
- reduce会启动一个copy的线程,通过http方式请求maptask属于自己的文件。
- merge动作,这里的merge的是不同map端的数据,merge有三种,第一种是内存到内存,第二种是内存到磁盘,第三种是磁盘到磁盘。如果设置了combiner也会执行combiner动作。
- 这里第一种默认不启动,当内存的数据达到一个阈值,会溢写到磁盘,直到map端没有数据后,将这些溢写的文件通过磁盘到磁盘的方式合并成一个最终文件
- 最终merge的文件进行排序。
- 排序后的文件执行reduce方法,键相等的键值对会调用一次reduce放法。
2. mapreduce的并行度机制
a. maptask并行度机制
maptask的数量是由在客户端job提交之前,对数据进行逻辑切片后的切片数量。切片是由FileInputFormat类的getSplit()放法实现的。
b. reducetask并行度机制
reducetask数量可以手动设置,如果数据分布不均匀很可能造成数据倾斜,但是reducetask不是随意设置的,比如需要全局汇总计算的一个reducetask就好。
3. CombineTextInputFormat小文件处理场景
Hdfs是用来存储海量数据的。如果出现太多的小文件会出现以下影响。
- 消耗namenode大量内存
- mapreduce执行时间过长
解决方案:hadoop内置了CombineTextInoutFormat类,按照一定规则将多个小文件合并到一个inputsplit中,然后启用一个map对其进行处理,这样就可以减少mapreduce的运行时间
切片机制过程
CombineTextInputForma切片机制过包括:虚拟存储过程和切片过程二部分
假设 setMaxInputSplitSize 值为 4M,有如下四个文件
- a.txt 1.7M
- b.txt 5.1M
- c.txt 3.4M
- d.txt 6.8M
虚拟存储过程
-
- 将输入目录下所有文件大小,依次和设置的 setMaxInputSplitSize 值比较,如果不大于设置的最大值,逻辑上划分一个块。
- 如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块,当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
1.7M < 4M 划分一块
5.1M > 4M 但是小于 2*4M 划分二块:块1=2.55M,块2=2.55M
3.4M < 4M 划分一块
6.8M > 4M 但是小于 2*4M 划分二块:块1=3.4M,块2=3.4M
-
- 最终存储的文件:
1.7M
2.55M,2.55M
3.4M
3.4M,3.4M
切片过程
-
- 判断虚拟存储的文件大小是否大于 setMaxIputSplitSize 值,大于等于则单独形成一个切片。
- 如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
最终会形成3个切片:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M

 浙公网安备 33010602011771号
浙公网安备 33010602011771号