NSQ基础
前言
介绍
NSQ 最初是由 bitly公司 开源出来的一款 由Go语言 编写的一个开源的、实时、分布式、内存 消息队列。
它可用于大规模系统中的实时消息服务,并且每天能够处理数亿级别的消息,其性能十分优异。
特性
// 1. 分布式:
它提供了分布式的、去中心化且没有单点故障的拓扑结构,稳定的消息传输发布保障,能够具有高容错和高可用特性。
// 2. 易于扩展:
它支持水平扩展,没有中心化的消息代理( Broker ),内置的发现服务让集群中增加节点非常容易。
// 3. 运维方便:
它非常容易配置和部署,灵活性高。
// 4. 高度集成:
现在已经有官方的 Golang、Python 和 JavaScript 客户端,社区也有了其他各个语言的客户端库方便接入,自定义客户端也非常容易。
应用场景
// 1. 异步化流程
将 繁杂的 同步流程 进行 异步化 处理, 降低 服务的响应 时长,提高用户的 使用感受。
// 2. 应用解耦
通过使用 消息队列 将不同的业务逻辑解耦,降低系统间的耦合,提高系统的健壮性。
后续有其他业务 需要加入,若要使用 消息队列中的数据 可直接订阅消息队列,提高系统的灵活性。
// 3. 流量削峰
类似秒杀(大秒)等场景下,某一时间可能会产生大量的请求,使用消息队列能够为后端处理请求提供一定的缓冲区,保证后端服务的稳定性。
安装
下载
// 官网地址
https://nsq.io/deployment/installing.html
根据自己的平台下载并解压即可。
下载完后 得到 以下文件:
~/nsq-1.2.0.linux-amd64.go1.12.9$ tree
.
└── bin
├── nsqadmin
├── nsqd
├── nsqlookupd
├── nsq_stat
├── nsq_tail
├── nsq_to_file
├── nsq_to_http
├── nsq_to_nsq
└── to_nsq
核心为:nsqd、nsqadmin 和 nsqlookupd。
常用工具:nsq_to _file、nsq_to _http 和 nsq_to _nsq。
组件
1. nsqd
nsqd是一个守护进程,它接收、排队并向客户端发送消息。
nsqlookupd
nsqlookupd 是 nsqd 管家,维护所有nsqd状态、提供服务发现的守护进程。
它能为 消费者 查找特定topic下的nsqd提供了运行时的 自动发现服务。
它不维持持久状态,也不需要与任何其他nsqlookupd实例协调以满足查询。因此根据你系统的冗余要求尽可能多地部署nsqlookupd节点。它们 消耗 的资源很少,可以与其他服务共存。我们的建议是为每个数据中心运行至少3个集群。
nsqadmin
一个实时监控集群状态、执行各种管理任务的Web管理平台。
nsq_to _file
消费 指定的 话题(topic)/通道(channel),并写到文件中,有选择的滚动和/或压缩文件。
nsq_to _http
消费 指定的 话题(topic)/通道(channel)和执行 HTTP requests (GET/POST) 到指定的端点。
nsq_to _nsq
消费者 指定的 话题/通道和重发布消息到目的地 nsqd 通过 TCP。
架构
工作模式
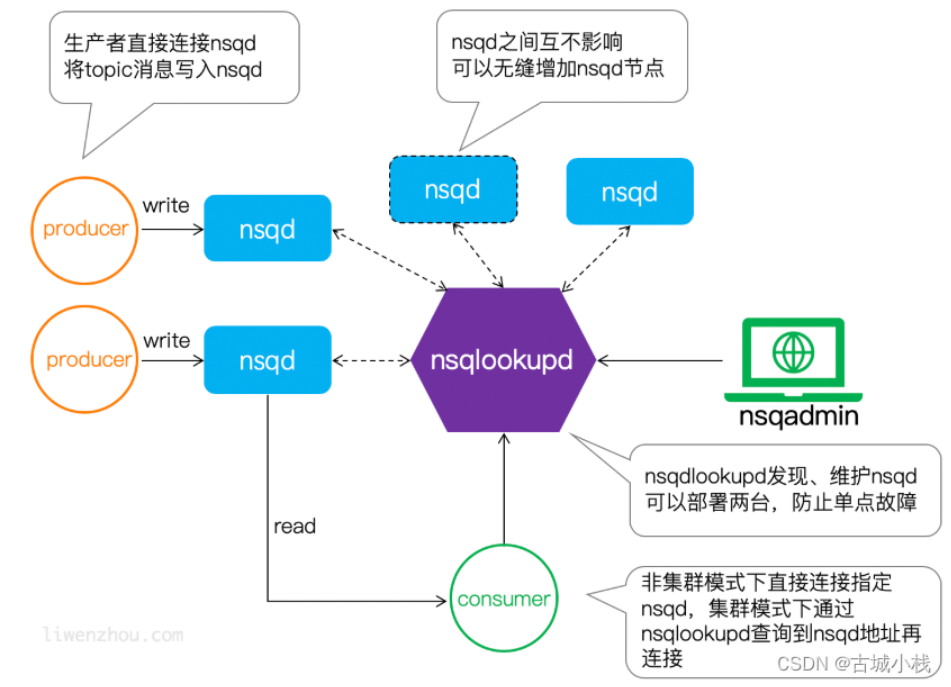
官方推荐 一个生产者 -----对应的部署-----> 一个nsqd ,
当然这样的做法有不少坏处,如果生产者对应的nsq挂掉了,那它就生产不了消息了。
而且每个生产者都要部署一个nsq,未免有些奢侈。
Topic
可以粗略的理解为是 消息的分类,topic在首次使用时创建,
一个topic具有1个或多个“channel”,下游的服务 是通过对应的channel来 消费 对应topic消息。
Channel
这里的 channel 对应 kafka 中 消费组(Comsumer Group) 的概念的概念。
这里是重点,为了容易理解 这里 不进行 概念介绍,而是采用 举例说明:
一个 网络请求的接口 其内的 代码流程 由 A、B、C 三个功能函数 组成,B 和 C 的输入 基于 A的 输出,
使用了 消息队列, 就可以 实现 同步流程 异步化, 所以 将 B 和 C 进行 代码抽离。
A 这里作为 生产者,将 自己的输出 放入到 消息队列 中 aaa topic中。
B 作为消费者, 代码被 部署到 1号服务器 和 2号服务器 上,
C 作为消费者, 代码被 部署到 3号服务器 和 4号服务器 上,
aaa topic 下 有 两个channel,分别为: chanB 和 chanC,
1号服务器 和 2号服务器 上 订阅 aaa topic 下的 chanB,所以 1、2号服务器 是一个 消费组
3号服务器 和 4号服务器 上 订阅 aaa topic 下的 chanC,所以 3、4号服务器 是一个 消费组
当 消息队列中 的 aaa topic 收到一个 消息时, 会将消息进行复制, 保证 aaa topic 下的 所有channel都 加入该 消息。
进而 每个 消费组 都可以 获取到 对应 channel 中的 消息。
但是 对于 同一个 消费组而言, 本着 负载均衡的 策略, 轮流 获取 对应 channel中的 消息,
也就是说 同一个 1号服务器 获取了 某个消息, 2号就 获取不到了。
nsqlookup 的 作用
kafka采用 pull模式, 而 nsq采用的是 push模式,那么问题来了
nsq收到 生产者 生产的消息后,需要将消息复制多份,然后推送给 对应topic 的消费者。
nsq怎么知道 哪些消费者 订阅了 对应 topic 的消息呢?
因此,我们需要一个类似于微服务里头的 注册中心 的模块,来实现服务发现的功能,这就是nsqlookup.
nsqlookup提供了类似于etcd、zookeeper一样的kv存储服务,里面记录了 topic下面都有哪些nsq。
nsqlookup提供了一个 /lookup 接口,比如你想知道哪些nsq上面,有topic为test的消息,那么只需要调一下:
curl 'http://127.0.0.1:4161/lookup?topic=test'
1
消费者 通过 调用 /lookup 接口查询,会和 响应的nsq,逐个建立连接。
nsq收到对应topic的消息后,就会给 和他们建立连接的 消费者,推送消息。
消息 漂流记
一条消息,是如何从 生产 到被 消费 的。
假设消费者最先启动,它要消费topic为”order_created“的消息,这时候它向nsqlookup调用/lookup接口,
试图获取对应topic的nsq。由于nsqlookup还没启动,因此获取失败,
不过这并不影响消费者的启动流程,因为它会每隔一段时间,去尝试重新拉取最新的数据。
为了方便调试,我将向nsqlookup查询最新nsq信息的时间间隔,由 1分钟一次,改为了10秒一次。
接着,我们启动了nsq和nsqlookup,这下消费者可以调通nsqlookup的接口了,不过由于nsq上面还没有任何topic,
因此/lookup接口返回的producers数组是空,因此消费者仍然无法向任何nsq订阅消息。
然后,我们调用这条命令,在nsq上创建新的topic:
curl -X POST http://127.0.0.1:4151/topic/create?topic=order_created
nsq创建完topic后,会自动向nsqlookup注册新的topic节点。
当消费者下次过来nsqlookup调用/lookup接口时,接口就会告诉它,已经有一台nsq,上面有”order_created“的topic了。
于是消费者拿到那台nsq的ip和端口,和它建立连接,向它发送sub命令,
带上topic和channel参数,订阅这台nsq上面的”order_created“的消息。
所有 消息队列 的 四项 决策
- 消息投递策略
- 消息时序性
- push or pull
- 内存 or 磁盘
消息投递策略
消息投递策略,是 消息中间件 的 特有属性,不同的消息中间件,对投递策略的支持也不同。
比如Kafka,就支持最多一次(At most once)、至少一次(At lease once)、准确一次(Excatly once)三种策略,
而nsq,则只支持最常见的一种,也就是至少一次,即 消息至少被投递一次。
// 怎样保证消息至少被投递一次呢?
如果 消费者 收到消息,并成功执行,那么就给nsq返回FIN,代表消息已被成功执行,这时nsq就可以把内存中,也就是channel里的消息干掉;
而如果消费者处理消息时发生了异常,需要重试,那么就给nsq返回REQ,代表requeue,重新进入队列的意思,nsq就会把消息重新放到队列中,
再次推送给消费者(这一次可能是另一个消费者实例)。
如果消费者迟迟没有给nsq回响应,超过了最大等待时间,那么nsq也会将消息requeue.
所以,消费者 必须保证 操作的幂等性, 也就说, 消费者 的 消息处理逻辑中 要 加入 重复校验 的 逻辑。
// 重试次数
nsq推送过来的消息里,有个attempts字段,代表着尝试的次数,一开始是1,每次客户端给nsq会REQ响应后,
nsq再次推送过来的消息,attempts都会加1,消费者可以按照自己的需要,对重试次数进行限制,
比如希望最多尝试6次,那么就在消费者的处理逻辑中,判断attempts <= 6,是,则执行处理逻辑,
否则,打印日志或者做其他处理,然后直接返回FIN,告诉nsq不要再重试。
消息时序性
消息是否有序,是消息中间件的特有属性。,nsq的消息是无序的,
比如说channel A里现在有两条消息,M1和M2,M1先产生,M2后产生,
channel A分别将M1和M2推送给了消费者 C1和C2,那么有可能C1比C2先处理完消息,这样是有序的;
但也有可能,C2先处理了,这样M2就比M1先被处理,这样就是无序的。
push or pull
push还是pull,这也是在设计一个消息中间件时,必须要考虑的问题。Kafka用的是pull,而Nsq采取的是push。
相比于pull,push的好处不言而喻,消息处理更加实时,一旦有消息过来,立即推送出去,
而pull则具有不确定性,你不知道消费者什么时候有空过来pull,因此做不到实时消息处理。
这也是有赞只把Kafka用在那些对实时性要求不高的业务上的原因,比如大数据统计。
也正是因为采用了push,nsq选择把消息放到内存中,只有当队列里消息的数量超过 --mem-queue-size 配置的限制时, 才会对消息进行持久化,把消息保存到磁盘中,简称”刷盘“。
内存 or 磁盘
push + 内存存储 、pull + 磁盘存储,是消息中间件设计时的一些常见套路。
当然,push机制也有缺陷,那就是当消费者很忙碌的时候,你还一直给它push,那只会逼良为娼,所以采用push的消息中间件,必须要进行流控。
Nsq流控的方式非常简单,当消费者和nsq建立好连接,准备好接受消息时,会给nsq回一个RDY的响应,
同时带上一个rdy_count,代表准备接受消息的数量,于是nsq会给消费者推送消息,每推送一条,
对应连接的rdy_count就减1(如果是批量推送,则批量减),直到连接的rdy_count变成0,则不再继续推送消息。
当消费者觉得自己可以接收很多消息时,只需再发一次RDY命令,就可以更新连接的rdy_count,nsq就会继续给消费者推送消息。
代码应用
应用部署
cd 到下载目录的 bin目录下
在bin目录下 创建 数据目录:
mkdir datas && mkdir datas/node1 datas/node2 datas/node3
# 启动状态管理(默认 "0.0.0.0:4161")
./nsqlookupd
# 启动 3个 节点服务
./nsqd --lookupd-tcp-address 127.0.0.1:4160 --broadcast-address 127.0.0.1 --data-path=./datas/node1 -http-address 127.0.0.1:4151 -tcp-address 127.0.0.1:4150
./nsqd --lookupd-tcp-address 127.0.0.1:4160 --broadcast-address 127.0.0.1 --data-path=./datas/node2 -http-address 127.0.0.1:4251 -tcp-address 127.0.0.1:4250
./nsqd --lookupd-tcp-address 127.0.0.1:4160 --broadcast-address 127.0.0.1 --data-path=./datas/node3 -http-address 127.0.0.1:4351 -tcp-address 127.0.0.1:4350
# 启动 可视化 页面
./nsqadmin -lookupd-http-address=127.0.0.1:4161
go代码操作
官方提供了Go语言版的客户端:go-nsq: go get -u github.com/nsqio/go-nsq
生产者
package main
import (
"fmt"
"github.com/nsqio/go-nsq"
)
// NSQ Producer Demo
var producer *nsq.Producer
// 初始化生产者
func initProducer(str string) (err error) {
config := nsq.NewConfig()
producer, err = nsq.NewProducer(str, config)
if err != nil {
fmt.Printf("create producer failed, err:%v\n", err)
return err
}
return nil
}
func init() {
nsqAddress := "127.0.0.1:4150"
err := initProducer(nsqAddress)
if err != nil {
fmt.Printf("init producer failed, err:%v\n", err)
panic(nsqAddress + "nsq 连接失败")
}
}
func main() {
// 向 'topic_demo' publish 数据
err := producer.Publish("topic_demo", []byte("听我说谢谢你, see your"))
if err != nil {
fmt.Printf("publish msg to nsq failed, err:%v\n", err)
}
}
消费者
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
"time"
"github.com/nsqio/go-nsq"
)
// NSQ Consumer Demo
// MyHandler 是一个 消费者 类型
type MyHandler struct {
Title string
}
// HandleMessage 是需要实现的 处理消息 的方法
func (m *MyHandler) HandleMessage(msg *nsq.Message) (err error) {
fmt.Printf("%s recv from %v, msg:%v\n", m.Title, msg.NSQDAddress, string(msg.Body))
return
}
// 初始化 消费者
func initConsumer(topic string, channel string, address string) (err error) {
config := nsq.NewConfig()
// 轮训时间间隔
config.LookupdPollInterval = 15 * time.Second
c, err := nsq.NewConsumer(topic, channel, config)
if err != nil {
fmt.Printf("create consumer failed, err:%v\n", err)
return
}
consumer := &MyHandler{
Title: "test1",
}
c.AddHandler(consumer)
// if err := c.ConnectToNSQD(address); err != nil { // 直接连NSQD
if err := c.ConnectToNSQLookupd(address); err != nil { // 通过lookupd查询
return err
}
return nil
}
func init() {
err := initConsumer("topic_demo", "first", "127.0.0.1:4161")
if err != nil {
fmt.Printf("init consumer failed, err:%v\n", err)
panic(err)
}
}
func main() {
// 一直阻塞, 直到 ctrl + c 进行 手动中断
c := make(chan os.Signal, 1) // 定义一个信号的通道
signal.Notify(c, syscall.SIGINT) // 转发键盘中断信号到c
<-c // 阻塞
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号