Go基础 -- 内置函数和数据结构操作函数
1. 常用内置函数
append // 用来追加元素到数组、slice中,返回修改后的数组、slice
close // 主要用来关闭channel
delete // 从map中删除key对应的value
panic // 停止常规的goroutine (panic和recover:用来做错误处理)
recover // 允许程序定义goroutine的panic动作
imag // 返回complex的实部 (complex、real imag:用于创建和操作复数)
real // 返回complex的虚部
make // 用来分配内存,返回Type本身(只能应用于slice, map, channel)
new // 用来分配内存,主要用来分配值类型,比如int、struct。返回指向Type的指针
cap // capacity是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map)
copy // 用于复制和连接slice,返回复制的数目
len // 来求长度,比如string、array、slice、map、channel ,返回长度
print、println // 底层打印函数,在部署环境中建议使用 fmt 包
2. init和main函数
2.1 init函数
go语言中init函数用于包(package)的初始化,该函数是go语言的一个重要特性。
-
init函数是用于程序执行前做包的初始化的函数,比如初始化包里的变量等 -
每个包可以拥有多个
init函数 -
包的每个源文件也可以拥有多个
init函数 -
同一个包中多个
init函数的执行顺序go语言没有明确的定义(说明) -
不同包的
init函数按照包导入的依赖关系决定该初始化函数的执行顺序 -
init函数不能被其他函数调用,而是在main函数执行之前,自动被调用
2.2 main函数
// Go语言程序的默认入口函数(主函数):
// func main()
// 函数体用{}一对括号包裹。
func main(){
//函数体
}
2.3 init和main的异同
相同点:
1. 两个函数在定义时不能有任何的参数和返回值,且Go程序自动调用。
不同点:
init可以应用于任意包中,且可以重复定义多个。- main函数只能用于main包中,且只能定义一个。
2.4 执行顺序
全局变量 -> init() -> main()
1. 同一个package中
同一个go文件的init()从上到下的执行。
同一个package中不同文件是按文件名字符串比较“从小到大”顺序调用各文件中的init()函数。
2. 不同的package
不同的package,按照import顺序执行init()
如果init函数中使用了println()或者print()你会发现在执行过程中这两个不会按照你想象中的顺序执行。这两个函数官方只推荐在测试环境中使用,对于正式环境不要使用。
**示例: **
同一个package中
package main
import "fmt"
func init() {
fmt.Println("第一个个定义的init")
}
func init() {
fmt.Println("第二个定义的init")
}
func main() {
fmt.Println("hello world")
}
3. 数据结构操作函数
3.1 字符串
3.1.1 len()
统计字符串长度(字节数长度,中文占用3字节)
len("abc") //3
len("abc第") //6
3.1.2 字符串遍历
字符串遍历同时处理中文问题
package main
import "fmt"
func main() {
// 如果字符串中有中文可以将str1,转换成[]rune切片,否则会按照默认的字节遍历
str1 := "hello北京"
// 1. 转成rune 切片
new_str := []rune(str1)
for _,v := range new_str{
fmt.Println(string(v))
}
}
// 打印结果
h
e
l
l
o
北
京
3.1.3 字符串数字转整数
package main
import (
"fmt"
"strconv"
)
func main() {
str1 := "12"
n,err := strconv.Atoi(str1) // 转成整数型
if err != nil{
fmt.Println(err.Error())
return
}
fmt.Printf("%v,%T",n,n)
}
// 打印结果:
12,int
3.1.3 整数转成字符串数字
package main
import (
"fmt"
"strconv"
)
func main() {
number := 12
str1 := strconv.Itoa(number) // 转成字符串
fmt.Printf("%v,%T",str1,str1)
}
// 打印结果:
12,string
// 整数转字符串:
str := strconv.Itoa(123)
// 字符串转[]byte:
bytes := []byte("hello go") // 转成字节
// []byte 转字符串:
str := string([]byte{97,98,99}) // 转成97,98,99对应的字符组成字符串
// 十进制转二,八,十六进制:
str := strconv.Formatint(123,2) 2表示进制,返回值为string
// 查找子串是否在指定的字符串中:
b := strings.Contains("hello","o") // 返回值为bool
// 统计一个字符串中有几个指定子串:
strings.Count("ceheese","e") // 没有返回0
// 不区分大小写的字符串比较(==是区分大小写的比较):
strings.EqualFold("ab","AB") // 返回值为bool
// 返回子串在字符串中第一次出现的index值,如果没有返回-1:
strings.index("abcaa","a")
// 字符串替换
strings.Replace("go go hello","go","go语言",n) // n可以指定替换几个,如果n=-1, 表示全部替换
// 字符串分割
stings.split("hello,world",",")
// 大小写转换
strings.Tolower("Go")
strings.ToUpper("go")
// 去除字符串两边的空格
strings.TrimSpace(" hello ")
//字符串两边,指定字符去除
strings.Trim("!hello!","!")
// 字符串左边指定字符去除
strings.TrimLeft("!hello","!")
// 字符串右边指定字符去除
strings.TrimRight("!hello!","!")
// 是否以指定字符开头
strings.HasPrefix("http://","http")
// 是否以指定字符结束
strings.HasSuffix("http://www.baidu.com","com")
3.2 日期时间
import time // 包导入
// 获取当前时间
time.Now() // 类型为time.Time
// 获取年月日等等日期信息
now := time.Now()
now.Year()
now.Month() // May , 转成对应的数字,可以直接用int(now.Month())强转
now.Day()
now.Hour()
now.Minute()
now.Second()
// 格式化日期和时间
now := time.Now()
// 方式一:使用Printf 或者 Sprintf
fmt.Printf("%02d-%02d-%02d %02d:%02d:%02d",now.Year(),int(now.Month()),now.Day(),now.Hour(),now.Minute(),now.Second())
string = fmt.Sprintf("%02d-%02d-%02d %02d:%02d:%02d",now.Year(),int(now.Month()),now.Day(),now.Hour(),now.Minute(),now.Second()) //返回给变量然后存入数据库
fmt.Println(string)
// 方式二:Format()
fmt.Printf(now.Format("2006-01-02 15:04:05")) // 2006/01/02 15:04:05时间格式是固定的
/* 时间的常量
Nanosecond Duration=1 //纳秒
Microsecond == 1000 * Nanosecond // 微妙
Millisecond == 1000 * Microsecond // 毫秒
Second == 1000 * Millisecond // 秒
Minute == 60 * second // 分钟
Hour == 60 * Minute // 小时
想得到100毫秒 100 * Millisecond
*/
// 获取当前时间戳 (可以获取随机的数字)
// Unix 时间戳 -- 秒数
// Unixnano 时间戳 -- 纳秒数
now := time.Now()
now.Unix()
now.Unixnano()
3.3 数组
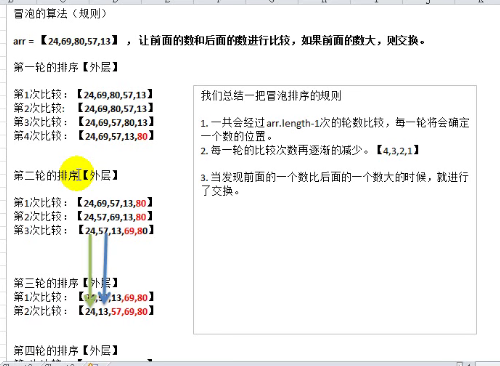
排序之冒泡排序
// 冒泡排序法
通过对 带排序序列从后向前(从下表较大的元素开始),一次比较相邻元素的排序码,若发现逆序则交换,使排序码较小的元素逐渐从后部移向前部(从下标较大的单元移向下表较小的单元)
// 优化思想:
因为在排序的过程中,各元素不断接近自己的位置,如果一次比较下来没有进行过交换,就说明序列有序,因此要在排序过程中设置一个标志flag 判断元素是否进行过交换,从而减少不必要的比较
func BubbleSort(arry *[5]int){
temp := 0 //临时变量,用来存储交换的值
for i := 0; i < len(*arry) - 1;i++{
for j := 0; j < len(*arry) -1 - i;j++{
if (*arry)[j] > (*arry)[j+1]{
temp = (*arry)[j]
(*arry)[j] = (*arry)[j + 1]
(*arry)[j + 1] = temp
}
}}
}
func main(){
var arry [5]int = [5]int{11,3,444,5,6}
BubbleSort(*arry)
}
// 选择式排序法
// 插入式排序法
// 合并排序法
// 直接合并排序法
// 内部排序
// 数据量较小,将需要处理的所有数据都加在到内部存储器中进行排序
// 交换式排序法(冒泡排序Bubble sort,快速排序quick sort)
// 外部排序
// 数据量过大,无法全部加在到内存中,需要借助外部存储进行排序
python防脱发技巧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号