is 和 == 区别 编码的问题 id()函数
一丶is 和 == 的区别
== 比较的是值
is 比较的是内存地址
#字符串 a = "abc" b = "abc" print(a == b) print(a is b)
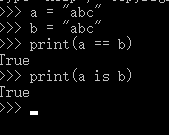
#数字 a = 123 b = 123 print(a == b) print(a is b)
# 字典 a = {"a":1,"b":2,"c":3} b = {"a":1,"b":2,"c":3} print(a == b) print(a is b) print(id(a)) print(id(b))

#元组 a = (1,"a","b") b = (1,"a","b") print(a == b) print(a is b) print(id(a)) print(id(b))

#列表 a = [1,"a","b"] b = [1,"a","b"] print(a == b) print(a is b) print(id(a)) print(id(b))

二丶id() 和小数据池
id()是查看内存地址的
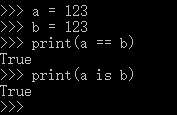
a = 123
print(id(a))
⼩数据池(常量池): 把我们使⽤过的值存储在⼩数据池中.供其他的变量使⽤.
注:在python中一般的字符串都是会被缓存的,为了节约内存
⼩数据池给数字和字符串使⽤, 其他数据类型不存在
对于数字: -5~256是会被加到⼩数据池中的. 每次使⽤都是同⼀个对象.
对于字符串:
-
如果是纯⽂字信息和下划线. 那么这个对象会被添加到⼩数据池
-
如果是带有特殊字符的. 那么不会被添加到⼩数据池. 每次都是新的
-
如果是单⼀字⺟*n的情况. 'a'*20, 在20个单位内是可以的. 超过20个单位就不会添加到⼩数据池中
三丶编码的补充
ascii 码:
不支持中文
支持 英文 数字 符号
8位 一个字符
gbk码 国标码:
支持 中文,英文,数字,符号
英文 16位 二个字节
中文 16位 二个字节
unicode 万国码:
支持 中文,英文,数字,符号
英文 32位 四个字节
中文 32位 四个字节
utf-8 长度可变的万国码 :
最少用8位
英文 8位 一个字节
中文 24位 三个字节
Python3中 程序运行阶段 使用的是unicode 显示所有的内容
bytes类型
传输和存储都是使用bytes
pycharm 存储的时候默认是使用utf-8
编码和解码:
encode(编码方式) -----拿到明文编码后对应的字节
decode(编码方式) -----将编码后的字节解码成对应的明文
s = "饿了吗" s1 = s.encode("utf-8") #编码 encode(XXX) XXX是指要编码的类型 print(s1) s2 = s1.decode("utf-8") #解码 decode(XXX) XXX是指要解码的类型 print(s2)

注意:用什么进行编码就要用什么进行解码 不然会解不开

 浙公网安备 33010602011771号
浙公网安备 33010602011771号