while循环,break和continue,运算符,格式化输出
一丶while循环
while条件:
代码块(循环体)
1 #数数 打印1-100 2 count = 1 3 while count <= 100: 4 print(count) 5 count += 1
执行顺序:
判断条件是否为真.如果真,执行循环体,然后再次判断条件......直到循环条件为假,程序退出.
while else循环:
while 条件:
代码块(循环体)
else:
代码块


1 flag = True 2 while flag: 3 count = input("请输入一句话,输入q退出:") 4 if count == "q": 5 flag = False 6 print(count) 7 else: 8 print("退出成功!")
二丶break和continue
break:停止当前本层循环
示例:
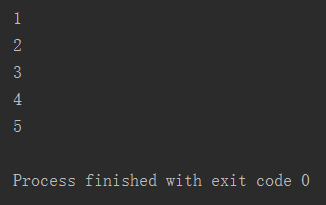
1 count = 1 2 while count < 10: 3 print(count) 4 count += 1 5 if count == 6: 6 break
运行结果:
continue:停止当前本次循环,继续进行下一次循环
示例:
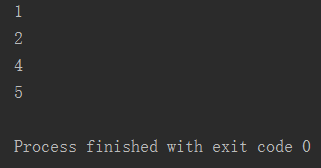
1 count = 0 2 while count < 5: 3 count += 1 4 if count == 3: 5 continue 6 print(count)
运行结果:
三丶格式化输出
%s 占位字符串
示例:
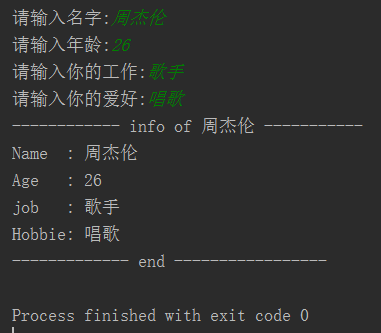
1 name = input("请输入名字:") 2 age = input("请输入年龄:") 3 job = input("请输入你的工作:") 4 hobby = input("请输入你的爱好:") 5 6 s = '''------------ info of %s ----------- 7 Name : %s 8 Age : %s 9 job : %s 10 Hobbie: %s 11 ------------- end -----------------''' % (name, name, age, job, hobby) 12 print(s)
运行结果:
%d 占位数字
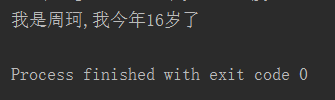
1 s = "我是%s,我今年%d岁了"%("周珂",16) 2 print(s)
四丶运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
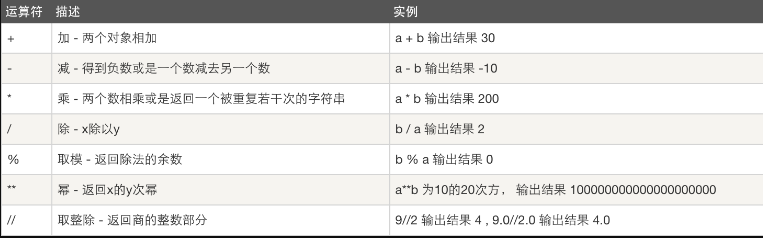
算数运算:
以下假设 a=10,b=20
比较运算:

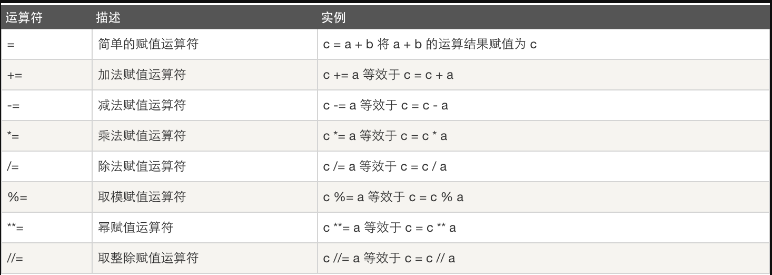
赋值运算:
逻辑运算:

1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
示例:
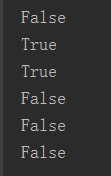
print(3>4 or 4<3 and 1==1) print(1 < 2 and 3 < 4 or 1>2) print(2 > 1 and 3 < 4 or 4 > 5 and 2 < 1) print(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8) print(1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6) print(not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6)
运行结果:
2. x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。
Ture为非零,False为零
五丶编码
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
总结:
1. Ascii. 最早的编码. 至今还在使用. 8位一个字节(字符)
2. GBK. 国标码. 16位2个字节.
3. unicode. 万国码. 32位4个字节
4. UTF-8. 可变长度的unicode.
英文: 8位. 1个字节
欧洲文字:16位. 2个字节
汉字. 24位. 3个字节


 浙公网安备 33010602011771号
浙公网安备 33010602011771号