
爬虫---爬取公众号内容
前面写都是抓取一些网站上的数据,今天工作提前完成了,闲来无事写一篇如何抓取公众号数据。
爬取公众号
常见的爬取公众号有3种方法
1、通过抓包获取公众号数据(app端)
2、通过抓包获取公众号数据(PC端)
3、通过搜狗搜索公众号(目前只能显示前10篇文章)
今天写的是通过抓取PC端数据获取公众号内容。
抓取思路
1、选择需要抓取的公众号链接
通过PC端微信选择需要抓取的公众号
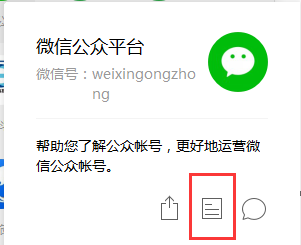
2、分析公众号数据格式
通过fiddler查看请求信息
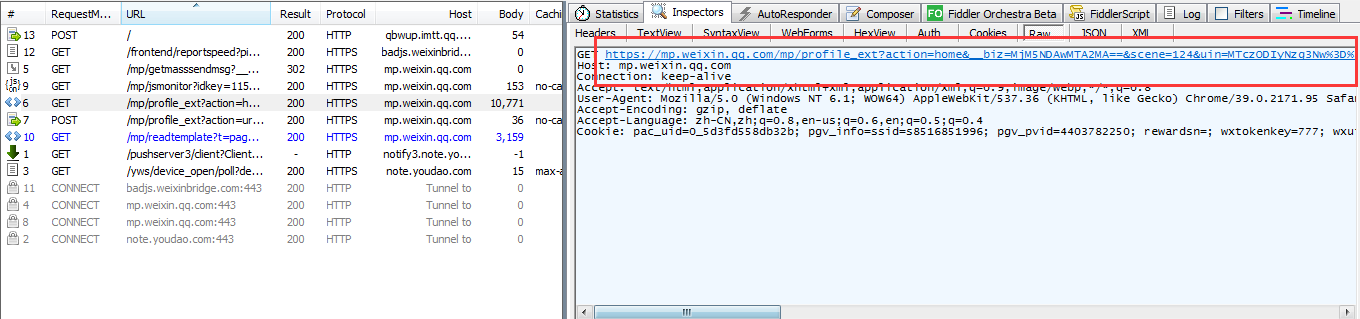
发现我们请求的地址为:https://mp.weixin.qq.com/mp/profile_ext? 后面的为参数
这里会引入一个新的知识点Ajax。
通过分析数据得到(如何分析Ajax方法,下一篇单独写)
__biz : 用户和公众号之间的唯一id,
uin :用户的私密id
key :请求的秘钥,一段时候只会就会失效。
offset :数量
count :每次请求的条数
3、通过requests请求获取数据
import requests # 请求地址 url = 'https://mp.weixin.qq.com/mp/profile_ext?' # 添加请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' } # 请求参数 params={ '__biz': 'MjM5NDAwMTA2MA==', 'uin': 'MTczODIyNzg3Nw==', 'key': 'f0a7c0779e79e92b25b1a3f8779ec559b50f247ff4dd1ece070c17dd08d9dbdc602bbd8c5837e4b68c252507ac45796c2f928b87d1cdfdbd2852c1b48f9e019806524a1c8d633b8886c30d48f6a82a8c', 'offset': 0, 'count': 10, 'action': 'getmsg', 'f': 'json' } # 获取请求的json格式 r = requests.get(url,headers=headers,params=params,verify = False).json()
4、解析请求数据获取我们想要内容
下图为我们想要的数据公众号的名称,链接,图片等
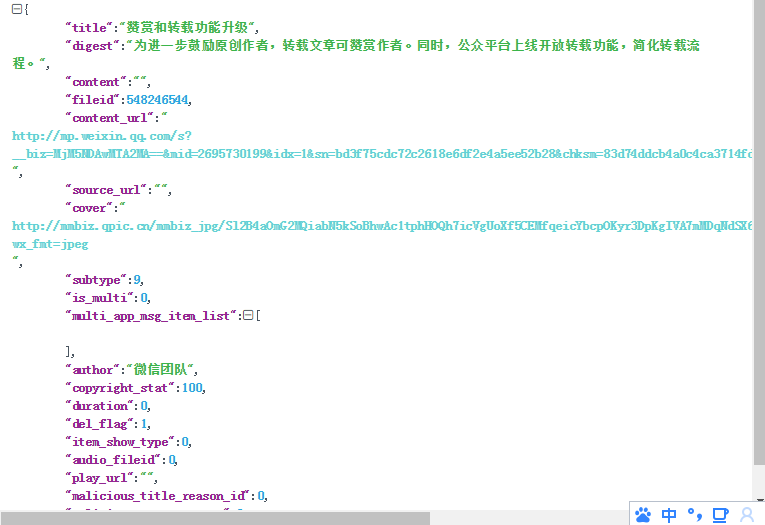
通过json格式解析返回的json数据,拿到我们想要的数据
msg_list = json.loads(r['general_msg_list']) list = msg_list.get('list') for i in list: info_list = i['app_msg_ext_info'] # 获取标题 title = info_list['title'] print(title) # 链接 content_url = info_list['content_url'] print(content_url) #发布时间 datetime_list = i['comm_msg_info']['datetime'] datetime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(datetime_list)) print(datetime)
请求结果:获取到了公众号的标题,公众号好的链接,公众号号的发布时间

这个地方也可以通过模拟url链接信息,然后获取全部数据,也可以再次请求公众号详情数据获取公众号发布的内容
5、分析分页规律,获取全部公众号全部文章信息
通过分析发现控制分页的的是 offset 和 count 两个参数,通过观察发现规律,获取全部连接数据
# 这里模拟抓取5页的数据 for i in range(0,5): print('开始抓取第%s页数据'%(i+1)) params={ '__biz': 'MjM5NDAwMTA2MA==', 'uin': 'MTczODIyNzg3Nw==', 'key': 'f0a7c0779e79e92b25b1a3f8779ec559b50f247ff4dd1ece070c17dd08d9dbdc602bbd8c5837e4b68c252507ac45796c2f928b87d1cdfdbd2852c1b48f9e019806524a1c8d633b8886c30d48f6a82a8c', 'offset': (i*10)+122, 'count': (i*10)+10, 'action': 'getmsg', 'f': 'json' }

实例代码
# coding:utf-8 import requests import json import urllib3 import time urllib3.disable_warnings() # 请求地址 url = 'https://mp.weixin.qq.com/mp/profile_ext?' # 添加请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' } # 请求参数 for i in range(0,5): print('开始抓取第%s页数据'%(i+1)) params={ '__biz': 'MjM5NDAwMTA2MA==', 'uin': 'MTczODIyNzg3Nw==', 'key': 'f0a7c0779e79e92b25b1a3f8779ec559b50f247ff4dd1ece070c17dd08d9dbdc602bbd8c5837e4b68c252507ac45796c2f928b87d1cdfdbd2852c1b48f9e019806524a1c8d633b8886c30d48f6a82a8c', 'offset': (i*10)+122, 'count': (i*10)+10, 'action': 'getmsg', 'f': 'json' } # 获取请求的json格式 r = requests.get(url,headers=headers,params=params,verify = False).json() msg_list = json.loads(r['general_msg_list']) list = msg_list.get('list') for i in list: info_list = i['app_msg_ext_info'] # 获取标题 title = info_list['title'] print(title) # 链接 content_url = info_list['content_url'] print(content_url) #发布时间 datetime_list = i['comm_msg_info']['datetime'] datetime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(datetime_list)) print(datetime)
感觉写的对您有帮助的话,点个关注,持续更新中~~~~坚持每天学习2小时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号