

mongodb(1)
一、数据库操作
-
切换数据库
use database_name
use school
注:如果数据库存在,则切换到该数据库下,如果此数据库还不存在,也可以切过来,但是并不能立刻创建该数据库
-
查看所有得数据库
show dbs
备注:刚创建的数据库shcool如果不在查询的列表中,如果要显示它,则需要向school中插入数据
db.students.insert({age:1})
-
查看当前使用的数据库
db
-
删除数据库
db.dropDatabase()
二、集合操作
查看集合帮助
use demo
db.demo.help()
创建集合
db.createCollection(collection_name)
创建集合并插入一个文档
db.collection_name.insert({document})
//例如
db.demo.insert({age:1})

注:上图里的ObjectId是有规律的,规律如下
之前我们使用MySQL等关系型数据库时,主键都是设置成自增的。但在分布式环境下,这种方法就不可行了,会产生冲突。为此,MongoDB采用了一个称之为ObjectId的类型来做主键。ObjectId是一个12字节的 BSON 类型字符串。按照字节顺序,依次代表:
| - | - |
|---|---|
| 4字节: | UNIX时间戳 |
| 3字节: | 表示运行MongoDB的机器 |
| 2字节: | 表示生成此_id的进程 |
| 3字节: | 由一个随机数开始的计数器生成的值 |
查看当前数据库下的集合
show collections
删除当前集合
db.collection_name.drop() 例如: db.demo.drop()
文档操作
插入文档
- insert
db.collection_name.insert({document})
collection_name:集合的名字
document 插入的文档(数据)
注:每当插入一条新文档的时候mongodb会自动为此文档生成一个_id属性,_id属性是唯一的,用来标识一个文档,_id也可以直接指定,但如果数据库中此集合下已经有此_id的话,将插入失败2
- save
db.collection_name.save(document)
注:如果不指定_id字段,save方法类似于insert方法。如果指定_id字段,则会更新_id的数据。
db.demo.save({_id:1, age:2})
更新文档
语法
db.collection.update(
,
,
{
upsert:,
multi:
}
)
参数:
query: 查询条件,指定要更新符合哪些条件的文档
update: 更新后的对象或指定一些更新的操作符
$set: 在原基础上累加
upsert: 可选,如果不存在符合条件的记录时是否插入updateObj。默认是false,不插入
multi:可选,mongodb默认只更新找到的第一条记录,如果这个参数为true,就更新所有符合条件的记录。
更新文档
db.demo.insert({name:'zhangsan'})
db.demo.update({name:'zhangsan'},{age:12})
upsert
将students集合的数据中name是lisi的值改为ww,原本数据库中没该数据,也不会插入成功,但是设置upsert为true后就能插入成功
db.demo.update({name:'lisl'}, {name:'ww'}, {upsert:true})
multi
如果有多条age是1的数据,只更新一条,如果想全部更新,需要指定{multi:true}参数
db.school.insert({age:1})
db.school.insert({age:1})
db.school.insert({age:1})
db.school.update({age:1}, {$set:{name:'lisi'}}, {multi:true})
db.school.find()
更新操作符
$set
直接指定更新后的值
use c3;
db.c3.insert({name:'a'});
db.c3.update({name:'a'},{$set:{age:10}});
db.c3.find({})
$inc
在原基础上累加
db.c3.update({name:'a'},{$inc:{age:1}})
$unset
删除指定的键
db.c3.update({name:'2'}, {$unset:{age:11}}) 删除name为'2'的文档中的age为11的数据
$push
向数组中添加元素
db.c3.insert({name:'2', age:10})
db.c3.update({name:'2'}, {$push:{hobbys:'drink'}}, {multi: true})
向name为2的文档中的数组hobbys中添加drink
$ne
$ne类似于MYSQL的not in 或者 not exists
db.c3.update({hobbys:{$ne:"eating"}}, {$push:{"hobbys":"sleeping"}}, {multi:true})
将c3集合中没有hobbys属性,或者hobbys文档中hobbys中没有sleeping的集合中添加hobbys数组或者追加数据到hobbys数组
$addToSet
向集合中添加数组元素(一条)
db.c3.update({name:'a'}, {$addToSet:{"addr":"hb"}})
$each
把数组中的元素逐个添加到集合中(可以添加多条)
db.c3.update({name:'a'}, {$addToSet:{"addr":{$each:["wh", "sh"]}}})
$pop
从数组中移除指定的索引中对应的元素
- ${pop:{key:1}} 从数组末尾删除一个元素
- ${pop:{key:-1}} 从数组开头删除一个元素
db.c3.update({name:'a'}, {$pop:{addr:1}})
修改指定索引的元素
修改c3中第一个name为a的集合中add数组文档
db.c3.update({name:'a'}, {$set:{"addr.1":"zh"}})
删除文档
remove方法是用来移除集合中的数据
语法
db.collection.remove(
<query>,
{
justOne: <boolean>
}
)
参数
| - | - |
|---|---|
| query | (可选)删除的文档的条件。 |
| justOne | (可选)如果设为 true 或 1,则只删除匹配到的多个文档中的第一个 |
实例
删除wroker集合里name是a的所有文档数据
db.c3.remove({name:'a'})
即时匹配多条也只删除一条
db.c3.remove({name:'a'},{justOne:true})
查询文档
find
db.collection_name.find()
查询指定的列
语法
db.collection_name.find({querywhere},{key:1,key:1})
参数列表
| - | - |
|---|---|
| collection_name | 集合的名字 |
| queryWhere | 参阅查询条件操作符 |
| key | 指定要返回的列 |
| 1 | 表示要显示 |
实例
只返回显示age列
db.c3.insert([{name:1,age:2},{name:1,age:3},{name:1,age:4}])
db.c3.find({}, {_id:0,age:1})
findOne
查询匹配结果的第一条数据 语法
db.collection_name.findOne()
实例
db.c3.findOne()
$in
查询字段在某个范围内
查询age为3或4的文档中的name和age
db.c3.find({age:{$in:[3,4]}}, {name:1, age:1})
$nin
查询字段不在某个范围内
db.c3.find({age:{$nin:[3,4]}}, {name:1, age:1})
$not
对特定条件取反
db.c3.find({age:{$not:{$gte:3, $lte:4}}})
释:查找age不在3到4之间的
array
where
db.c3.find({$where:"this.age>2"}, {name:1,age:1})
注意:$where后面的条件需要引号
cursor
游标不是 查询结果,而是查询的一个返回资源 或接口,通过这个接口,可以逐条读取数据
var result = db.student.find();
while(result.hasNext()){
printjson(result.next());
}
条件操作符
条件操作符用于比较两个表达式并从mongoDB集合中获取数据
大于、大于等于、小于、小于等于
参数
| - | - |
|---|---|
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
使用_id进行查询
语法
db.collection_name.find({"_id": ObjectId("value")})
db.c3.find({_id:ObjectId("5d99738a82b8ca8cde36ac7e")})
查询结果集的条数
语法
db.collecton_name.find().count()
db.c3.find().count()
正则匹配
语法
db.collection_name.find({key:/value/})
参数
| - | - |
|---|---|
| collectoin_name | 集合名称 |
| key | 字段 |
| value | 值 |
查询name里包含qiao的数据,正则只能匹配字符串
db.c3.insert({name:"qiaogege"})
db.user.find({name:/qiao/})
与和或
and
find方法可以传入多个键(key),每个键(key)以逗号隔开
语法
db.collection_name.find({key1:value1, key2:value2})
查询name是1并且age是2的数据
db.c3.find({name:1,age:2})
or
语法
db.collection_name.find(
{
$or: [
{key1: value1}, {key2:value2}
]
})
查询age=2或者age=3的数据
db.c3.find({$or:[{age:2},{age:3}]})
and和or联用
语法
db.collection_name.find(
{
key1:value1,
key2:value2,
$or: [
{key1: value1},
{key2:value2}
]
}
)
实例
查询age是2并且name是zs或者name是lisi的数据
db.c3.insert([{age:25,name:"zs"},{age:25,name:"lisi"},{age:25,name:"wangwu"}])
db.c3.find({age:25,$or:[{name:"zs"},{name:"lisi"}]})
分页查询
limit
读取指定数量的数据记录 语法
db.collection_name.find().limit(number)
var a = [];
for (var i = 0; i < 10; i++) {
a.push({age:i})
}
db.c3.insert(a);
db.c3.find().limit(3)
skip
跳过指定数量的数据,skip方法同样接收一个数字参数作为跳过记录的条数 语法
db.collection_name.find().skip(number)
db.c3.find().skip(2)
skip+limit实现分页
通常用这种方式来实现分页功能 语法
db.collection_name.find().skip(skipNum).limit(limitNum)
db.c3.find().skip(2).limit(2)
sort排序
sort()方法可以通过参数指定排序的字段,并使用1和-1来指定排序的方式,其中1表示为升序,-1表示降序。语法
db.colleciton_name.find().sort({key:1})
db.collection_name.find().sort({key:-1})
db.c3.find().sort({age:1})
聚合查询
group
group 的作用是按指定的键对集合中的文档进行分组,并执行简单的聚合函数,它与 SQL 中的 SELECT ... GROUP BY 类似。其语法格式如下:
{
group:
{
ns: <namespace>,
key: <key>,
$reduce: <reduce function>,
$keyf: <key function>,
cond: <query>,
finalize: <finalize function>
}
}
group 支持的指令及对应描述如下:
| 指令 | 类型 | 描述 |
|---|---|---|
ns |
string | 通过操作执行组的集合,必填。 |
key |
ducoment | 要分组的字段或字段,必填。 |
$reduce |
function | 在分组操作期间对文档进行聚合操作的函数。 该函数有两个参数:当前文档和该组的聚合结果文档。 必填。 类似having操作 |
initial |
document | 初始化聚合结果文档, 必填。 |
$keyf |
function | 替代 key。指定用于创建“密钥对象”以用作分组密钥的函数。 使用$keyf而不是 key按计算字段而不是现有文档字段进行分组。 |
cond |
document | 用于确定要处理的集合中的哪些文档的选择标准。 如果省略,group 会处理集合中的所有文档。相当于where筛选 |
finalize |
function | 在返回结果之前运行,此函数可以修改结果文档。 |
db.sales.insertMany([
{_id: 1, orderDate: ISODate("2012-07-01T04:00:00Z"), shipDate: ISODate("2012-07-02T09:00:00Z"), attr: {name: "新款椰子鞋", price: 2999, size: 42, color: "香槟金"}},
{_id: 2, orderDate: ISODate("2012-07-03T05:20:00Z"), shipDate: ISODate("2012-07-04T09:00:00Z"), attr: {name: "高邦篮球鞋", price: 1999, size: 43, color: "狮王棕"}},
{_id: 3, orderDate: ISODate("2012-07-03T05:20:10Z"), shipDate: ISODate("2012-07-04T09:00:00Z"), attr: {name: "新款椰子鞋", price: 2999, size: 42, color: "香槟金"}},
{_id: 4, orderDate: ISODate("2012-07-05T15:11:33Z"), shipDate: ISODate("2012-07-06T09:00:00Z"), attr: {name: "极速跑鞋", price: 500, size: 43, color: "西湖蓝"}},
{_id: 5, orderDate: ISODate("2012-07-05T20:22:09Z"), shipDate: ISODate("2012-07-06T09:00:00Z"), attr: {name: "新款椰子鞋", price: 2999, size: 42, color: "香槟金"}},
{_id: 6, orderDate: ISODate("2012-07-05T22:35:20Z"), shipDate: ISODate("2012-07-06T09:00:00Z"), attr: {name: "透气网跑", price: 399, size: 38, color: "玫瑰红"}}
])
假设要将集合 sales 中的文档按照 attr.name 进行分组,并限定参与分组的文档的 shipDate 大于指定时间。对应示例如下:
# select name from sales where shipDate > '2012-07-04T09:00:00Z' group by name
db.runCommand({
group:{
# from操作
ns: 'sales',
# group by操作
key: {"attr.name": 1},
# where操作
cond: {shipDate: {$gt: ISODate('2012-07-04T09:00:00Z')}},
# 这个处理类似having的操作; curr:是当前遍历的文档,result聚合的结果文档
$reduce: function(curr, result){
},
initial: {}
}
})
命令执行后,会返回一个结果档。其中, retval 包含指定字段 attr.name 的数据,count 为参与分组的文档数量,keys 代表组的数量,ok 代表文档状态
# select shipDate, count(price) total from sales where shipDate > '2012-07-04T00:00:00Z' group by shipDate
db.runCommand({
group:{
ns: 'sales',
key: {shipDate: 1},
cond: {shipDate: {$gt: ISODate('2012-07-04T00:00:00Z')}},
initial: {total: 0},
$reduce: function(curr, result){
result.total += curr.attr.price;
}
}
})
# select shipDate, count, total, avg(price) avg from sales where shipDate > '2012-07-04T00:00:00Z' group by shipDate
db.runCommand(
{
group:{
ns: 'sales',
key: {shipDate: 1},
cond: {shipDate: {$gt: ISODate('2012-07-04T00:00:00Z')}},
$reduce: function(curr, result){
result.total += curr.attr.price;
result.count ++;
},
initial: {total: 0, count: 0},
finalize: function(result) {
result.avg = Math.round(result.total / result.count);
}
}
})
上面的示例中改动了 $reduce 函数,目的是为了统计 count。然后新增了 finalize,目的是计算分组中的平均销售额
aggregate聚集框架
管道操作符
| 常用管道 | 含义 |
|---|---|
| $group | 将collection中的document分组,可用于统计结果 |
| $match | 过滤数据,只输出符合结果的文档 |
| $project | 修改输入文档的结构(例如重命名,增加、删除字段,创建结算结果等) |
| $sort | 将结果进行排序后输出 |
| $limit | 限制管道输出的结果个数 |
| $skip | 跳过制定数量的结果,并且返回剩下的结果 |
| $unwind | 将数组类型的字段进行拆分 |
管道的概念:
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
聚合的表达式 :
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
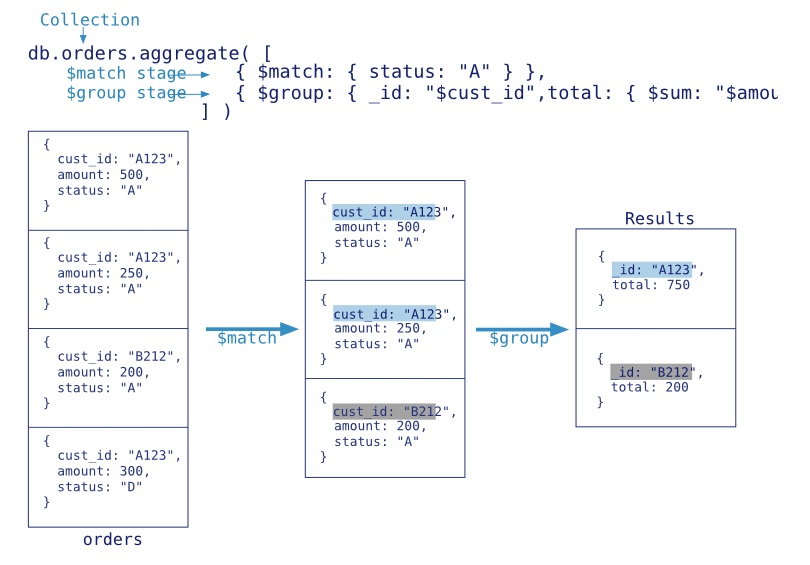
数据准备
use shcool
db.createCollection("student")
var arr = [
{_id:1, name:'zs',subject:'语文',score:90,cid:1},
{_id:2, name:'zs',subject:'数学',score:95,cid:1},
{_id:3, name:'zs',subject:'英语',score:95,cid:1},
{_id:4, name:'ls',subject:'语文',score:80,cid:1},
{_id:5, name:'ls',subject:'数学',score:85,cid:1},
{_id:6, name:'ls',subject:'英语',score:90,cid:1},
{_id:7, name:'ww',subject:'语文',score:70,cid:2},
{_id:8, name:'ww',subject:'数学',score:75,cid:2},
{_id:9, name:'ww',subject:'英语',score:55,cid:2}
]
db.student.save(arr)
db.createCollection("class")
db.class.save([{_id:1, cid: 1, name:"3年1班"}, {_id:2, cid: 2, name:"3年2班"}])
操作
# 查询name为ls的
db.student.aggregate([
{$match: {name:'ls'}}
])
# 查询数学成绩大于等于80,小于90的人
db.student.aggregate([
{$match: {subject : "数学", score: {$gte: 80, $lt: 90}}}
])
# 根据name分组求每个人的选课数
db.student.aggregate([
{$group:{_id: "$name", snumber: {$sum:1}}}
])
#_id: 指定分组的字段
# "$name": 引用集合中的文档"name", 需要用$符号
# snumber是{$sum:1}计算出来的值的别名
# {$sum:1}这里是1, 和mysql中count(1)一个意思
# 求每个人的总分
db.student.aggregate([
{$group:{_id: "$name", snumber: {$sum:"$score"}}}
])
# $sum:"$score" 在这里的意思是sum求和
# 成绩大于等于80的科目求总分,同时总分要大于240分
db.student.aggregate([
{$match: {score: {$gte: 80}}},
{$group:{_id: "$name", snumber: {$sum: "$score"}}},
{$match: {snumber: {$gte:240}}}
])
# $match在group上面前面类似于mysql的where
# $match 在 group后面,类似于mysql的having
# 按名字分组求平均
db.student.aggregate([
{$group:{_id: "$name", snumber: {$avg : "$score"}}}
])
looup
$lookup 的作用是对同一数据库中的集合执行左外连接,其语法格式如下:
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
| 领域 | 描述 |
|---|---|
from |
指定集合名称。 |
localField |
指定输入 $lookup 中的字段。 |
foreignField |
指定from 给定的集合中的文档字段。 |
as |
指定要添加到输入文档的新数组字段的名称。 新数组字段包含from集合中的匹配文档。 如果输入文档中已存在指定的名称,则会覆盖现有字段 。 |
# select c.*, studentArr from class c inner join student s where c.cid = s.cid
# 不同的是这个studentArr是以数组的形式作为class的字段出现
db.class.aggregate([
{
$lookup: {
from: "student",
localField: "cid", #class中的字段
foreignField: "cid", #student中的字段
as: "studentArr"
}
}
]).pretty()
# 结果部分截取
{
"_id" : 1,
"cid" : 1,
"name" : "3年1班",
"studentArr" : [
{
"_id" : 1,
"name" : "zs",
"subject" : "语文",
"score" : 90,
"cid" : 1
},
{
"_id" : 2,
"name" : "zs",
"subject" : "数学",
"score" : 95,
"cid" : 1
}
}
unwind
unwind 能将包含数组的文档拆分称多个文档,其语法格式如下:
{
$unwind:
{
path: <field path>,
includeArrayIndex: <string>,
preserveNullAndEmptyArrays: <boolean>
}
}
| 指令 | 类型 | 描述 |
|---|---|---|
path |
string | 指定数组字段的字段路径, 必填。 |
includeArrayIndex |
string | 用于保存元素的数组索引的新字段的名称。 |
preserveNullAndEmptyArrays |
boolean | 默认情况下,如果path为 null、缺少该字段或空数组, 则不输出文档。反之,将其设为 true 则会输出文档。 |
db.shoes.save({_id: 1, brand: "Nick", sizes: [37, 38, 39]})
> db.shoes.aggregate([{$unwind : "$sizes"}])
{ "_id" : 1, "brand" : "Nick", "sizes" : 37 }
{ "_id" : 1, "brand" : "Nick", "sizes" : 38 }
{ "_id" : 1, "brand" : "Nick", "sizes" : 39 }
显然,这样的文档更方便我们做数据处理。preserveNullAndEmptyArrays 指令默认为 false,也就是说文档中指定的 path 为空、null 或缺少该 path 的时候,会忽略掉该文档。假设数据如下:
> db.shoes2.insertMany([
{"_id": 1, "item": "ABC", "sizes": ["S", "M", "L"]},
{"_id": 2, "item": "EFG", "sizes": [ ]},
{"_id": 3, "item": "IJK", "sizes": "M"},
{"_id": 4, "item": "LMN" },
{"_id": 5, "item": "XYZ", "sizes": null}
])
> db.shoes2.aggregate([{$unwind: "$sizes"}])
{ "_id" : 1, "item" : "ABC", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC", "sizes" : "L" }
{ "_id" : 3, "item" : "IJK", "sizes" : "M" }
# 已经忽略了 sizes == null, sizes.leng <= 0, size == undefind的数据
_id 为 2、4 和 5 的文档由于满足 preserveNullAndEmptyArrays 的条件,所以不会被拆分。
以上就是 unwind 的基本用法和作用介绍,更多与 unwind 相关的知识可查阅官方文档 unwind
out
out 的作用是聚合 Pipeline 返回的结果文档,并将其写入指定的集合。要注意的是,out 操作必须出现在 Pipeline 的最后。out 语法格式如下
{ $out: "
" }
> db.student.aggregate([
{$group:{_id: "$name", snumber: {$avg : "$score"}}},
{ $out : "avg_result" }
])
> show tables
avg_result
# 发现生成了一个集合 avg_result
Map-Reduce
Map-reduce 用于将大量数据压缩为有用的聚合结果,其语法格式如下:
db.runCommand({
mapReduce: <collection>,
map: <function>,
reduce: <function>,
finalize: <function>,
out: <output>,
query: <document>,
sort: <document>,
limit: <number>,
scope: <document>,
jsMode: <boolean>,
verbose: <boolean>,
bypassDocumentValidation: <boolean>,
collation: <document>,
writeConcern: <document>
})
其中,db.runCommand({mapReduce: }) 也可以写成 db.collection.mapReduce()。各指令的对应描述如下:
| 指令 | 类型 | 描述 |
|---|---|---|
mapReduce |
collection | 集合名称,必填。 |
map |
function | JavaScript 函数,必填。 |
reduce |
function | JavaScript 函数,必填。 |
out |
string or document | 指定输出结果,必填。 |
query |
document | 查询条件语句。 |
sort |
document | 对文档进行排序。 |
limit |
number | 指定输入到 map 中的最大文档数量。 |
finalize |
function | 修改 reduce 的输出。 |
scope |
document | 指定全局变量。 |
jsMode |
boolean | 是否在执行map和reduce 函数之间将中间数据转换为 BSON 格式,默认 false。 |
verbose |
boolean | 结果中是否包含 timing 信息,默认 false。 |
bypassDocumentValidation |
boolean | 是否允许 mapReduce在操作期间绕过文档验证,默认 false。 |
collation |
document | 指定要用于操作的排序规则。 |
writeConcern |
document | 指定写入级别,不填写则使用默认级别。 |
简单的 mapReduce
一个简单的 mapReduce 语法示例如下:
var mapFunction = function() { ... };
var reduceFunction = function(key, values) { ... };
db.runCommand(
{
mapReduce: <input-collection>,
map: mapFunction,
reduce: reduceFunction,
out: { merge: <output-collection> },
query: <query>
})
map 函数负责将每个输入的文档转换为零个或多个文档。map 结构如下:
function() {
...
emit(key, value);
}
emit 函数的作用是分组,它接收两个参数:
- key: 指定用于分组的字段
- value : 要聚合的字段
在 map 中可以使用 this 关键字引用当前文档。
reduce 结构如下:
function(key, values) {
...
return result;
}
reduce 执行具体的数据处理操作,它接收两个参数:
key:与map中的key相同,即分组字段。values:根据分组字段,将相同key的值放到同一个数组,values就是包含这些分类数组的对象。
out 用于指定结果输出,out: 会将结果输出到新的集合,或者使用以下语法将结果输出到已存在的集合中:
out: { <action>: <collectionName>
[, db: <dbName>]
[, sharded: <boolean> ]
[, nonAtomic: <boolean> ] }
要注意的是,如果 out 指定的 collection 已存在,那么它就会覆盖该集合。在开始学习之前,我们需要准备以下数据:
db.mprds.insertMany([
{_id: 1, numb: 3, score: 9, team: "B"},
{_id: 2, numb: 6, score: 9, team: "A"},
{_id: 3, numb: 24, score: 9, team: "A"},
{_id: 4, numb: 6, score: 8, team: "A"}
])
# emit 指定按numb分组,聚合字段为score
var func_map = function() {
emit(this.team, this.score);
}
var func_reduce = function(key, values) {
return Array.sum(values);
}
# 按numb分组查询 team="A" 每个人的总分
db.student.mapReduce(func_map, func_reduce, {query: {team: "A"}, out: "mprds_result"})
接着定义 map 函数、reduce 函数,并将其应用到集合 mrexample 上。然后为输出结果指定存放位置,这里将输出结果存放在名为 mrexample_result 的集合中。
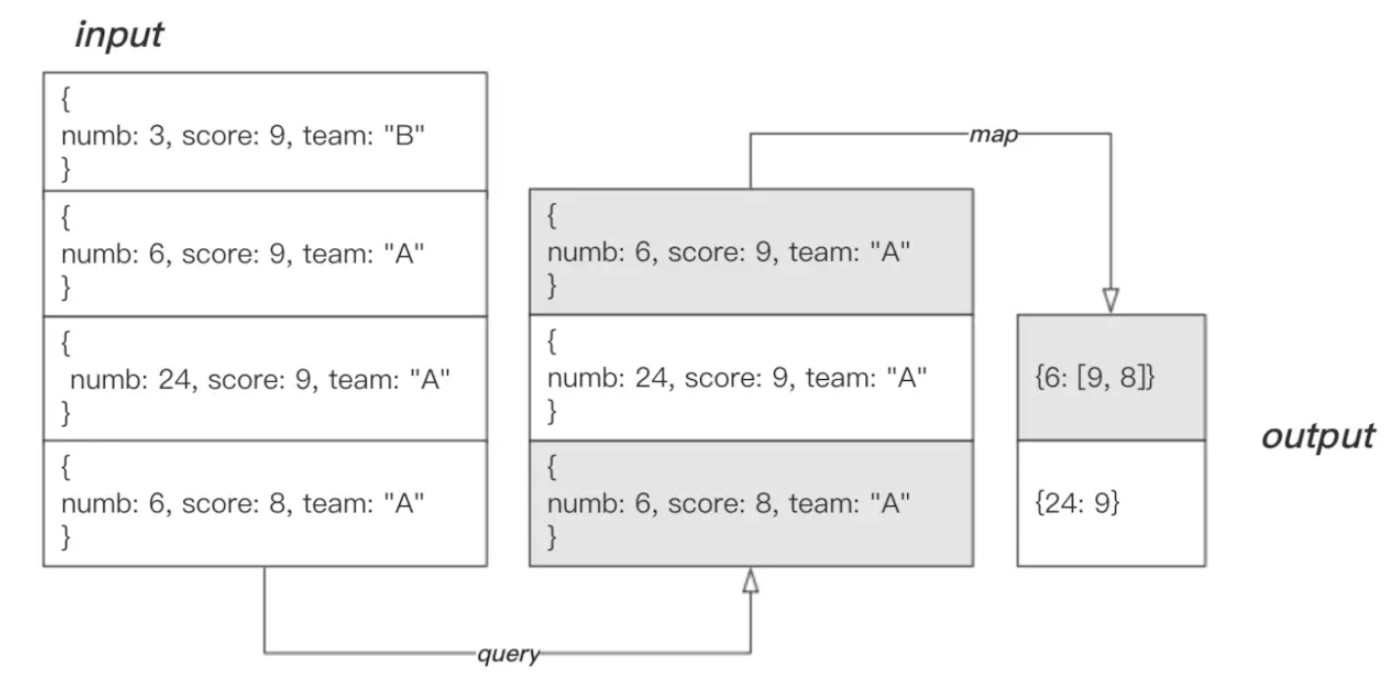
finallize(having) 剪枝
finallize 用于修改 reduce 的输出结果,其语法格式如下:
function(key, reducedValue) {
...
return modifiedObject;
}
它接收两个参数 :
key,与 map 中的 key 相同,即分组字段。
reduceValue, 一个Ojbect,是reduce的输出
上面我们介绍了 map 和 reduce,并通过一个简单的示例了解 mapReduce 的基本组成和用法。实际上我们还可以编写功能更丰富的 reduce 函数,甚至使用 finallize 修改 reduce 的输出结果。以下 reduce 函数将传入的 values 进行计算和重组,返回一个 reduceVal 对象:
var func_reduce2 = function(key, values){
reduceVal = {team: key, score: values, total: Array.sum(values), count: values.length};
return reduceVal;
};
reduceVal 对象中包含 team、score、total 和 count 四个属性。但我们还想为其添加 avg属性,那么可以在 finallize 函数中执行 avg 值的计算和 avg 属性的添加工作:
var func_finalize = function(key, values){
values.avg = values.total / values.count;
return values;
};
map 保持不变,将这几个函数作用于集合 mprds 上,对应示例如下:
# emit 指定按numb分组,聚合字段为score
var func_map = function() {
emit(this.team, this.score);
}
var func_reduce2 = function(key, values){
reduceVal = {team: key, score: values, total: Array.sum(values), count: values.length};
return reduceVal;
}
# 这个key和上面是同一个(分组的字段), values是func_reduce2函数的返回结果
var func_finalize = function(key, values) {
values.avg = values.total / values.count;
return values;
}
db.mprds.mapReduce(func_map, func_reduce2, {query: {team: "A"}, out: "mprds_result", finalize: func_finalize})
> db.mprds_result.find()
{ "_id" : "A", "value" : { "team" : "A", "score" : [ 9, 9, 8 ], "total" : 26, "count" : 3, "avg" : 8.666666666666666 } }
finallize 在 后面使用,微调 的处理结果。这着看起来像是一个园丁在修剪花圃的枝丫,所以人们将 形象地称为“剪枝”。
要注意的是:map 会将 key 值相同的文档中的 value 归纳到同一个对象中,这个对象会经过 reduce 和 finallize。对于 key 值唯一的那些文档,指定的 key 和 value 会被直接输出。
简单的聚合
count
count 用于计算集合或视图中的文档数,返回一个包含计数结果和状态的文档。其语法格式如下
{
count: <collection or view>,
query: <document>,
limit: <integer>,
skip: <integer>,
hint: <hint>,
readConcern: <document>
}
count 支持的指令及对应描述如下:
| 指令 | 类型 | 描述 |
|---|---|---|
count |
string | 要计数的集合或视图的名称,必填。 |
query |
document | 查询条件语句。 |
limit |
integer | 指定要返回的最大匹配文档数。 |
skip |
integer | 指定返回结果之前要跳过的匹配文档数。 |
hint |
string or document | 指定要使用的索引,将索引名称指定为字符串或索引规范文档。 |
假设要统计集合 mprds 中的文档数量,对应示例如下:
db.runCommand({count: 'mprds'})
{ "n" : 4, "ok" : 1 }
假设要统计集合 mprds 中 numb 为 6 的文档数量,对应示例如下:
> db.runCommand({count: 'mprds', query: {numb: {$eq: 6}}})
{ "n" : 2, "ok" : 1 }
指定返回结果之前跳过 1 个文档,对应示例如下:
> db.runCommand({count: 'mprds', query: {numb: {$eq: 6}}, skip: 1})
{ "n" : 1, "ok" : 1 }
更多关于 count 的知识可查阅官方文档 Count。
distinct
distinct 的作用是查找单个集合中指定字段的不同值,其语法格式如下:
{
distinct: "<collection>",
key: "<field>",
query: <query>,
readConcern: <read concern document>,
collation: <collation document>
}
| 指令 | 类型 | 描述 |
|---|---|---|
distinct |
string | 集合名称, 必填。 |
key |
string | 指定的字段, 必填。 |
query |
document | 查询条件语句。 |
readConcern |
document | |
collation |
document |
准备以下数据 :
db.createCollection("dress")1
db.dress.insertMany([
{_id: 1, "dept": "A", attr: {"款式": "立领", color: "red" }, sizes: ["S", "M" ]},
{_id: 2, "dept": "A", attr: {"款式": "圆领", color: "blue" }, sizes: ["M", "L" ]},
{_id: 3, "dept": "B", attr: {"款式": "圆领", color: "blue" }, sizes: "S" },
{_id: 4, "dept": "A", attr: {"款式": "V领", color: "black" }, sizes: ["S" ] }
])
# 计集合 dress 中所有文档的 dept 字段的不同值
# select distinct dept from dress
db.runCommand ( { distinct: "dress", key: "dept" } )
{ "values" : [ "A", "B" ], "ok" : 1 }
# select distinct attr.款式 from dress
db.runCommand ( { distinct: "dress", key: "attr.款式" } )
{ "values" : [ "立领", "圆领", "V领" ], "ok" : 1 }
#就算值是数组, distinct 也能作出正确处理
db.runCommand ( { distinct: "dress", key: "sizes" } )
{ "values" : [ "M", "S", "L" ], "ok" : 1 }

