

Hive FGC 问题排查步骤
背景:
本文FGC排查方法包含 Metastore 和 HiveServer2服务,Metastore是一个相对成熟的服务,通常情况下不会发生特殊的异常,Hive FGC 通常是由两种情况导致:
- 一是因为任务量得到增长导致现有服务示例不能满足当前任务的请求量,这类情况通过查看对应服务的连接数,任务数量的监控即可快速得出;
- 二是因为上层业务使用用法不恰当导致,例如发起一些全分区扫描的HQL,是可能导致发生系统异常。
本文我们重点介绍因第二种情况。
FGC排查
针对因上层业务使用用法不恰当导致的FGC,核心问题找到这个任务,只有找到任务后才能让用户停止执行并进行修正,从根本上解决这个问题,具体排查方法是如下:
step1、从Metastore侧进行排查
查看Metastore进程最多的20个存活对象。
通过命令 jmap -histo:live $PID| head -n20

存在的对象很多,但是对应不到对应的接口,更对应不到任务,只能初步判断一些大概的方向,比如,jdbc连接相关对象过多等信息,此步如果没有更具体的对象信息则较难判断;
通过mat查看具体的对象信息
jmap -dump:format=b,file=hms.hprof $pid ./ParseHeapDump.sh hms.hprof org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components。
使用浏览器打开index.html文件内容,查看分析报告
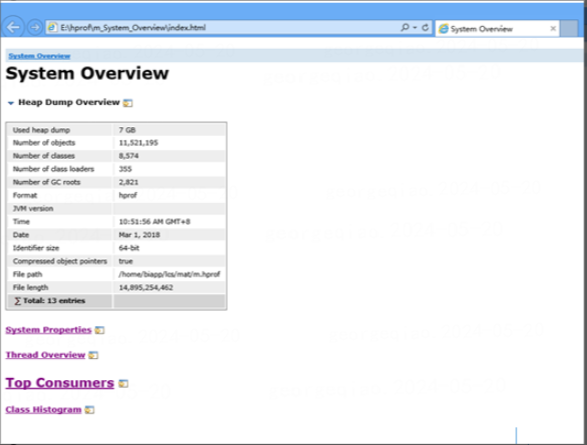
查看Class Histogram一项

step2、查找可疑的Metastore操作
从内存升高这个表象关联到可疑的Metastore命令,查看对应Metastore的审计日志,通过审计日志查看出现问题时间段的执行命令,主要查看执行的API次数和执行所涉及的库表信息,例如发生问题时间段未10:30~10:35,那么使用如下命令进行统计API调用次数
拿到10:30~10:35之间的日志 awk '$0 >= "2024-05-16T10:30:00" && $0 <= "2024-05-16T10:35:00"' hive-audit.log.2024-05-16 > hive-range.log 获取API调用次数 grep -v 'local RawStore' hive-range.log |awk '{print $8}'|sort|uniq -c

重点关注get_multi_table,get_partitions,get_partitions_ps_with_auth,drop等可能涉及大分区操作的API调用,通过审计日志找到对应提交的客户端IP和用户来定位上层业务异常任务,例如如下get_multi_table 如果高频调用因每次均会扫描该数据库下的所有表,即会引发FGC

step3、通过火焰图排查
火焰图使用方法:https://arthas.aliyun.com/en/doc/profiler.html#specify-execution-time

火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
根据上图可以看到,get_all_functions、get_database命令占用的内存最多,初步怀疑这个命令比较可疑。。到了这一步,就要开始第二阶段的排查了。使用平台提供的监控排查问题时间窗口所有get_all_functions命令的执行情况,如下图所示:

这个时间段发生了多次扫描get_all_functions的请求,因为是临时函数,每次均需要进行注册和拉取,对Hive Metastore造成很大的性能影响。

