

ORC的文件解析异常
问题背景
在开启了Hive表 ORC+SNAPPY后,生产问题收到如下异常
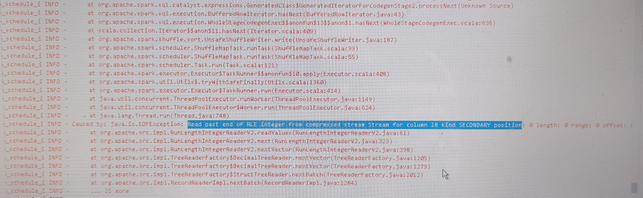
Caused by: java.io.EOFException: Read past end of RLE integer from compressed stream Stream for column 1 kind SECONDARY position: 0 length: 0 range: 0 offset: 0 limit: 0
初步原因定位
初步原因
在使用spark-sql跑批,通过create table xxx as select 语法下,select 查询部分中使用静态值作为默认值(0.00 as column_name)且不指定默认值的数据类型。在该使用场景下,因未显式指定数据类型,在写入的ORC文件中该字段的metadata信息缺失(写入成功),但读取的时候,只要查询的列含有该字段,将会无法解析该ORC文件,出现如问题背景中的报错。
issue
SPARK和Hive issue中均能找到对应的patch,但是打上Hive的patch补丁后,查询虽然不再报上述异常,返回值为NULL,但是结果不符合预期,不符合开启压缩前的结果,所以我们还是要从根本上解决此问题。
https://issues.apache.org/jira/browse/SPARK-26437
https://issues.apache.org/jira/browse/HIVE-13083
问题复现
在spark-sql下执如下特定语句可复现上述异常
create table testgg as select 0.00 as gg;select * from testgg;
Caused by: java.io.IOException: Error reading file: viewfs://bdphdp10/user/hive/warehouse/hadoop/testgg/part-00000-e7df51a1-98b9-4472-9899-3c132b97885b-c000 at org.apache.orc.impl.RecordReaderImpl.nextBatch(RecordReaderImpl.java:1291) at org.apache.spark.sql.execution.datasources.orc.OrcColumnarBatchReader.nextBatch(OrcColumnarBatchReader.java:227) at org.apache.spark.sql.execution.datasources.orc.OrcColumnarBatchReader.nextKeyValue(OrcColumnarBatchReader.java:109) at org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:39) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:101) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:181) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:101) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.scan_nextBatch_0$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:255) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:247) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$24.apply(RDD.scala:836) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$24.apply(RDD.scala:836) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324) at org.apache.spark.rdd.RDD.iterator(RDD.scala:288) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:121) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)Caused by: java.io.EOFException: Read past end of RLE integer from compressed stream Stream for column 1 kind SECONDARY position: 0 length: 0 range: 0 offset: 0 limit: 0 at org.apache.orc.impl.RunLengthIntegerReaderV2.readValues(RunLengthIntegerReaderV2.java:61) at org.apache.orc.impl.RunLengthIntegerReaderV2.next(RunLengthIntegerReaderV2.java:323) at org.apache.orc.impl.RunLengthIntegerReaderV2.nextVector(RunLengthIntegerReaderV2.java:398) at org.apache.orc.impl.TreeReaderFactory$DecimalTreeReader.nextVector(TreeReaderFactory.java:1205) at org.apache.orc.impl.TreeReaderFactory$DecimalTreeReader.nextVector(TreeReaderFactory.java:1279) at org.apache.orc.impl.TreeReaderFactory$StructTreeReader.nextBatch(TreeReaderFactory.java:2012) at org.apache.orc.impl.RecordReaderImpl.nextBatch(RecordReaderImpl.java:1284) ... 25 more
深入跟进
spark orc写入逻辑
Spark 依赖 hive-exec 中的ORC来写入数据,针对 0.00 数据,如果不指定类型,会将数据类型解析为 decimal(2,2)(Hive解析为double,所以没问题),在进行数据和数据类型判断时,由于数据精度问题,不能enforcePrecisionScale不能通过对于decimal类型的校验,在查询时候返回null
定位源代码
//校验失败
if (dec.precision() - dec.scale() <= maxPrecision - maxScale && dec.scale() <= maxScale) { return dec; }
//处理逻辑,返回null
BigDecimal bd = HiveDecimal.enforcePrecisionScale(dec.bigDecimalValue(), maxPrecision, maxScale);
if (bd == null) { return null; }
异常数据在hdfs中的表现
HDFS上orc数据展示,可以看出在写入异常的数据当中,orc的stripes数据中,column1的length为0,说明数据是没有写入的
Rows: 1Compression: SNAPPYCompression size: 262144Type: struct<gg:decimal(2,2)>Stripe Statistics: Stripe 1: Column 0: count: 0 hasNull: false Column 1: count: 0 hasNull: trueFile Statistics: Column 0: count: 0 hasNull: false Column 1: count: 0 hasNull: trueStripes: Stripe: offset: 3 data: 5 rows: 1 tail: 64 index: 35 Stream: column 0 section ROW_INDEX start: 3 length 11 Stream: column 1 section ROW_INDEX start: 14 length 24 Stream: column 1 section PRESENT start: 38 length 5 Stream: column 1 section DATA start: 43 length 0 Stream: column 1 section SECONDARY start: 43 length 0 Encoding column 0: DIRECT Encoding column 1: DIRECT_V2File length: 213 bytesPadding length: 0 bytesPadding ratio: 0%
在正确的写入下,orc的stripes数据中,column1的长度为4
Rows: 1Compression: SNAPPYCompression size: 262144Type: struct<gg:decimal(3,2)>Stripe Statistics: Stripe 1: Column 0: count: 0 hasNull: false Column 1: count: 1 hasNull: false min: 1 max: 1 sum: 1File Statistics: Column 0: count: 0 hasNull: false Column 1: count: 1 hasNull: false min: 1 max: 1 sum: 1Stripes: Stripe: offset: 3 data: 10 rows: 1 tail: 58 index: 40 Stream: column 0 section ROW_INDEX start: 3 length 11 Stream: column 1 section ROW_INDEX start: 14 length 29 Stream: column 1 section DATA start: 43 length 4 Stream: column 1 section SECONDARY start: 47 length 6 Encoding column 0: DIRECT Encoding column 1: DIRECT_V2File length: 229 bytesPadding length: 0 bytesPadding ratio: 0%
方案梳理
1、spark依赖的hive直接升级2.3
2、升级ORC 版本至1.5以上
-- 以上两种风险较大,需要大量验证和长时间生产灰度,耗时较长,暂不考虑
3、spark pre hook 增加using orc ,using orc,会使用spark的逻辑去读写文件
-- 此方案会强制指定orc的写入逻辑为spark orc,相当于一个替换了写入方式且对SCT有侵入性暂不考虑
4、spark 对于0.00数据处理逻辑问题修复,将其默认解析为decimal(3,2)
-- 此方案比较可靠,从源头上解决此问题,对Hive 也没有任何侵入性,在spark 对于 0.00 默认数据类型转换的时候进行特殊处理
5、hive orc writer 对于 decimal(2,2)0.00 数据类型进行兼容处理
-- 起初使用下面代码可解决问题,但是因为spark而更改Hive逻辑会放大此问题风险,下面代码段可参考
// Minor optimization, avoiding creating new objects.
if (dec.precision() - dec.scale() <= maxPrecision - maxScale && dec.scale() <= maxScale)
{ return dec;}
if (dec.bigDecimalValue().compareTo(new BigDecimal(0)) ==0 && dec.precision() - dec.scale() > maxPrecision - maxScale && dec.scale() <= maxScale)
{ return dec;}
BigDecimal bd = HiveDecimal.enforcePrecisionScale(dec.bigDecimalValue(), maxPrecision, maxScale);
if (bd == null)
{ return null;}
最终解决方案
根据上面的方案梳理,我们最终确认通过方案4(spark 对于0.00数据处理逻辑问题修复,将其默认解析为decimal(3,2))来解决此问题。
首先我们来看一下spark为什么会解析错误,在spark中使用 Literals 标识字面常量,将指定的字面值转换成Spark能够理解的值,Literals属于一种表达式。
1.如sql:create table test_gg as select 0.000 as scores;
在此语句中,spark 将0.000解析为 Literals表达式,转换成decimal(3,3)类型,在写入hive时使用 HiveFileFormat 进行转换,将outputData转换为0,其precision为1,scale为0。而其typeInfo仍为decimal(3,3), 在写入hive orc数据时会校验该精度信息,因不符合校验规则,导致写入数据为NULL。
private val fieldOIs = standardOI.getAllStructFieldRefs.asScala.map(_.getFieldObjectInspector).toArray
private val dataTypes = dataSchema.map(_.dataType).toArray
private val wrappers = fieldOIs.zip(dataTypes).map { case(f, dt) => wrapperFor(f, dt) }
private val outputData = new Array[Any](fieldOIs.length)
在HiveFileFormat中获取写入的数据信息 outputData,转换后在write 的时候丢失了精度
private val fieldOIs = standardOI.getAllStructFieldRefs.asScala.map(_.getFieldObjectInspector).toArray
private val dataTypes = dataSchema.map(_.dataType).toArray
private val wrappers = fieldOIs.zip(dataTypes).map { case(f, dt) => wrapperFor(f, dt) }
private val outputData = new Array[Any](fieldOIs.length)
override def write(row: InternalRow): Unit = {
var i = 0
while (i < fieldOIs.length) {
outputData(i) = if (row.isNullAt(i)) null else wrappers(i)(row.get(i, dataTypes(i)))
i += 1
}
hiveWriter.write(serializer.serialize(outputData, standardOI)) // 丢失了精度
}
可以看出经过转换后出现了精度丢失的问题,在最终写入数据的时候经过hive-exec中HiveDecimal中enforcePrecisionScale校验,校验不通过返回为NULL
1. public static BigDecimal enforcePrecisionScale(BigDecimal bd, int maxPrecision, int maxScale) {
2.if (bd == null) {
3. return null;
4.} else {
5. bd = trim(bd);
6. if (bd.scale() > maxScale) {
7. bd = bd.setScale(maxScale, RoundingMode.HALF_UP);
8. }
9.
10. int maxIntDigits = maxPrecision - maxScale;
11. int intDigits = bd.precision() - bd.scale();
12. return intDigits > maxIntDigits ? null : bd;//此处校验不能通过
13.}
代码修复
在Literal中对显式字面常量,默认增加1个有效数字保留位。比如0.00 将其默认转换为decimal(3,2)。同时兼容38位数据的计算,具体代码请见PR:https://github.com/apache/spark/pull/37726

 浙公网安备 33010602011771号
浙公网安备 33010602011771号