

Hive 开启压缩后 shuffle 阶段 偶发OOM问题
一、 问题现象
查看yarn 日志确认是在 shuffle 阶段 发生了异常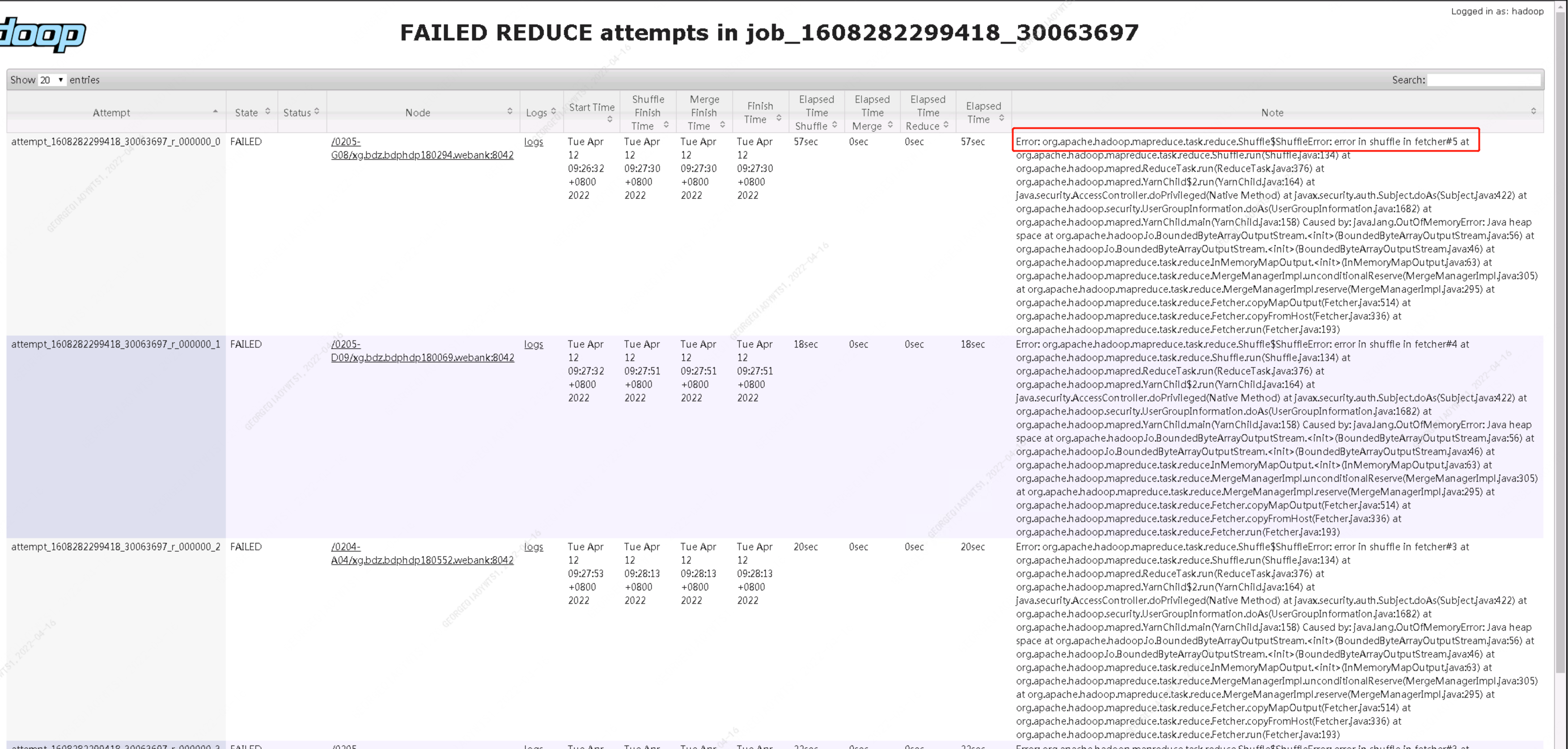
二、 初步分析
MR 流程总览
从异常栈来看,发生了shuffle的OOM,在shuffle阶段,会将map的output数据给取下来,然后根据相关参数值确认昂前shuffle可使用内存,决定是放进内存中,还是存储到磁盘里面进行操作。mapreduce.reduce.shuffle.memory.limit.percent这个参数默认值是0.25,代表单个shuffle能够消耗的内存占reduce所有内存的比例。所以解决问题的方法可以适当地将这个参数进行调小操作,那么单个shuffle能够消耗的内存就没办法满足将数据进行处理,就会使用磁盘来慢慢操作;那么应该如何配置和列参数参来避免此问题呢。
三、 深入分析
需要结合Hadoop 2.7.2的源代码来对整个失败过程进行简要分析。
Fetcher线程
从异常栈可以看出,是在Fetcher.run方法执行时出现的错误,在Shuffle.run方法中,会启动一定数量的Fetcher线程(数量由参数mapreduce.reduce.shuffle.parallelcopies决定,Fetcher线程用来从map端copy数据到Reducer端本地。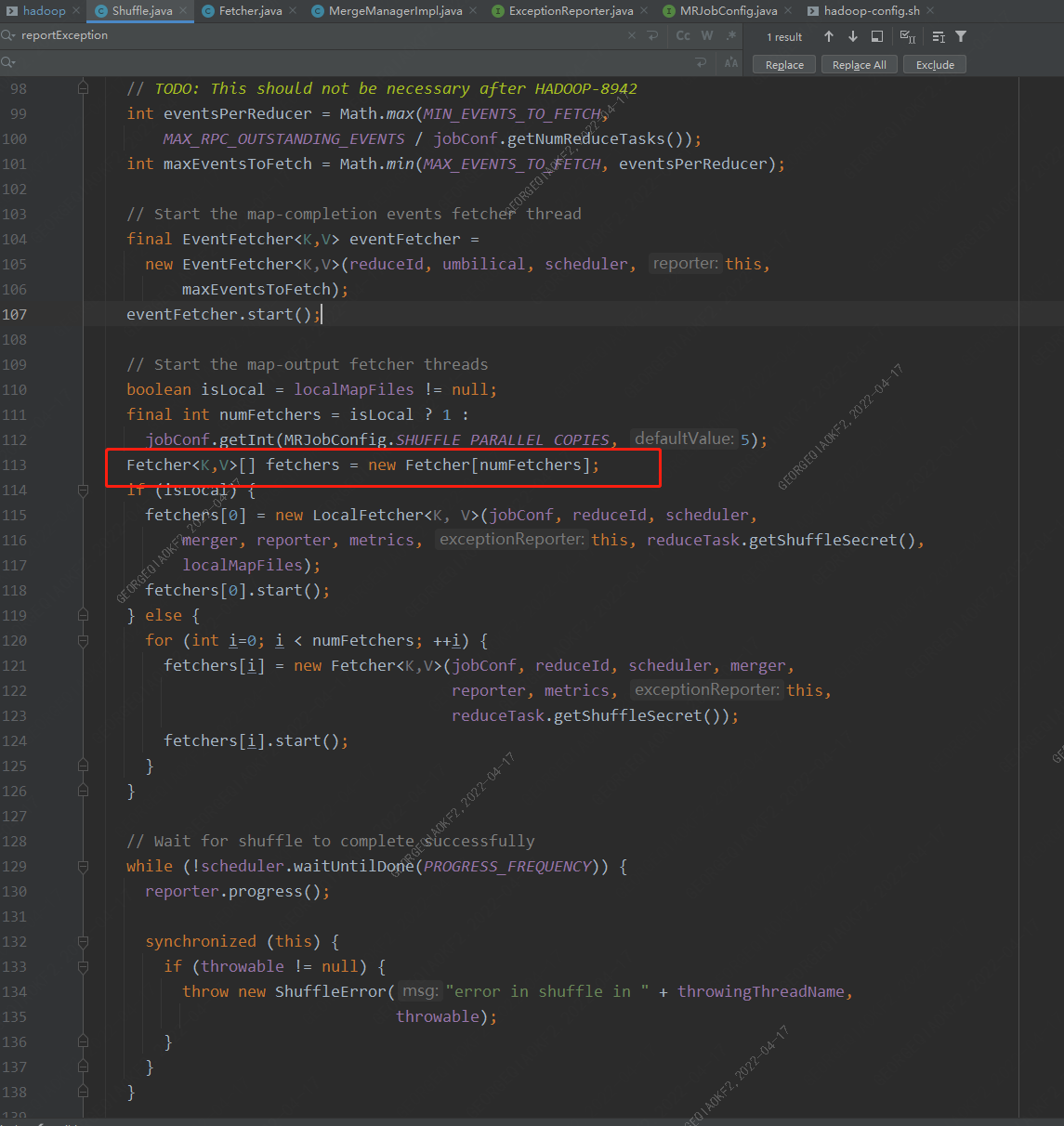
当任意一个Fetcher发生异常时,其会上报异常至主进程,停掉整个Reducer。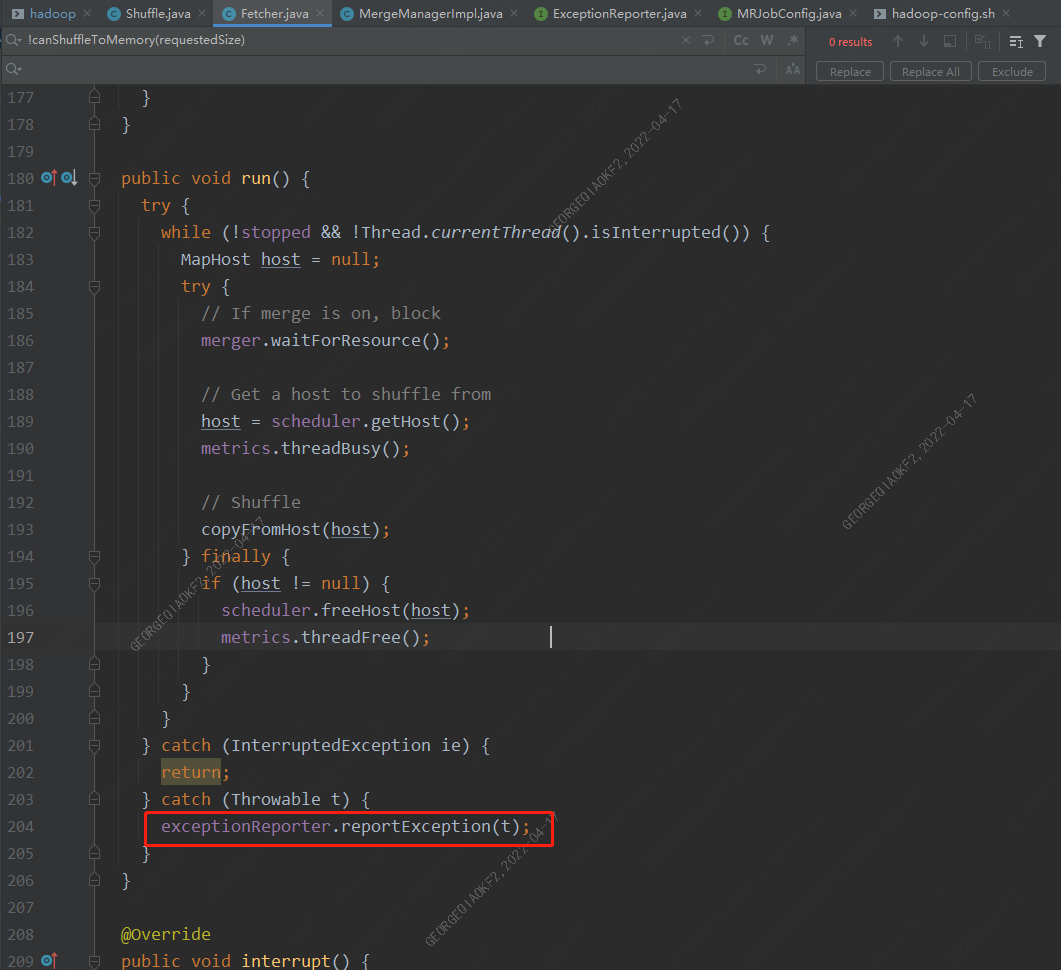

reserve的具体实现
在异常堆栈可以看出,Fetcher中调用copyFromHost方法,紧接着调用Fehcher的copyMapOutput方法,重点在这里,merger指向了MergeManagerImpl对象,调用其reserve函数,而这个函数中定义了shuffle的处理方式,是将output塞入内存(InMemoryMapOutput)还是放在磁盘上慢慢做(OnDiskMapOutput)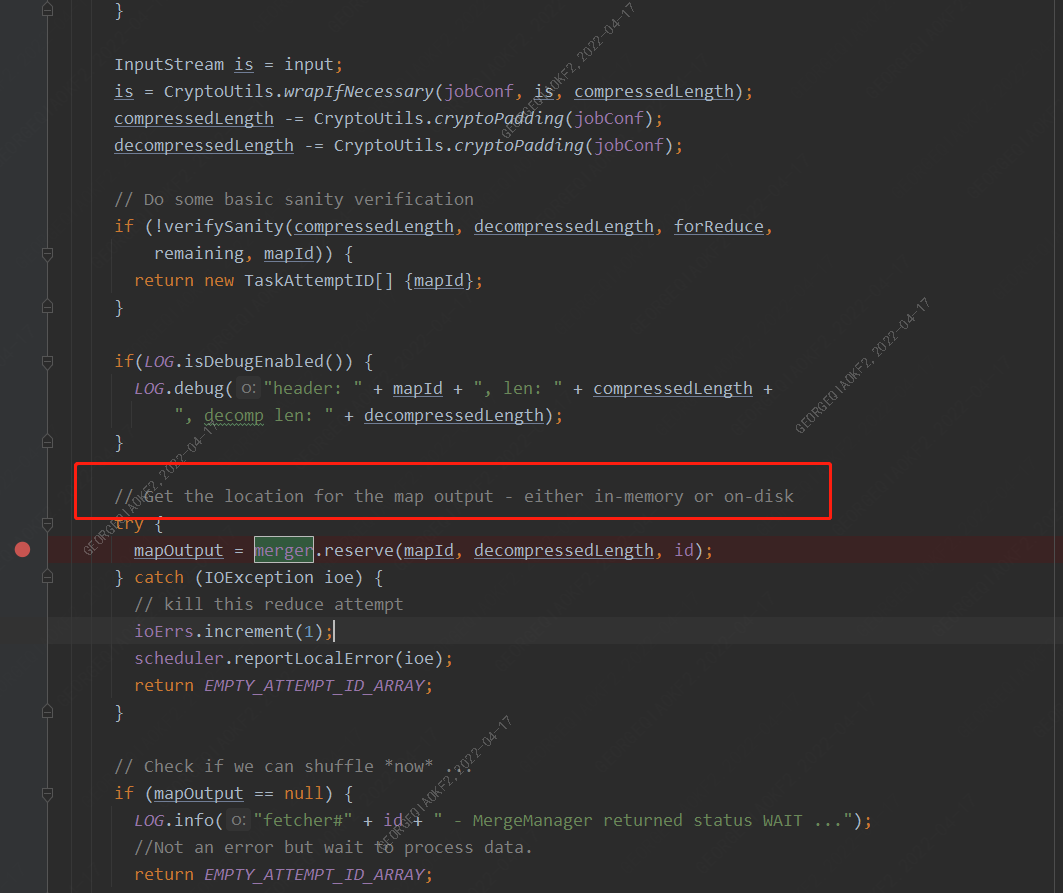
从我们这边的出错信息,显然可以看到任务选择了InMemoryMapOutput,既然认为可以在内存中进行shuffle,那么还会发生OOM 呢?
shuffle中可用内存的设置
shuffle在初始化MergeManager的时候设置了reduce总共可以使用的内存,MRJobConfig.REDUCE_MEMORY_TOTAL_BYTES(mapreduce.reduce.memory.totalbytes)这个参数我们并没有设置,因此使用的Runtime.getRuntime.maxMemory()*maxInMemCopyUse
MRJobConfig.SHUFFLE_INPUT_BUFFER_PERCENT(mapreduce.reduce.shuffle.input.buffer.percent) 参数使用的是0.70,也就是最大内存的70%用于做Shuffle/Merge,比如当前环境Reducer端内存设置成4G,那么就会有2.8G内存。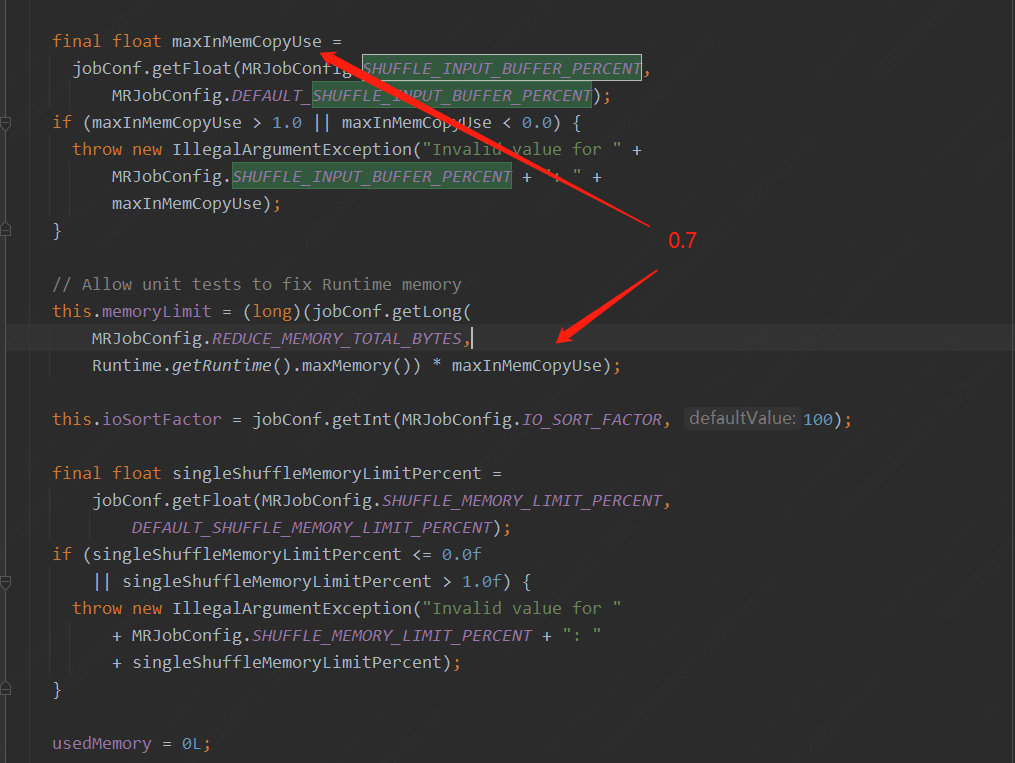
而单个shuffle 的最大内存使用量还需要,在乘以一个系数 mapreduce.reduce.shuffle.memory.limit.percent (默认0.25),那么也就是700M
获取 MapOutput
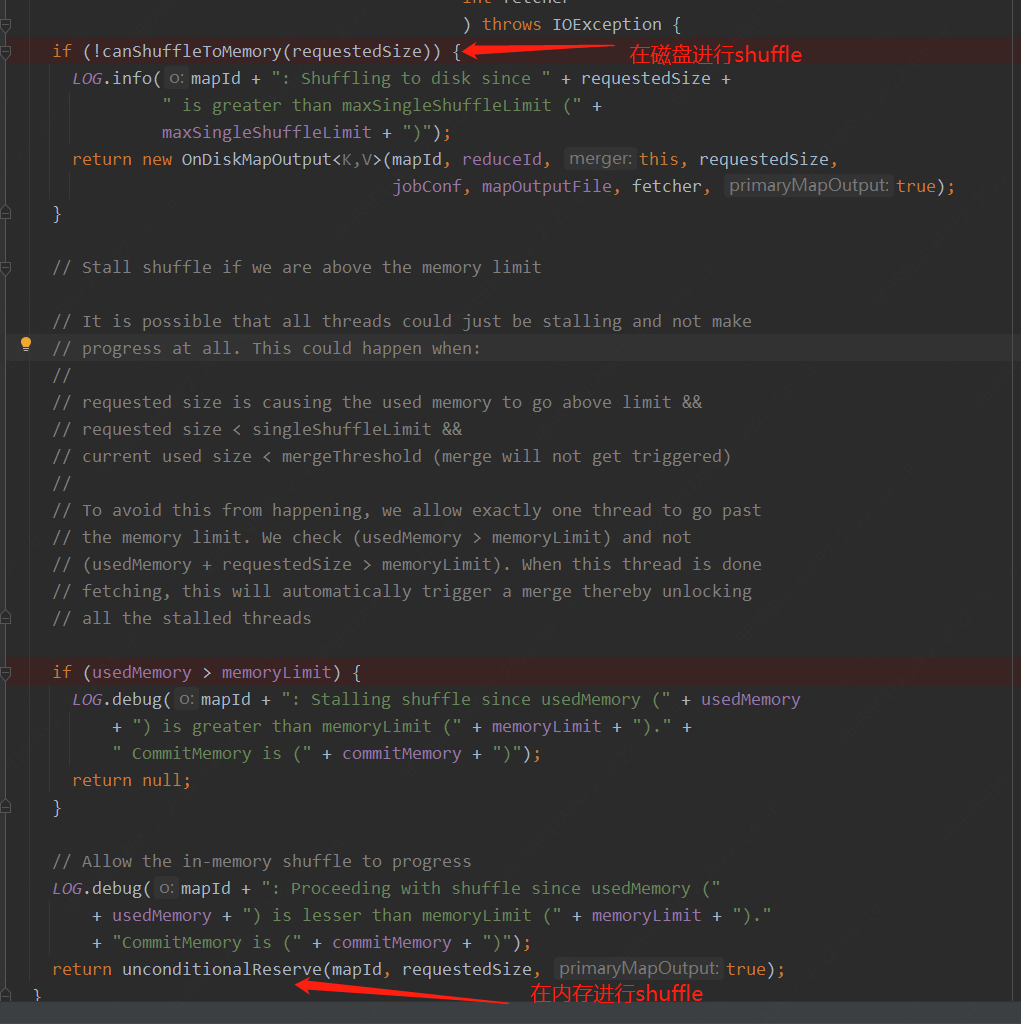
那么reserve方法是如何决定是启动OnDiskMapOutput还是InMemoryMapOutput类,其中有一个canShuffleToMemory方法,确认请求内存数量是否小于单个shuffle设置的内存限制。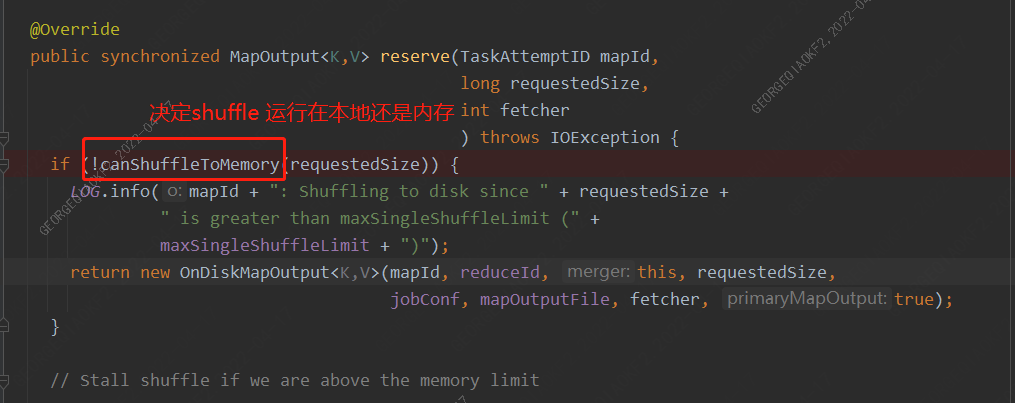
InMemory会在初始化时接收一个size参数,用于初始化其BoundedByteArrayOutputStream,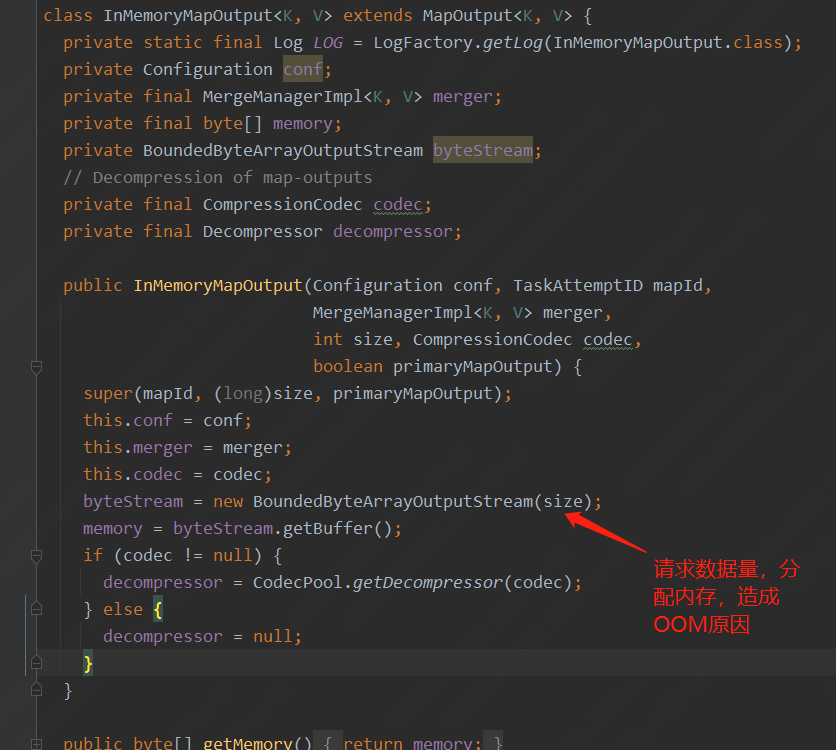
Fetcher线程取到数据后,进行mapOutput的commit操作,说明信息读取结束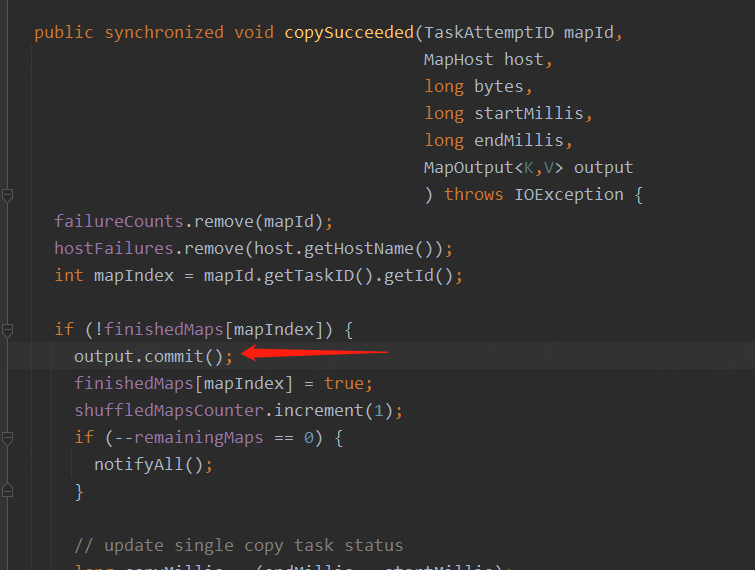
commit后这个mapOutput可以和其他的mapOutput进行合并。这里需要注意的是内存空间分给mapoutput后并不能启动merge操作,只有当commit完成后才可以进行Mapouput的合并并释放内存。
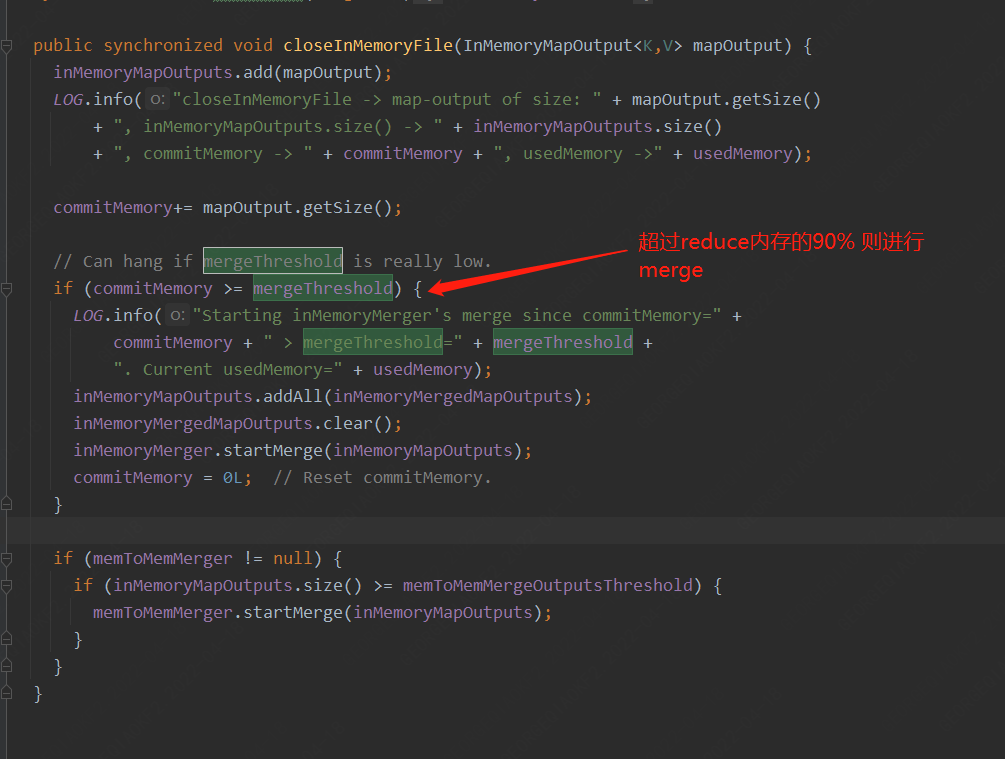
usedMemory: 已经分配的内存总量。
commitMemory: 已经提交的内存总量。
有关的几个重要参数事先说明:mapreduce.reduce.shuffle.input.buffer.percent默认0.7 (2.8 G) shuffile在reduce内存中的数据最多使用内存量为:0.7 × maxHeap of reduce task,缓存的数据量超过了这个值,便开始将缓存数据写入磁盘。mapreduce.reduce.shuffle.memory.limit.percent默认0.25 (700M) 每个fetch取到的输出的大小能够占的内存比的大小,低于此值可以输出到内存,否则输出到磁盘。默认是0.25。mapreduce.reduce.shuffle.merge.percent默认0.66 merge的百分比,shuffle的数据量到达shuffle总内存的多少百分比后开始做merge操作。mapreduce.reduce.shuffle.parallelcopies默认 5 Fetcher 数量
基于以上逻辑在如下两种情况可能出现OOM(以下说明都是按照hadoop的默认配置下):
-
如果前4个Fetcher已经使用了全部的shuffle可分配内存的99%(4G 0.7 0.25 = 700M ,700 * 4 ≈ 2.8G),并且还未commit(copysuccess 之后才能 commit ),第5个Fetcher取的数据为699M,因为小于700M,这时会为第5个fetcher分配25%的内存。总内存使用量达到124%,超出shuffle限制。
-
如果前4个fetcher已经使用shuffle内存的65%,并已经commit,由于未达到设定值,这时merge不会启动(commitmemory > 0.66 才会进行merge),第5个Fetcher取的数据为699M,因为小于700M,这时会为第5个fetcher分配25%的内存。总内存使用量达到90%,超出shuffle限制,此时如果reduce在做消耗内存的操作,那么会发生OOM。
四、解决方案
将shuffle内存比例调整为0.6,单个shuffle最大比例调整为0.18,merge比例保持不变 0.66
调整后参数如下:mapreduce.reduce.shuffle.parallelcopies=5mapreduce.reduce.shuffle.input.buffer.percent=0.6(2.4G)mapreduce.reduce.shuffle.memory.limit.percent=0.18(0.432G)mapreduce.reduce.shuffle.merge.percent=0.66
这样在shuffle内存分配到接近100%时,最多可以分配15%的shuffle内存,总Shuffle内存不超过0.6 + 0.6 * 0.18 = 0.7,虽然超过了我们的60%,但是对整个reduce JVM而言,70%不会OOM,而超过0.66后会进行merge释放内存。

