


Hive开启压缩后 MapJoin 偶发OOM问题
一、 问题现象
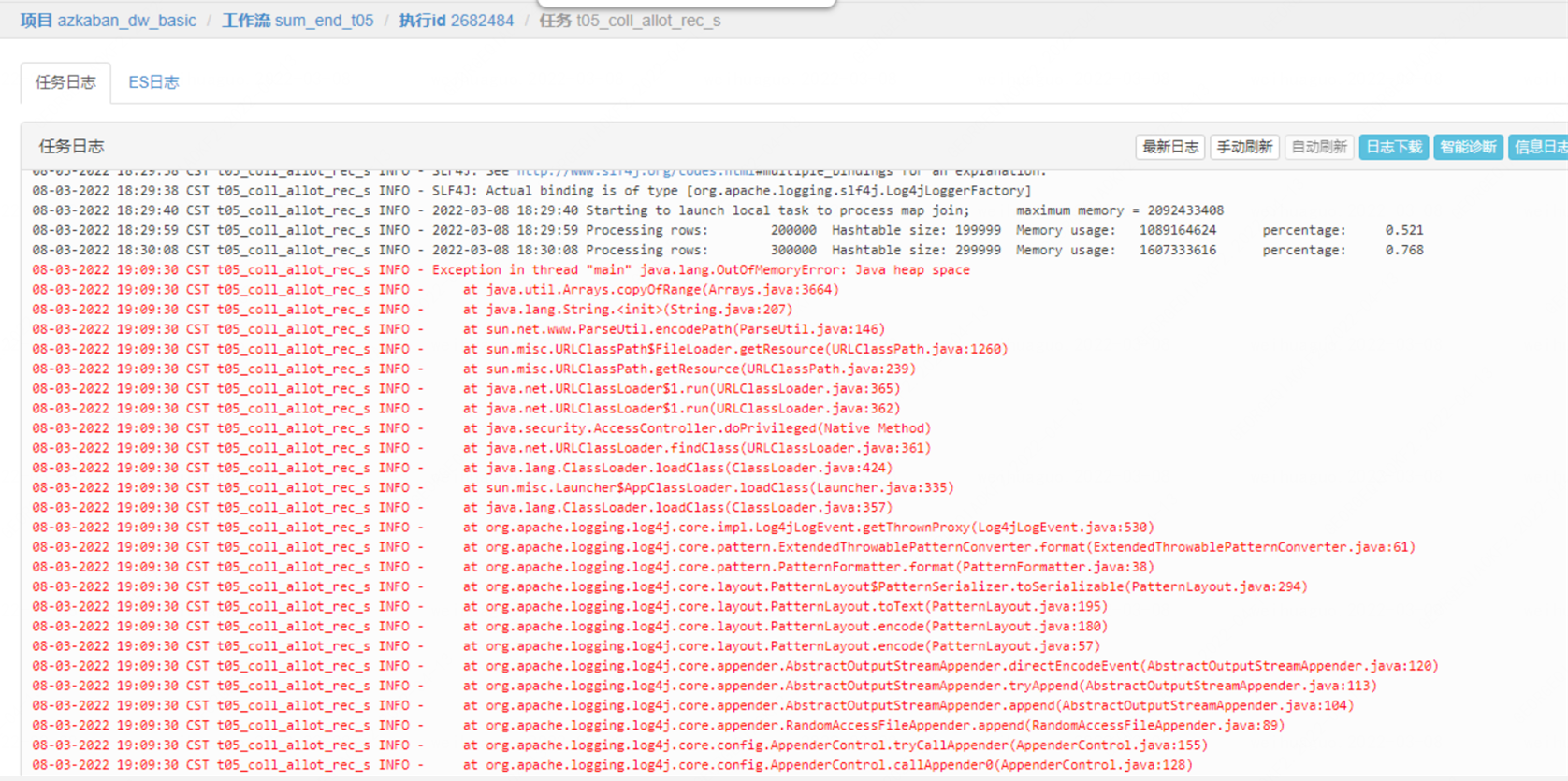
生产环境开启默认压缩后,Hive任务在触发MapJoin优化时会偶发OOM,如下图
二、 初步分析
从报错日志上面可以明显看出,maplocaltask 总共的分配内存2092433408
处理行数:200000 哈希表大小:199999 内存使用量:1089164624 比例:0.521
处理行数:300000 哈希表大小:299999 内存使用量:1607333616 速率:0.768
在 300000 行时,哈希表的大小已经暂用了 76.8% 的堆,MapJoin 默认是每10W行数据进行一次内存检测,那么按照这种趋势在下一次检测前肯定会撑爆maplocaltask的堆,导致OOM;但是比较奇怪的是,hive 在执行计划优化的时候会检测当前表数据的大小,只有满足设定的堆大小才会触发本地任务,所以说就算把数据全部方案哈希表也是完全够用的,如果只是想避免这个问题也很简单,通过直接设置set hive.auto.convert.join = false 关闭MapJoin,将任务放在hadoop运行;但是mapjoin作为一种hive任务的优化手段,可以大大降低任务的运行时间,如果关闭此配置,那么所有涉及mapjoin任务的运行时效都将得不到保障,所以我们只能迎难而上从根本上解决这个问题。
三、 MapJoin原理分析
1. common join的问题
首先我们来看看Hive 中的Join是如何运行,在任务启动之初,Hive 的join可以统称为Common Join,任务涉及 Map 阶段和 Reduce 阶段。Mapper 从连接表中读取数据并将连接的 key 和连接的 value 键值对输出到中间文件中。Hadoop 在所谓的 shuffle 阶段对这些键值对进行排序和合并。Reducer 将排序结果作为输入,并进行实Join。Shuffle 阶段代价非常昂贵,因为它需要排序和合并。减少 Shuffle 和 Reduce 阶段的代价可以提高任务性能。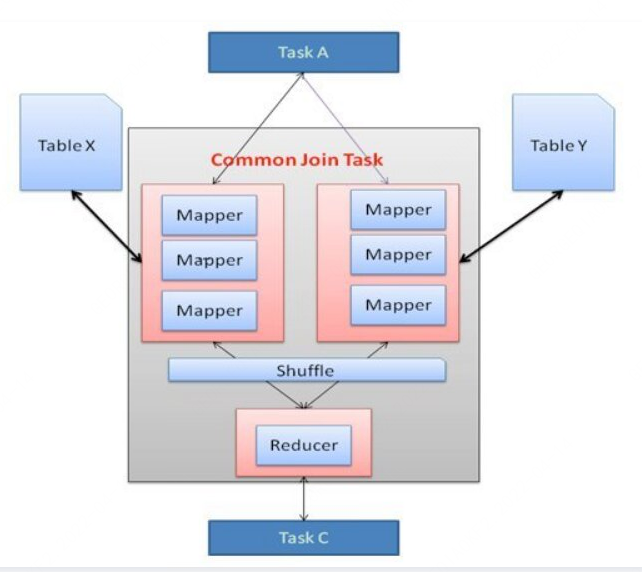
2. map join的产生
Map Join 的目的是减少 Shuffle 和 Reducer 阶段的代价,并仅在 Map 阶段进行 Join。通过这样做,当其中一个连接表足够小可以装进内存时,所有 Mapper 都可以将数据保存在内存中并完成 Join。因此,所有 Join 操作都可以在 Mapper 阶段完成。但是,这种类型的 Map Join 存在一些扩展问题。当成千上万个 Mapper 同时从 HDFS 将小的连接表读入内存时,连接表很容易成为性能瓶颈,导致 Mapper 在读取操作期间超时。
3. 使用分布式缓存
Hive-1641 解决了这个扩展问题。优化的基本思想是在原始 Join 的 MapReduce 任务之前创建一个新的 MapReduce 本地任务。这个新任务是将小表数据从 HDFS 上读取到内存中的哈希表中。读完后,将内存中的哈希表序列化为哈希表文件。在下一阶段,当 MapReduce 任务启动时,会将这个哈希表文件上传到 Hadoop 分布式缓存中,该缓存会将这些文件发送到每个 Mapper 的本地磁盘上。因此,所有 Mapper 都可以将此持久化的哈希表文件加载回内存,并像之前一样进行 Join。优化的 Map Join 的执行流程如下图所示。优化后,小表只需要读取一次。此外,如果多个 Mapper 在同一台机器上运行,则分布式缓存只需将哈希表文件的一个副本发送到这台机器上。
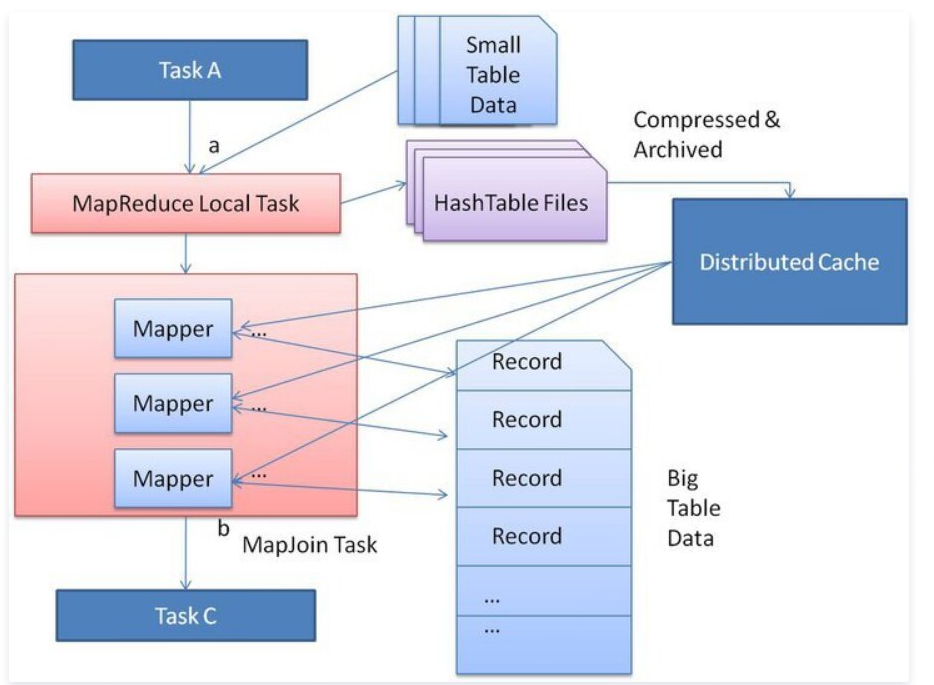
对于 Map Join,查询处理器应该知道哪个输入表是大表。其他输入表在执行阶段被识别为小表,并将这些表保存在内存中。然而,查询处理器在编译时不知道输入文件大小,因为一些表可能是从子查询生成的中间表。因此查询处理器只能在执行期间计算出输入文件的大小。
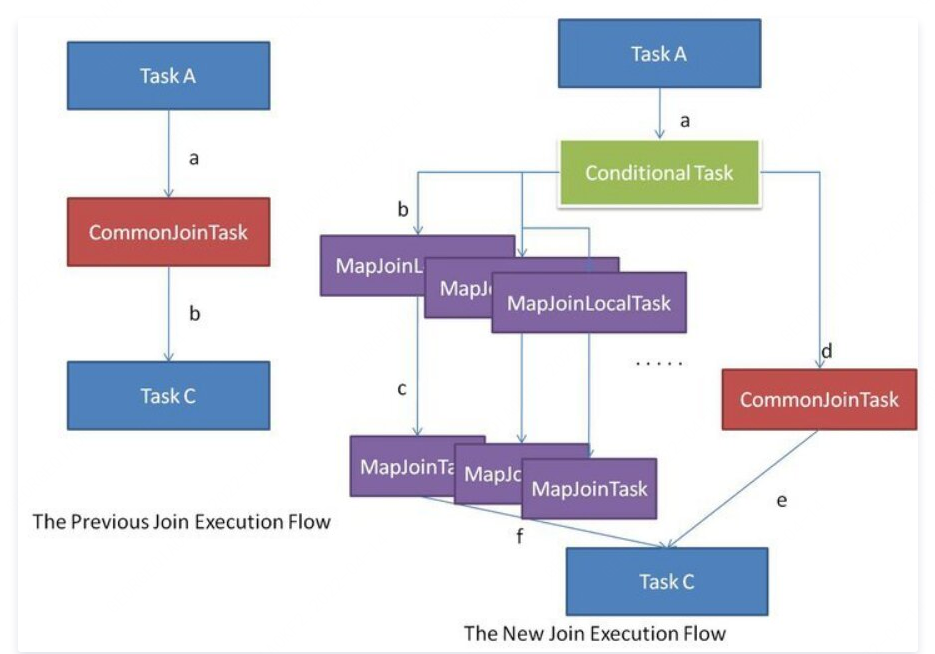
如上图所示,左侧流程显示了先前的 Common Join 执行流程,这非常简单。另一方面,右侧流程是新的 Common Join 执行流程。在编译期间,查询处理器生成一个包含任务列表的 Conditional Task。在执行期间运行其中一个任务。首先,应将原始的 Common Join 任务放入任务列表中。然后,查询处理器通过假设每个输入表可能是大表来生成一系列的 Map Join 任务。
例如,select * from src1 x join src2 y on x.key=y.key因为表 src2 和 src1 都可以是大表,所以处理器生成两个 Map Join 任务,其中一个假设 src1 是大表,另一个假设 src2 是大表。
在执行阶段,Conditional Task 知道每个输入表的确切文件大小,即使该表是中间表。如果所有表都太大而无法转换为 Map Join,那么只能像以前一样运行 Common Join 任务。如果其中一个表很大而其他表足够小可以运行 Map Join,则将 Conditional Task 选择相应 Map Join 本地任务来运行。通过这种机制,可以自动和动态地将 Common Join 转换为 Map Join。
至此通过原理,对于开始提到的MapJoin中存在的OOM问题,我们可以大概猜测,系统是将某一张表识别为小表而触发了mapjoin后,在本地任务中将小表放入哈希表的过程中撑爆了内存,如果小表的总大小大于25MB,Conditional Task 会选择原始 Common Join 来运行,(可使用 set hive.smalltable.filesize 来修改),那么为什么大于25M的表hive也触发了mapjoin呢,从日志是看不出什么了,下面我们来从源码层面来分析。
四、 定位真相
我们以如下三张表的join为例来跟踪源码,分别为一张orc的小表和两张txt类型的大表
3366670 2022-04-12 20:51 viewfs://bdphdp10/user/hive/warehouse/hadoop/mapjoin_join/data.txt5748 2022-04-12 20:52 viewfs://bdphdp10/user/hive/warehouse/hadoop/mapjoin_orc/000000_03366670 2022-04-12 20:51 viewfs://bdphdp10/user/hive/warehouse/hadoop/mapjoin_txt/data.txtset hive.auto.convert.join = true;set hive.auto.convert.join.noconditionaltask=true;set hive.mapjoin.smalltable.filesize = 2000000;set hive.auto.convert.join.noconditionaltask.size=2000000;select count(tmp1.cate)from mapjoin_orc tmp1inner join mapjoin_join tmp2 on tmp1.cate=tmp2.cateinner join mapjoin_15_txt tmp3 on tmp3.cate=tmp2.categroup by tmp1.cate,tmp2.cate,tmp3.cate;
我们知道MapJoin的优化是发生在将逻辑执行计划转换为物理执行计划后,对于物理执行计划的优化阶段发生的,如下图:
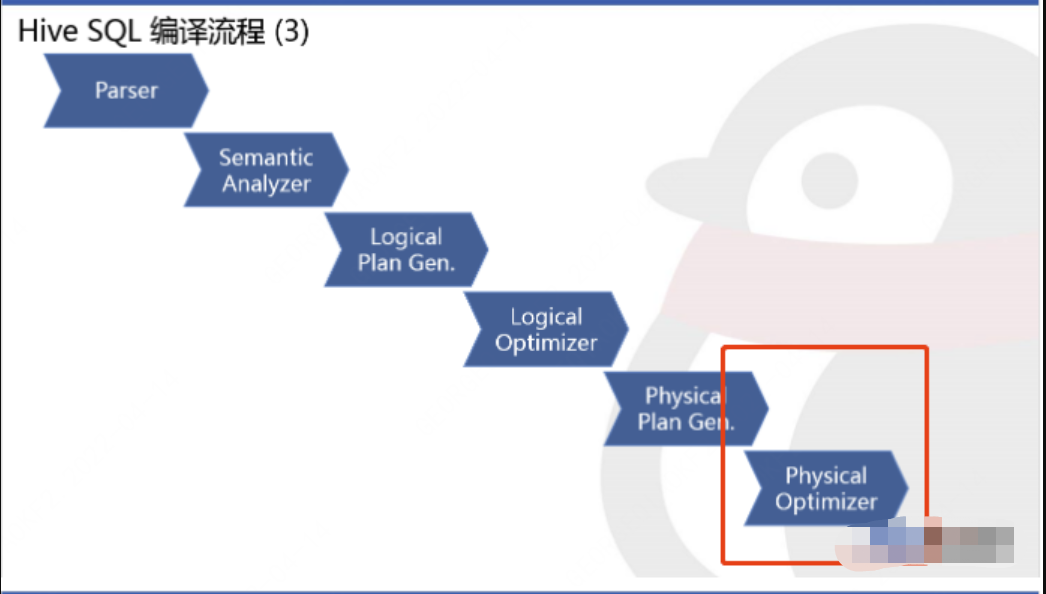
所以我们直接从物理执行计划优化切入,其中关键点在于两个逻辑:
1. 针对两个表的join,对于小表大小逻辑判断如下代码:
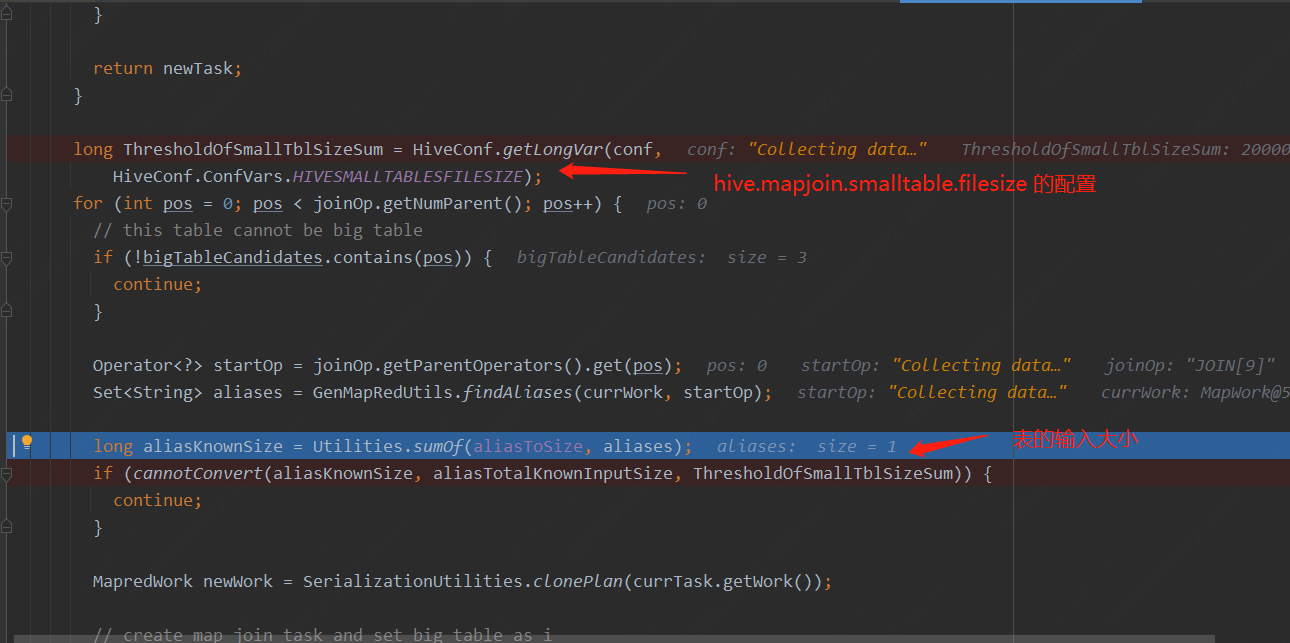
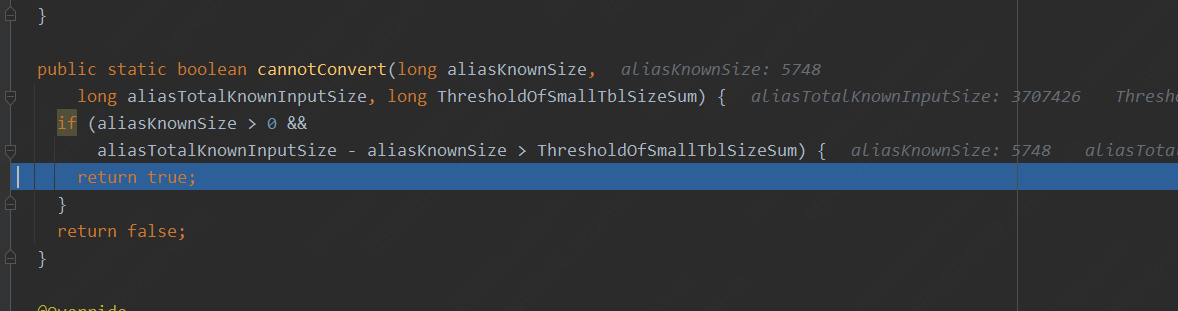
2. 针对多表的join,通常会对于小表大小逻辑判断如下代码:
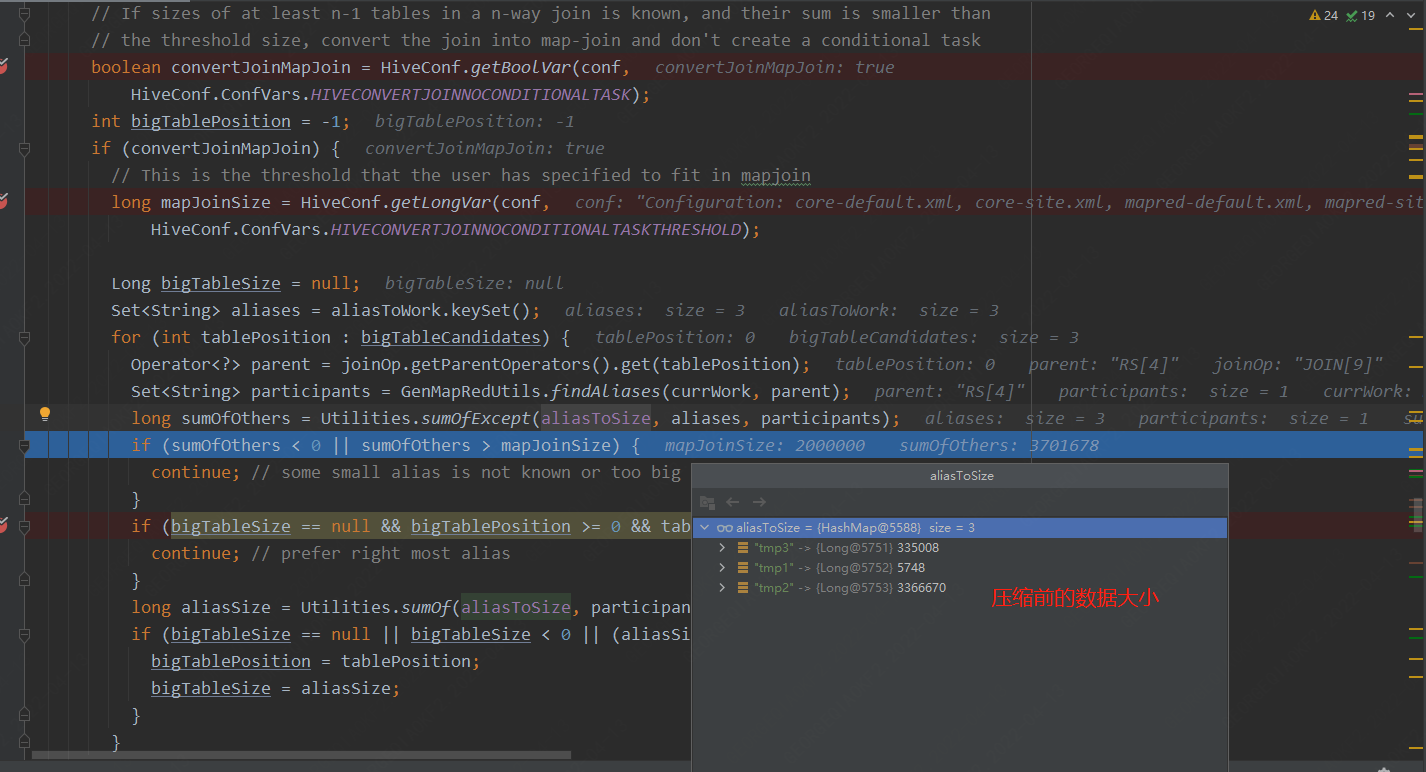
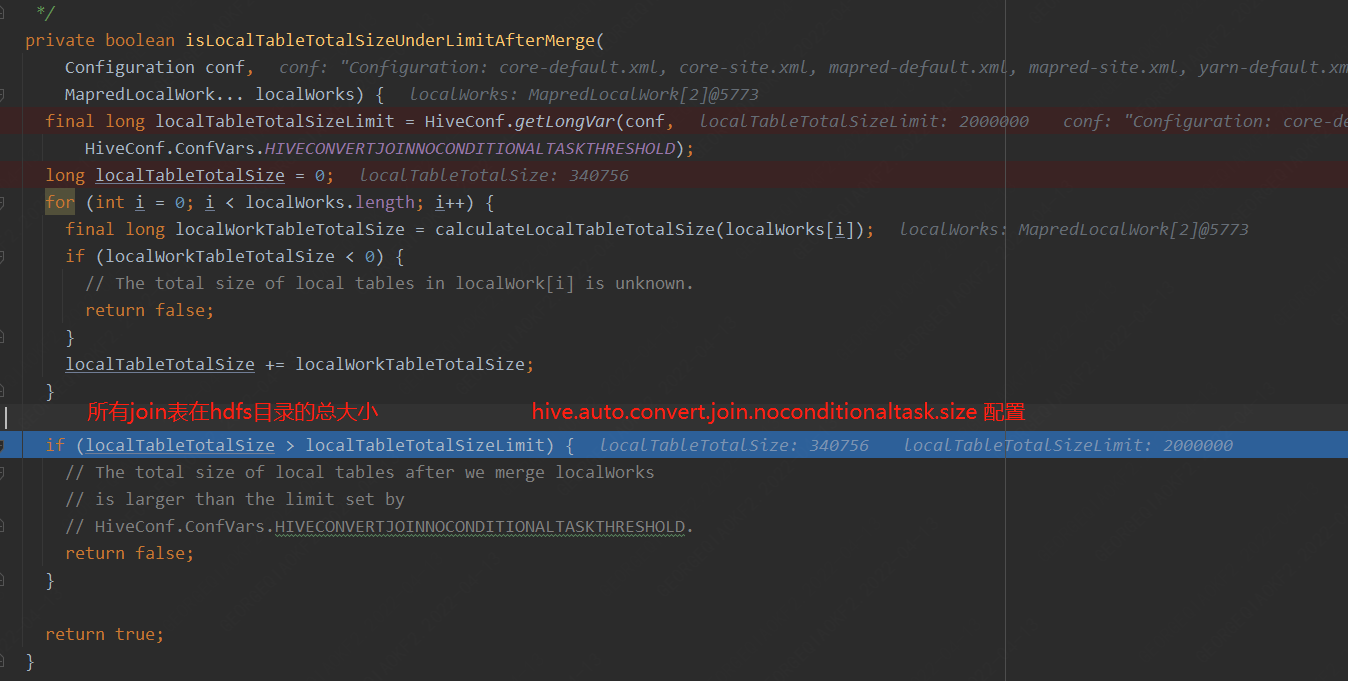
loacltask任务
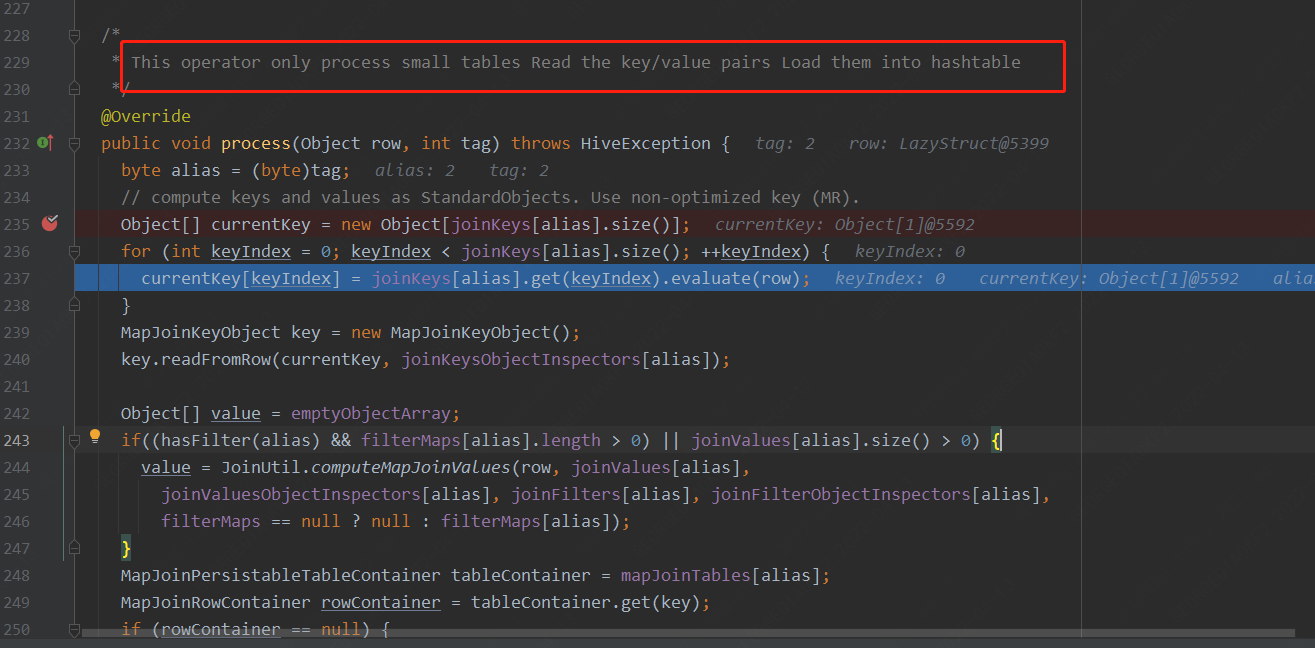
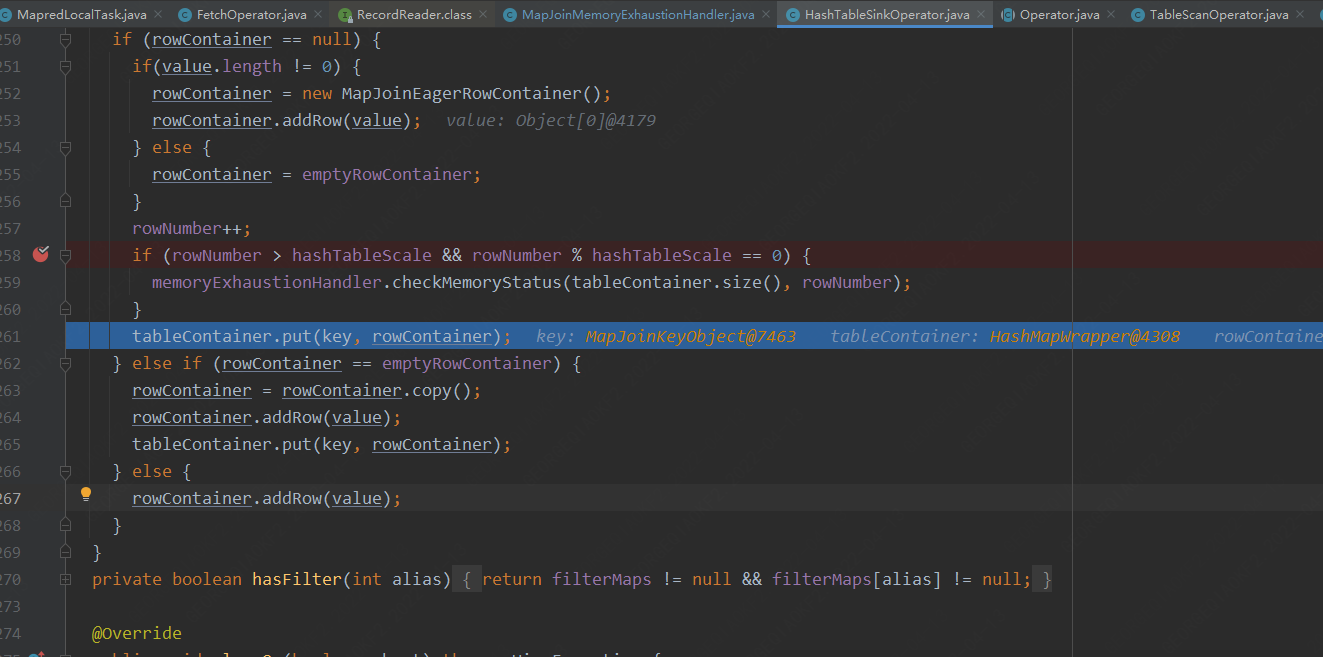
此处为读取每行数据,将数据放入哈希表的逻辑
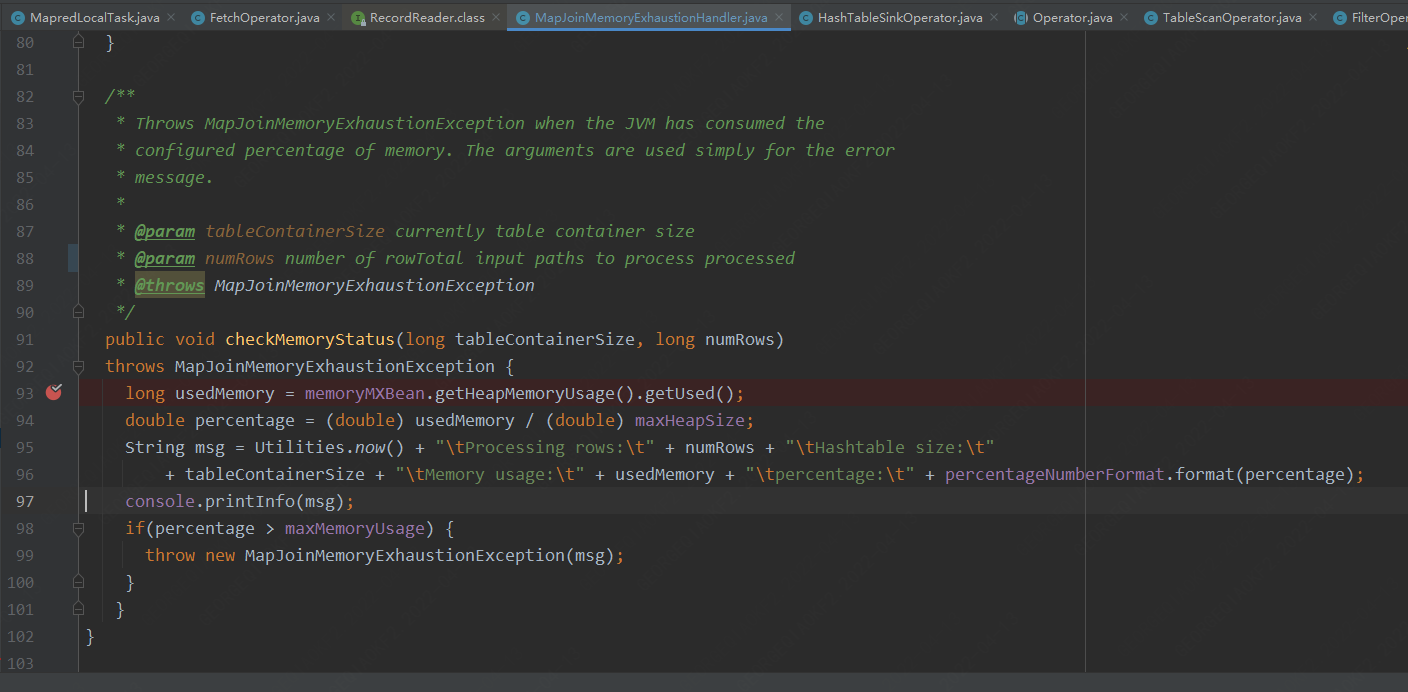
此处为每处理10W行数据,检测一下当前堆的使用情况。
可以看出,不管是两表join ,还是多表join,对于表大小逻辑的检测都是直接读取hdfs上存储的数据的大小,当表被压缩存储时,表大小可能不会太大,但是当它被解压缩时,它可以增长 10 倍或更多,在此之上表示哈希表中的数据会占用更多空间. 因此,表在hdfs上压缩后的存储空间可能小于25MB( hive.mapjoin.smalltable.filesize 设置的值),但它的解压缩后,数据可能远远超过25吗,这就是 hive 尝试将表加载到内存中的原因,最终导致OutOfMemoryError 异常. 这是MapJoin在设计时候考虑不周到的地方(对于压缩表没有检查表是否是压缩表以及表的潜在大小可以是多少)。
五、 解决方案
明白了问题根源,那么解决问题的核心主要是围绕表大小检测,在针对压缩表的情况下如何检测到表的真正大小。
比较可惜的是目前Hadoop压缩库snappy并没有提供在未解压的情况下针对固定表或者目录计算解压后大小的API,但是snappy的JAVA-API库(xerial)进行身份信息解码提供了一个uncompressedLength的方法,用于在解压的时候提前分配内存空间,这样针对压缩表大小预估的代码可以这样改
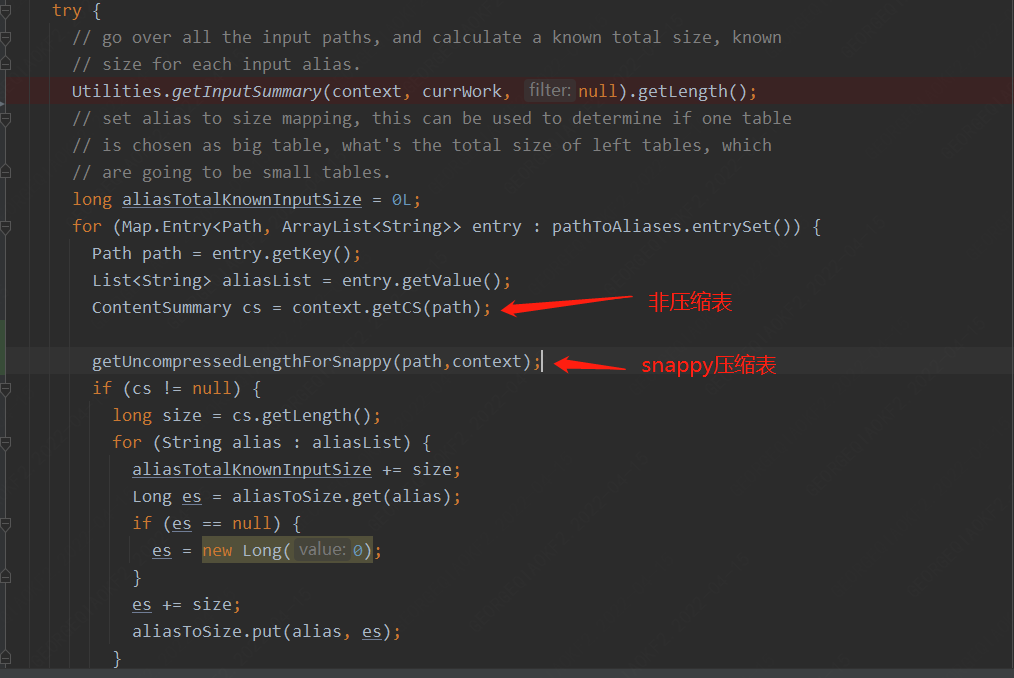
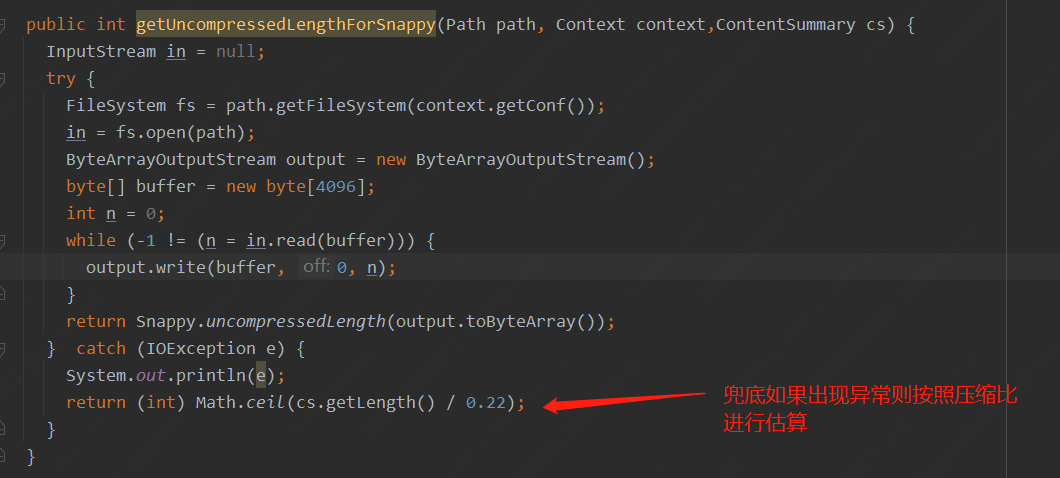
六、 总结虽然对于此类问题我们可以通过调整参数,例如增大mapjoin内存,调整内存占用比,甚至关闭mapjoin来解决此问题,但是治标不治本,单个任务调整对用户来说增加了开发成本,整体集群调整甚至可能对集群性能造成影响,我们需要从原理出发,从根本上解决此问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通