CTF-BugKu-加密
2020.09.12
恕我直言,上午做WeChall那个做自闭了,下午复习一下之前做过的。
做题
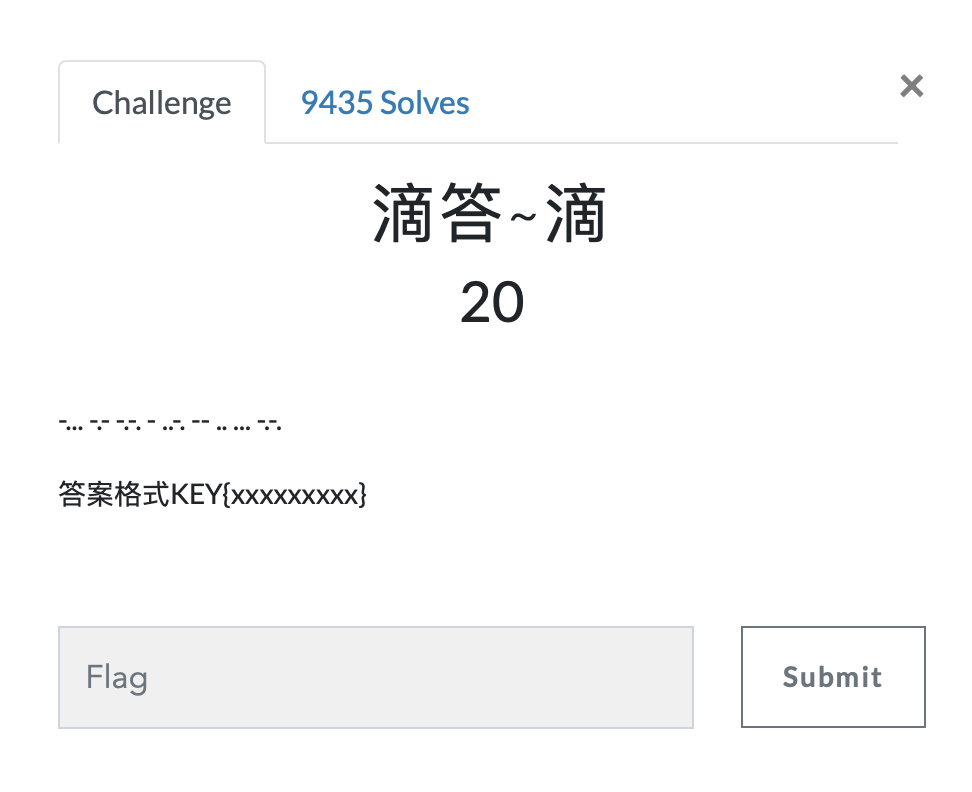
第一题 滴答~滴
https://ctf.bugku.com/challenges#滴答~滴
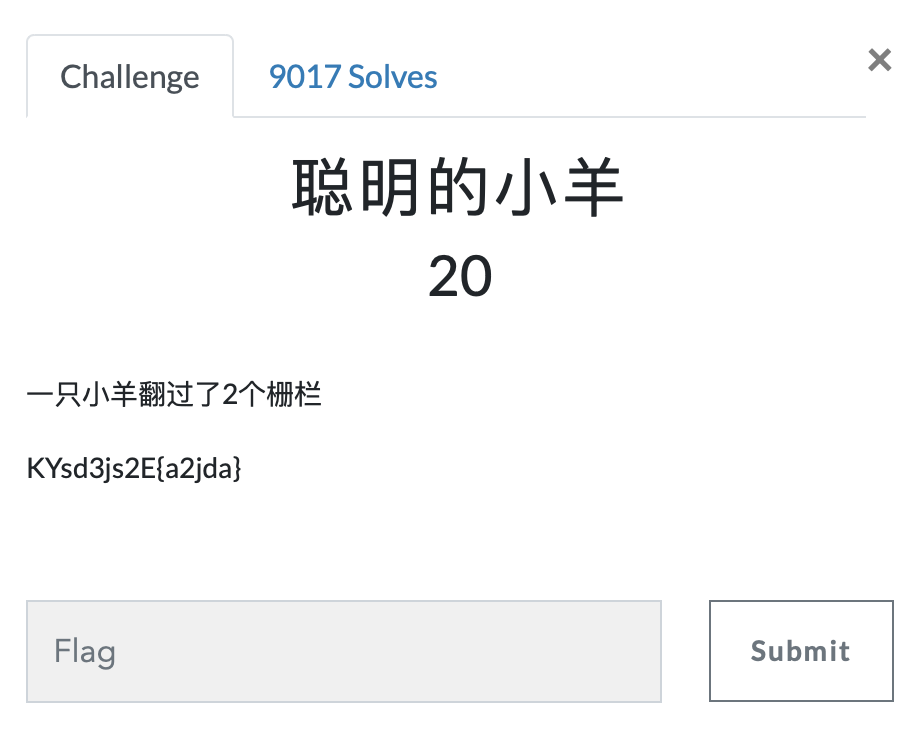
第二题 聪明的小羊
https://ctf.bugku.com/challenges#聪明的小羊

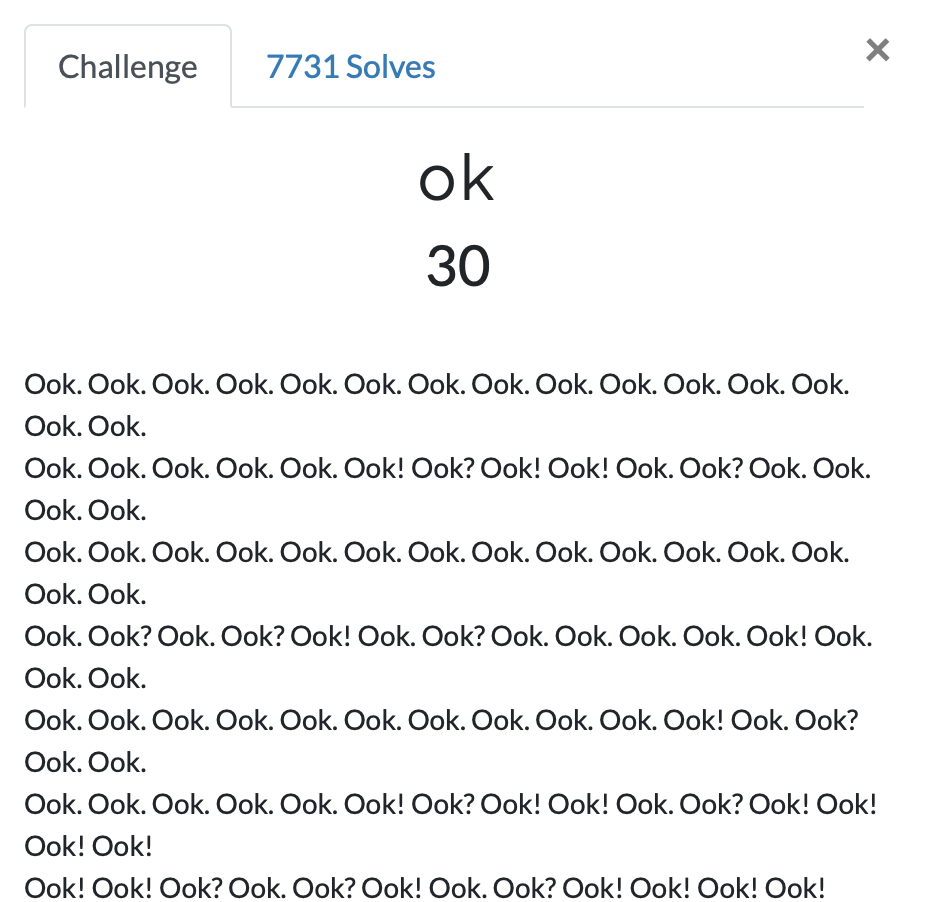
第三题 ok
https://ctf.bugku.com/challenges#ok

第四题 这不是摩斯密码
https://ctf.bugku.com/challenges#这不是摩斯密码

第五题 easy_crypto
https://ctf.bugku.com/challenges#easy_crypto

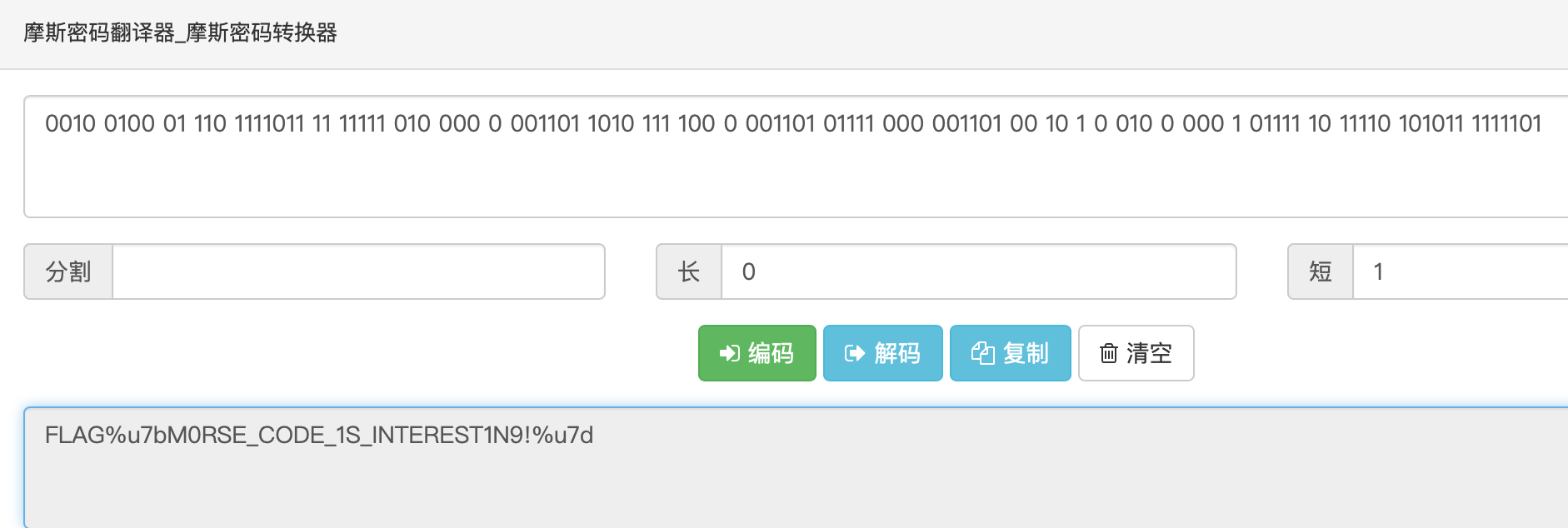
- 摩斯密码变种,
0代替了-,1代替了.,最后结果要化成小写。
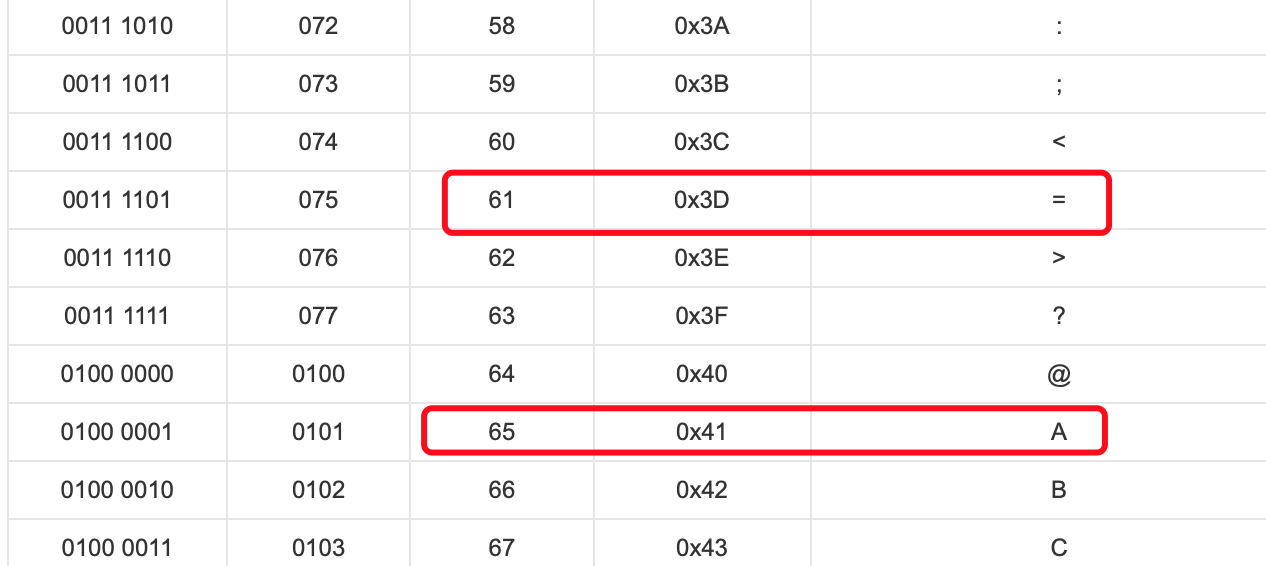
第六题 简单加密
https://ctf.bugku.com/challenges#简单加密
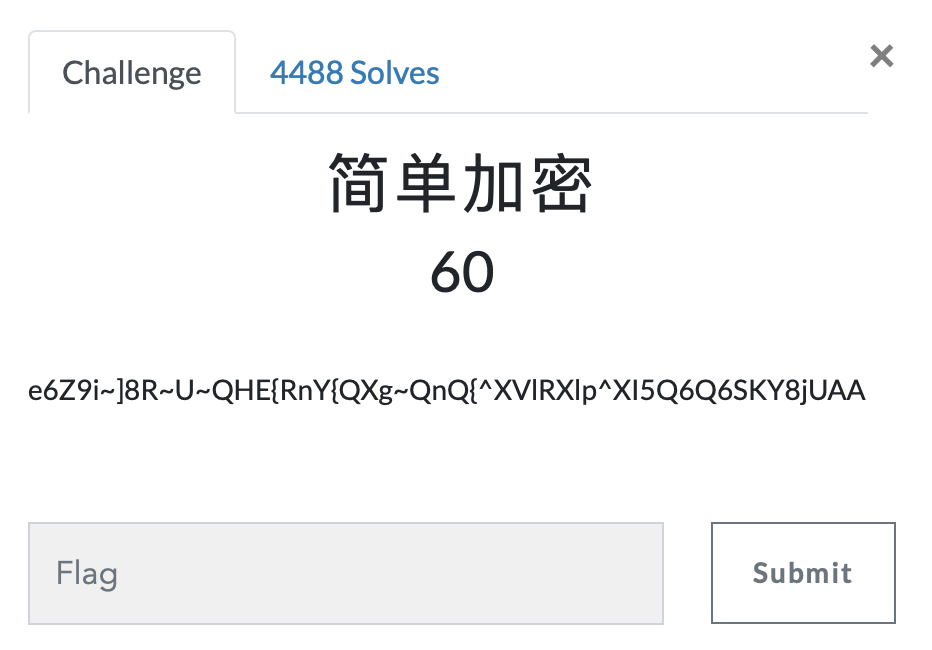
- 看起来很神似base64,但是有一些字符不在base64加密字符的范围,由最后两个AA,猜测是==偏移ascii码之后的结果。
- 写脚本,先进行ascii码偏移,再进行base64解码
# 这个脚本用于先进行ascii码偏移,再进行base64解码
import base64
miwen = open('miwen.txt').readline()
res = '' # 存储结果
for i,enu in enumerate(miwen):
res += chr(ord(enu)-4)
print('ascii码偏移后结果:'+res)
res = base64.b64decode(res).decode()
print('base64解码后结果:'+res)

第七题 散乱的密文
https://ctf.bugku.com/challenges#散乱的密文
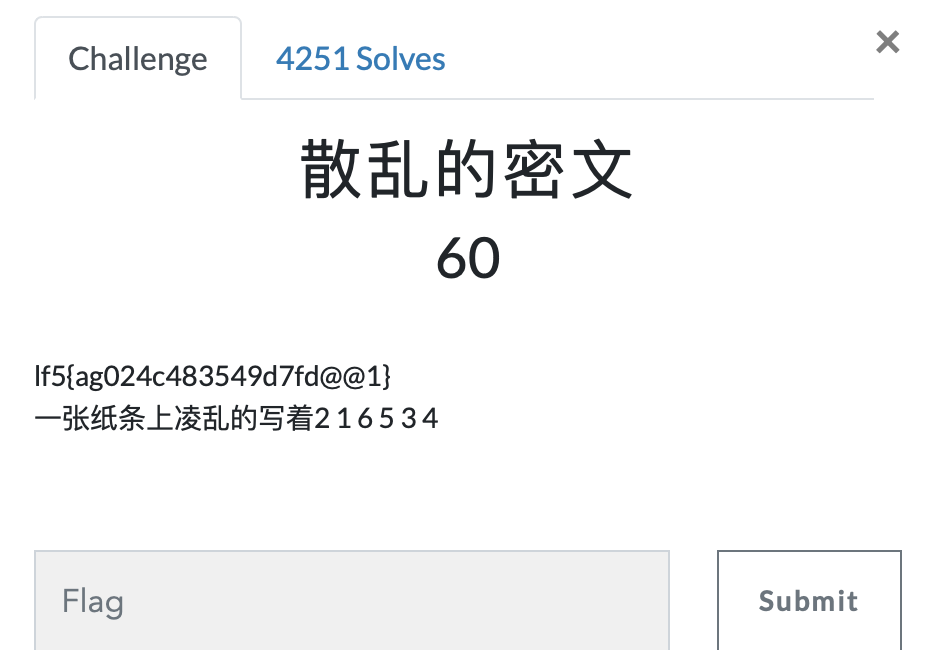
- 从密文中,我们大致可以猜测出只是字符顺序发生了改变,给的提示是2 1 6 5 3 4,也恰好证实了这一点,这样就说明密文是每六个一组,每一组的每个字符与2 1 6 5 3 4 ,分别对应,2 1 6 5 3 4 是他们明文的正确顺序,也就是说,明文中,第一个对应密文第二个,第二个对应密文第一个,第三个对应密文第五个……
- 写个脚本解决问题。
# 此脚本用来根据顺序调整密文以得到铭文
miwen = open('miwen.txt').readline()
tem = '' # 临时存储
resList = [] # 结果数组
res = '' # 最终结果
for i,enu in enumerate(miwen): # 先把密文每六个一组分好
tem += enu
if len(tem)==6 or i == len(miwen) - 1:
resList.append(tem)
tem = ''
for i in range(len(resList)):
res += resList[i][1]+resList[i][0]+resList[i][4]+resList[i][5]+resList[i][3]+resList[i][2]
print(res)

第八题 凯撒部长的奖励
https://ctf.bugku.com/challenges#凯撒部长的奖励

- 凯撒偏移20解密成功

第九题 一段Base64
https://ctf.bugku.com/challenges#一段Base64
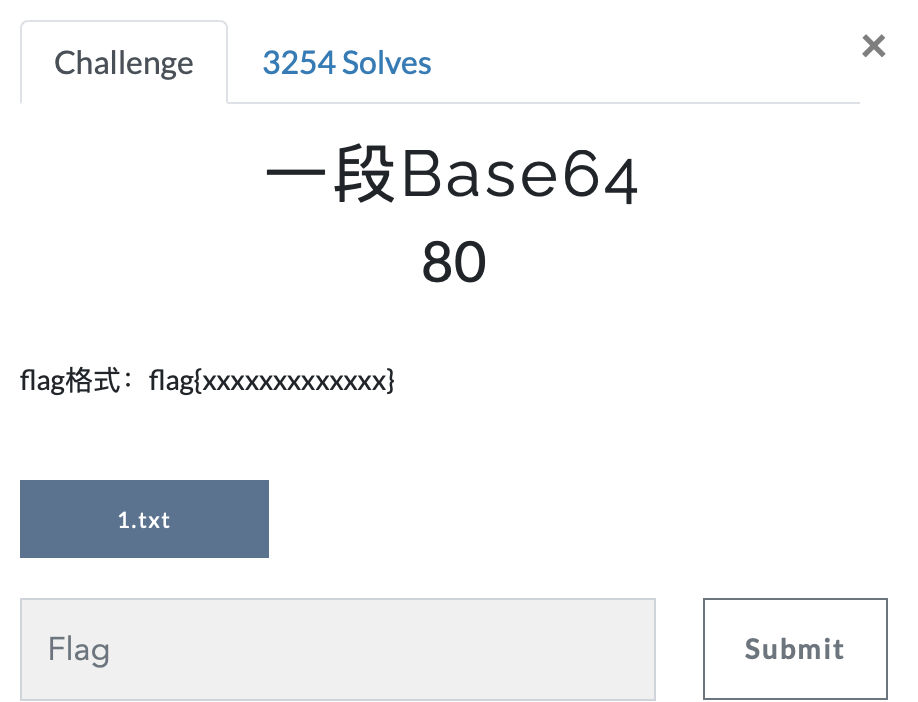
- Base64解密

- unescape
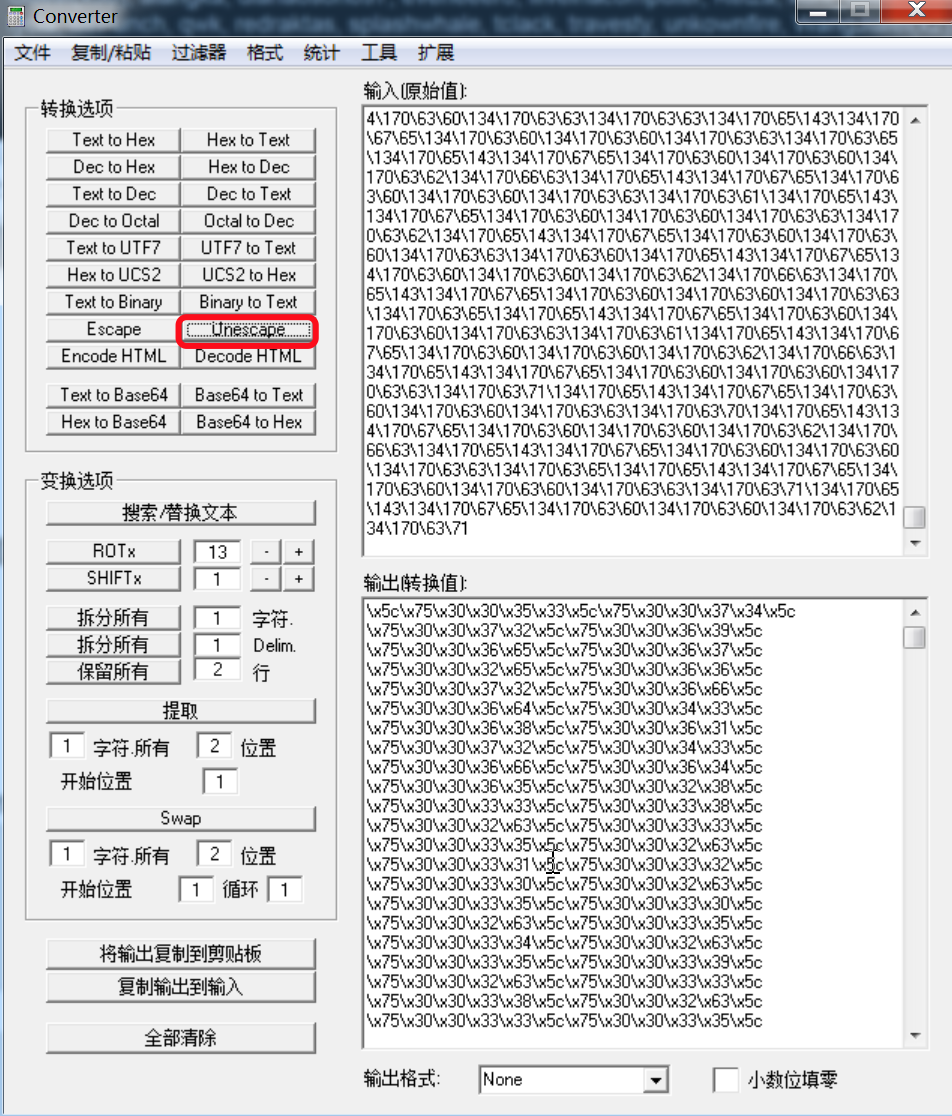
- Hex to text
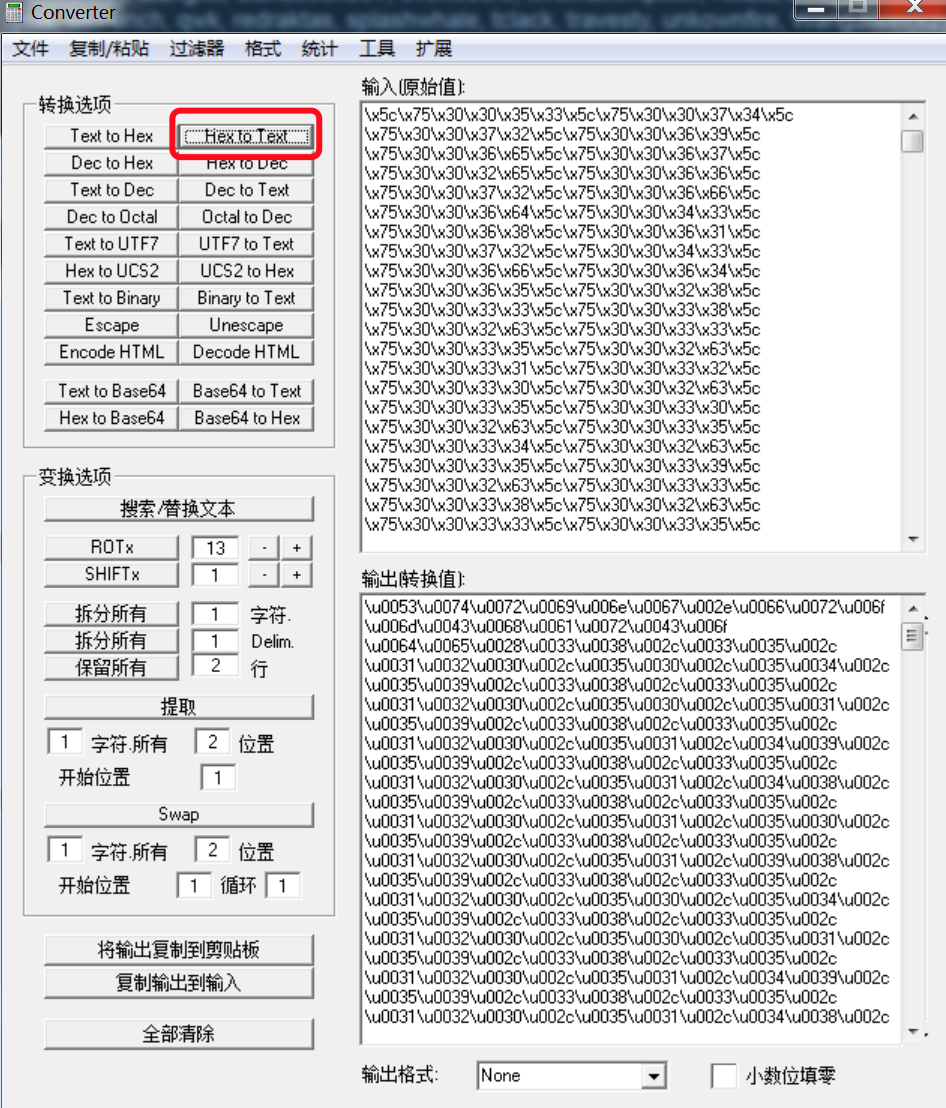
- unescape

String.fromCharCode(),也就是ascii码转字符吧,写个小脚本
# 此脚本用于ascii码转换字符,输入格式为:38,35,……,120,50
miwen = open('miwen.txt').readline().split(',')
for i in range(len(miwen)):
print(chr(int(miwen[i])),end='')
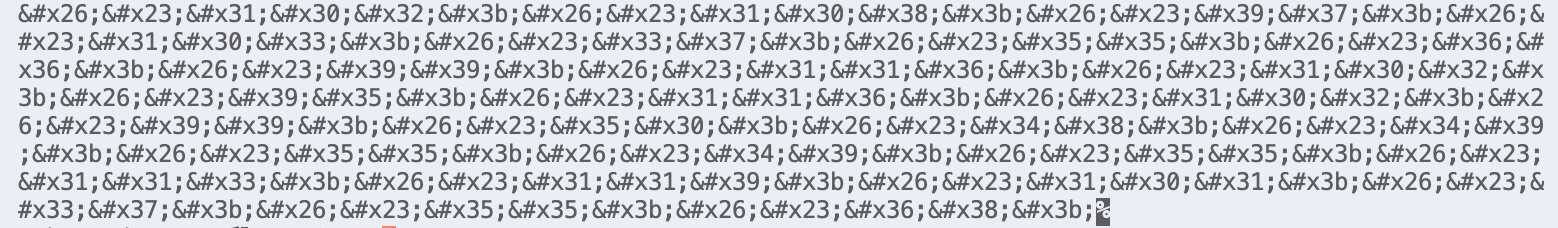
6. Decode HTML
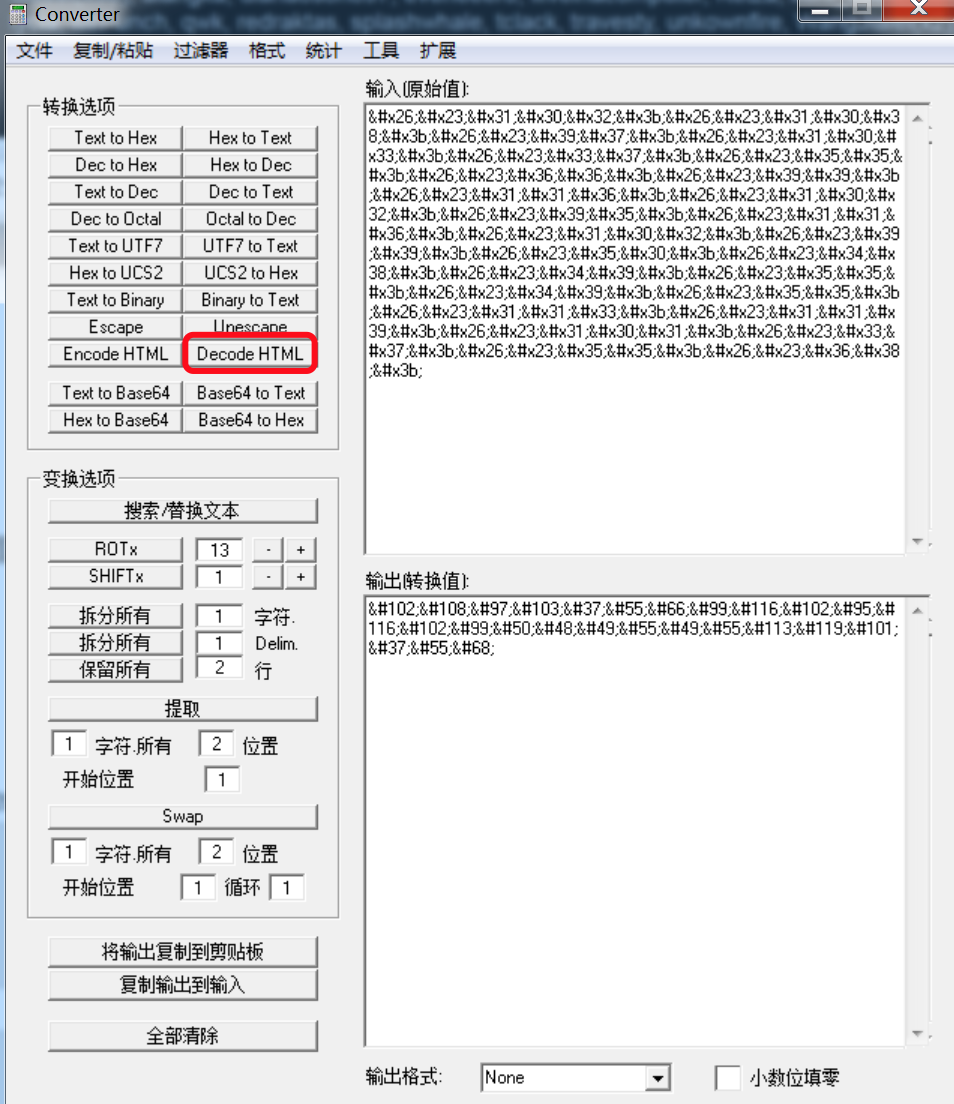
7. Decode HTML
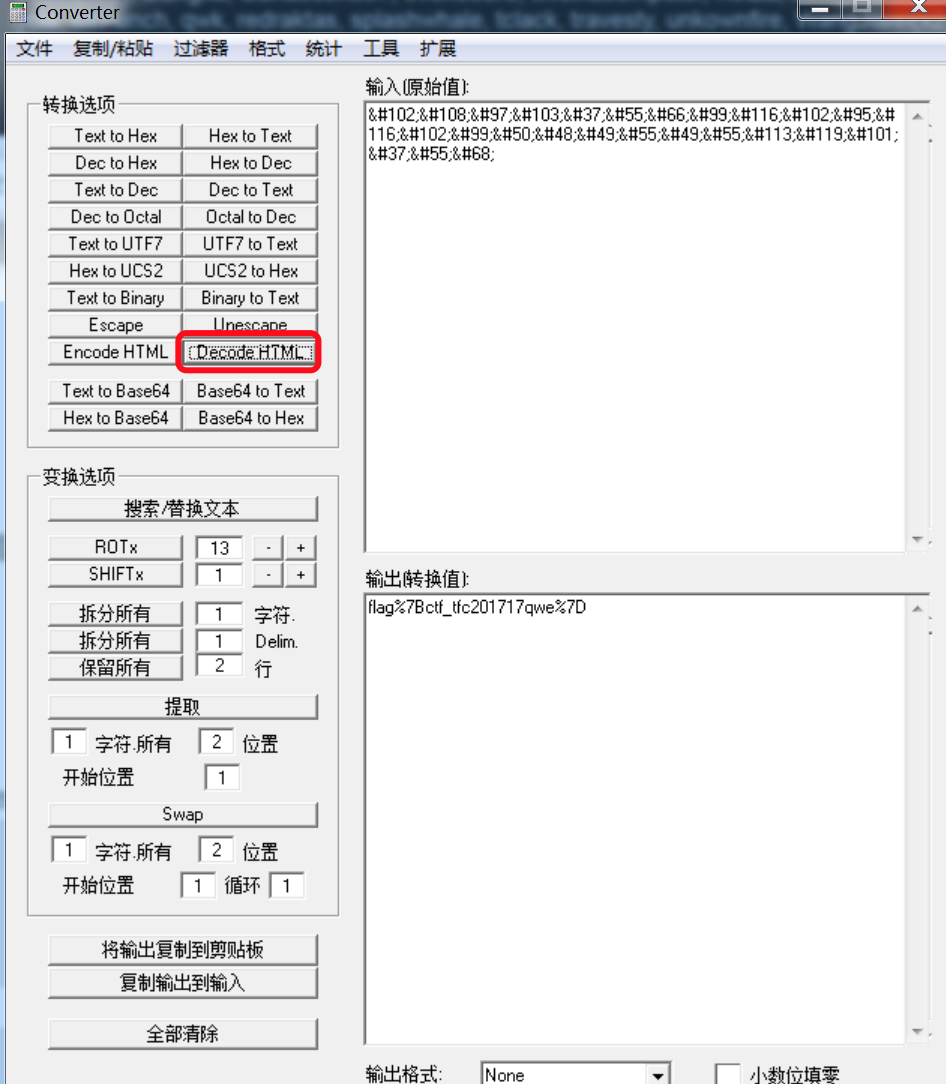
8. ……终于出结果了🙄
第十题 .!?
https://ctf.bugku.com/challenges#.!?
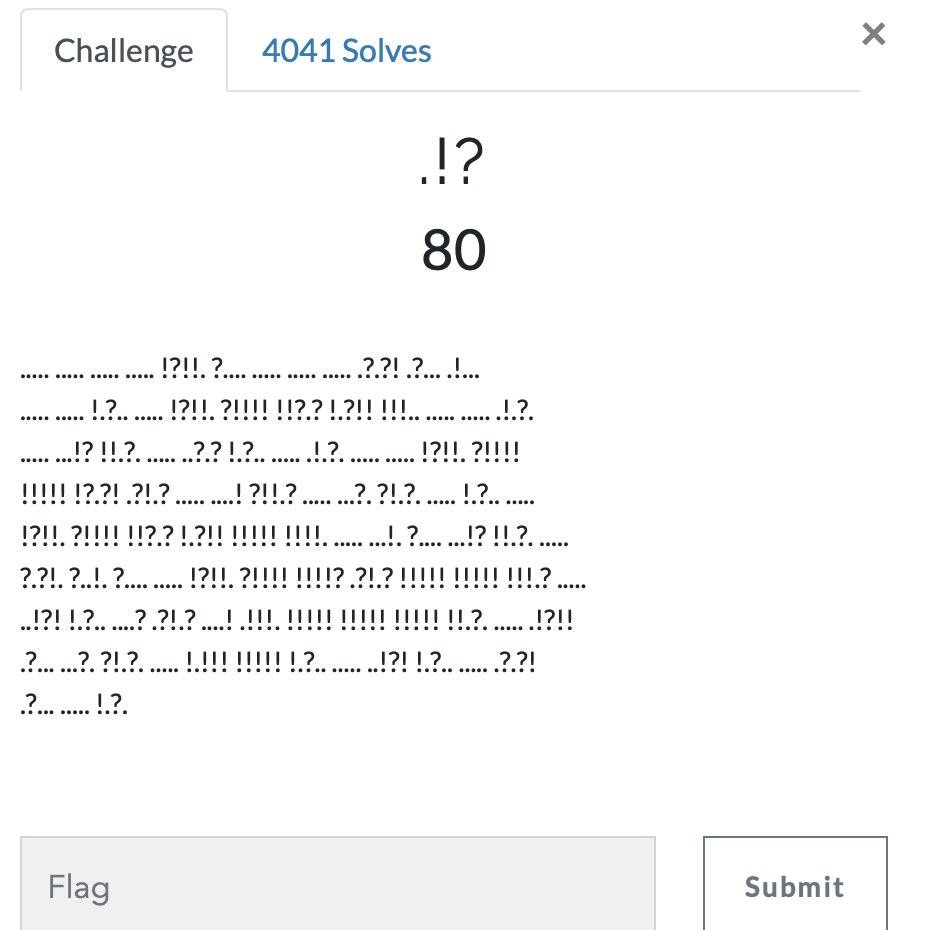
- short ook编码
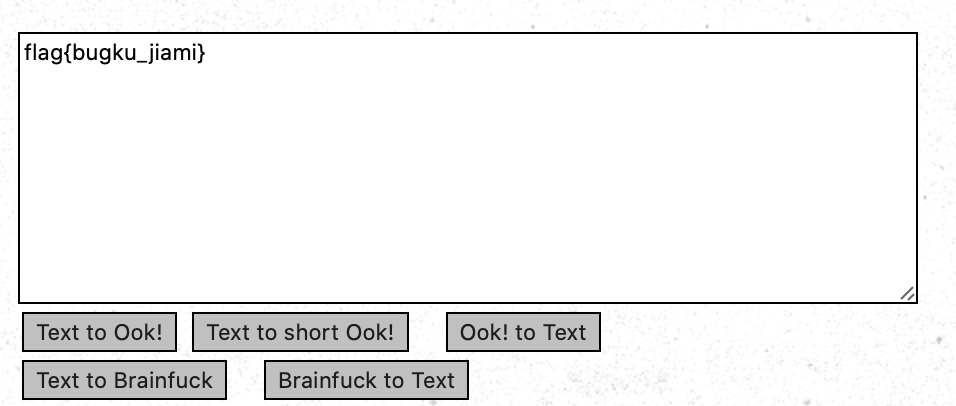
第十一题 +[]-
https://ctf.bugku.com/challenges#+[]-
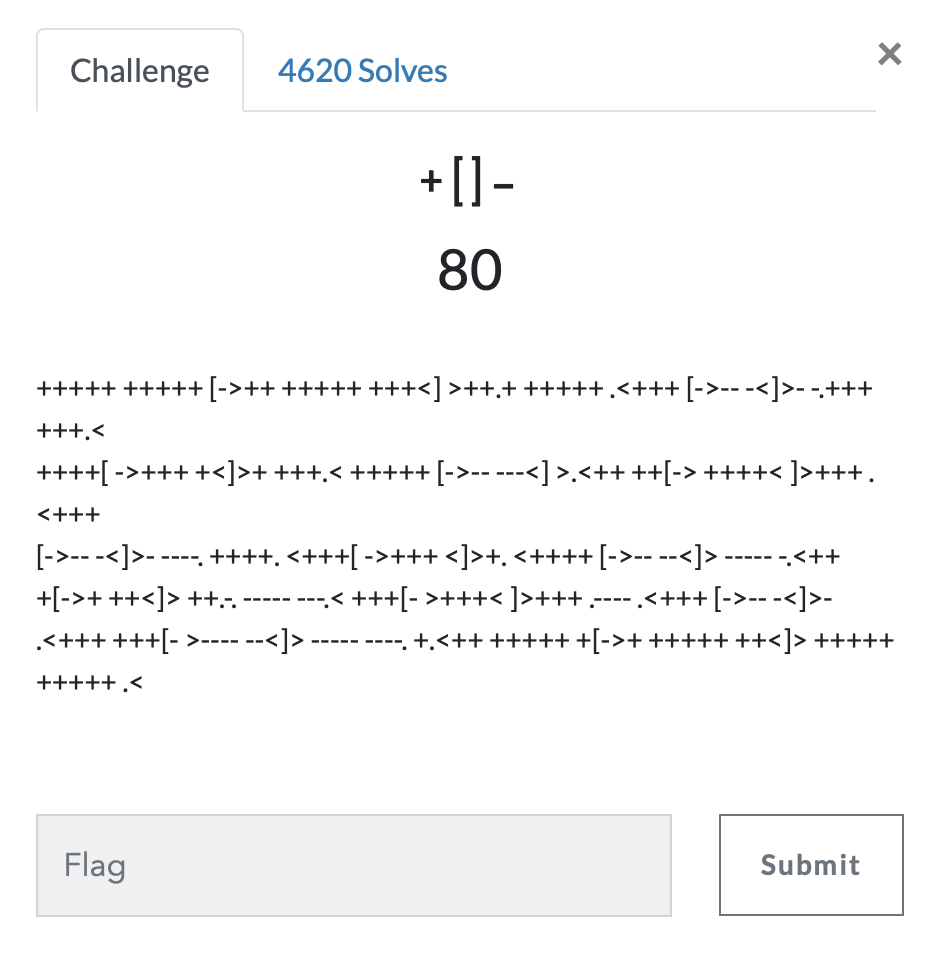

第十二题 奇怪的密码
https://ctf.bugku.com/challenges#奇怪的密码
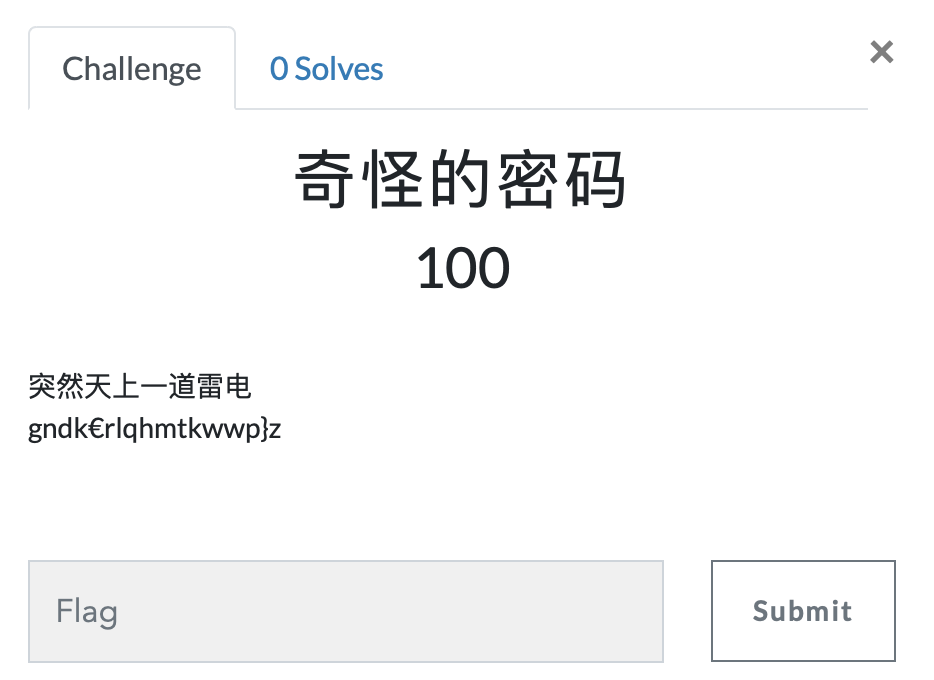
- 突然天上一道雷电,其实想说累次加密,也就是ascii码偏移量越来越大
- 小脚本
# 此脚本用于解决累次加密
miwen = open('miwen.txt').readline()
for j in range(10):
for i,enu in enumerate(miwen):
print(chr(ord(enu)-i-j),end = '')
print()
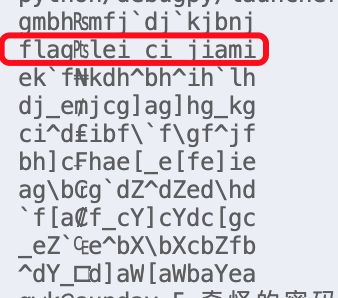
3. 去掉乱码,改改格式后提交
第十三题 托马斯.杰斐逊
https://ctf.bugku.com/challenges#托马斯.杰斐逊

- 百度托马斯.杰斐逊加密,杰弗逊加密
原理:- 三部分:加密表、密文、密钥
- 密钥决定由加密表转换行的顺序得到解密表,比如这里密钥为2,5,1,3,即表示,加密表中,第二行表示解密表中第一行,第五行表示解密表中第二行……
- 密文决定由解密表每行偏移得到明文
- 在脚本中体现过程
# 此脚本用于解密托马斯杰裴逊密文
jiaMiBiao = open('jiamibiao.txt').readlines()
miYao = open('miyao.txt').readline().split(',')
miwen = open('miwen.txt').readline()
jieMiBiao = []
print('---------')
# 简化加密表
for i in range(len(jiaMiBiao)):
jiaMiBiao[i] = jiaMiBiao[i].split(' <')[1]
print(jiaMiBiao[i])
print('---------')
# 通过密钥调整行顺序得到解密表
for i in range(len(miYao)):
jieMiBiao.append(jiaMiBiao[int(miYao[i])-1])
print(jieMiBiao[i])
print('---------')
# 通过密文调整每一行的字符顺序
tem = '' # 临时存储
for i,enu in enumerate(miwen):
for j in range(len(jieMiBiao[i])):
tem += jieMiBiao[i][(jieMiBiao[i].index(enu) + j) % len(jieMiBiao[i])]
jieMiBiao[i] = tem
tem = ''
print(jieMiBiao[i])
print('---------')
# 输出调整后的解密表每一列的数据
for i in range(len(jieMiBiao[0])):
for j in range(len(jieMiBiao)):
print(jieMiBiao[j][i],end = '')
print()
- 简化加密表结果:

- 通过密钥调整行顺序得到解密表结果:

- 通过密文调整每一行的字符顺序结果:

- 输出调整后的解密表每一列的数据,从中找到我们需要的信息:

- 太赞了,哈哈哈哈,给自己一个奥力给🤓提交的时候要变成小写哦🤷♂️
第十四题 zip伪加密
https://ctf.bugku.com/challenges#zip伪加密
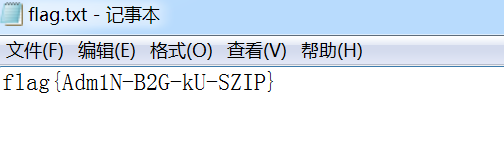
- 很明白了,直接winhex打开,把两处PK后边的
14000900改为14000000,解压得到答案

第十五题 告诉你一个秘密
https://ctf.bugku.com/challenges#告诉你个秘密(ISCCCTF)
- 给的密文由1-F的字符组成,应该是十六进制无疑,解密得
cjV5RyBscDlJIEJqTSB0RmhCVDZ1aCB5N2lKIFFzWiBiaE0g
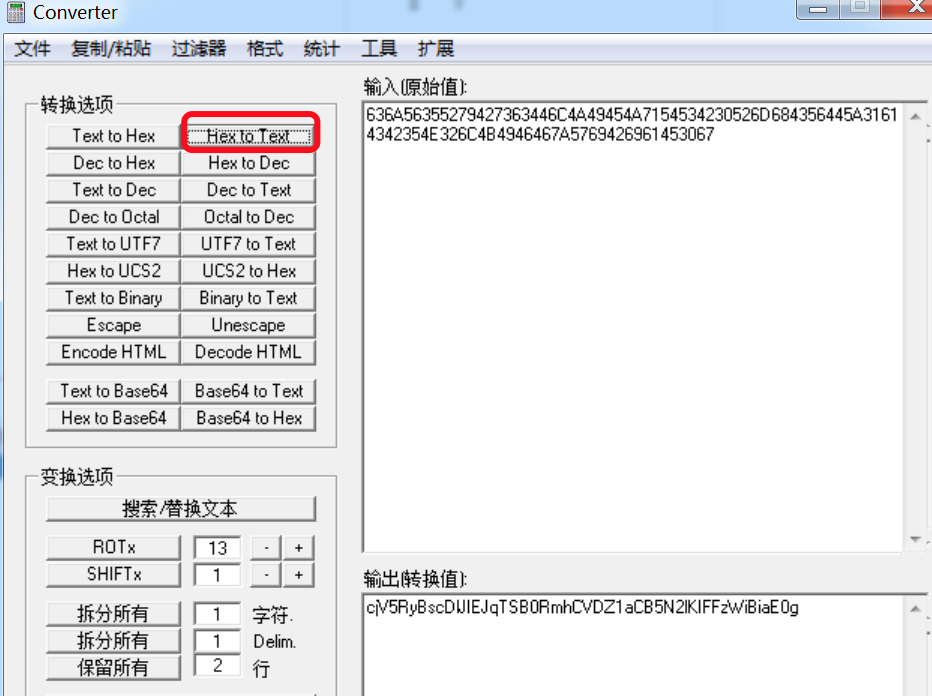
- 看起来像base64,解密得
r5yG lp9I BjM tFhBT6uh y7iJ QsZ bhM

- 字符中flag都有了,应该只是顺序发生变化,考虑栅栏密码,发现不是,ascii偏移也不是,
- 原来是这样,哈哈哈哈哈,每一组字符,在键盘上围成一圈,被围住的就是结果,哈哈哈哈,结果是
tongyuan,不对,是大写TONGYUAN
第十六题 这不是md5
https://ctf.bugku.com/challenges#这不是md5
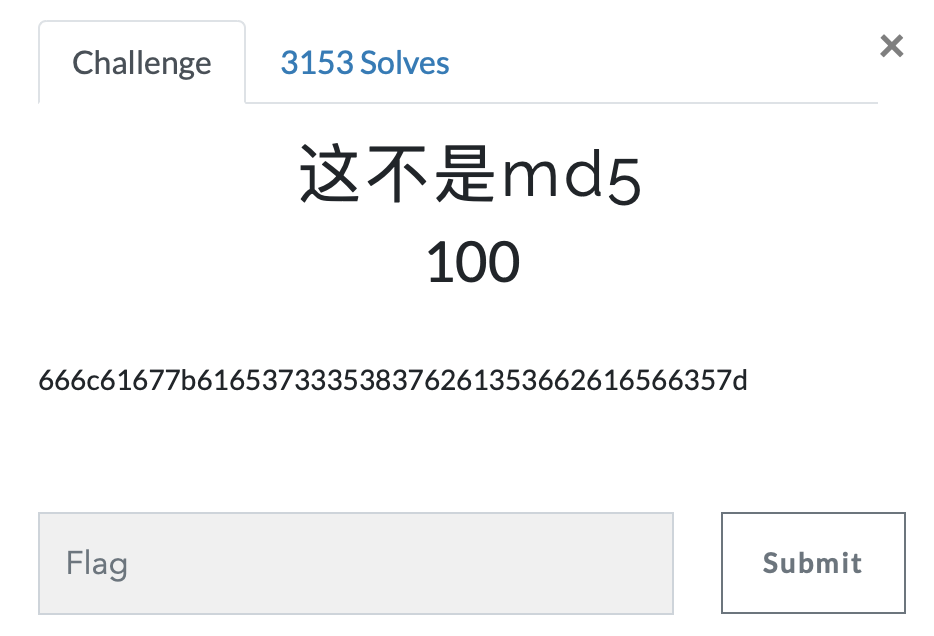
- e,这个好简单,他说不是md5,然后一看范围在1-F,试一下十六进制,一下就出结果了……这个题是不是应该放在前边🙄
第十七题 贝斯家族
https://ctf.bugku.com/challenges#贝斯家族
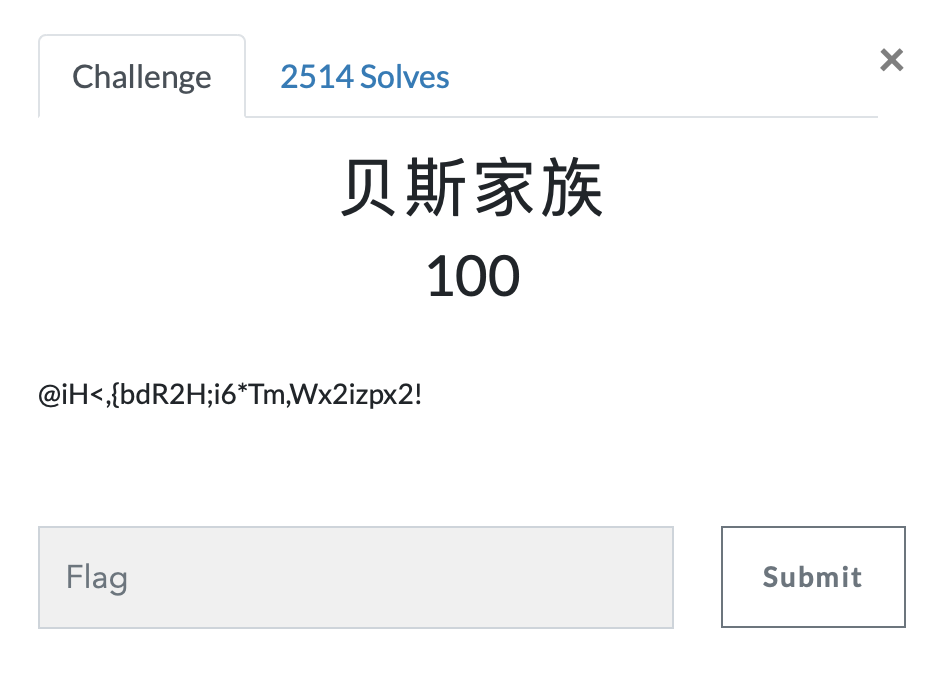
- 不平凡的base
@iH<,{bdR2H;i6*Tm,Wx2izpx2!,第二遍了我还没想起来🤷♂️base91
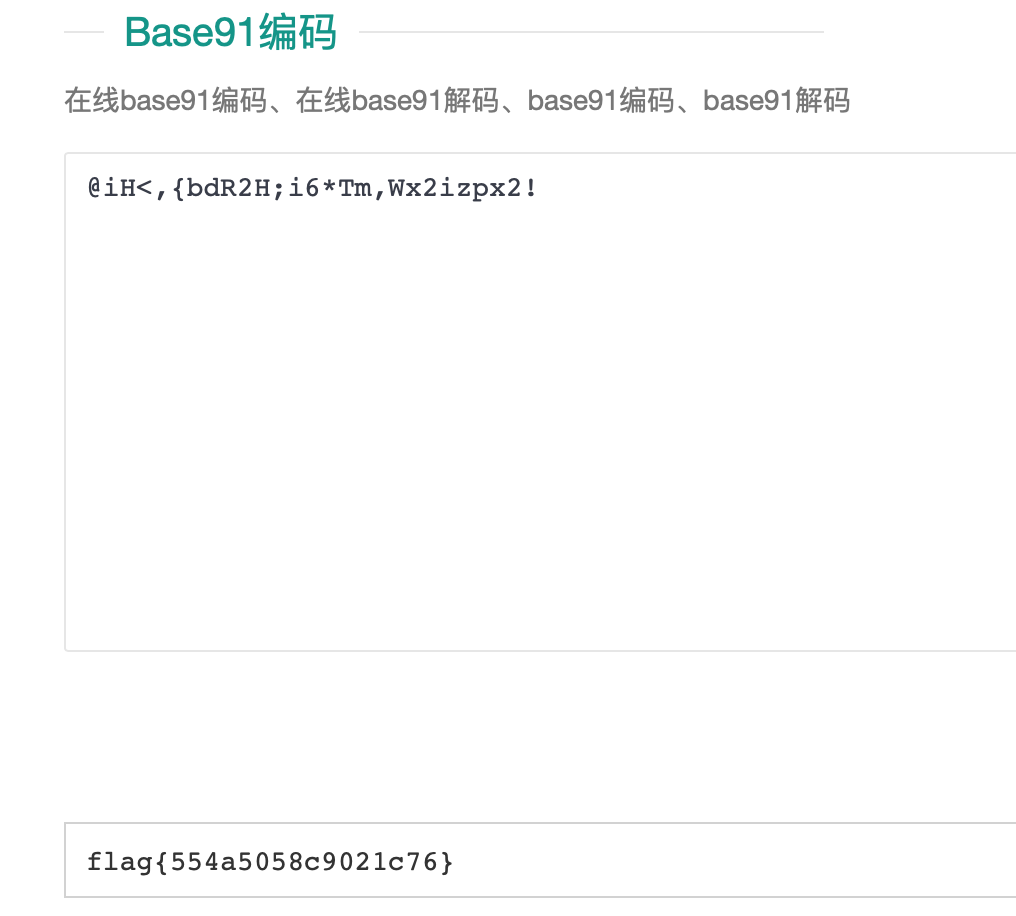
- base 91,字符比较多
第十八题 富强民主
https://ctf.bugku.com/challenges#富强民主
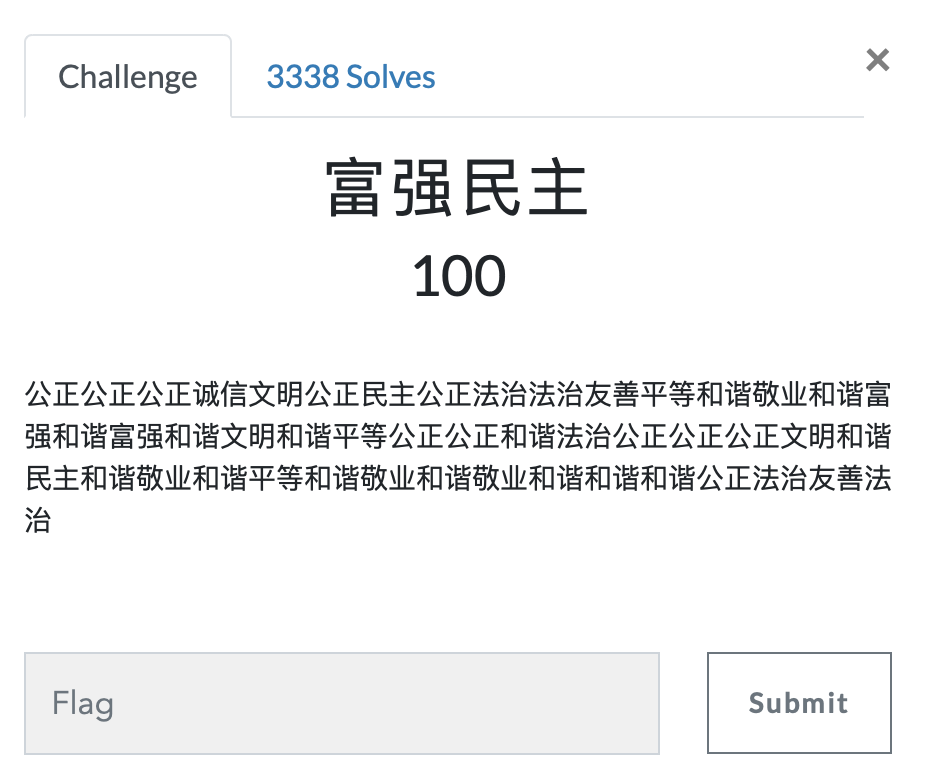
第十九题 python(N1CTF)
https://ctf.bugku.com/challenges#python(N1CTF)

- 先看看
- 太难了,放弃……
第二十题 进制转换
https://ctf.bugku.com/challenges#进制转换
- 下载下来,很明显,b开头是二进制,o开头是八进制,d开头是十进制,x开头是十六进制。
- 小脚本,经过上一题,我发现我的python真的🌶️🐔
# 此脚本针对不同进制字符,统一转换成十进制,再转成字符
miwen = open('text.txt').readline().split(' ')
res = ''
for i in range(len(miwen)):
if miwen[i][0] == 'b':
res += chr(int(miwen[i][1:],2))
elif miwen[i][0] == 'd':
res += chr(int(miwen[i][1:],10))
elif miwen[i][0] == 'o':
res += chr(int(miwen[i][1:],8))
elif miwen[i][0] == 'x':
res += chr(int(miwen[i][1:],16))
print(res)

第二十一题 affine
https://ctf.bugku.com/challenges#affine
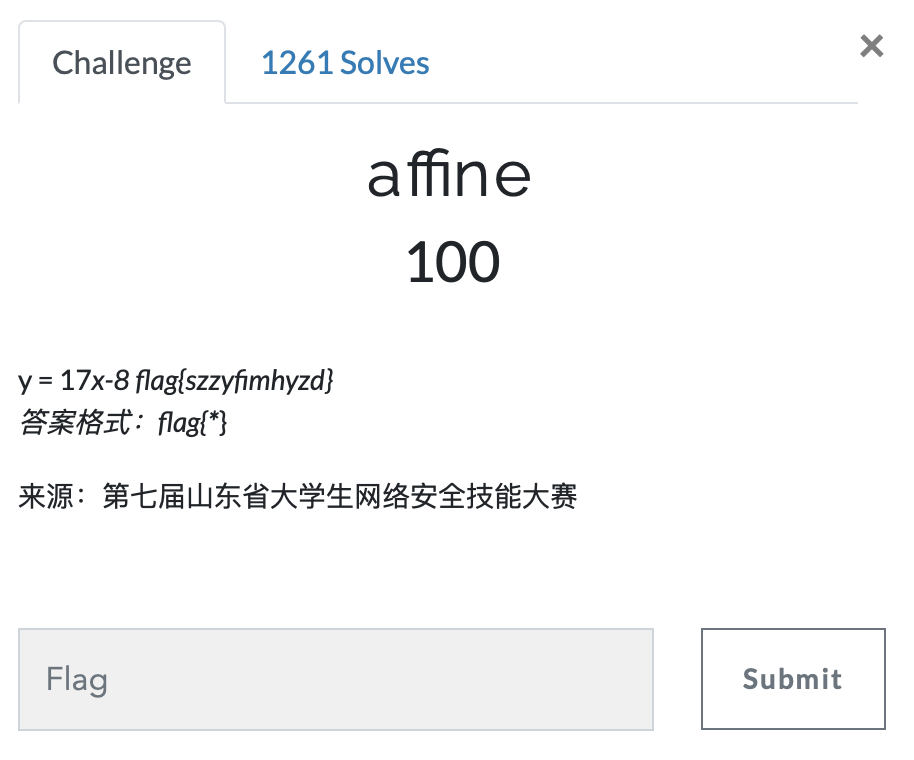
- affine加密,仿射加密,听着挺高级,其实也就是明文和密文之间有一个一次函数变化,y=kx+b,只不过为了让y能转换成对应的密文,要对kx+b取余。
- 一般常用的字符集就是a-z,分别对应0-26。
- 并且,一次函数能用于做密码是因为他有个特性,就是每一个x对应唯一的y,所以为了保证取余之后也能保持这种特性,就要求k与字符集的大小(这里是26)互质。
- 像这种知道加密函数解密也有两种方法,一种是用解密函数,一种是暴力破解,哪种都可以。这次我两种都试一下⛹🏻♂️
- decry.py,部分内容参考自这里
# 此脚本用于暴力破解仿射加密
# 加密函数:y=17x-8
# 密文: szzyfimhyzd
miwen = "szzyfimhyzd"
def baoLi(miwen): # 暴力解密
miwen = miwen.lower() # 全部转换成小写
res = ''
for i,enu in enumerate(miwen): # 遍历每一个字母
for j in range(26): # 遍历字母表
if (17 * j - 8) % 26 == ord(enu) - 97: # 比对加密结果
res += chr(j + 97)
break # 成功直接跳出
return res
#仿射密码解密
#改进欧几里得算法求线性方程的x与y
def get(a, b):
if b == 0:
return 1, 0
else:
k = a //b
remainder = a % b
x1, y1 = get(b, remainder)
x, y =y1, x1 - k * y1
return x, y
def jiemi(miwen): # 解密函数解密
miwen = miwen.lower()
res = ''
k = 17
b = -8
#求a关于26的乘法逆元
x, y = get(k, 26)
a1 = x % 26
for i, enu in enumerate(miwen):
res += chr((a1 * (ord(enu)- 97 - b) % 26)+ 97)
return res
print("暴力解密结果:"+baoLi(miwen))
print("解密函数解密:"+jiemi(miwen))

第二十二题 Crack it
https://ctf.bugku.com/challenges#Crack%20it
- 没带工具,等等再做
第二十三题 rsa
https://ctf.bugku.com/challenges#rsa
- rsa相关概念:取自这里
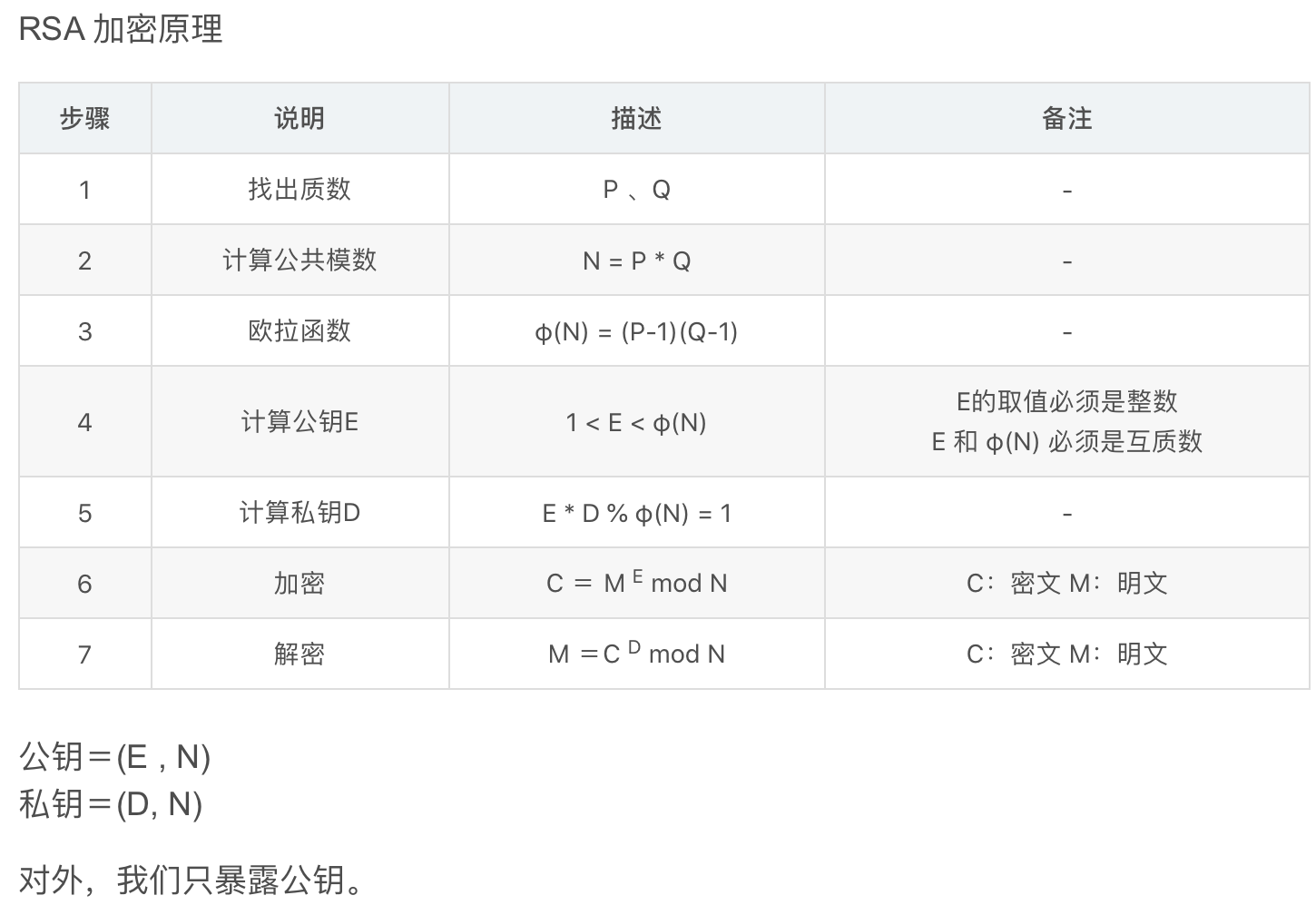
- 给出了N、e、密文,解密函数是
M =C^D mod N,那么问题的关键就是怎么通过N、e求出来密钥D - 然后有了方法,把N分解成大素数
经验教训
- 有两种符号组成,每几个一组,每组符号个数不一定相同的加密结果,考虑摩斯密码;
- 每组有五个字符,一共有三种类型的字符,可能是short ook加密,一般是
.!?这三种字符; - 每组有五个字符,一共有七种类型的字符,可能是brainfuck加密,一般是
+-[]<>.这七种字符; \123\123\123,类似的反斜杠加数字的组合,是escape加密结果;\x5c\x75,类似的组合是十六进制结果;\u0053\u0074,类似的组合是escape加密结果;&#,类似的组合是encode HTML的结果;f7,类似的组合是encode HTML的结果;
赠人玫瑰🌹手有余香
能帮到你我很高兴
您的赞👍是我前进的动力,奥力给
Thanks for watching!
