pytorch
model.train()的作用是启用 Batch Normalization 和 Dropout。
model.eval()的作用是不启用 Batch Normalization 和 Dropout。
训练流程:
def train(model, optimizer, epoch, train_loader, validation_loader):
for batch_idx, (data, target) in experiment.batch_loop(iterable=train_loader):
model.train() # 正确的位置,保证每一个batch都能进入model.train()的模式
data, target = Variable(data), Variable(target)
# Inference
output = model(data) # 计算模型结果
loss_t = F.nll_loss(output, target) # 计算loss
# The iconic grad-back-step trio
optimizer.zero_grad() # 梯度清零
loss_t.backward() # loss反向传播
optimizer.step() # 参数优化
if batch_idx % args.log_interval == 0:
train_loss = loss_t.item()
train_accuracy = get_correct_count(output, target) * 100.0 / len(target)
experiment.add_metric(LOSS_METRIC, train_loss)
experiment.add_metric(ACC_METRIC, train_accuracy)
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx, len(train_loader),
100. * batch_idx / len(train_loader), train_loss))
with experiment.validation():
val_loss, val_accuracy = test(model, validation_loader) # ????????????
experiment.add_metric(LOSS_METRIC, val_loss)
experiment.add_metric(ACC_METRIC, val_accuracy)
如果不在意显存大小和计算时间的话,仅仅使用model.eval()已足够得到正确的validation/test的结果;
而with torch.no_grad()则是更进一步加速和节省gpu空间(因为不用计算和存储梯度),从而可以更快计算,也可以跑更大的batch来测试。
LN和Bn
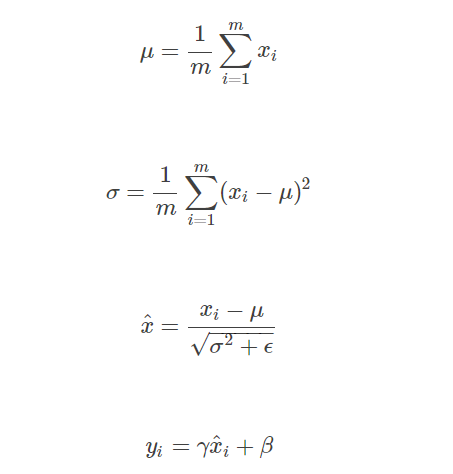
如果单纯地使用前三个公式,有可能会影响一些层的表达能力,例如,如果使用激活函数使用sigmoid,那么这个操作会强制输入数据分布在sigmoid接近线性的部分,接近线性的模型显然不好(影响整个模型的表达能力)。所以文中说把前三个公式作为基本变换(单位变换),加上放缩和平移后再拿来使用,这两个参数是可以学习的。

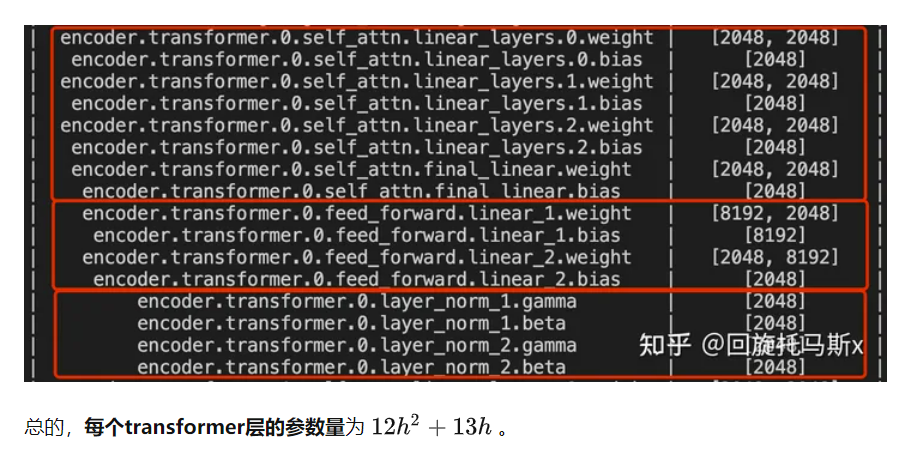
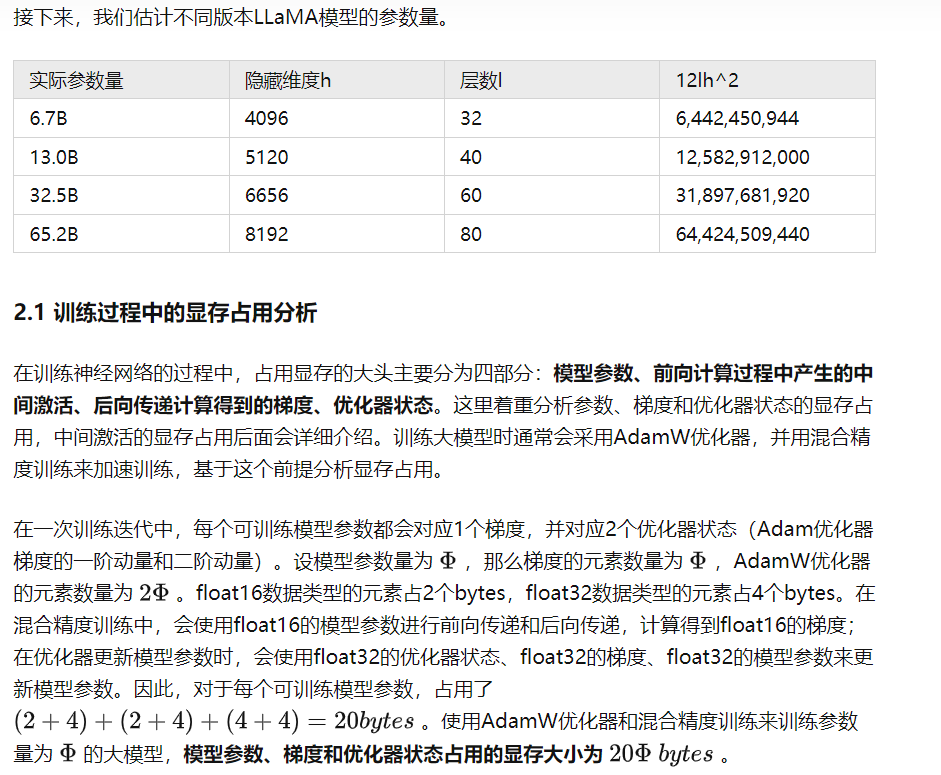
Transformer的模型参数量:

















 浙公网安备 33010602011771号
浙公网安备 33010602011771号