
transformers


transformer中的模型分类:
bert(自编码)、gpt(自回归)、bart(编码-解码)

hidden_size (d) = num_attention_heads (m) * attention_head_size (a),也即 d=m*a,

d为transformer模型输出的维度,这个维度一般是 attention头的个数*attention_head_size
transformer的多头:
d_size = 512(隐藏层维度) n=200(序列长度) head_size = 64(attention的头的维度) head_nums = 512/64=8(attention头的个数)
Input = 200*512 通过3个W权重矩阵,权重矩阵为512*64,生成qkv3个矩阵,维度为200*64*8(个数)
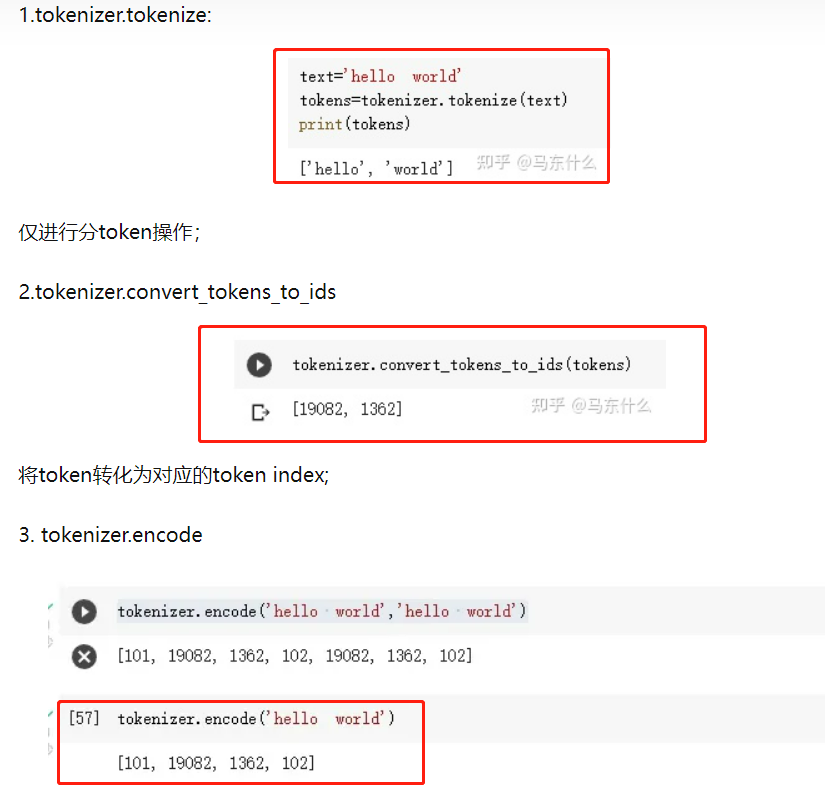
sentence = "Hello, my son is cuting."
input_ids_method1 = torch.tensor(tokenizer.encode(sentence, add_special_tokens=True)) # Batch size 1 //一次性进行分词和id映射
# tensor([ 101, 7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012, 102])
input_token2 = tokenizer.tokenize(sentence) //进行word piece分词
# ['hello', ',', 'my', 'son', 'is', 'cut', '##ing', '.']
input_ids_method2 = tokenizer.convert_tokens_to_ids(input_token2) // 将分词转为分词对应的ids
# tensor([7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012])
# 并没有开头和结尾的标记:[cls]、[sep]
(当tokenizer.encode函数中的add_special_tokens设置为False时,同样不会出现开头和结尾标记:[cls], [sep]。)
print(tokenizer.encode_plus(sentence)) // encode_plus除了输出ids,和type mask三个字典
[101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102]
{'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程