
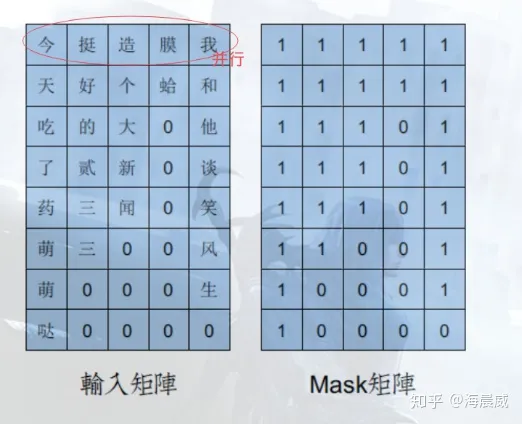
bert中mask
bert中n(seq_len)默认是512,通过padding,head_size = 64 hidden_size = 768 默认计算方式是hidden_size / heads(12) = 64,输入为seq_len(句子长度)*batch(句子个数)*embedingsize
(44条消息) BERT原理和结构详解_bert结构______miss的博客-CSDN博客
在BERT小模型中,每个head的神经元个数是64,12个head总的神经元的个数即为768,也就是模型介绍时说的H=768。在上图中单个的的Wq,Wk,Wv都是768*64的矩阵,那么Q,K,V则都是512*64的矩阵,Q,K_T相乘后的相关度矩阵则为512*512,归一化后跟V相乘后的z矩阵的大小则为512*64,这是一个attention计算出的结果。12个attention则是将12个512*64大小的矩阵横向concat,得到一个512*768大小的多头输出,这个输出再接一层768的全连接层,最后就是整个muti-head-attention的输出了,如图4所示。整个的维度变化过程如下图所示:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程