
面试专用
SY-个人主页 (jiangnanboy.github.io)
github:GitHub - lyhue1991/eat_pytorch_in_20_days: Pytorch🍊🍉 is delicious, just eat it! 😋😋
NLP 百面百搭 地址:https://github.com/km1994/NLP-Interview-Notes
推荐系统 百面百搭 地址:https://github.com/km1994/RES-Interview-Notes
搜索引擎 百面百搭 地址:https://github.com/km1994/search-engine-Interview-Notes 【编写ing】
NLP论文学习笔记:https://github.com/km1994/nlp_paper_study
推荐系统论文学习笔记:https://github.com/km1994/RS_paper_study
GCN 论文学习笔记:https://github.com/km1994/GCN_study
推广搜 军火库:https://github.com/km1994/recommendation_advertisement_search
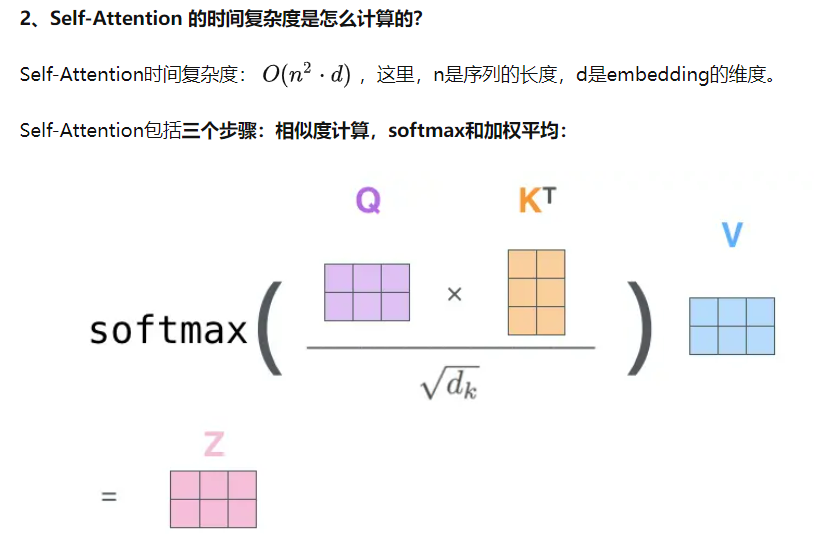
上面的公式可以看出,self-Attention中的Q是对自身(self)输入的变换,而在传统的Attention中,Q来自于外部。

3. torch.no_grad()与 model.eval()
model.eval()只是改变模型模式,对于有些操作,比如:BatchNorm、Dropout 等不再生效,与梯度无关。
torch.no_grad()即不再维护梯度相关的数据,比如前向过程不再构建反向图,因为不需要反向计算梯度了,不用再缓存中间节点的数据。
一般模型训练完成后,推理阶段这两个同时使用。
model.eval()只是改变模型模式,对于有些操作,比如:BatchNorm、Dropout 等不再生效,与梯度无关。
torch.no_grad()即不再维护梯度相关的数据,比如前向过程不再构建反向图,因为不需要反向计算梯度了,不用再缓存中间节点的数据。
一般模型训练完成后,推理阶段这两个同时使用。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程