
排序
RankNet,LambdaRank:


Ranknet的模型的目标函数的缺点:以错误pair最少为优化目标的RankNet算法,容易让好的变差,坏的变好来减少损失,LambdaRank就是来解决这个问题
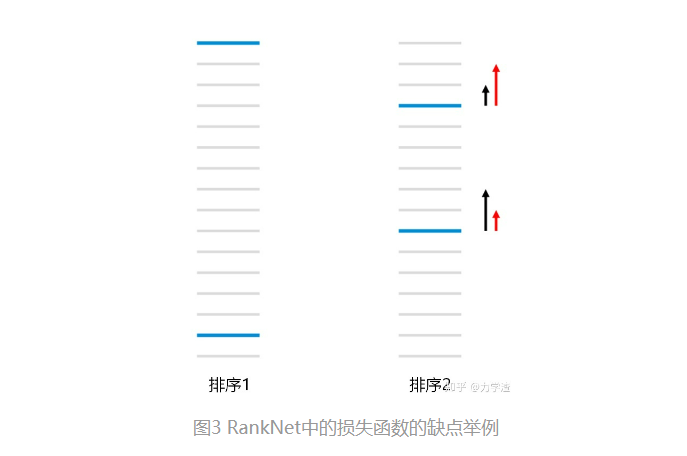
在上图中,每一条线表示一个文档,蓝色表示相关文档,灰色表示不相关文档。RankNet以Error pair(错误文档对数目)的方式计算cost。左边排序1排序错误的文档对(pair)共有13对,故cost为13,右边排序2通过把第一个相关文档下调3个位置,第二个相关文档上条5个位置,将cost降为11,但是像NDCG或者ERR等指标只关注top k个结果的排序,在优化过程中下调前面相关文档的位置不是我们想要得到的结果。上图排序2左边黑色的箭头表示RankNet下一轮的调序方向和强度,但我们真正需要的是右边红色箭头代表的方向和强度,即更关注靠前位置的相关文档的排序位置的提升。LambdaRank正是基于这个思想演化而来,其中Lambda指的就是红色箭头,代表下一次迭代优化的方向和强度,也就是梯度。
Learning to rank指标介绍
-
MAP(Mean Average Precision):
假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP= (0.83+0.45)/2=0.64。 -
NDCG(Normalized Discounted Cumulative Gain):
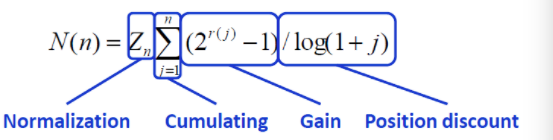
NDCG把相关度分为r个等级,如果r=5,等级设定分别文2^5-1,2^4-1等等
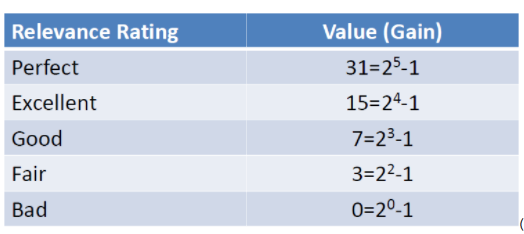
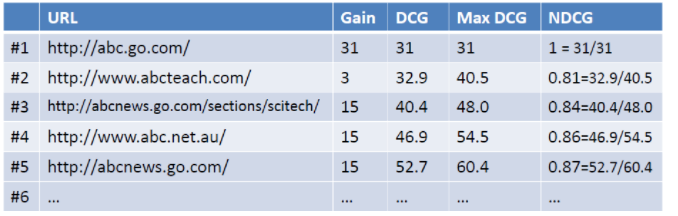
那么加入现在有一个query为abc, 返回如下图所示的列表,假设用户选择和排序结果无关,则累积增益值如右列所示:
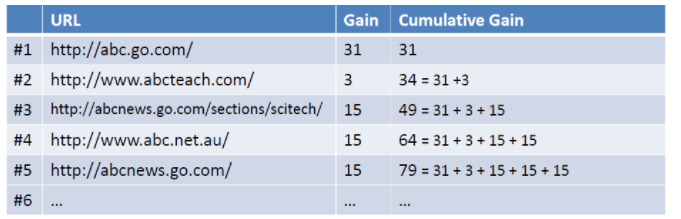
考虑到靠前的位置点击概率越大,那么靠下的位置需要加上衰减因子
log2/log(1+j),求和就可以得到DCG的值,最后为了使得不同不搜索结果可以比较,用DCG/MaxDCG就可以得到NDCG的值了。
MaxDCG就是当前情况下最佳排序的DCG值。如图所示MaxDCG就是1、3、4、5、2的排序情况下的DCG的值(rank 2的gain较低,应该排到后面)
NDCG值
- MRR(Mean Reciprocal Rank)
给定查询q,q在相关文档的位置是r,那么MRR(q)就是1/R
LambdaMART算法:
LambdaMART是Learning to rank其中的一个算法,在Yahoo! Learning to Rank Challenge比赛中夺冠队伍用的就是这个模型。
LambdaMART模型从名字上可以拆分成Lambda和MART两部分,训练模型采用的是MART也就是GBDT,lambda是MART求解使用的梯度,其物理含义是一个待排序文档下一次迭代应该排序的方向。
但Lambda最初并不是诞生于LambdaMART,而是在LambdaRank模型中被提出,而LambdaRank模型又是在RankNet模型的基础上改进而来。所以了解LambdaRank需要从RankNet开始说起。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程