
BUAA_2022_OO_Unit3 总结
一、任务概述
Java建模语言(JML)是一种行为接口规范语言,可用于指定Java模块的行为。
基于JML规格来实现程序,能够形式化验证程序的正确性,在检查各个模块时,也可以通过本模块的约束进行检查和验证。
第三单元的三次作业均为基于JML语言来设计java模块,以达到相应的行为描述。难点在于对JML语言的理解以及图论算法的应用。
-
理解JML语言,对语法的掌握是三次作业的基础
-
二、自测过程
测试数据采用了通过构造随机数据以及特殊数据加对拍的方式。
-
随机数据:
-
用大量数据覆盖对各个异常的检查
-
模块化测试指令
-
构造较大量的操作指令,ap,ar…,随后模块化检测查询指令,通过随机数据的随机性检查图模型之外的各个查询指令的正确性。
-
-
-
特殊数据
-
根据JML规格,设置边界数据:
-
一个
group的人数上限为1111
-
对于没有人的
group的报错处理
-
-
用大量的需要高复杂度的指令检查超时的情况
-
HW9的
queryBlockSum与isCircle,使用dfs会超时,应使用并查集
-
HW11的
qlc与HW10的qgvs均没有限制数量,容易出现超时的情况
-
-
针对图模型的算法正确性的构造
-
对
queryBlockSum、query_least_connection与send_indirect_message进行单独的检测,构造复杂的图(尽可能增加节点ap,增加节点之间的关系ar,同时避免孤立的节点)结构进行检测。
-
后将数据结果用对拍器对拍进行检测
-
JML知识梳理
以下为一些JML重点语法的记录与梳理
1、JML表达式
-
原子表达式
\result:表示一个非void方法执行获得的结果。\result 的表达式类型就是方法的返回值类型
\old(expr) :表示一个表达式expr在执行方法前的取值,括号中是一个表达式整体
\not_assigned(x,y
-
量化表达式
\forall表达式:全称量词修饰的表达式 eg:
\forall int i,j;0 <= i && i < j && j < 10;a[i] < a[j]
\exists表达式:存在两次修饰的表达式
\exists int i;0 <= i && i < 10;a[i] < 0 (对0<=i<10,至少存在一个a[i]<0)
\sum表达式:返回给定范围内的表达式的和
(\sum int i; 0 <= i && i < 5; i*i) = 1 + 4 + 9 + 16
\min表达式:返回给定范围内的表达式的最小值
(\min int i; 0 <= i && i < 5; i)
\num_of表达式: 返回范围内满足条件的个数
(\num_of int x; 0<x && x<=20;x%2==0)
-
操作符
(1) 子类型关系操作符: E1<:E2 ,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真。如果E1和E2是相同的类型,该表达式的结果也为真。
Integer.TYPE<:Integer.TYPE 为 真
Integer.TYPE<:ArrayList.TYPE为假
(2) 等价关系操作符:b_expr1<==>b_expr2 或者 b_expr1<=!=>b_expr2这两 个操作符和Java中的 == 和 != 具有相同的效果
(3) 推理操作符: b_expr1==>b_expr2 或者 b_expr2<==b_expr1对于表达式``b_expr1==>b_expr2 而 言,当 b_expr1==false ,或者 b_expr1==true 且 b_expr2==true 时,整个表达式的值为 true 。
(4) 变量引用操作符:\nothing指示一个空集;\everything指示一个全集
2、方法规格
-
前置条件:通过requires子句来表示: requires P;
-
后置条件:通过ensures子句来表示: ensures P;
-
副作用范围限定(side-effects)
-
使用关键词 assignable 或者 modifiable
-
句共有两种形态,一种不指明具体的变 量,而是用JML关键词来概括;另一种则是指明具体的变量列表
-
对于不对对象状态改变也不需要传入参数的纯粹访问性方法,且执行一定可以正常结束,可以使用简单的方式描述:
public /*@ pure @*/ String getname(); //@ ensure \result == bachelor || \result == master; public /*@ pure @*/ int getStatus();
-
区分正常功能行为与异常行为
/*@ public normal_behavior @ requires z <= 99; @ assignable \nothing; @ ensures \result > z; @ also @ public exceptional_behavior @ requires z < 0; @ assignable \nothing; @ signals (IllegalArgumentException e) true; @*/ public int cantBeSatisfied(int z) throws IllegalArgumentException;
-
其中,also的用法为:
(1)父类中对相应方法定义了规格,子类重写了该方法,需要补充规格,这时应该在补充的规格之前使用also;
(2)一个方法规格中涉及多个功 能规格描述,正常功能规格或者异常功能规格,需要使用also来分隔。
-
-
作为一种重要的设计原则,同一个方法的正常功能前置条件和异 常功能前置条件一定不能有重叠。异常功能规格中,后置条件常常表示为抛出异常,使用signals子句来表示。
-
signals子句
-
signals (***Exception e) b_expr,意思是当 b_expr 为 true 时,方法会抛 出括号中给出的相应异常e -
signals_only子句,后面跟着一个异常类型。(signals子句强调在对象状 态满足某个条件时会抛出符合相应类型的异常;而signals_only则不强调对象状态条件,强调满足前置条 件时抛出相应的异常。) -
针对输入参数的取值范围抛出不同的异常,从而提醒调用者进行 不同的处理
-
方法与类规格的约束关系
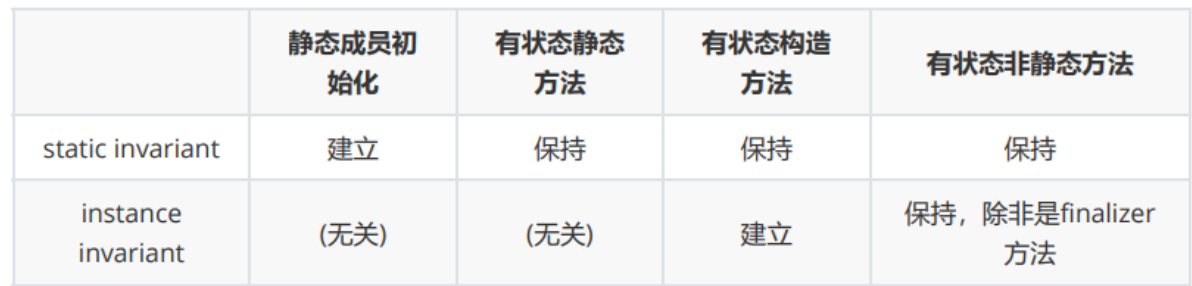
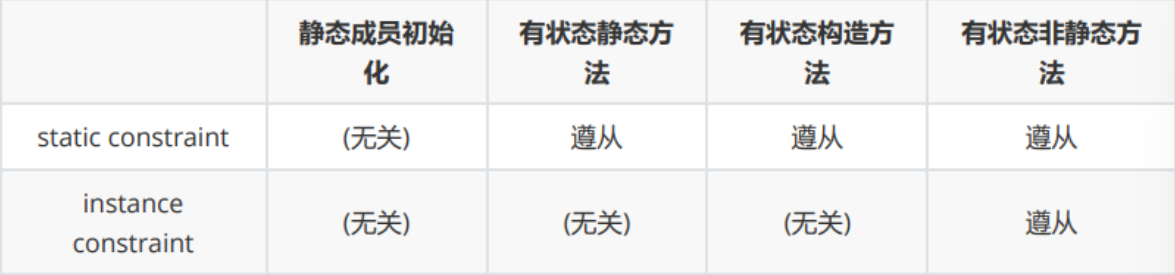
三、设计架构与图模型
1、基本架构
-
容器选择
在三次作业中我均选择了用
HashMap去存储,方便对于特定项进行判断是否在容器中,也方便对于项的加入,移除和修改。HashMap的复杂度为O(1),而若采用数组或链表来存的话,查找或遍历元素复杂度为O(N)private HashMap<Integer, Person> people; private HashMap<Integer, Group> groups; private HashMap<Integer, Message> messages;
-
对于异常类
对于异常情况的处理,三次作业几乎完全相同,在三次迭代的过程中可以总结出来以下四类
-
EqualId类 -
IdNotFound类 -
RelationNotFound类 -
EqualRelation类
均维护一个全局计数变量(counter异常引发次数),以及全局的对应各个异常类的实例引发异常的次数(Exception[i].counter)
采用static设置静态变量作为整个类的计数器
counter,对于个人引发异常的计数,采用设置全局HashMap数组,Key为id,value为相应实例的计数器counter -
2、图模型分析
1、HW9——连通分量
HW9设计图模型的指令的方法为isCircle以及QueryBlockSum
queryBlockSum:求连通分量的数量,开始我选用DFS算法(复杂度为n的平方),但是在互测会被hack到CTLE,于是改为并查集(复杂度为n)的办法。
并查集的数组下标对应元素ID,数组内容为所属组的id,通过每次的通过每次Add Relation时将并查集元素进行合并unionElements,即将新加入的元素的元素内容设置为所属的组号,进而可以通过查询
isCircle:查询两节点是否是联通的状态,实际为判断两者是否属于同一组下,用并查集方法可以很轻松的解决
//并查集 public int find(int element) { int ele = element; while (ele != parent[ele]) { ele = parent[ele]; } return ele; } public boolean isConnected(int fristElement, int secondElement) { return find(fristElement) == find(secondElement); } public void unionElements(int firstElement, int secondElement) { int firstRoot = find(firstElement); int secondRoot = find(secondElement); if (firstRoot == secondRoot) { return; } parent[firstRoot] = secondRoot; }
对于qbs指令中,为了避免每次计算block sum都要进行遍历,我选择了维护一个全局变量blockSum,在每次add person时判断该人是否时孤立的点,若是则blockSum++;在Add Relation时,判断该人是否原本出于relatio的连通分量中,若不是则blockSum--
2、HW10——最小生成树
求最小生成树用了Kruskal算法——在图中选择代价最小的边,若该边依附的顶点分别在T中不同的连通分量上,则将此边加入到T中;否则,舍去此边而选择下一条代价最小的边。依此类推,直至T中所有顶点构成一个连通分量为止。
因为Kruskal算法主要为对边的操作,便于实现算法,我设置了Edge类,作为算法中处理的原子
// Kruskal算法 ArrayList<Edge> sortList = sort(edgesPri); //由小到大排序好边集 UnionFind union = new UnionFind(); union.initial(); Iterator<Edge> iterator1 = sortList.iterator(); while (iterator1.hasNext()) { Edge edge = iterator1.next(); if (union.isConnected(((MyPerson) edge.getPerson1()).getMyCounter(), ((MyPerson) edge.getPerson2()).getMyCounter())) { continue; } union.unionElements(((MyPerson) edge.getPerson1()).getMyCounter(), ((MyPerson) edge.getPerson2()).getMyCounter()); path.add(edge); sum = sum + edge.getValue(); }
3、HW11——最短路径
应用到最短路径算法的是Sim指令,我采用了dijkstra算法
public int dijkstra(Person person1, Person person2) { boolean[] flag = new boolean[people.size()]; int[] prev = new int[people.size()]; int[] dist = new int[people.size()]; for (int i = 0;i < people.size();i++) { //Initial flag[i] = false; //标志是否确定下来最短距离 dist[i] = ((MyPerson)person1).queryValueMy(people.get(i)); if (person1.equals(people.get(i))) { flag[i] = true; dist[i] = 0; } } int k = 0; for (int i = 0;i < people.size();i++) { //遍历所有节点,求出其到顶点的最小距离 int min = INF; for (int j = 0;j < people.size();j++) { if (flag[j] == false && dist[j] < min) { //找到目前与顶点联通的距离最小的点 min = dist[j]; k = j; } } flag[k] = true; if (people.get(k).equals(person2)) { //找到了该点到顶点的距离 return min; } MyPerson personTmp = (MyPerson) people.get(k); for (int j = 0;j < people.size();j++) { int disTmp = personTmp.queryValueMy(people.get(j)); int tmp = (disTmp == INF ? INF : (min + disTmp)); if (flag[j] == false && tmp < dist[j]) { //更新节点到顶点的最短距离 dist[j] = tmp; } } } return INF; }
四、性能问题与修复情况
-
性能问题
1、若多次含有遍历的方法,会造成超时的bug。
2、虽然拥有正确性但是复杂度较高的算法
3、选择了功能较为简单的容器,查询时的遍历造成极大的性能损失
-
亿些可以降低复杂度的细节
-
getAgeMean()方法可以通过维护全局变量ageSum,减少每次访问时遍历数组。(同理与getAgeVar()) -
对于在操作中不断修改的值,也可以通过逻辑分析设置记录的全局变量:
-
getValueSum()设置valueSum变量,在ap时进行valueSum = valueSum + 2 * person.queryValue(item);
在delete person时进行
valueSum = valueSum - 2 * person.queryValue(item);
用valueSum记录了变化的过程,可以随时进行访问
-
-
改变储存数据的容器,选用
Linkedlist,PriorityQueue简化代码,同时降低复杂度。private LinkedList<Message> messages; public void addMessage(Message message) { messages.addFirst(message); }
-
三次作业的bug
HW9
我在查询连通分量时采用了dfs算法,造成了超时的bug,改成并查集后极大的提高了性能。
HW10
在qgvs指令的实现中,我采用了循环遍历的方法计算valueSum,过程复杂度较高,造成强测一个点CTLE。通过改变为维护变量valueSum的方法后修复bug
五、对Network的扩展
假设出现了几种不同的Person
-
Advertiser:持续向外发送产品广告
-
Producer:产品生产商,通过Advertiser来销售产品
-
Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买 -- 所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
-
Person:吃瓜群众,不发广告,不买东西,不卖东西
Advertiser、Producer、Customer继承Person类
Advertisement 、BuyMessage、ProductMessage 继承Message类
在Network类中设置
//Network中的新增属性 private HashMap<Integer, Product> products = new HashMap<>(); private HashMap<Integer, ArrayList<ProductMessage>> producers = new HashMap<>();//KEY = ProducerID;value = Product Message private HashMap<Integer, Advertisement > advertisers = new HashMap<>(); //KEY = AdvertiserID, VALUE = Advertisement private HashMap<Integer, ProductMessage> favourList = new HashMap<>(); //KEY = customerID; VALUE = ProductMessage private HashMap<Integer, ProductMessage> buyList = new HashMap<>(); //KEY = customerID;VALUE = ProductMessage
//Network中的新增方法 //生产产品 void addProduct(Producer producer, ProductMessage product) throws PersonIdNotFoundException, EqualMessageIdException //发送广告 void sendAdvertisement(int productMessageId) throws MessageIdNotFoundException //show favour void addToFavourList(int customerId, ProductMessage product) throws PersonIdNotFoundException, EqualMessageIdException, MessageIdNotFoundException //购买产品 void buyProduction(int customerId, ProductMessage product) PersonIdNotFoundException, MessageIdNotFoundException //查询价格 int getProductValue(ProductMessage product) throws MessageIdNotFoundException
//生产产品JML /*@ public normal_behavior @requires contains(producer.getId()) && !containsMessage(product.getId()); @assignable products; @ensures products.length = \old(products.length) + 1; @ensuers (\forall int i; 0 <= i && i < \old(products.length); @ (\exists int j; 0 <= j && j < products.length; @ products[j] == (\old(products[i])))); @ ensures (\exists int i; 0 <= i && i < products.length; @ products[i] == product); @ also @ public exceptional_behavior @ signals (PersonIdNotFoundException e) !contains(producer.getId()); @ signals (EqualMessageIdException e) containsMessage(product.getId()); @*/ void addProduct(Producer producer, ProductMessage product) throws PersonIdNotFoundException, EqualMessageIdException
//询问销售额的JML /*@ public normal_behavior @ requires containsProductId(product.getId()); @ ensures \result == products(product.getId()).getvalue(); @ also @ public exceptional_behavior @ signals (ProductNotFoundException e) !containsProduct(product.getId()); @*/ int getProductValue(ProductMessage product) throws MessageIdNotFoundException /*@ public normal_behavior @ requires containsMessage(prductMessageId) && (getMessage(prductMessageId) instanceof Advertisement); @ assignable messages; @ assignable people[*].messages; @ ensures (\forall int i; 0 <= i && i < people.length && getMessage(prductMessageId).getPerson1().isLinked(people[i]); @ (\forall int j; 0 <= j && j < \old(people[i].getMessages().size()); @ people[i].getMessages().get(j+1) == \old(people[i].getMessages().get(j))) && @ people[i].getMessages().get(0).equals(\old(getMessage(id))) && @ people[i].getMessages().size() == \old(people[i].getMessages().size()) + 1); @ ensures !containsMessage(prductMessageId) && messages.length == \old(messages.length) - 1 @ ensuers (\forall int i; 0 <= i && i < \old(messages.length) && \old(messages[i].getId()) != id; @ (\exists int j; 0 <= j && j < messages.length; messages[j].equals(\old(messages[i])))); @ ensures (\forall int i; 0 <= i && i < people.length && !getMessage(prductMessageId).getPerson1().isLinked(people[i]); @ people[i].getMessages().equals(\old(people[i].getMessages())); @ also @ public exceptional_behavior @ signals (MessageIdNotFoundException e) !containsMessage(prductMessageId); @*/ void sendAdvertisement(int prductMessageId) throws MessageIdNotFoundException
六、学习体会
本单元相较于前两个单元难度降低,主要学习JML规格化表示以及基于规格的实现方式,并在完成任务的过程中复习了数据结构中图论的相关算法。对JML的理解需要站在代码整体的角度去理解语义,结合实际的需求(并重点注意规格中括号的范围),进而理解程序的功能,才能正确的实现,进而优化算法。
虽然三次作业难度都不大,迭代开发也较为容易,但是除去理解JML语义和实现规格之外,一个重点的部分就是对于程序性能的优化。三次作业对复杂度的要求均比较高,容易出现超时的bug。
