

大数据技术
大数据技术
大数据主要涉及到数据的采集、存储、计算和分析、以及管理调度。
数据的采集
数据存储
数据管理调度
数据计算和分析
大数据技术涉及:数据的采集、预处理、和分布式存储、以及数据仓库、机器学习、并行计算和可视化等方面。
对于大数据技术,应用广泛的是以hadoop和spark为核心的生态系统。hadoop提供一个稳定的共享存储和分析系统,存储由hdfs实现,分析由mapreduce实现, 。
hadoop子项目
1、hdfs:Hadoop分布式文件系统,运行与大型商用机集群
hdfs是gfs的开源实现,,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。
2、hbase:分布式的列存储数据库。hbase将hdfs作为底层存储,同时支持mapreduce的批量计算和点查询(随机读取)
hbase是一个建立在hdfs之上,面向列的nosql数据库。它可用于快速读写大量数据,是一个高可靠、高并发读写、高性能、面向列、可伸缩和易构建的分布式存储系统。hbase具有海量数据存储、快速随机访问和大量写操作等特点。
在kudu出现之前,hadoop生态环境的存储主要依赖hdfs和hbase。在追求高吞吐、批处理的场景中,使用hdfs,在追求低延时且随机读取的场景中,使用hbase,而kudu正好能兼容这两者。
3、批处理计算的基石:mapreduce
批处理计算主要解决大规模数据的批量处理问题,是日常数据分析中常见的一类数据处理需求。业界常用的大数据批处理框架有mapreduce\spark\tez\pig等。其中mapdeduce是比较有影响力和代表性的大数据批处理计算框架。它可以并发执行大规模数据处理任务,即用于大规模数据集(大于1tb)的并行计算。mapreduce的核心思想:将一个大数据集拆分成多个小数据集,然后在多台机器上并行处理。
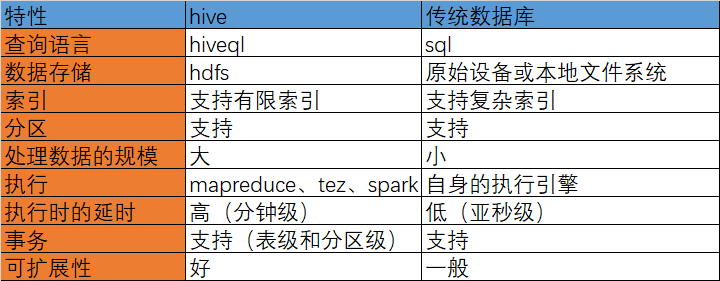
4、hive:分布式数据仓库,管理hdfs中存储的数据,并提供基于sql的查询语言用于查询数据
hive是一个构建在hadoop之上的数据仓库工具,在某种程度上可以把它看做成用户编程接口,本身并不存储和处理数据(它依赖hdfs存储数据,依赖mapreduce等模型框架处理数据)。hive定义了简单的类似sql的查询语言-hiveql.当将madreduce作为执行引擎时,通过hiveql语句可以快速完成简单的mapreduce任务。因此,hiveql适合进行数据仓库的统计分析。
hive与传统数据库的区别
5、zookeeper
zookeeper是hadoop的一个子项,用来管理hadoop、hive、pig等,zookeeper是开源的分布式协调服务组件,提供高可用、高性能和稳定的分布式数据一致性解决方案。
zookeeper对分布式数据的一致性提供全面的支持,具体包括以下5个特性。顺序一致性、原子性、单一性、可靠性、实时性。
大数据技术的意义
不在于账务规模庞大的数据信息,而在与对这些数据进行智能处理,从中分析挖掘有价值的信息。
大数据采集:保证采集数据的可靠性和数据采集的高效性,要避免数据重复
大数据计算:主要完成海量数据的并行处理,分析挖掘等面向业务的任务。大数据计算主要涉及批处理框架、流处理框架、交互式分析框架和图计算等
大数据测试技术
需要掌握:大数据测试方法论,大数据测试工具、大数据测试技能。
在大数据项目测试的测试流程中,通常涉及到数据库测试、基准测试、性能测试和功能测试等,定制清洗的大数据测试策略和计划有助于项目的成功交付



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本