

学习参考:050-distinct关键字_哔哩哔哩_bilibili
本文仅用于强化学习记忆,如果需要系统学习点击链接跟随视频学习;
- 查询去重: distinct关键字:
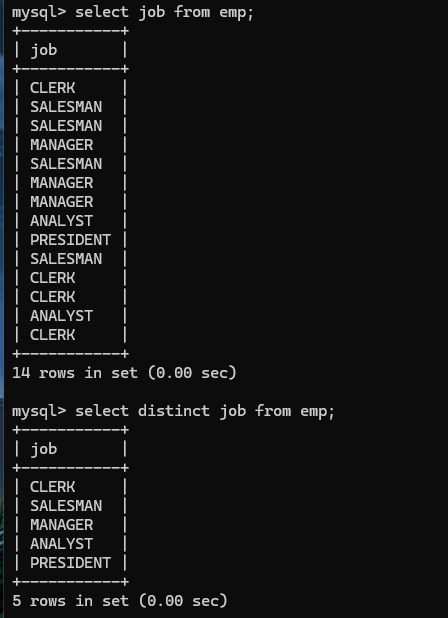
注意:distinct只能使用在所有字段前面,不能使用在中间。
但是如果使用在多个字段前,就代表联合的字段去重
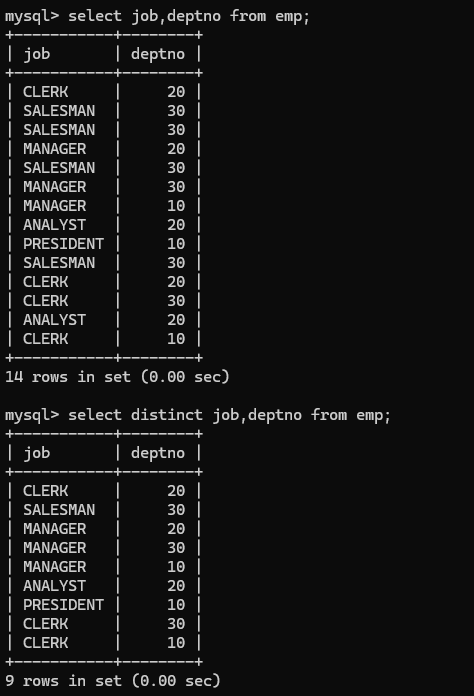
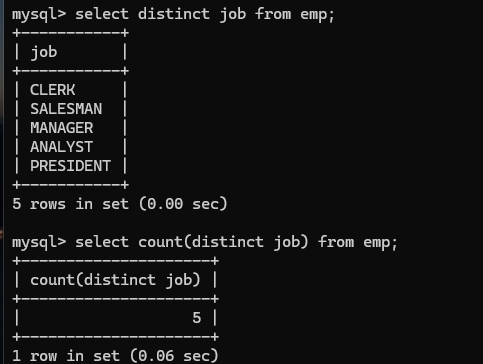
统计工作岗位数量:
- 连接查询:
从一张表中单独查询,叫做单表查询;
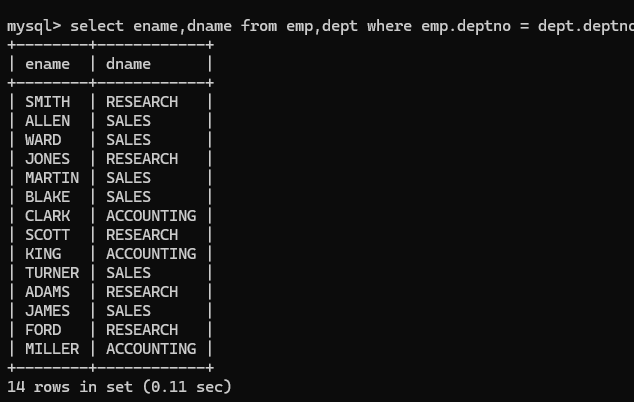
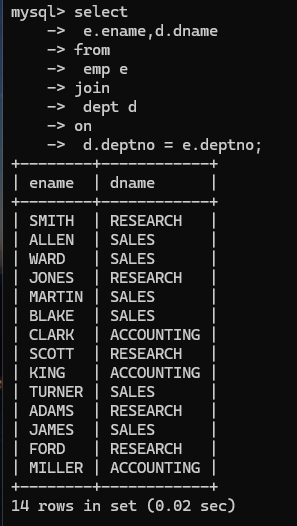
emp和dept表中联合起来查数据,从emp表中取员工姓名,从dept表中取部门名。
这种跨表查询,多张表联合起来查询的数据,就叫连接查询
-
-
-
- 根据表连接的方式分类:
- 内连接:
- 等值连接
- 非等值连接
- 自连接
- 外连接
- 左外连接(左连接)
- 右外连接(右连接)
- 全连接
- 内连接:
- 根据表连接的方式分类:
-
-
- 内连接之等值连接:对于两张表进行直接的连接查询,其结果是表一的行数乘以表二的行数,每个数据都会配对一遍,太长就不进行展示了。这种现象被称为笛卡尔积现象,从笛卡尔积这种情况来看可以得出表的连接情况越多,效率越低下
- 消除这种笛卡尔积的办法:
- 使用条件进行过滤: (虽然能进行过滤最后得到需要的显示结果,但是运行过程还是按照一行一行进行匹配效率低下),下面是sql92的语法。 相较于sql99的语法,其结构不清晰,表连接条件与后期筛选条件都放在where后面
- sql99的语法:使用 select ... from 表1 join 表2 on 表1和表2的连接条件;其优点:表的连接条件是独立的,连接之后如果需要进一步筛选,再往后添加where条件筛选就行
- 使用条件进行过滤: (虽然能进行过滤最后得到需要的显示结果,但是运行过程还是按照一行一行进行匹配效率低下),下面是sql92的语法。 相较于sql99的语法,其结构不清晰,表连接条件与后期筛选条件都放在where后面
- 消除这种笛卡尔积的办法:
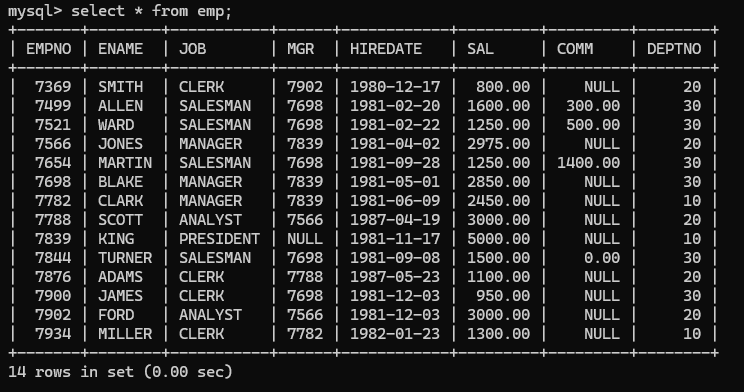
- 内连接之非等值连接:查询员工的姓名薪资和薪资等级:这里面涉及两张表慢慢进行分析:下面是表emp,其中存在员工的姓名,薪资,起个别名e表示这张表,要从表e中查找ename,和sal,也就是e.ename,e.sal
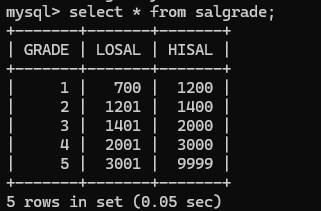
这张表右我们所要查找的薪资等级水平,给这个表起别名为s,我们所需要查找的就是s.grade,当然还有这两张表连接的条件,也就是e.sal要再s.losal和s.hisal之间:
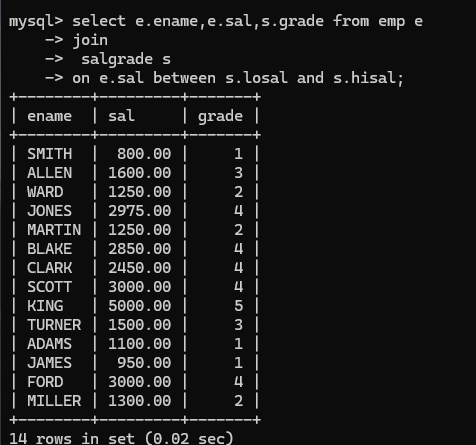
这样慢慢进行分析就完成了一次表内连接的非等值连接:
- 内连接中的自连接:如果需要找出员工的上级领导名字,顺带显示自己的名字,但是他们都出现在同一张表中,也很简单,直接将一张表看成两张表,起两个别名就行,一张员工表,一张领导表,其连接条件就是,员工表中的领导编号,等于领导表中的领导编号就行:但是这里只会出现13条查询记录,因为其中有个人没有上级领导,是NULL,就给过滤了
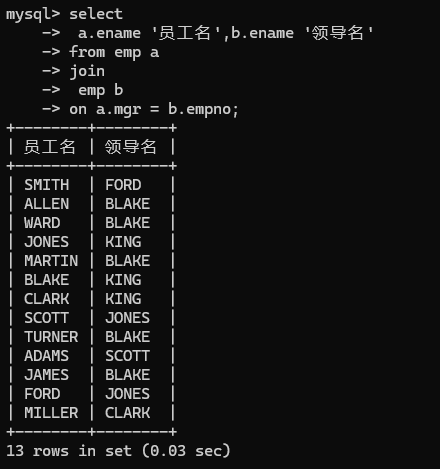
- 外连接(右外连接):eg:将员工姓名和所在部门名字显示出来,要求要显示所有部门即使表中没有员工。这个和上面的自连接看起来没什么区别,但是存在一个主次之分,这里使用的是右外连接就是以右表为主要查询目标捎带查询左表。所有要将右表查询的内容全部查出,左表有没有不影响,补个null就行。如果是内连接两张表都是平等的,如果说查到不符合的没有就不显示了,不会单一以某个表为主
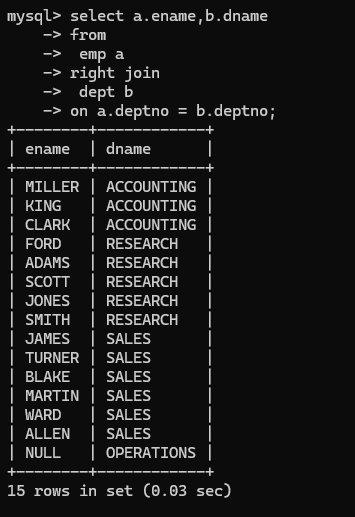
外连接的左连接也是相同的意思。
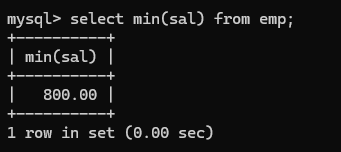
- 多表连接:其实和两表连接差不多,就是在基础上再添加join on,其中一条sql语句中是可以存在内连接和外连接混合使用的 语法格式:select ... from ... join ... on ... join ... on right join on ...;就行了。 子查询:就是在select中嵌套select,被嵌套的select 就叫子查询:格式存在: select ...(select)... from ...(select)... where ...(select)... eg:找出比最低薪资高的员工姓名和薪资:不是很清楚的时候可以分步进行:
- 先找出最低员工薪资
-
找出员工的姓名和薪资大于800的(最低薪资)
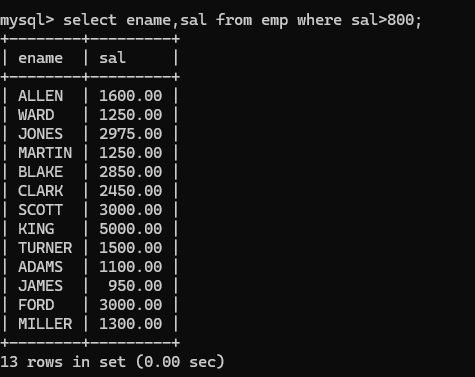
- 再将800替换:
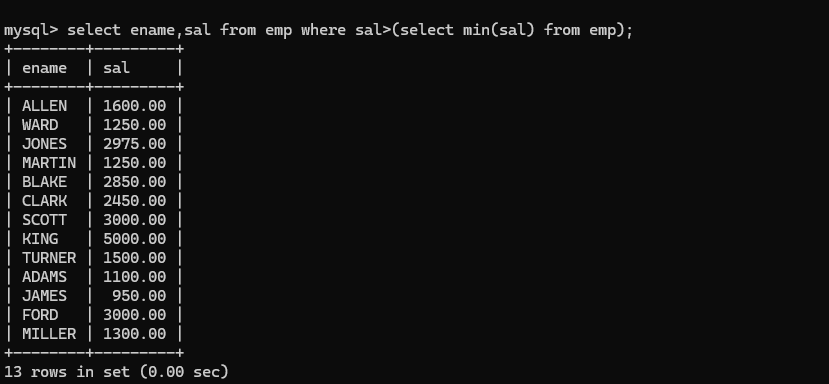
以上就是一个where的子查询
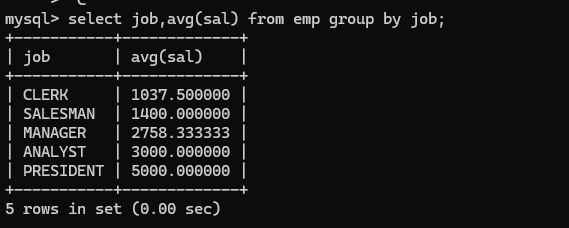
在from中的子查询:找出每个岗位的平均工资的薪资等级。 不清楚的话还是先分步进行
-
- 第一步找出每个岗位的平均薪资: 将这个表当作一个新表,从这个新表中和salgrade表进行连接,并且其中的avg(sal)需要一个别名否则会嵌套执行
-
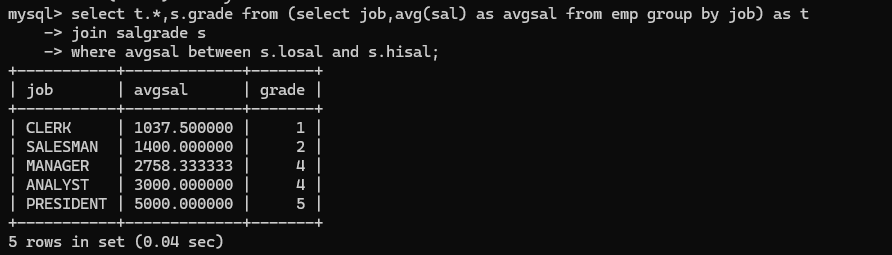
- 第一步找出每个岗位的平均薪资: 将这个表当作一个新表,从这个新表中和salgrade表进行连接,并且其中的avg(sal)需要一个别名否则会嵌套执行
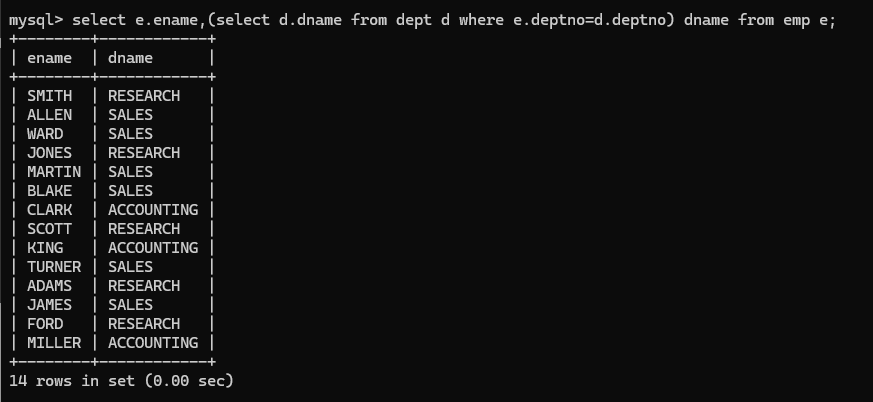
- select 后面出现子查询语句:eg:显示每个员工的名字以及部门名字:
-
- union合并查询结果集:eg查询工作岗位是manager和salesman的员工
- 使用where条件查询 or或者in都可以直接实现
- 也可以使用union进行合并处理
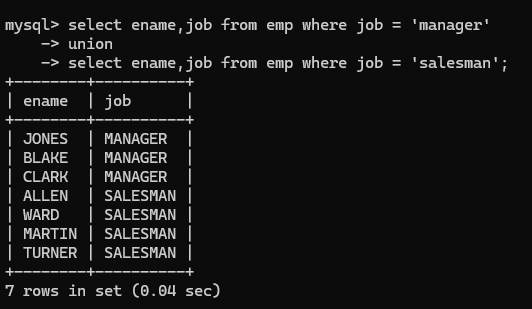
union的效率在表连接中会更高;对于表的连接来说每连接一次新表,则匹配次数满足笛卡儿积,成倍的翻,但是union可以减少匹配的次数,同时进行表的连接
limit 作用:将结果集中的一部分取出来。通常使用在分页查询当中,百度默认:一页显示10条记录。分页可以提高用户体验,一次性查出来不太好看,一页页翻信息量没这么大。完整用法(下标从0开始计算):limit start_indx length;缺省用法limit length;
- eg:按照薪资降序取出前5的员工信息
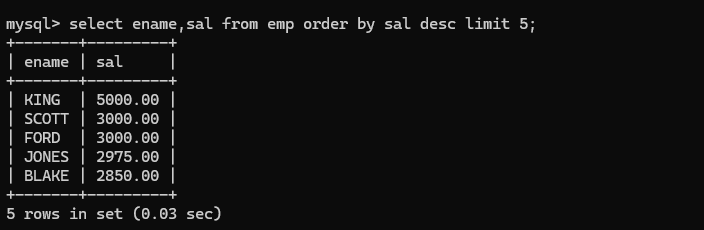
-
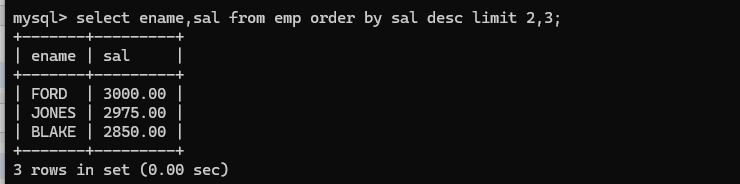
取出员工姓名,薪资,薪资降序在3到5之间的员工:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人