


本文仅用于强化学习记忆,具体学习请根据链接直接学习视频效果最好。
关于SQL语句的分类:
DQL:
数据查询语言,凡是带有select关键字的都是查询语言、
select...
DML:数据操作语言,凡是对表中数据进行增删改的都是DML
insert delete update
insert 增
delete 删
update 改
主要对表中的数据进行操作
DDL:
数据定义语言
凡是带有create , drop , alter ,的都是DDL
DDL是针对表的结构,不是表的数据
create 新建,相当于增
drop 删除
alter 修改
这里也相当于增删改,但是对比DML就可以知道,DML中的增删改(insert,delete,update)是针对具体表中数据,而DDL中的增删改(create,drop,alter)是针对表的结构进行操作。
TCL:
事务控制语言
包括事物提交:commit
事物回滚:rollback
DCL:
数据控制语言
eg:授权:grant,撤销权限:revoke....
常用命令:
查看表数据使用的语句为select,当你想查看表的结构使用的是desc + 表名;
mysql> desc salgrade;
+-------+------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------+------+-----+---------+-------+
| GRADE | int | YES | | NULL | |
| LOSAL | int | YES | | NULL | |
| HISAL | int | YES | | NULL | |
+-------+------+------+-----+---------+-------+
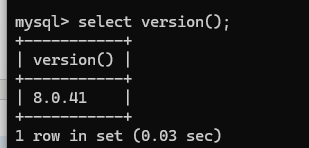
查看mysql版本号:
select version();
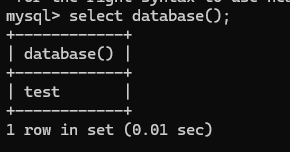
查看当前使用的是哪个数据库
select database();
简单查询:
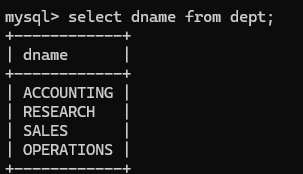
查询一个字段名:
select 字段名 from 表名;
其中要注意:
select和from都是关键字
字段名和标名都是标识符
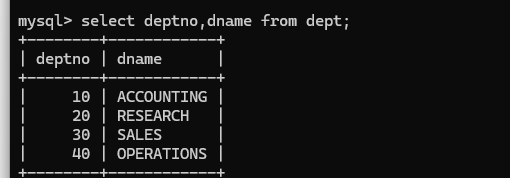
查询两个字段或者多个字段:
当使用两个或者多个字段使用逗号‘,’隔开即可
查询所有字段:
1)将所有字段名打出来当作多字段查询
2)使用*代替字段名:
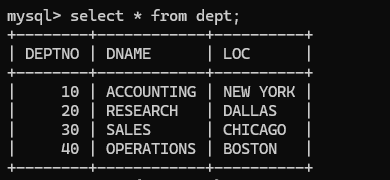
存在的缺点:1.效率低,程序是将*转换为所有字段再进行查询
2.可读性差,在实际开发中不建议使用
给查询的列起别名:
使用as关键字:
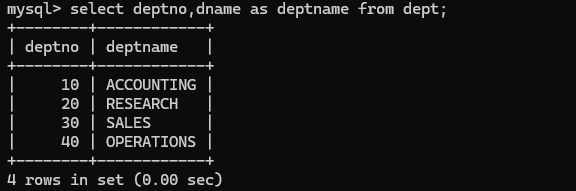
注意:只是将查询结果中的列名取为deptname,原来的表中不会发生改变
select 语句不会对原表发生修改,只起到查询操作
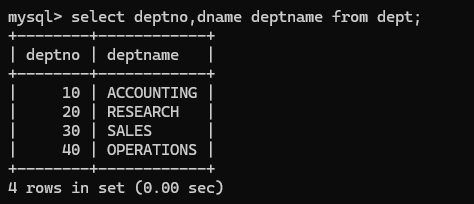
as关键字也是可以省略的,但是不要加上逗号: 效果不会改变
如果你取别名的时候别名是中间分开存在空格的例如上面deptname改为dept name,这个时候使用单引号或者双引号将这个别名括起来表示是一体就可以使用了, 'dept name';
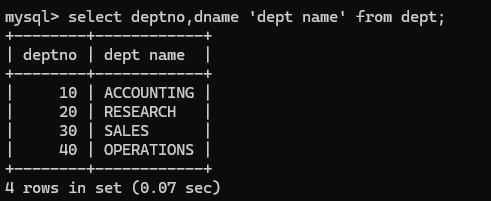
以上就是给一个字段取别名的方式,在这个例子中,你想给前面的deptno也取别名,就在前面加as 或者使用空格隔开

注意:在所有数据库中,字符串统一使用单引号括起来,单引号是标准,双引号在Oracle数据库中用不了,但是在Mysql中可以使用
计算员工年薪:
字段名是允许数学表达式运算的:
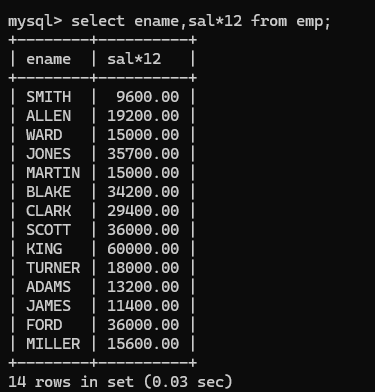
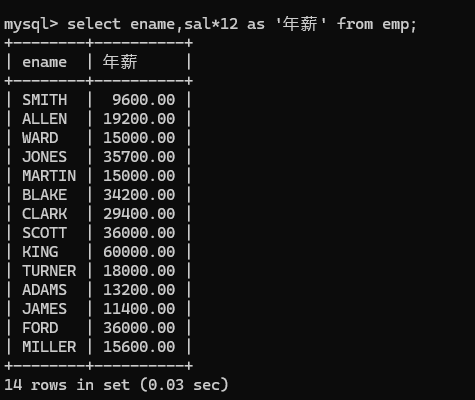
再起个别名:
使用中文记得用单引号阔起来
条件查询:
不是将表中所有数据都查出来,是查询符合条件的。
语法格式:
select
字段1,字段2,字段3,...
from
表名
where
条件;
查询条件
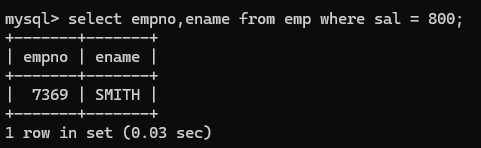
(1)‘=’ 如下例子,查询薪资800的员工编号和姓名
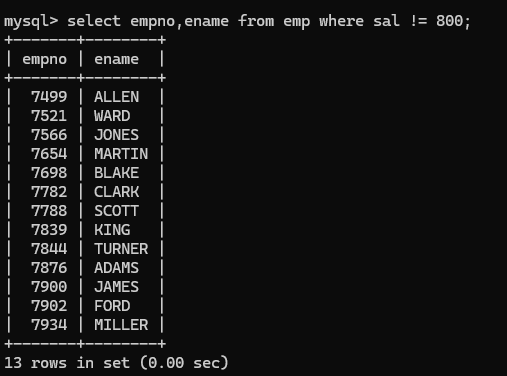
(2) <>或者!= 表示不等号,如下例子
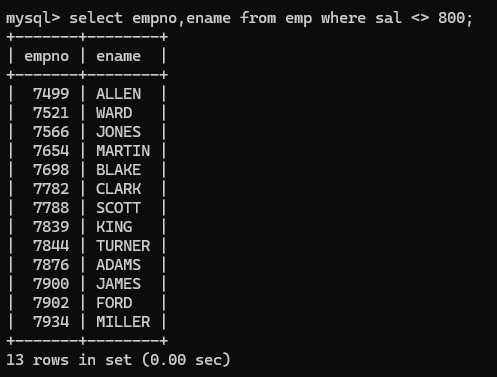
(3)‘<’ 查询薪资小于2000的员工姓名和编号
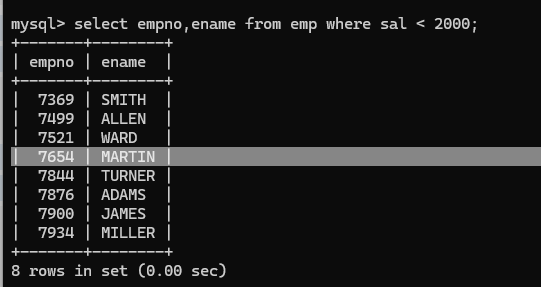
(4)‘<=’ 查询薪资小于等于3000的员工姓名和编号

(5) '>' 查询薪资大于3000的姓名,编号,薪水
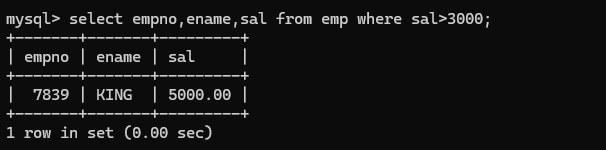
(6) ‘>=’ 查询大于等于3000的
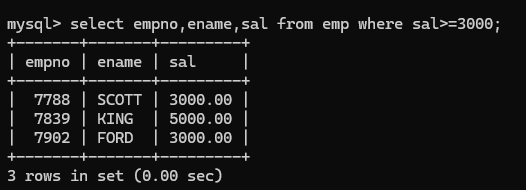
(7) between ... and ...,两个值之间,等同于>= and <=
可以使用>= and <=的方法直接表示
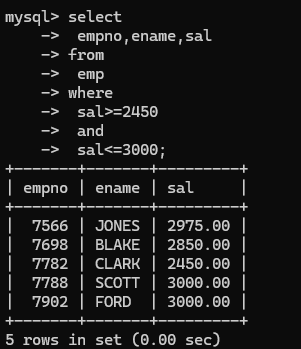
也可以使用between ... and ... 的方法直接表示,使用between ... and ... 必须遵循左小右大
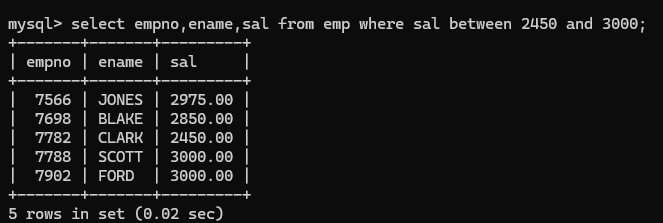
(8)is null 表示查询是空值,只能使用is null 不能使用=null
注意在数据库中null不能使用等号进行衡量,数据库中的null代表什么也没有,不是一个值,所以不能使用等号进行衡量
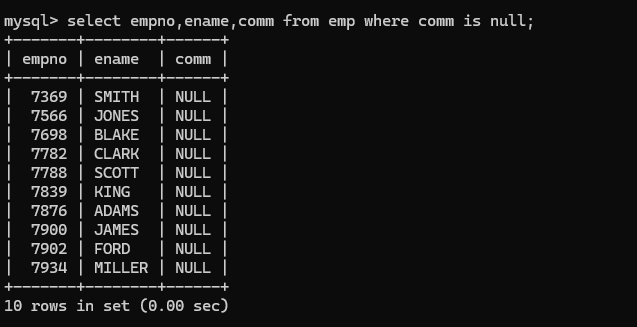
is not null 查询不为null
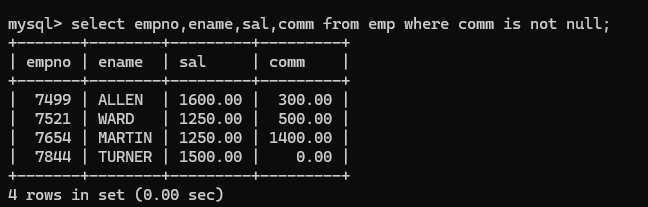
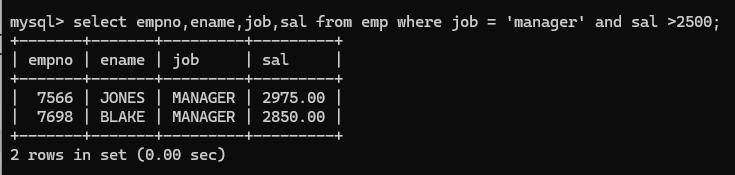
(9) and 表示并且,eg找出工作岗位是manage并且工资大于2500的员工信息
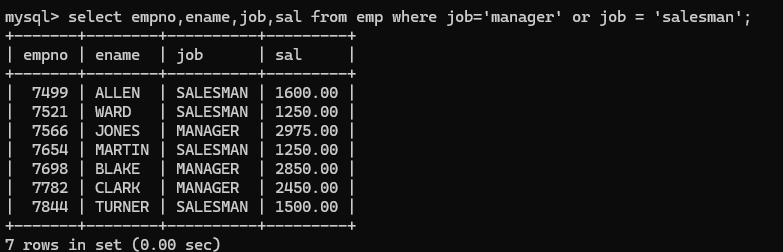
(10) or 表示或者,eg:找出工作岗位是manager或者salesman的员工信息
(11)and 与 or 优先级对比,and优先级高于or
如果你需要查询部门工资大于2500,并且编号为10或者20的员工;
select * from emp where sal > 2500 and empno = 10 or empno = 20;
根据and优先级大于or的方法来看,这种语句不是我们想要的,这个查询的结果应该是工资>2500并且编号为10的员工,或者编号为20的员工。
当需要进行这种低优先级的先进行执行,可以使用()将所需语句括起来表明先执行
select
*
from
emp
where
sal>2500 and (deptno=10 and deptno=20);

这样就符合我们所需要的需求了。
(12)in (not in), 表示一个查询范围,相当于多个or
假设查询工作岗位为manager和salesman的员工信息,in相当于多个or叠加
注意:in不是一个区间,是要一个具体的值
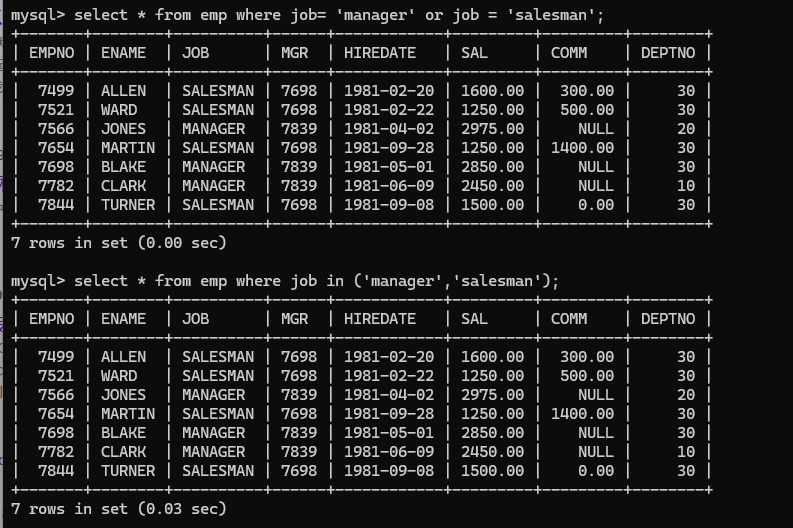
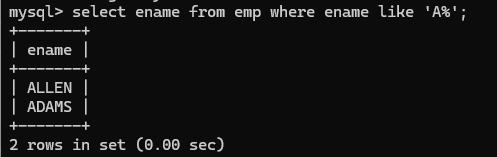
(13)like, 模糊查询,其中有关键字符, %,这个可以代表任意多个字符, _ ,下划线代表任意一个字符
找寻名字中含有O的:

当特殊情况,名字中含有下划线这些特殊符号的时候,使用转移字符 \ ,就可以正常查询

(14)order by , 排序
eg: 查找员工姓名薪资按照薪资从低到高排序,默认是升序
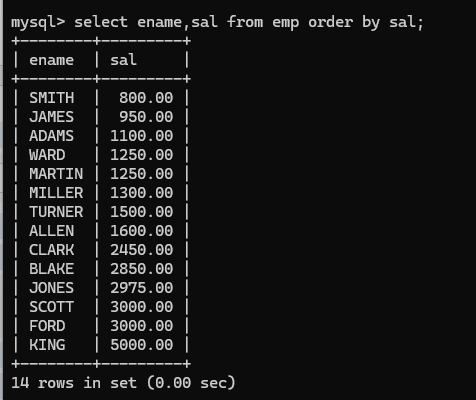
如果需要进行降序排列就要添加后缀desc
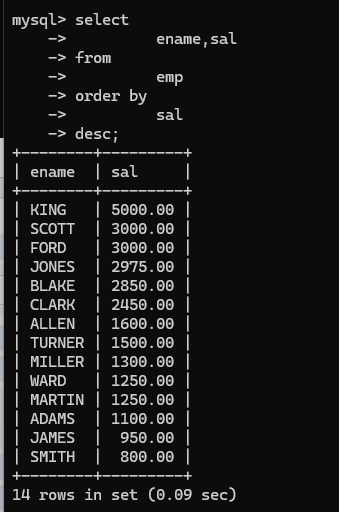
当要进行多字段排序的时候:先排薪资,再排名字, asc升序
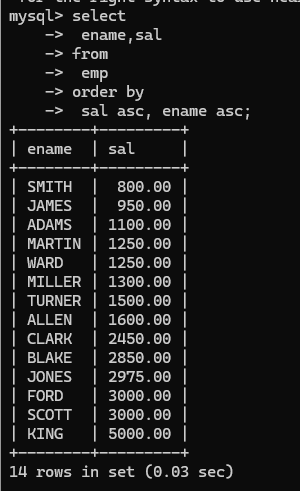
一种方便的方式直接从查询的字段中选择是第几列进行排序就行:

(15)数据处理函数:
单行处理函数:顾名思义,数据一行一行处理
特点:一个输入对应一个输出
与单行处理函数相对的是:多行处理函数(特点:多个输入对应一个输出)
常见的单行处理函数:
lower 转换小写
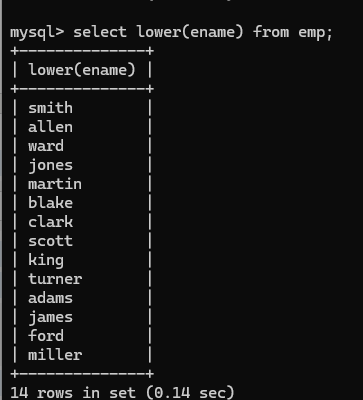
upper 转换大写
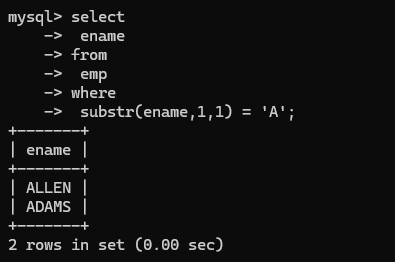
substr 取子串(substr(被截字符串,起始下标从1开始,截取长度))
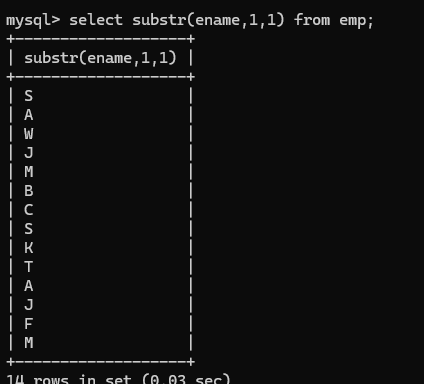
eg:如果找出名字第一个字母是A的员工名字方式:
1.模糊查询
2.字串函数查询
length 取长度
concat 字符串拼接
除了首字母大写外其他都小写进行字符串拼接:

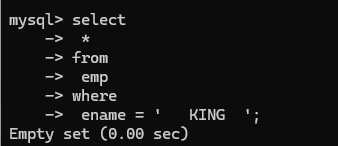
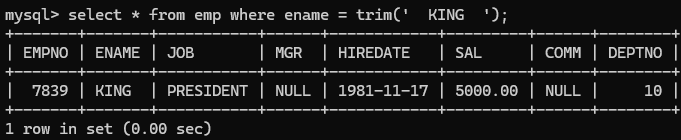
trim 去空格
eg:注意trim只是去空格,不要使用tab,tab不为空格
str_to_date 将字符串转换为日期
date_format 格式化日期
format 设置千分位
round 四舍五入
rand() 生成随机数,给的是小数,0.几的,如果需要大数可以乘以多少达到你所需要的位数,同时套用round四舍五入
ifnull 可以将null转换为一个具体值
在所有数据库中有NULL参与的数学运算结果均为NULL:
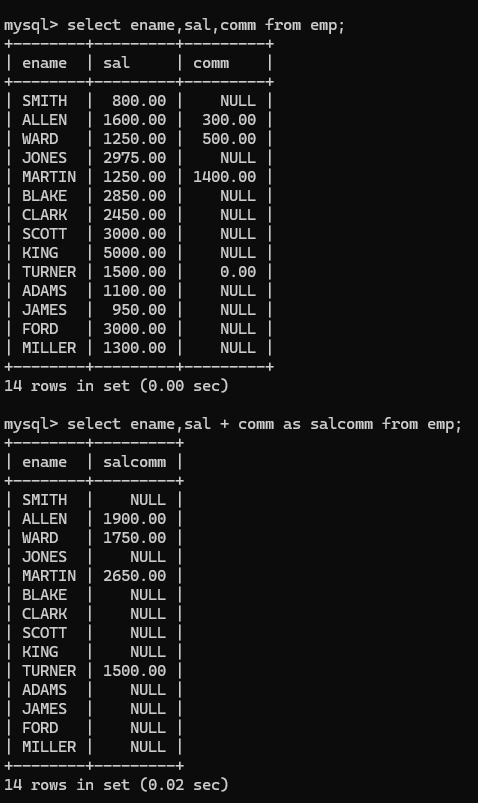
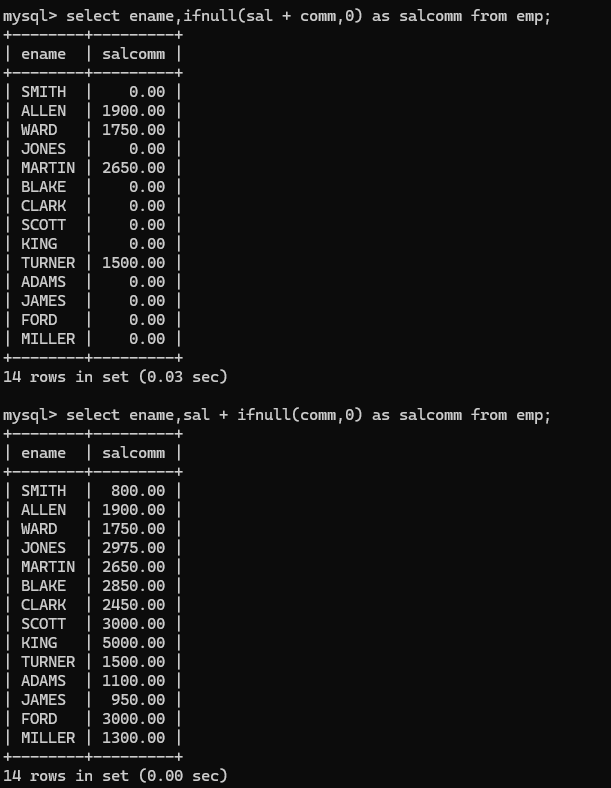
使用ifnull避免这个问题,但是要注意ifnull使用的位置,下面就有一种使用错误的情况
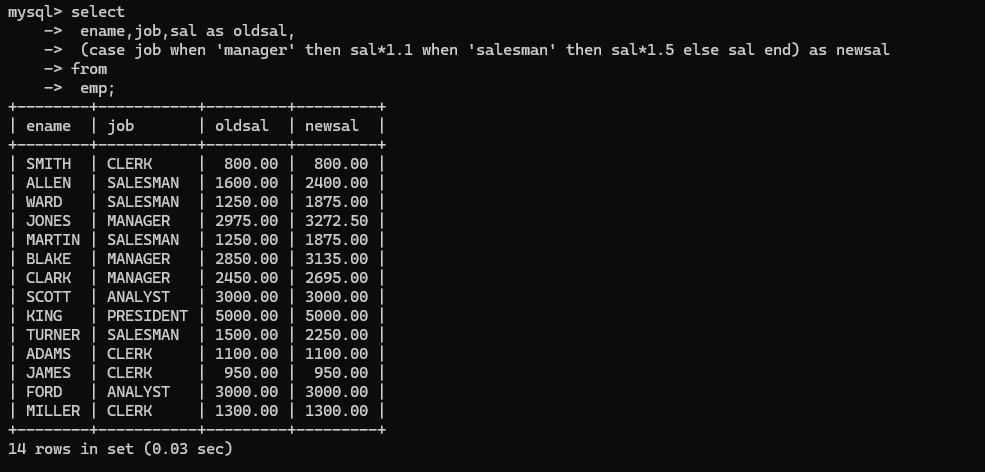
case ... when ... then ... when ...then ... else ... end
eg:当工作岗位是manager的时候新工资提升10%,当工作岗位是salesman的时候新工资提升50%;
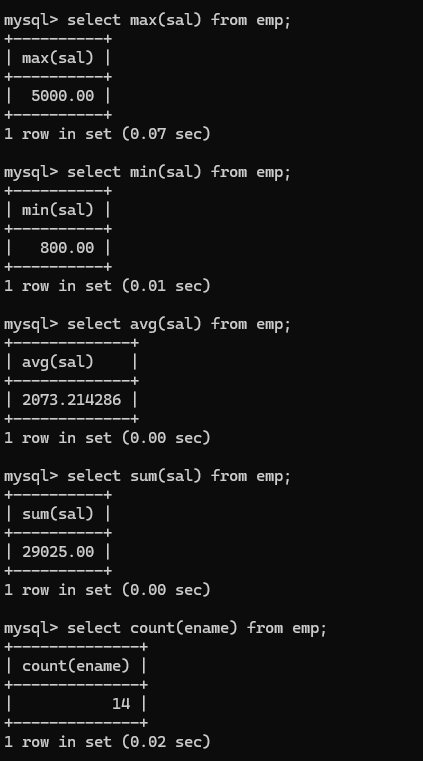
(16)分组函数(多行处理函数)
特点:输入多行,最终出来一行
注意:分组函数使用必须先分组,再使用
如果没分组,默认整张表是一组
5个:
count 计数
sum 求和
avg 平均
max 最大值
min 最小值
注意,分组函数不能使用在where语句中 eg:找出比最低工资高的员工
会显示错误

同时,所有的分组函数可以组合起来用

(17)分组查询:
在实际的应用中,可能有这样的需求,需要先分组,然后对每一组的数据进行操作
这个时候就需要使用分组查询,格式:
select
....
from
....
group by
...
将之前关键字全部组合在一起,来看看他们的查询执行顺序:
select
....
from
...
where
...
group by
...
order by
....
以上关键字不能颠倒,需要记忆。
执行顺序:
1.from
2.where
3.group by
4.select
5.order by
从表中进行选择,条件过滤,再分组,选择需要的列信息,再排序
从emp表中,根据工作分组,查询工作和其工资总和
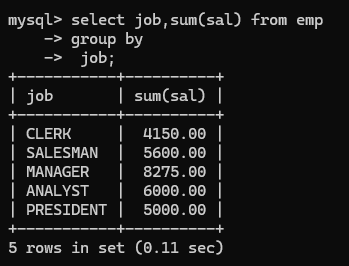
注意:在一条select语句中,如果有group by语句的话,select后面只能跟:参加分组的字段,以及分组函数,其他都不能跟。
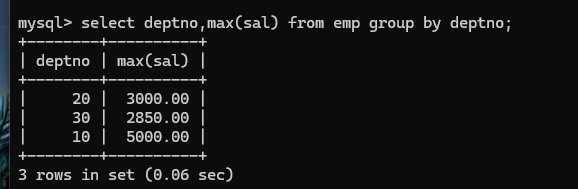
找出每个部门中的最高薪资:
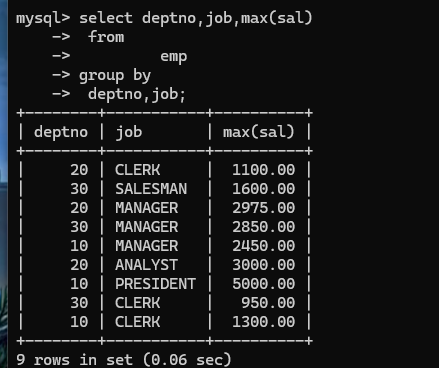
找出“每个部门中不同岗位的最高薪资”,这是相当于分组再分组:
技巧:两个字段联合成一个字段看。(两个字段联合分组),下面可以看成将deptno和job联合成一个字段deptno,job
(18) having 子句,作用类似于where,但是where是在分组前执行,having必须跟随group by 使用,执行在其后其作用是分组后再进行过滤:
eg:找出每个部门最高薪资,并且只有最高薪资大于3000才进行显示:

这种sql语句执行效率低,如果可能尽量在分组前进行过滤,不要分组后再进行子句过滤,上面那个例子可以直接用where过滤低于3000的再分组找最高
(19)大总结(单表查询):
格式顺序,不能颠倒:
select
....
from
...
where
..
group by
...
having
....
order by
...
执行顺序:
from ...
where ...
group by ...
having ...
select ...
order by ...
从某张表中,进行条件过滤,再分组,再组内进行过滤,选择需要查询显示的数据,进行排序。
eg:找出每个岗位平均薪资,要求显示平均薪资大于1500,并且工作不为manger的,要求按照平均薪资降序排:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本