

参考学习:
【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客
彻底搞懂了Transformer解码器(图文详解) - 知乎 (zhihu.com)
这样图解Transformer应该没人看不懂了吧——多头注意力机制详解_transformer 多头注意力机制-CSDN博客
本文目标是加强记忆,如果想具体学习点击链接参考学习。
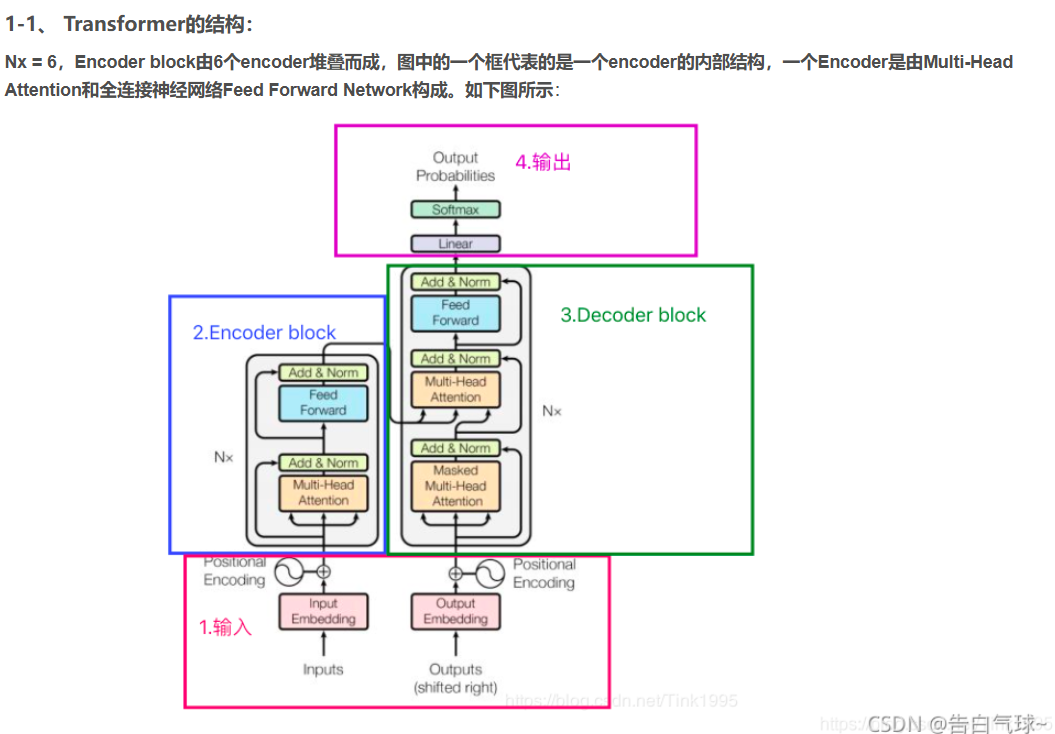
下图为Transformer模型结构:
下面是另一种简单的表示形式:
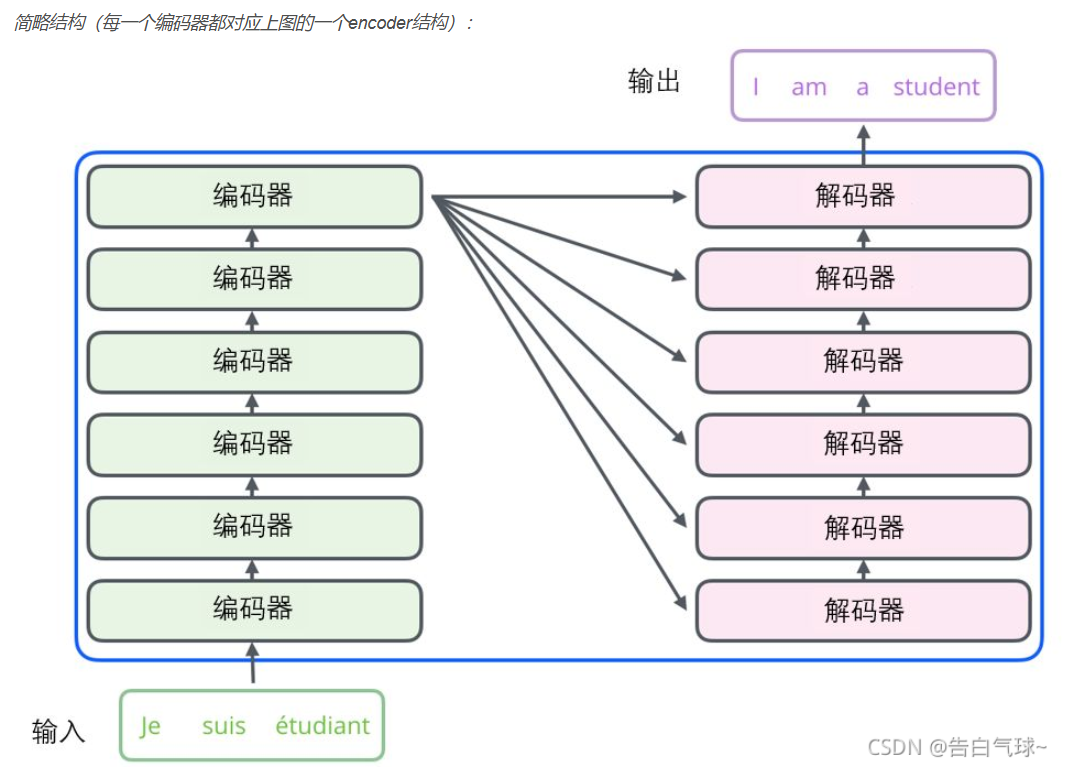
这样看在Transformer中主要部分其实就是编码器Encoder与解码器Decoder两个部分;
编码器:
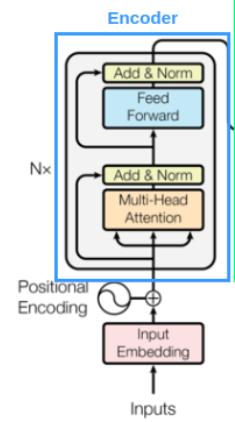
编码器部分是由多头注意力机制,残差链接,层归一化,前馈神经网络所构成。
先来了解一下多头注意力机制,多头注意力机制是由多个自注意力机制组合而成。
自注意力机制:
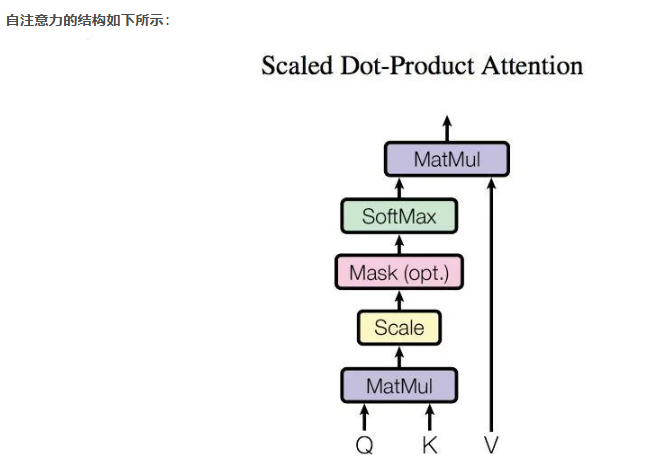
我们的输入是词嵌入向量与位置编码所结合而成的一种编码将其作为输入。
而自注意力机制中需要我们将输入的编码经过Wq,Wk,Wv权重进行线性代数运算后先得到的QKV的向量进行后面的处理。
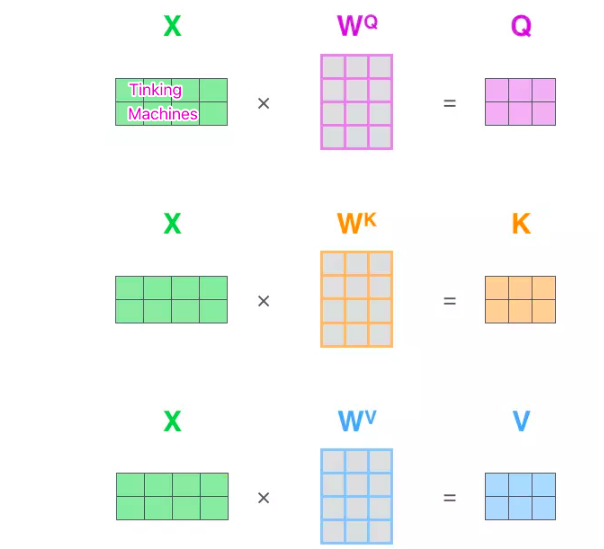
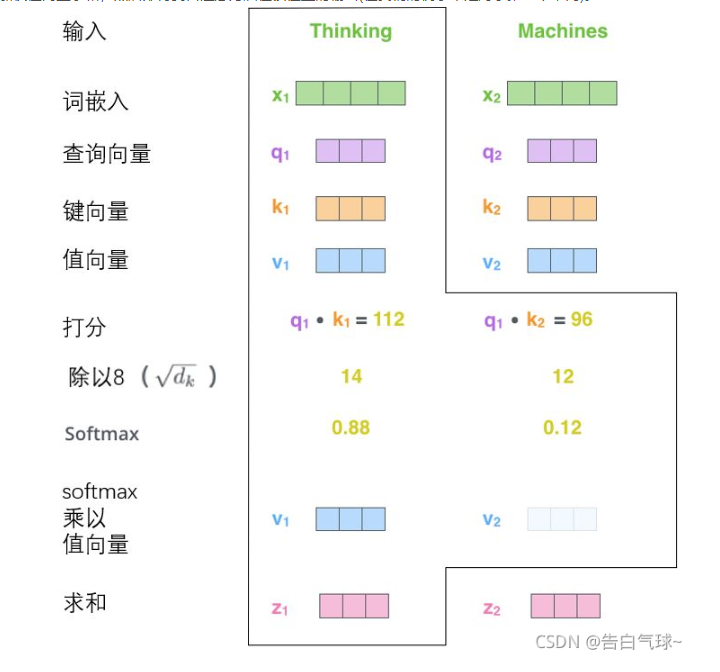
在算出每个词嵌入的QKV之后还要对其进行打分操作,具体方式就是选定一个词向量的Q与遍历一遍词向量与遍历的词向量的K相乘得出一个数值,再除以一个数值防止这个QK的乘积过大影响梯度更新稳定性,最后将所有的遍历值进行一次softmax操作,将所得到的数值控制在(0-1)范围之内,将这些打分权重与各个词向量的V进行相乘最后求和,得出这个词向量的z,也就是最终的目标值。
而多头注意力机制就是对输入进行多个并层的自注意力机制,最后将值拼接起来,通过一个W0的矩阵进行乘法,得到最后的结果维度要与输入的维度相同,与输入的数据进行一次相加也就是残差思想。
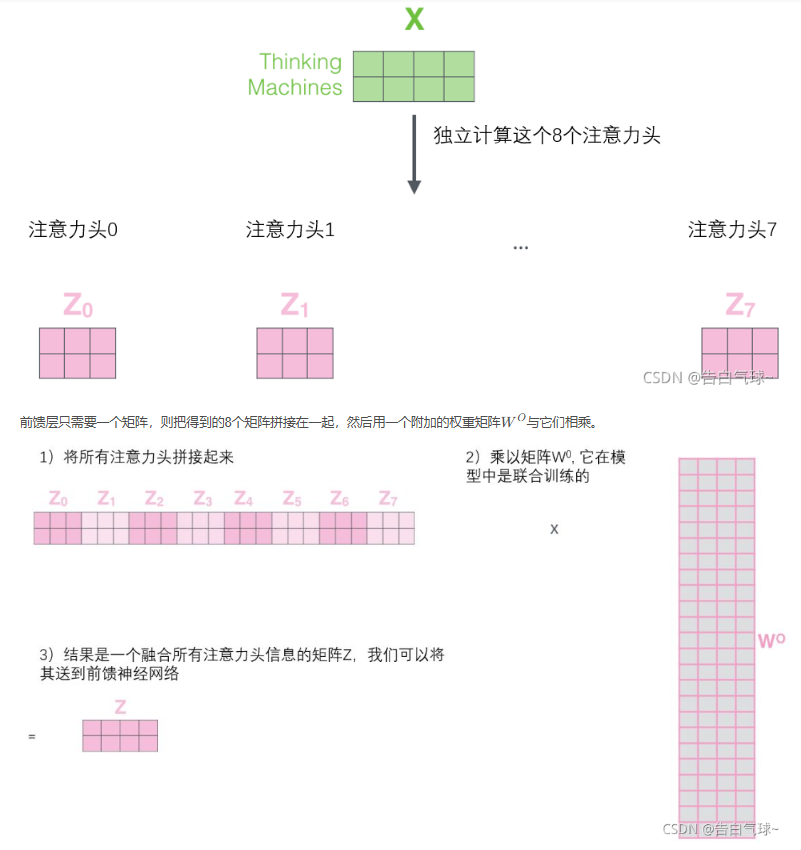
上面就是多头注意力机制的模块解析。
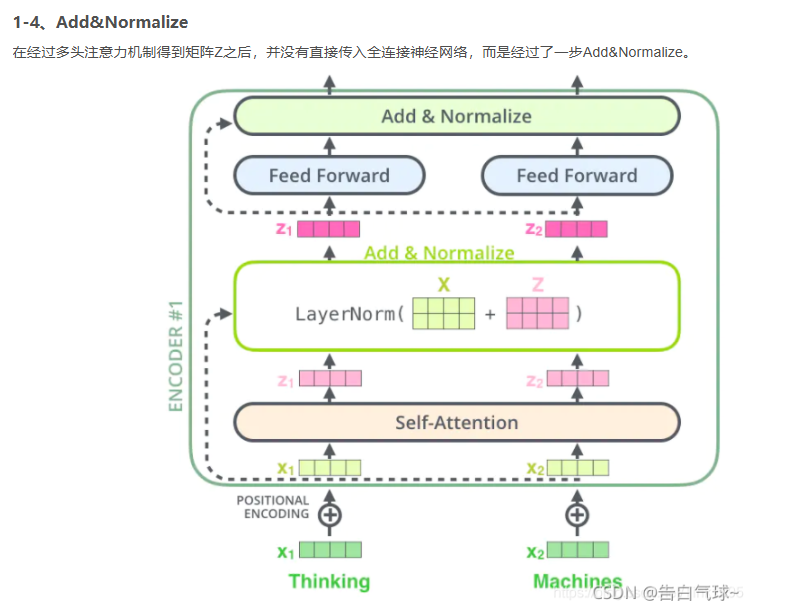
得到多头注意力机制的向量后再输送下一层前,进行了一次残差连接与层归一化操作再送往前馈神经网络进行处理。
前馈神经网络就很简单了:

解码器部分:
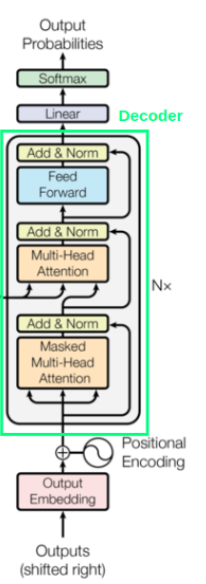
解码器结构与编码器类似,但是在处理解码器的第一个多头自注意力机制的时候进行了掩码操作,为了防止后续的词影响前面的词进行预测,防止他们之间产生关联影响训练:


在解码器第二个多头注意力机制模块使用编码器得到的结果与Wq,Wk进行矩阵乘法计算得到QK,V是使用解码器第一次多头自注意力计算得出的结果与Wv矩阵相乘得出。
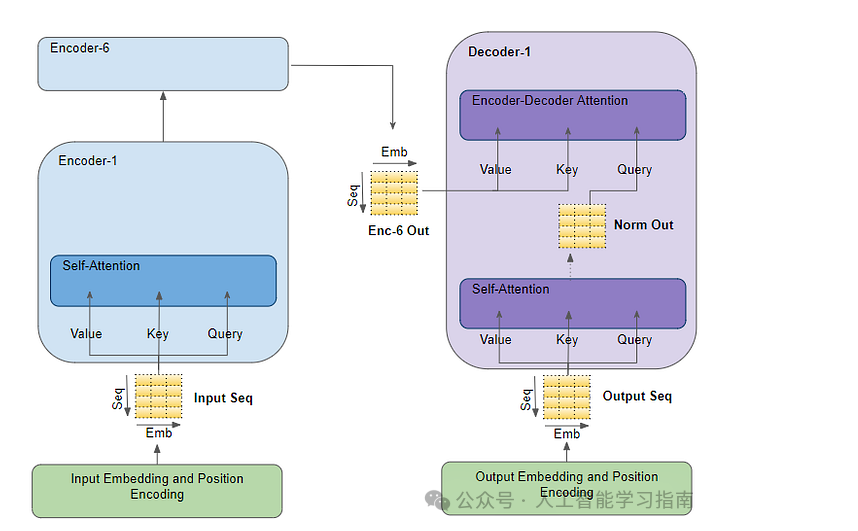
来看看编码器和解码器运行流程:
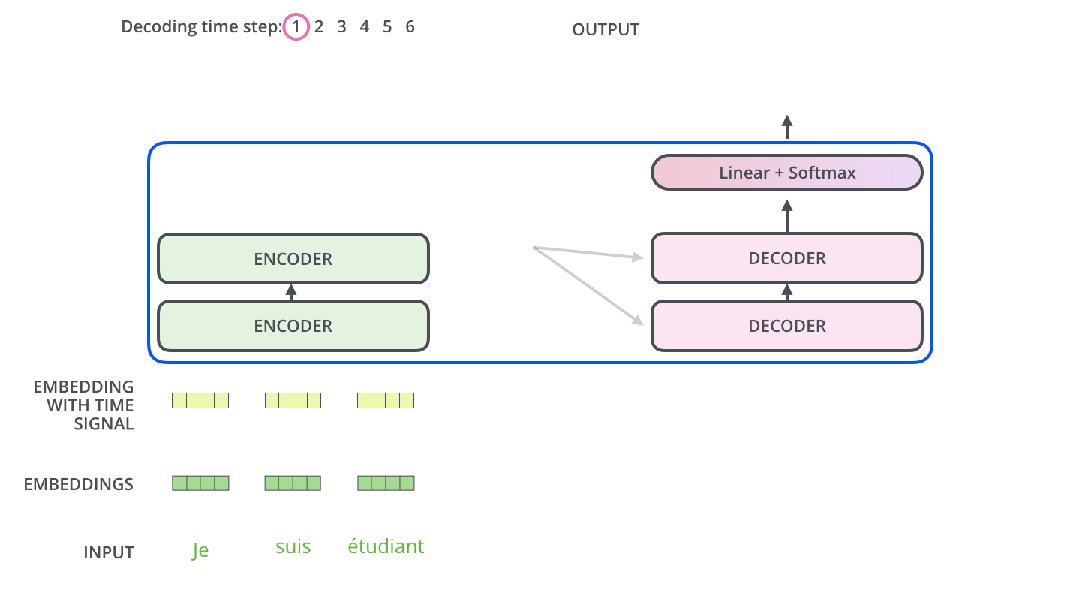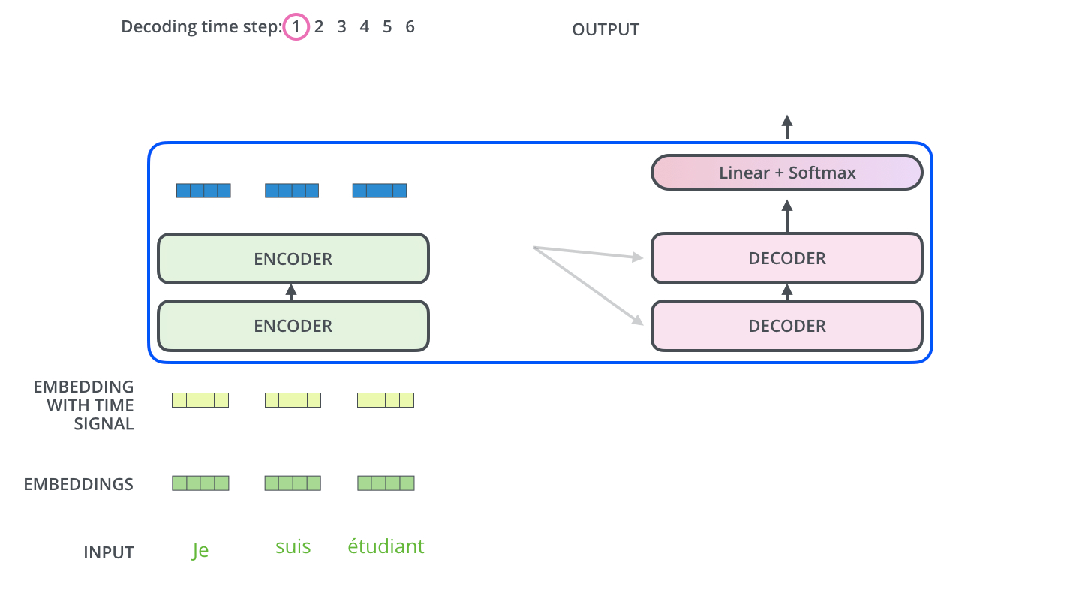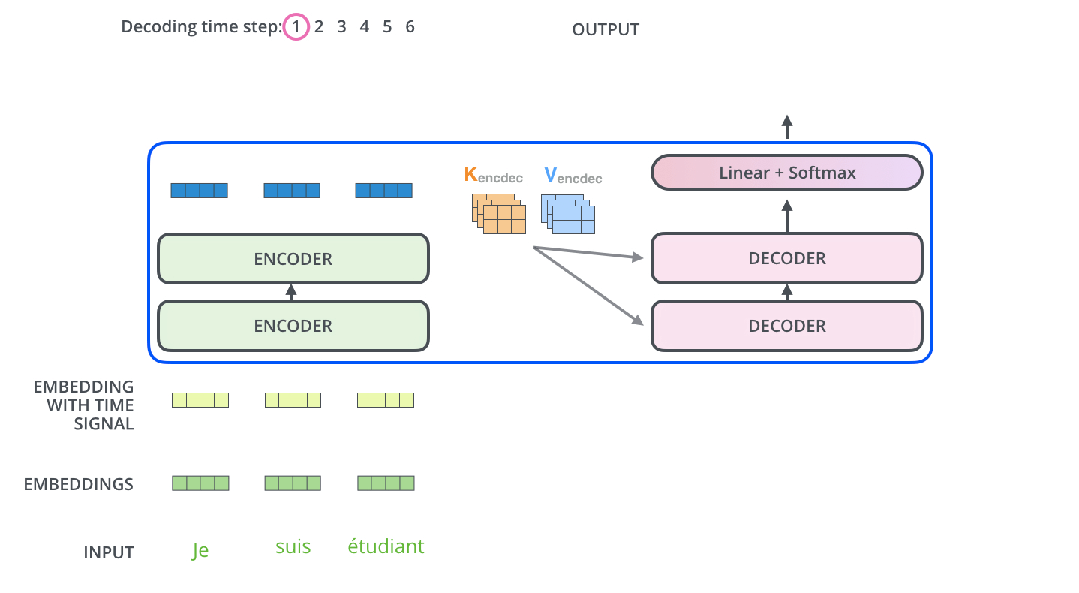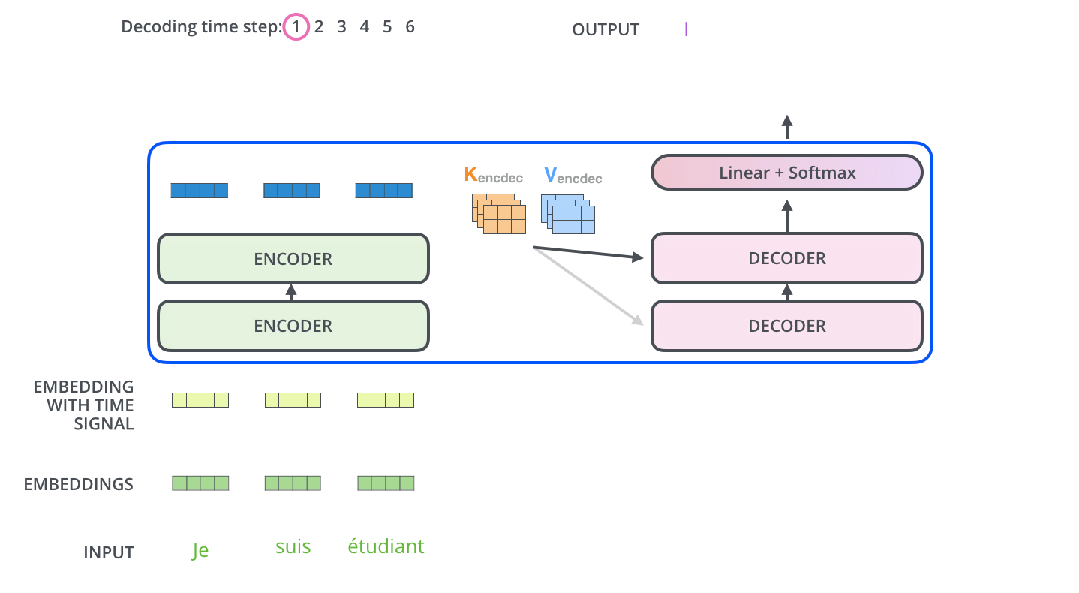
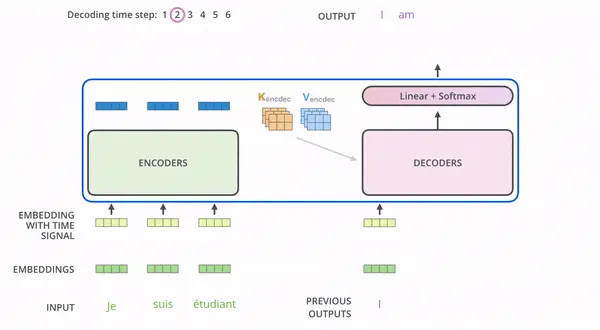
这样运行就很直观了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)