

- 先导入数据:
将要处理的文件数据导入x_train,y_train,x_valid,y_valid中,转换为张量。

使用PyTorch中的数据模块,将上面转换为张量的数据使用TensorDataset函数转换为数据集。
之后使用DataLoader来加载数据集,DataLoader包相当于一个派发器的感觉。

下方也是一个导入数据示例但是这是直接从PyTorch中的包含的datasets包中下载的数据并读取转换为张量,再放入加载器中,batch_size就是mini-batch操作每一批迭代取多少个数据。shuffle是随机加载的意思。

在数据规模小的情况下对模型进行数据增强:
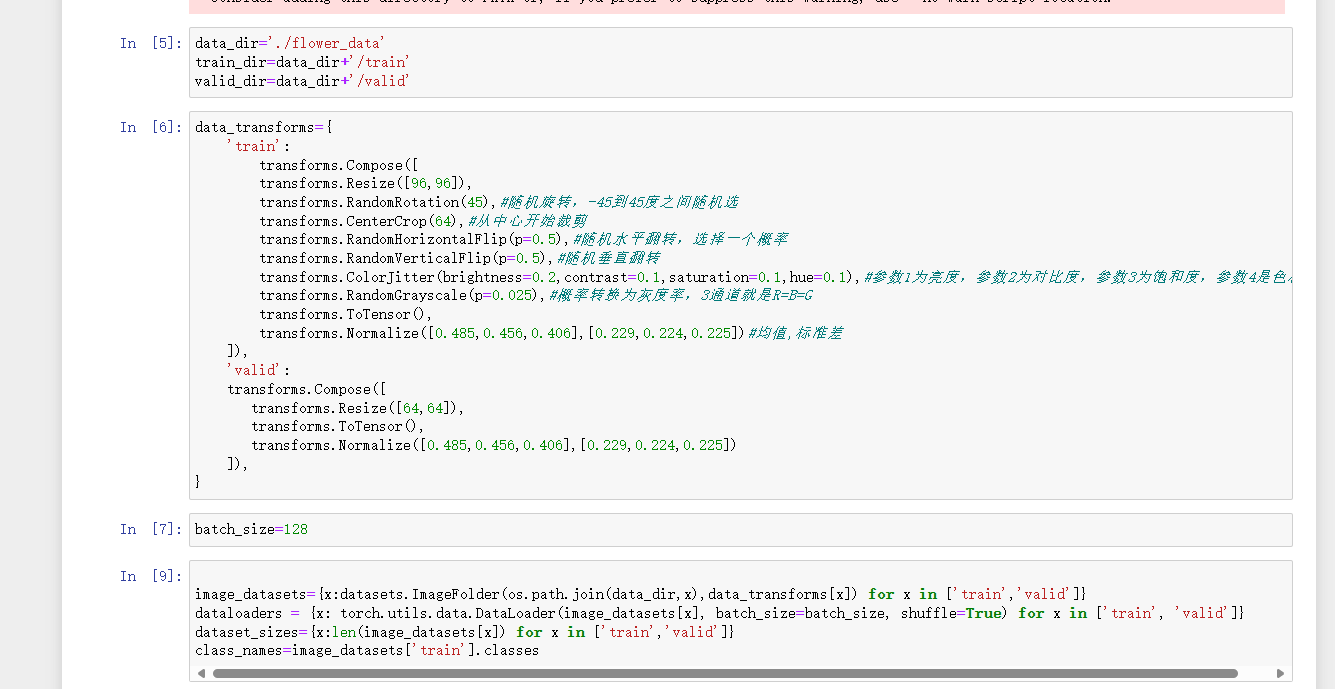
上面说的都是分开的,在实际中书写导入数据也是建议写在一个类中,如下图所示:

那个数据增强那些预处理放入getitem()中就好了,最后返回图像和标签。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人