

参考学习:
日月光华 ---------python 数据分析 深度学习
写本文不是为了提供学习参考,主要目的是为了加强记忆,如需学习建议去到上述参考资料自行搜索学习;
上节记载了Series的入门操作,还提及了pandas库另外一个数据结构 DataFrame
这个数据结构有点像列表:
下面是一种DataFrame的创建格式:
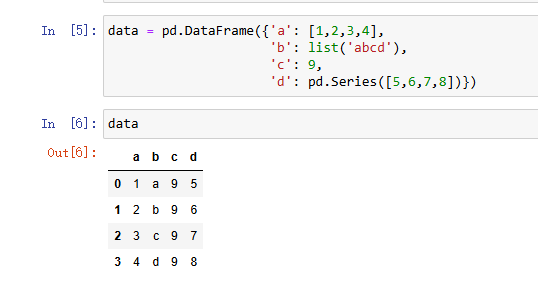
可以看见它存储生成的是表,自动生成了一个行索引(index)从0-3;
我们可以使用它的列(columns)索引进行操作

当然也可以使用它的行row索引,但是它对行索引有点像键就是上文提及的index操作类似

我们也可以自定义它的行index与列columns索引:具体的做法就是自己设定相应多个index与columns然后传入创建函数中使用
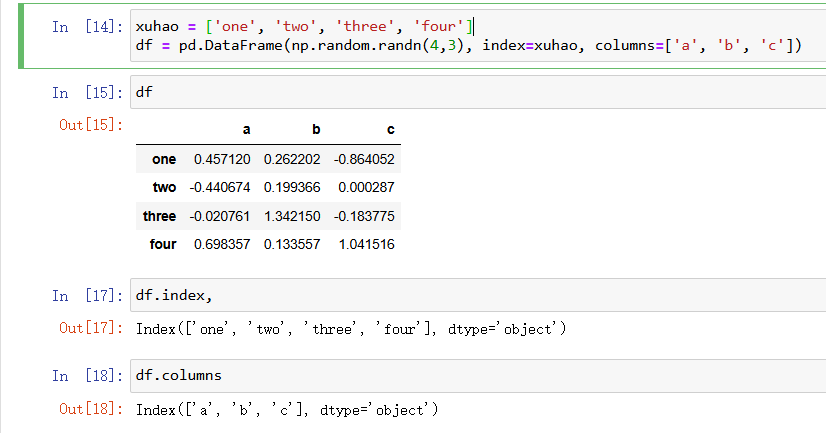
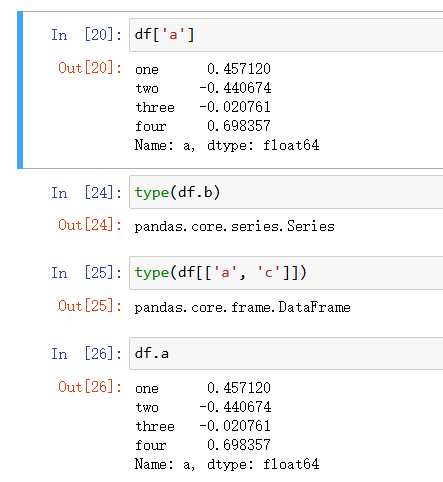
上面通过自定义定义了行索引与列索引,那么我们可以直接调用相应索引来查看相应的行或者列:
下图也可以看出一个单独的列是Series类型的,所以感觉可以理解为DataFrame类型是由Series类型组成,只是在Series类型上多增加了键或者说多增加了一个维度;如果同时查看DataFrame中的多列返回的类型也是DataFrame的;
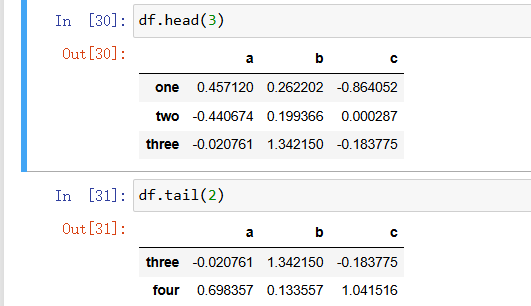
可以通过head(+num)与tail(+num)函数查看前面几行总表数据或者后面几行总表数据:
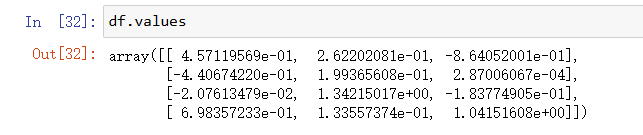
我们也可以直接显示DataFrame中记载的数据:
使用values
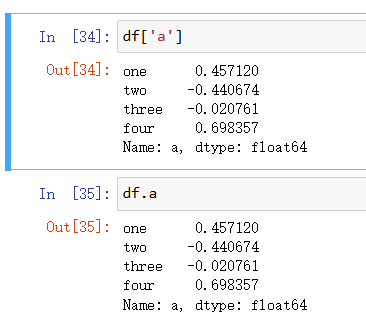
对于其中列的索引存在两种方式,两种索引其结果都是相同的:
也可以同时对多个列进行索引,返回的类型是DataFrame的:

上述都是对列columns的进行索引显示的情况,之前还提及了可以使用行row进行索引,但是这里要使用一个函数loc,同时还可以使用行索引与列索引一同进行处理索引特定的行与列,前面放置的是要索引的行,后面放置的是要索引的列,如果只有一个数据,那么默认索引全部列:
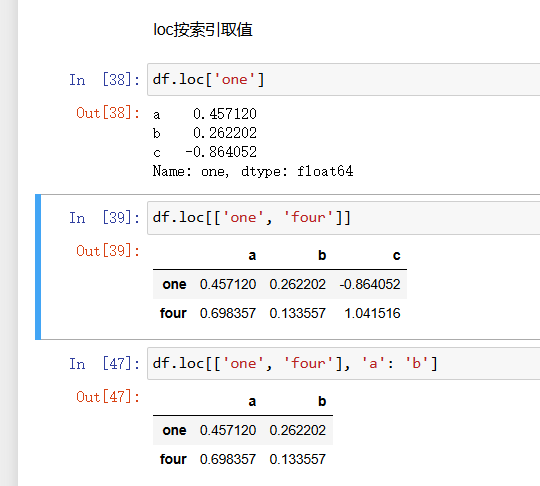
loc是一种索引方式,那么我们可以通过索引后对其进行一些其他操作:

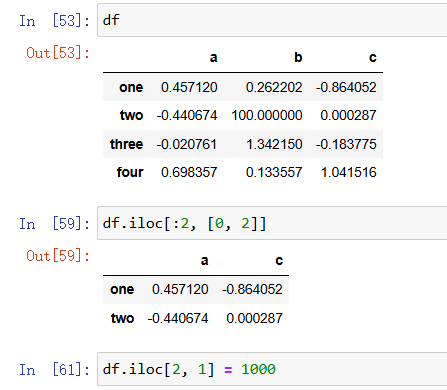
除了使用loc对其于列的键进行具体索引外还可以使用iloc函数默认其排序进行数字方面的行列索引,相当于一种重映射的感觉吧,或者说直接将其当作多维数组了:注意的是我们对多行或者多列进行iloc的索引方式是在[]中嵌套[],如果[]中只有一个数字那么代表的就是索引相应的行,就是上述所说,如果【】中两个数字通过“,”隔开,那么就是索引第几行第几列具体位置,如果中间嵌套[]就是一个多行多列索引:
使用方式也差不多
当然Series中可以类似像数组一般索引其中索引内部还可以增加条件那么DataFrame也是有相应的操作,但是还是会将全表打出,对于不满足条件的值直接就用NaN进行替代,也可以索引之后进行相应操作:
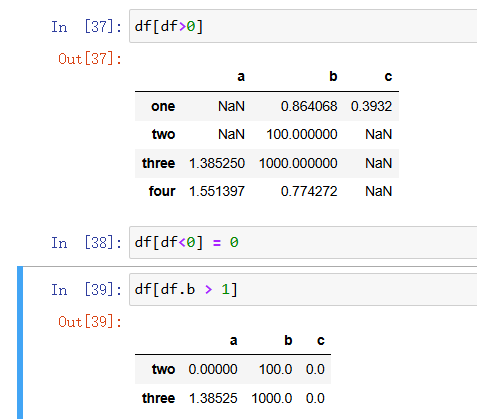
对于那么df.b>1我感觉它返回的东西应该是[two,three]类似的东西所以在外面嵌套一层df的时候才会返回上面的结果;
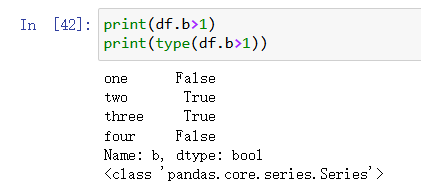
测试了一下,返回的是b的Series类型:
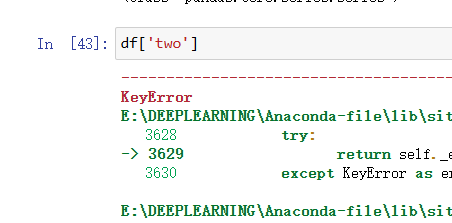
对行的索引只能使用loc函数或者iloc函数,如果直接照上面的那么索引会报错:
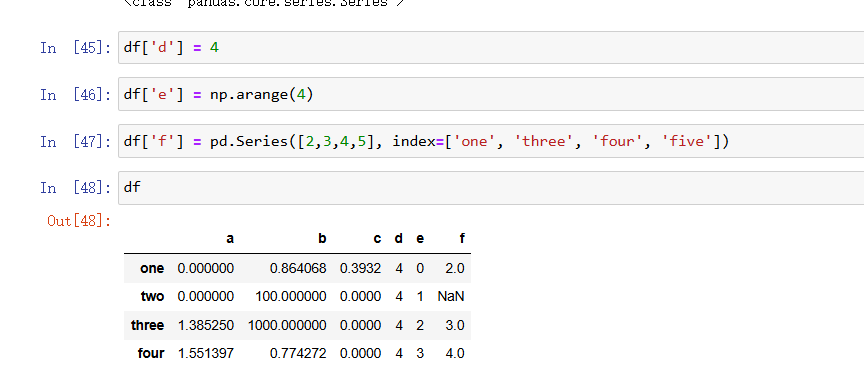
除了一开始使用DataFrame创建完这个表之外我们还可以在后续添加相应的列,使用方式和图类似直接索引赋值就好,但是好像要给完与行对应的数据大小:
增加完相应的列可以使用del删除相应的列,上面提到了增加的列数据要对应,如果数据个数要对应,如果不对应好像生成不了,反正是这样理解的,或者说下面那种方式df.h=5本来就不行:
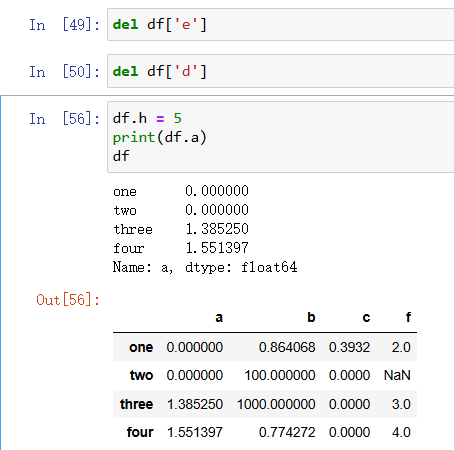
上面说了列的增加与删除,那么相应的也就有行的增加与删除:
行的增加使用loc函数,删除使用drop函数,如果你是对一整行的设定一个数就是下图的方式,如果你是想增加列并且每一列都存放指定的值就用一个列表代替下面那个10即可,但是数据个数要与列相同;

记住了使用普通的df【】进行索引,只能索引相应的列,loc,iloc函数才能实现对行列的共同索引
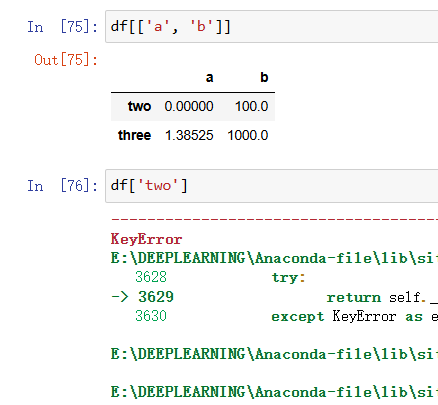
如果在直接使用df[]索引时不太清晰建议直接在内部写上columns=[]与相应的列

DataFrame索引重置:
索引重置的相关函数reindex,其格式可以是完全重新设定,设置的方式很多我不太好描述,使用下图的方式进行重置可以观察到,行索引是可以完全替换的,但是如果列索引不是对应的那么就是相当于重建表的感觉了,里面的值是不存在的
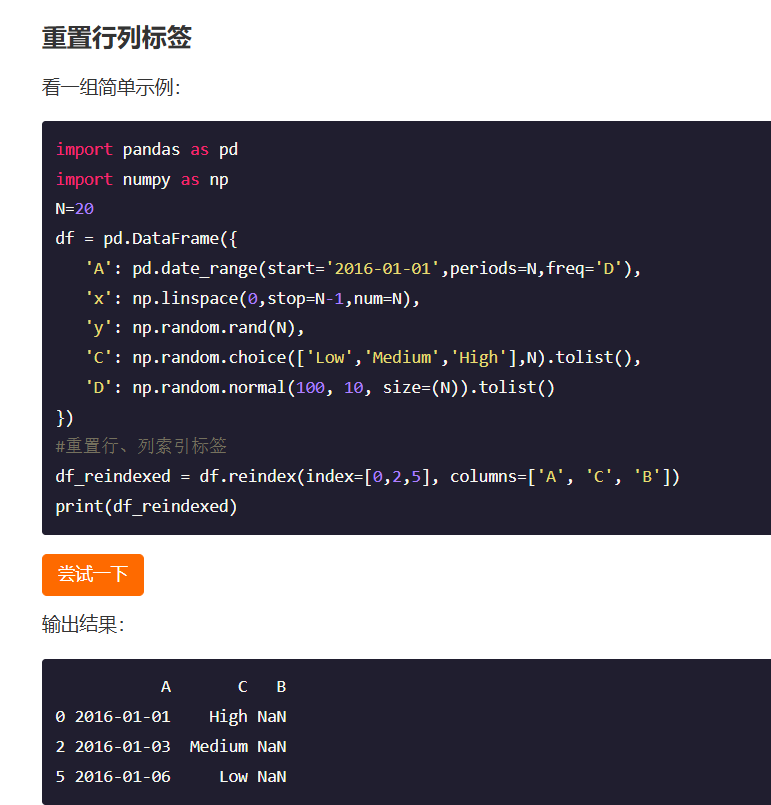
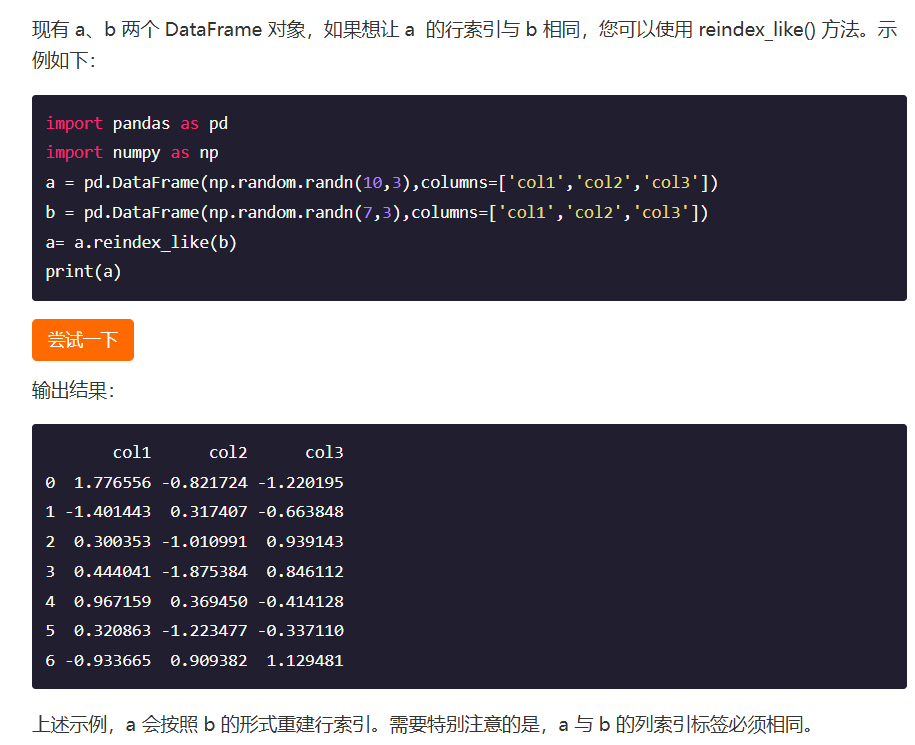
上面那种方式很糙,还是别用的比较好,使用reindex_like()函数比较好一点下面是reindex_like函数的相关使用:
下图的使用方式就是在原表的基础上将10*3的表换位7*3的尺寸,就是把最后三行数据删掉
填充元素值:
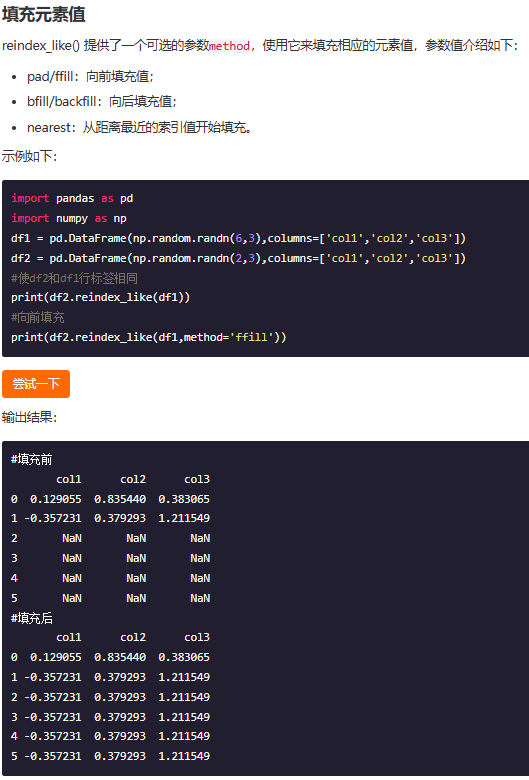
如果表格在原表的基础上增加了行或者列扩充的尺寸的值都是NaN,所有在使用reindex_like中还有个参数method,它的向前填充方式ffill好像就是复制前面的值进行填充,向后填充就是复制末尾的值向上进行填充;
同时在函数内部设置一个limit参数设定扩增后使用填充方式填充的行数

重命名标签:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人