

人脸验证问题:
对于进行人脸验证我们在数据库中可能只有每位员工的一张照片而已,然而要通过这一张照片验证出是否是库中的员工,同时如果在库中增加成员是否能验证出来,这种数据集实在太小,可以使用learning a similarity function 这个函数进行计算验证,其作用就是设置一个阈值,如果说对人脸以及数据库中的图像进行验证,小于这个阈值就预测是这个人,如果大于这个阈值就预测不是数据库中的人

实现上述函数d,是 基于Siamese网络;
Siamese网络:
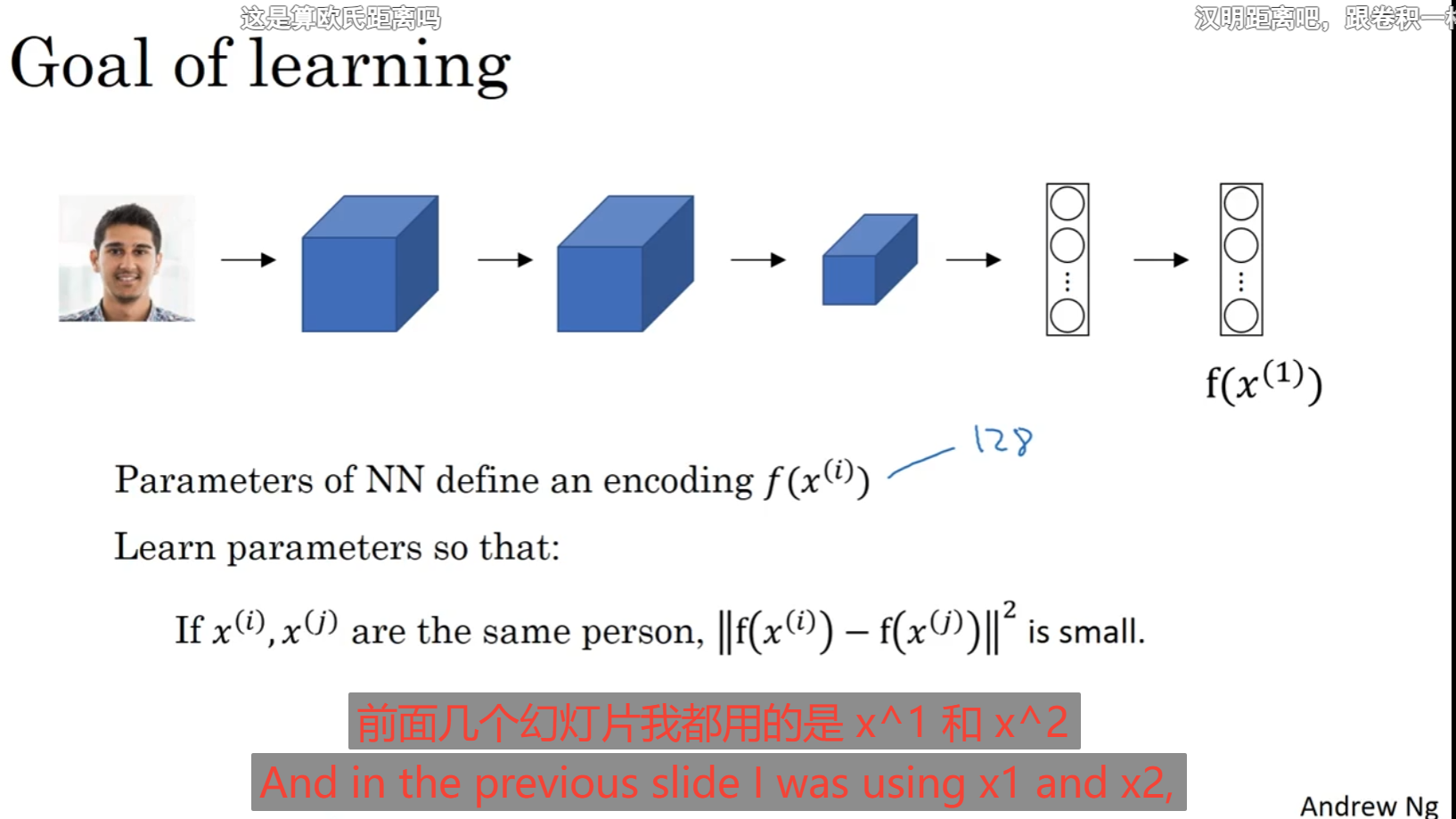
将图片经过卷积神经网络最后获取的预测值Y向量作为一个编码代表一个人的身份,相当于一种映射哈希的感觉,对于函数d就是上述的相似函数,是以这两张图像为自变量,传入他们相应编码对其求取编码的范数之差,这就是一个预测,Siamese网络。
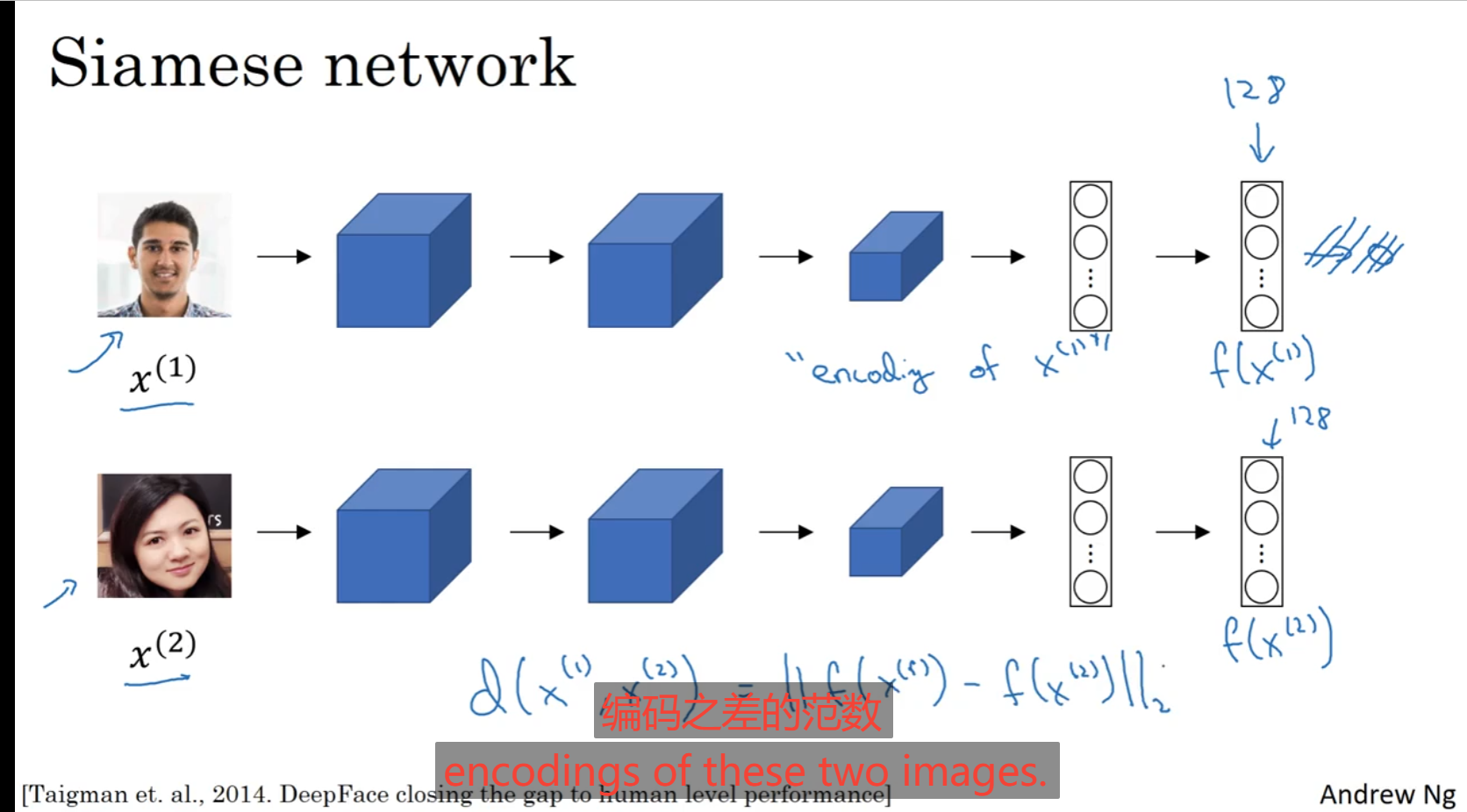
训练出来的模型参数要使得对于同一个人进行面部检测时候xi与xj的编码之差的范数小,对于不同的人尽可能大
Triplet loss function:
下面图像中存在三个人,Positive表示与Anchor相似的人像或者说就是同一人,Negative表示不同,按照上述的我们要做的就是在进行人脸检测的时候对两张图像的编码之差取范数,通过范数来进行预测是不是同一人,对于相似的人我们要使得其预测的范数尽可能小,不同的人使得范数尽可能大,那么就出现下面的一个等式,但是存在取等的情况,就是超参数均为0这些特殊情况,为了避免训练出这些特殊情况,我们可以设定一些隔离值,通过隔离值来训练超参数保证不会取到这种极端均为0的情况。
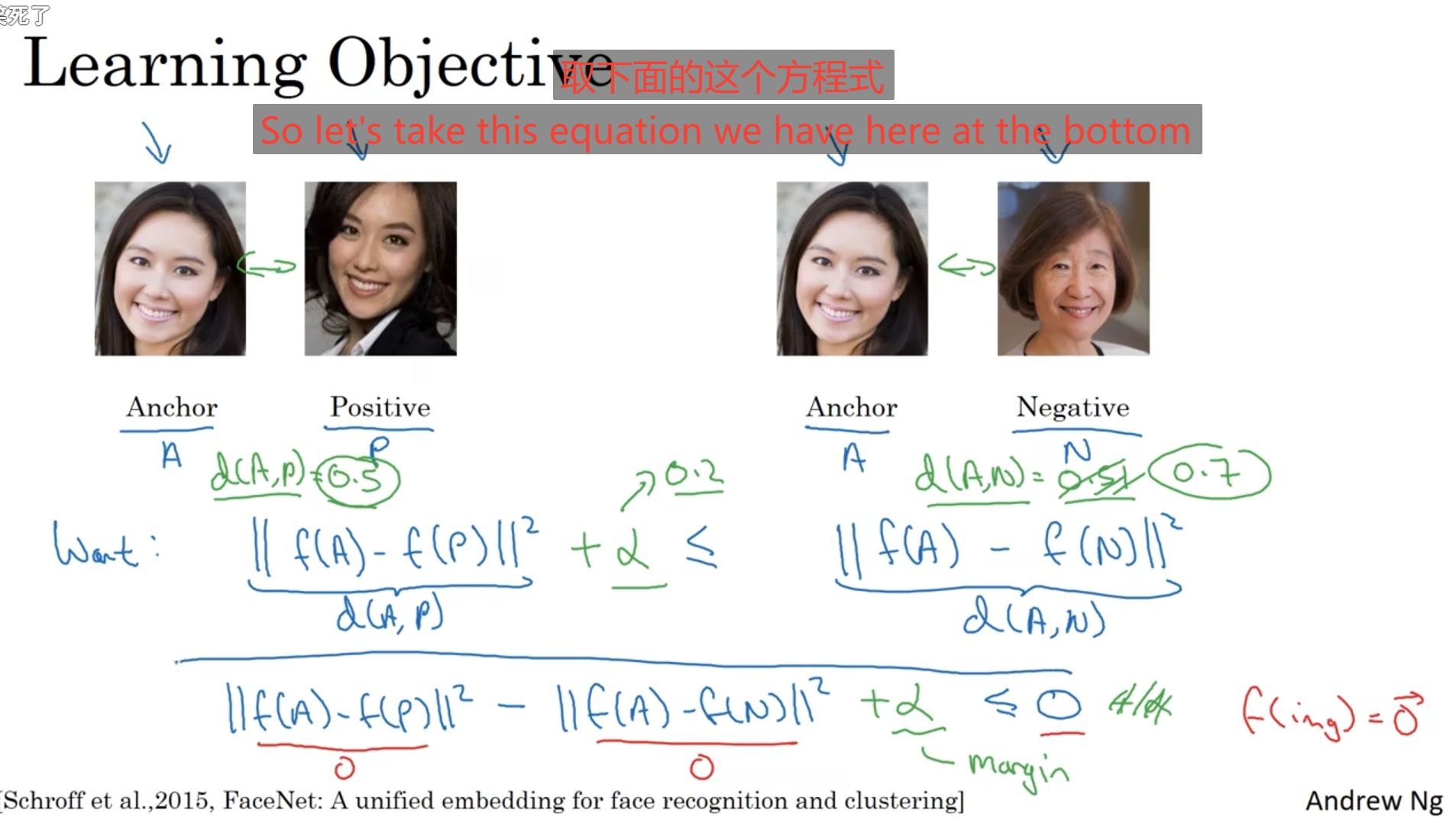
定义将图像分为A,P,N三类,A是检测的目标,P是同一个目标,N是不同的目标;
将人脸检测模型的损失函数设定为max(A与P之差的范数-A与N之差的范数,0)取其最大,其实我也不太理解为啥这个损失函数这样设定,但是又弹幕先抄下来,后面再去理解,这个A与P之差的范数-A与N之差的范数不是越大越好,因为如皋模型过度关注差异性可能会让个例差异影响总体预测,而非关注于综合判断;感觉就是在训练模型参数的时候初始的时候并不能确定参数可以使得A-P的范数加一个值小于A-N的范数,甚至还可能是相反,使用使用这种损失函数进行训练,让这个损失函数尽可能小,那么尽可能小最好的就是取0,如果取得大于0的情况就要重新训练参数因为它预测错误了,A-P的范数就是大于A-N的范数,与我标签不同,所以这样去训练。

对于训练集中的AP要成组的出现因为这是同一个人的图片,而且因为是在训练阶段,如果说我们是随机选取APN三张图像的话,那么对于它的训练效果不是很好,因为它原本的差距可能就很符合这种A-P的范数+一个值<=A-N的范数,所以初始训练时要寻找这两者相近的图像,也就是A-P的范数+一个值约等于A-N的范数,通过超参数的训练,使得我们的A-P的范数变小,而A-N的范数变大,这样才能训练出一个好的模型。

上述是Triple Loss对面部识别的模型应用。
还可以将使用二分类对面部验证模型进行建立:
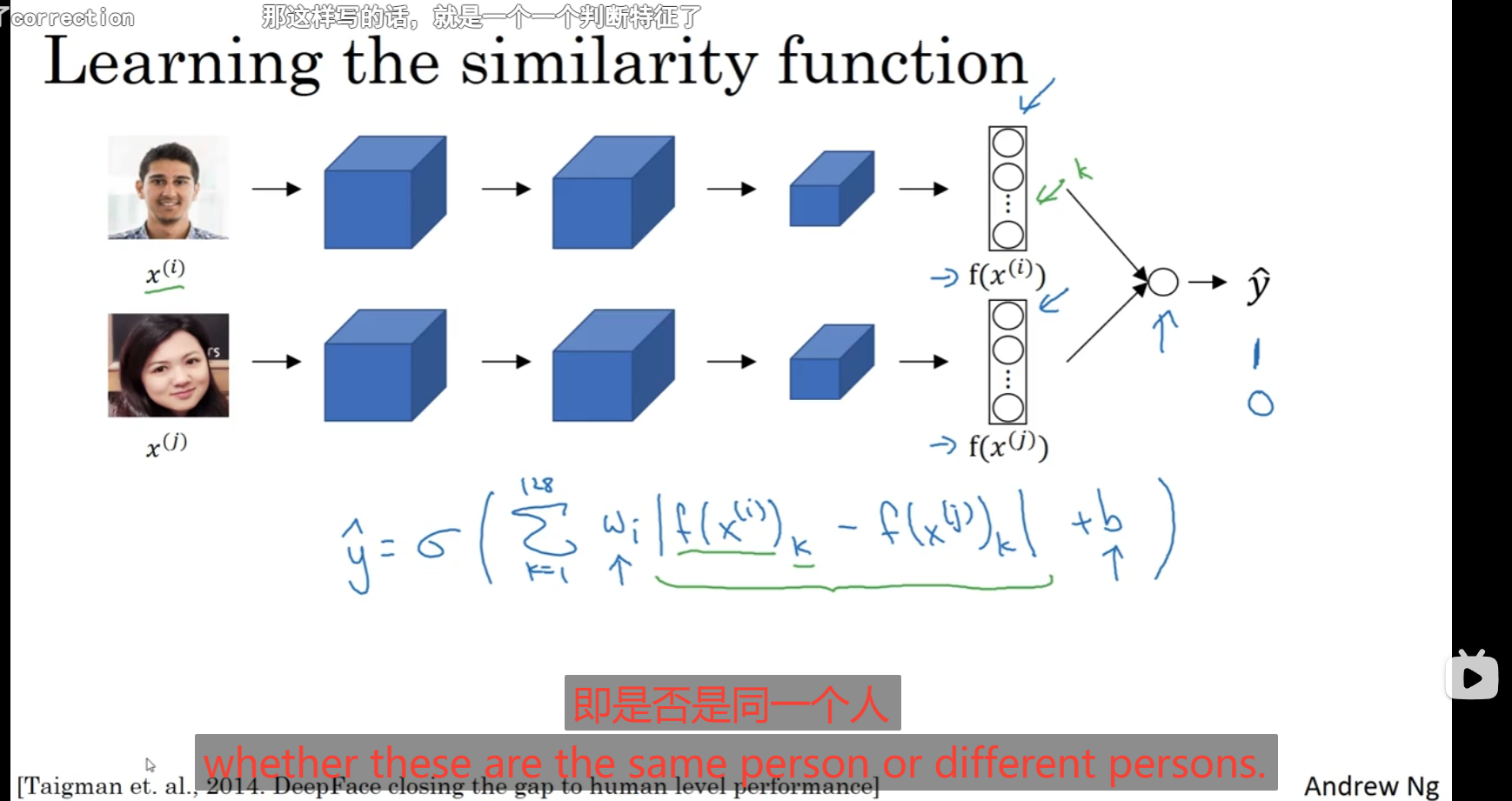
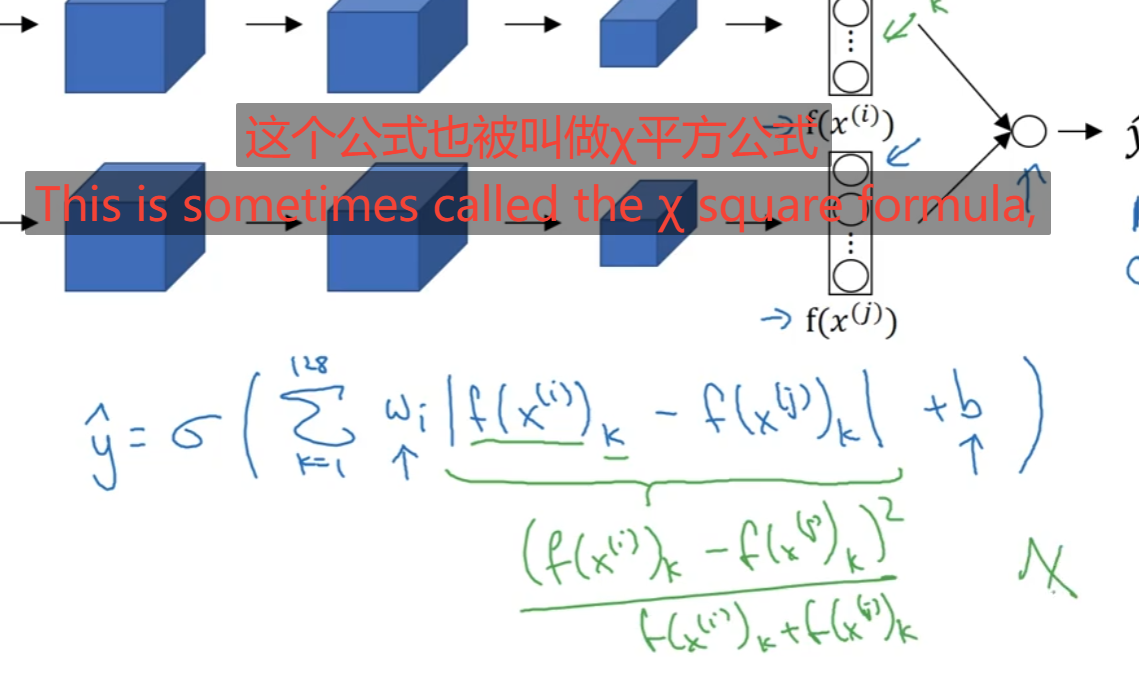
将图片通过设置的卷积层等等最后到神经网络层,比如说到了那个f(x(i))比如说这玩意就是提取的一个特征向量1x128的维度即1x128个特征,那么预测值Y^就设定为一个sigmoid(1到128求和 (权重即w*abs(f(x(i))中第k个特征-f(x(j))中第k个特征)+b))进行预测,预测值为0或1通过超参数的训练得出这个二分模型。中间的f运算可以使用其他东西替代
神经风格转移:
神经风格转移最直观的就是将两种图像结合,结合的新图像其中内容为一张图像的,但是风格为另外一张图像的,首先我们需要确定两张图像的代价函数,他们的代价函数由两部分组成,一个函数是内容代价函数,一个是风格代价函数,再对这两个函数设置权重组成整体的代价函数

对于内容代价函数,这个代价函数保证你生成的图像接近你的内容图像,如果代价函数是浅层,那么生成的图像像素会与内容图像相似,如果是深层,那么生成图像的内容可能会与内容图像相似,我们要做的是找到介于这两者之间的内容代价函数的超参数。

将内容图像与生成图图像拿出来看,内容代价函数的值计算就是(内容图像的激活向量-生成图像的激活向量)的平方和再乘上一个权重。
在运用时整个代价函数会激励这个算法来找到图像G生成图像。
风格代价函数:
有点复杂不想研究这个先不管了,后续有用到再去深究。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人