

目标定位:
对于图像上的目标,如果进行识别后还需要将其在图上进行框出,我们就要多训练几个数据,一个就是识别目标的中心点,另外一个就是我设置圈出的长与宽可以记为bx,by,bh,bw;根据训练出的模型在图像检测上预测出这四个点的位置,当物体出现的时候就可以根据这个数据进行定位。当然要做出这些预测在训练集中就要添加相应的标记,进行训练迭代。
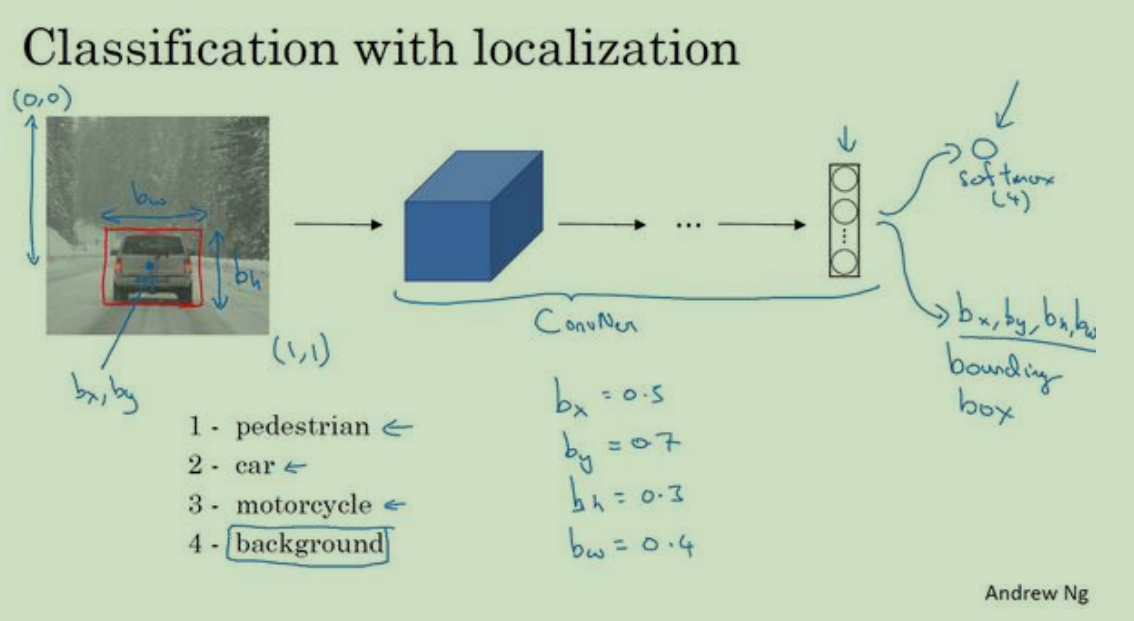
如果说是图像上不存在我所需要的目标,或者说仅仅是一个背景,那么这个预测结果Y^的值中就只有一个对我们有效果就是预测图中不存在要检测的目标,其余的预测参数可以忽略,因为我们不需要。
特征点检测:
特征点检测就是预测图像上的点位了,比如在人脸识别的模型上,要标记出人的眼角或者说嘴部表情等等,用于预测人的情绪之类的,我们在训练集的时候要对这些进行标记。


目标检测:
在目标检测训练集的标记阶段,可以将图片中的目标单独抽出来作为图像的主要部分。

通过上面训练集训练出来的模型后在要预测的图像中设置小方框,可以使用滑动窗口的方式对图像进行检测预测:
可以对窗口的大小,滑动的步长做出不同的设置,感觉就是把图片切成红色方框小块,再将这些红色方框小块的图片放入模型中检测,最后得出这张图像上是否存在所要检测的目标。这种算法也叫做滑动窗口目标检测;

但是使用滑动窗口的算法进行目标检测要考虑很多,而且如果说对其步长设置很大就很容易失去准确率,但是如果对其步长设置过小效率会很低,所以滑动窗口算法进行目标检测并不算太好的办法。
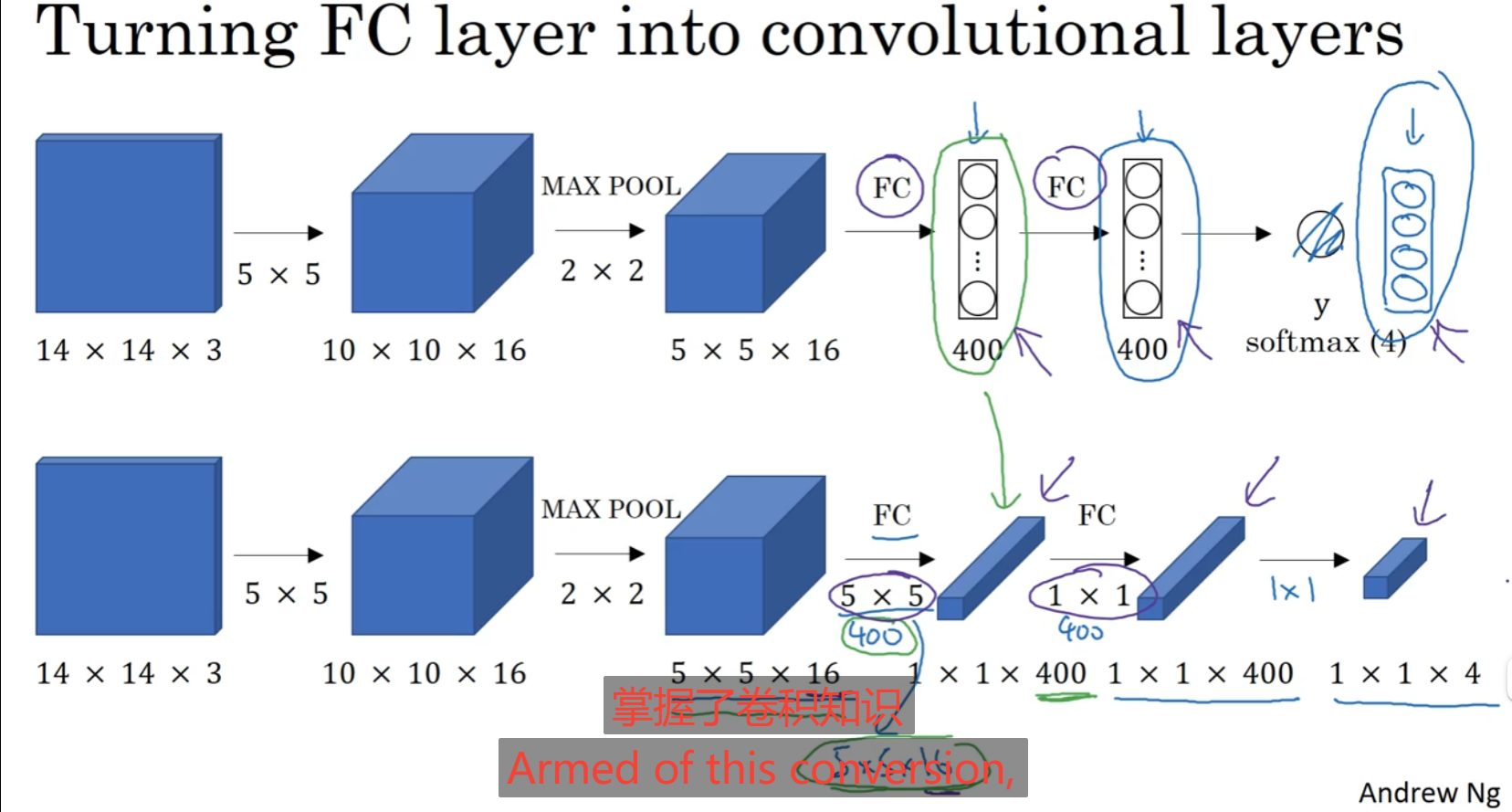
卷积神经网络中一般为卷积层到神经网络层,从数学的角度来看,我们也可以使得数据从神经网络层到卷积层:
如下图本来是将卷积层展平变为神经网络,但是图中神经网络可以看为一个(1,1,400)的向量,那么我在下方设置一个核,后面的卷积层得出的卷积维度与神经网络的维度相同,就可以看成从神经网络恢复到卷积的感觉。
前面的 滑动窗口进行目标识别是将图片拆成小块滑动展平,经过卷积层,池化层,再展平进入神经网络进行运算,但是这种运算效率挺低的,我们就可以优化这种运算,直接使用卷积层进行滑动窗口运算处理,就像上面那种用卷积替代神经网络层一样。再下图中第二第三行最后一位四个方块就是对图像只进行卷积滑动窗口预测的结果就是分成四块区域,分别代表对左上,左下,右上,右下做出预测的情况。
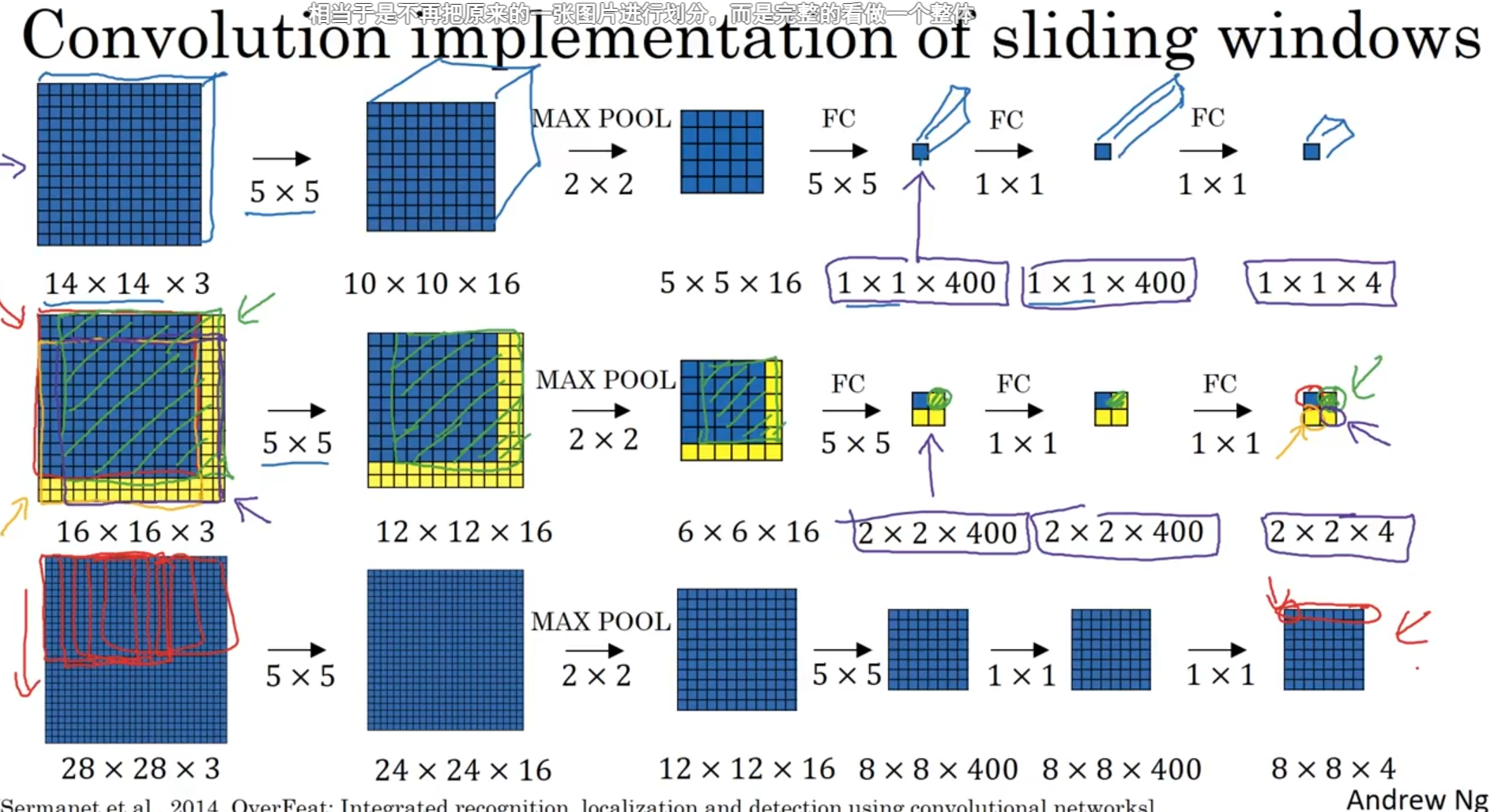
在卷积层上使用滑动窗口,将立体卷积拆分成所要的窗口大小进行卷积处理。具体细品一下下图弹幕。

Bounding Box预测:
YOLO算法:
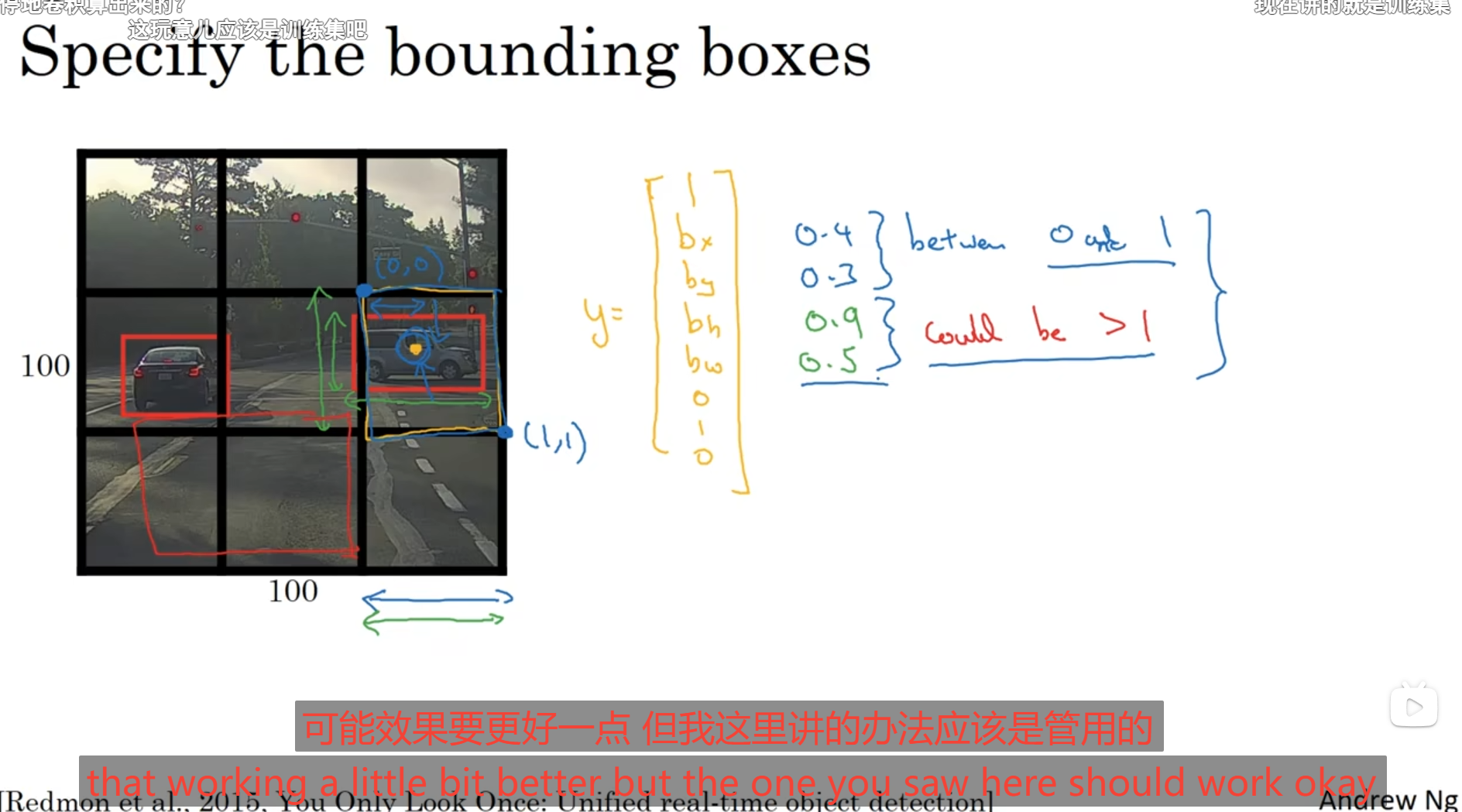
可以将图像分成3x3进行预测,我们在训练集上要标记的是每一块我们所要识别的物体,对于分割的一块图像中只有一小部分可以选择忽视它,当作不存在,但是在3x3方框中,如果有大部分我们所要识别的物体就要标记出物体的中心点为即bx,by同时设定bh,hw用于训练,那么对于这一块分割的方框训练出来的预测Y^就是一个1x8的向量,第一个是Pc预测值是这个方框中是否存在我们要识别的物体,下面的维度分别是bx,by,bh,bw,c1,c2,c3八个维度,那么这张图像给我们切割成3X3最后得出的结果就是一个3X3X8的方块,对于其中1X1X8的一块就是对应3X3方框的预测情况。

在3X3方框中在我们使用一个方框去检测的时候,一般将左上角设为(0,0)右下角设为(1,1)让bx,by坐标处于0-1之间,对于bh,bw而言,他们的值设定是可以大于1的因为可能物体的中心点在一个方框内部,但是有的部分横跨方框在别的方框内,这是在标记训练集所要处理的事情。
交并比(IoU):
在对目标识别的时候我们手动标记的物体存在一个方框的区域,训练的模型会对训练图片产生一个方框的区域,交并比的意思就是这两个方框覆盖的区域的交集与并集之比,那么显然,交集必定小于并集,所以我们的模型的交并比越大,效果越好,一般而言如果说IoU大于等于0.5就认为预测正确。

非极大值抑制:
非极大值抑制作用是使得你的算法只对你检测的目标进行一次检测。如 下图中当你使用细分的方框进行目标检测的时候,虽然你的训练集只标注楽一个方框中心点但是因为划分的方框太小,所以在目标检测可能会对同一个目标预测多个中心点,就好比下面画的图像,虽然只有一个中心点,但是通过模型去预测可能会觉得周围几个方框也是物体的中心点,那么同一个物体就存在多个中心点,就是进行了重复预测

就比如下图中的情况对于一个物体进行多次检测并且标记出中心点位与方框在图像上

非极大值抑制的作用就是使得其只对同一个物品做出一次预测而不是上图中的多次预测;

那么它作用是先进行预测,再找出最大值,因为最大值的预测效果最可靠也是可能是预测最完整的目标检测,在选定最大值后对最大值边框进行高亮设置,对其周围的预测边框进行检测,对于这两个预测边框IoU值程度高也就是重叠度高的其他边框进行抑制,将那些重叠的非最大值边框设为暗色,最后将这些暗色预测删去即可。
anchor Boxes:
使用上述的目标检测,在一个方框格子内只能检测一个目标,但是使用anchor Boxes可以在一个方框格子中检测多个目标;
使用 这种方法一般是专门针对一些图像的,用于特定设置,下面举个例子,对于图像中 又有人又有车子,但是人与车子可能中心点出现在同一位置,如下图:
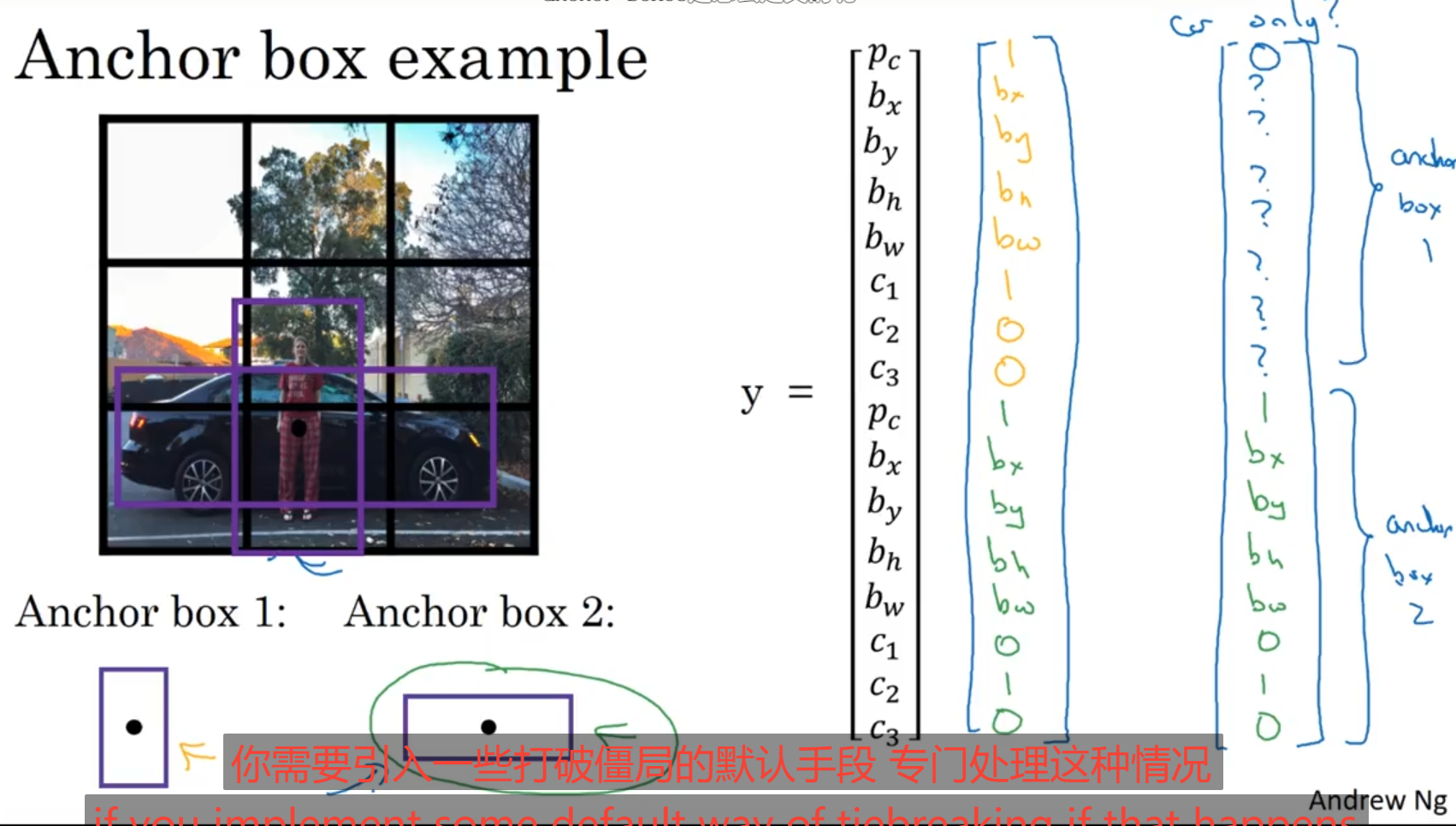
这种情况下对于同一个方框中处理多个对象就可以使用anchor boxes方法处理,之所以说是针对性的,是因为在图中人物大概的方框就是anchor box 1这种,而成对应的方框就是anchor box 2这种,所以在我们进行预测的时候假设我们只处理同一个方框中预测只预测两个物体,人与车,那么我们就可以设定预测值Y^的格式,上面的半个维度存放的就是人物的预测维度或者说标记维度,分别为Pc,bx,by,bh,bw,c1,c2,c3,对于Y^下面八个维度我们存放的就是汽车的预测维度或者说是标记维度,按照anchor box 1,anchor box 2的顺序放置数据。这些anchor box都是自己设定的,对于你想在一个检测方框中检测多少个目标进行设置。
YOLO对象检测算法:
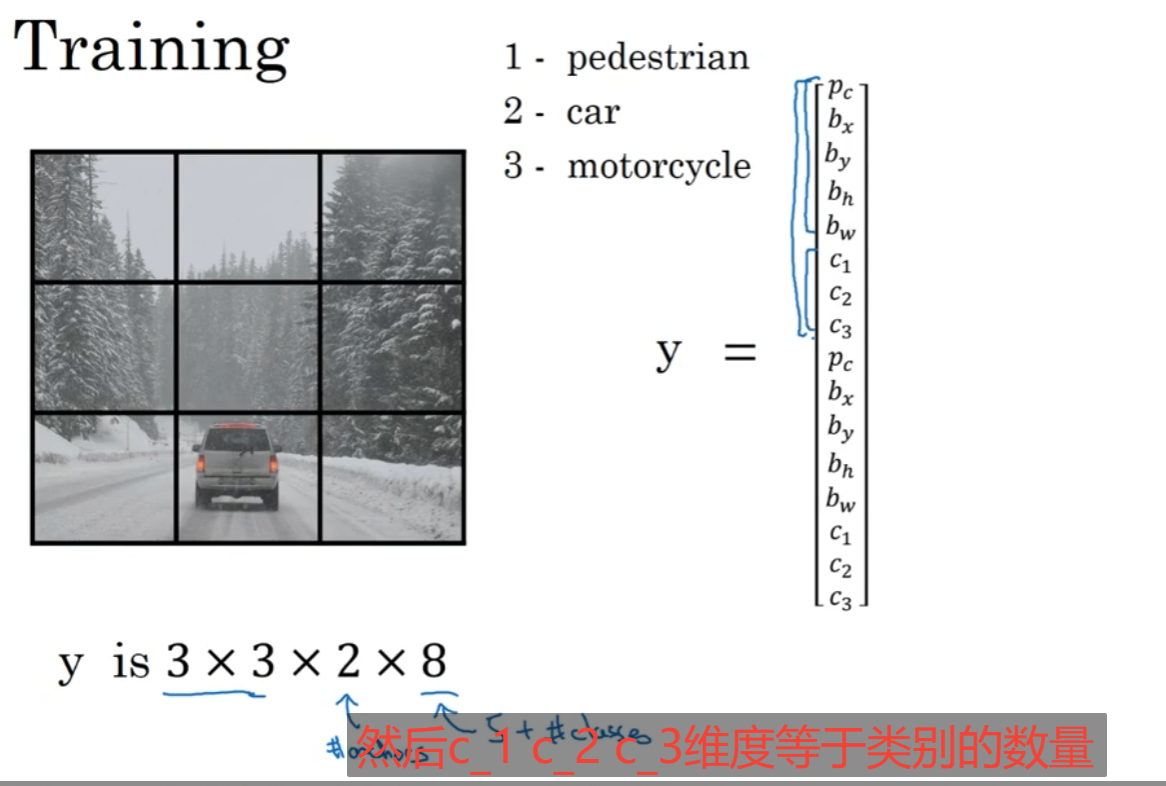
预测值的维3x3x2x8,3X3是因为将图片分为3x3方框进行检测,2是你设置要检测的目标数量,就是在一个方框内部可能可以检测出多少个不同物体,至于那个8是5+你所设定图像上存在的类别,这里的3个类别分别为行人,汽车,摩托车,但是我只要对行人与汽车做出预测即可,5就是Pc,bx,by,bh,bw。那么你预测的Y^维度也就是你要检测的物体类别*每个类别要做出预测的维度,这里的2是使用author box操作的。

在使用anthor box预测如上图设置两个box,这种情况下检测出来后还要使用非最大值抑制的方法将对同一个目标检测的方框去除


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人