

在建立模型中出现三种情况:
1.欠拟合,偏差大,模型对训练数据都预测不准确,要调整自己的模型,或者说重构自己的神经网络。
2.刚刚好,偏差与方差都挺高的,说明模型建立的还可以。
3.过拟合,方差过大,拟合太准,缺少泛化,只对训练集起到效果很好,对测试集效果不是很好,这种时候就要考虑正则化;
以下两种普遍的正则化方式:
1. L2正则化


目标要处理的是损失函数最后达到最小值,对λ取大一点后续更新参数也会快一点,由于L要往小里处理,λ取较大那么w只能取较小。
从欠拟合到过拟合中是有一个刚好的状态,那个状态就是我们需要找的模型以及参数,在浅层网络神经的时候,就会出现欠拟合的状态,而在深层网络神经出现过拟合状态,中间发生最主要的变换就是层数的增加以及w超参数的增多,将w的权重调小就是L2正则化的目的,让其泛化,不要过拟合还有其他的正则化方式
2.随机失活(dropout)正则化:直观理解:

上述说了网络神经深,w超参数太多可能出现过拟合,那么dropout直接随机处理删除掉一些网络神经路径,后续也迭代不起来,通常要设置一个数字keep-prob


上面只是正则化其中两种,还有数据扩展,增大训练数据的方式对处理方差也是很好的方式,很多时候没有那么多数据,所以可以从已有数据入手,对图片进行镜像处理,还可以放大缩小,这些方式都让原有的数据情况下扩展数据量;early—stopping,在训练数据的同时找出一个最合适参数点,在过拟合的转折点停止训练,找到一合适参数就行,紫色线代表预测误差;

————————————————————————————————————————————————————————————
归一化输入:

先求出均值,把每个数据都减去均值实现零均值,这样调整后数据都会在0周围;
再求出方差,因为前面已经求过了每个数减去平均值,所以求方差只是每个数平方之和在除以一遍总数就好;
最后将每个数据都除以方差,实现归一化;
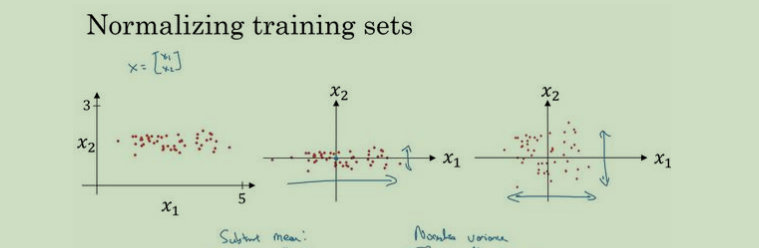
这是二维参数的情况,第三图图表现了归一化后数据分布情况,可以看见很比较均匀了,并且在0轴附近;
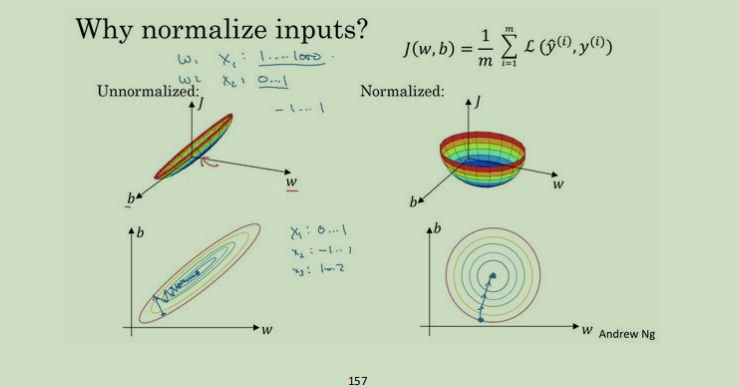
上面是对归一化处理的表示,如果不使用归一化,数据分布可能是呈现第一种状态的,这种情况下需要设置较小的学习率进行迭代才能更准确找到成本函数最低处,进行了归一化处理就不会这样,更像一个半圆,无论超参数随机生成什么处于什么位置,学习率适当调整就可以更快迭代到成本函数最合适的位置;
————————————————————————————————————————————————————————————————————
梯度消失和梯度爆炸:
对于深层网络神经而言,都是根据层数进行迭代的,如果设置L层,激活函数为线性函数,那么迭代过程无论是下降或者上升的情况都是按照指数函数的情况进行爆降或者爆增的

虽然归一化对于数据已经是处理到一个0轴区间以及一定范围内分布较为均匀,但是可能还是存在梯度消失或者说梯度爆炸的情况,因为这是迭代的问题,不是数据的问题,神经网络的权重初始化就是为了优化梯度消失或者梯度爆炸的问题;
下面是神经网络权重初始化只有一个神经元的时候处理方式:

相当于每个超参数除以上一次计算出来的A的数量,或者说是特征量;对于激活函数的不同,相应的会有一些变化以求达到最佳的情况;


————————————————————————————————————————————————————————————————
梯度检测:
梯度检测可以帮助我们检测自己推导的公式运行的正确性,找出推导程序运行出问题的地方,帮助我们及时处理更正bug;
在梯度下降的时候对梯度检测方法相当于求中值导数,对其进行一个误差范围的判断,如果误差足够小就证明自己的推导没有问题至少还没bug,如果误差大于一定区间就要对数据进行查找了;处理方式有点像拉格朗日中值定理,但只用找中值就行,不是切线,为了大概测试迭代的数据是否存在问题;
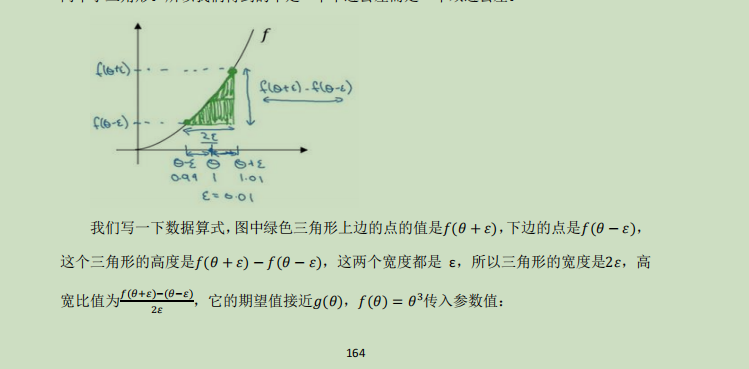

上面是理论,具体做法是把所有w,b参数求出,最后连接成一个向量θ,存在w,b那么就有dw,db,将他们连成向量dθ;

根据理论对每个θ进行改变都,根据导数原始公式求出来的θ中值于dθ做差后进行范数,然后用向量长度归一化,使用向量长度的欧几里得范数;


——————————————————————————————————————————————————————————
mini-batch梯度下降法:
之前处理的一次性把训练集样本全迭代的方式叫batch梯度下降法,缺点是一次性迭代大量数据需要时间长,如果数据量不是很大那么还是很好用的;如果一次性只迭代一个样本叫min-batch,如果这样迭代那么减小学习率可以减少噪音,但是速度也很慢,因为处理整个训练集,超参数可能迭代差不多了,但是对于训练样本却没跑完。所有在处理单次传播迭代过程中将batch训练集分成适当大小,用loop进行梯度下降,减少对样本处理的迭代或者说加速迭代得到恰当超参数,如果mini-batch迭代过程中成本函数,或者参数变化动荡太大可以试着减小学习率缓解找出适合超参数;
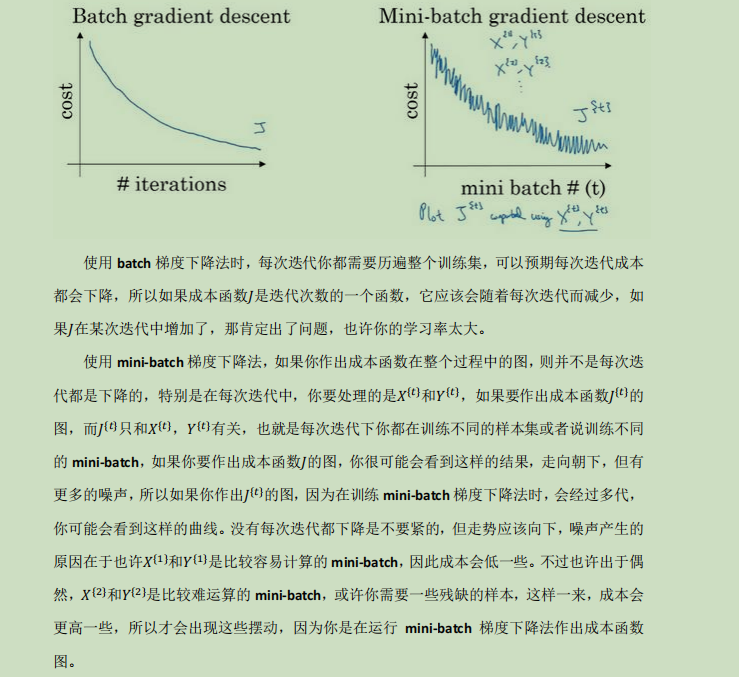
——————————————————————————————————————————————————————————————————————
指数加权平均数:v=0,v=βv+(1-β)θ;
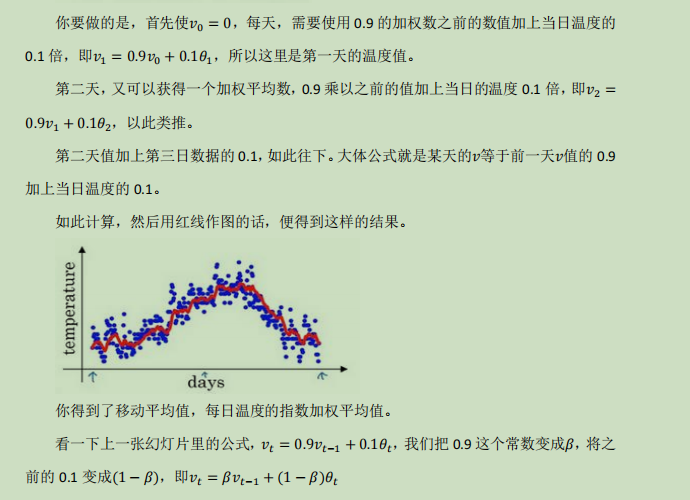
对于不同的β对曲线变换不同,β越大起伏越小,因为后一天所占有权重太小,影响不大,选择一个合适的β达到一个刚刚好的曲线
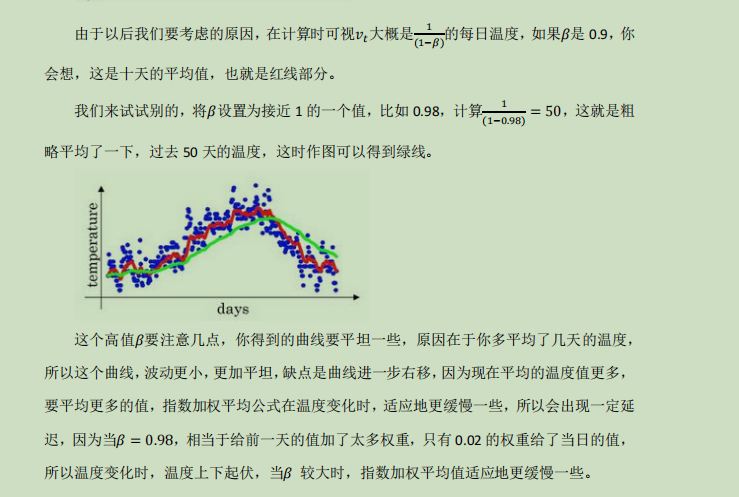
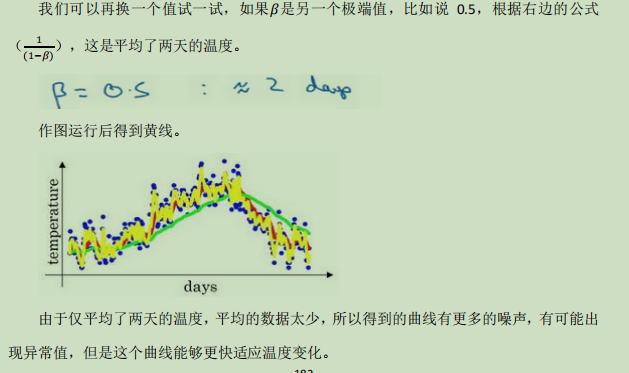
本质是调整前面天数对后面天数计算的一个影响,前面天数的权重会随计算慢慢向后挪移,而前面天数权重下降到1/e的时候就影响不太大了,

指数加权平均数优点就是可以少存存储数据,代码就一行;
——————————————————————————————————————————————————
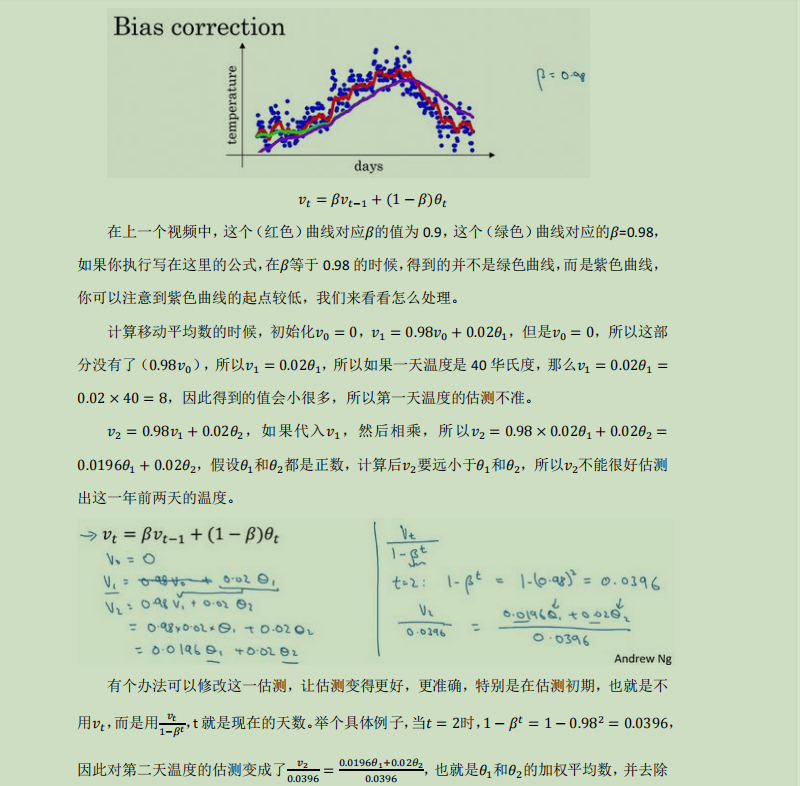
偏差修正:
当β过大的时候初始化阶段偏差会比较大,所以存在一个偏差修正用于处理这个问题:vt/=(1-β^t)

——————————————————————————————————————————————————
在mini-batch梯度下降的时候对于dw,db动荡太大,当学习率增加的时候,偏差会增大,拐来拐去,增大学习率可以增快下降速度,但是偏差大会产生较大的噪音,或者在最低点周围动荡很难靠近,所以在跟新dw,db时候结合指数加权平均数,让其偏差变小,如上面的红线一般;


在使用这个的时候不用考虑初始偏差的问题,我们需要的是最快到达最低点的超参数,前期影响对我们最后结果不重要

————————————————————————————————————————————————————————————————
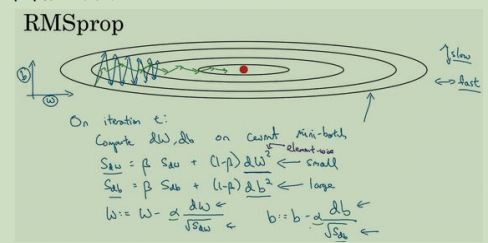
RMSprop梯度下降法:





————————————————————————————————————————————————————————
Adma优化算法:
Adma优化算法是把rmsprop和momentum两个梯度下下降法融合在一起使用,对于momentum存在一个超参数设为β1,一般情况都将β1=0.9;rmsprop超参数β2=0.999;ε=10^(-8);对于这些超参数来说一般最主要调整的是学习率而不是它们的调整;


————————————————————————————————————————————————————————————————


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人