

SpringCloud简单使用及介绍
SpringCloud介绍
Spring Boot擅长的是集成,把世界上最好的框架集成到自己项目中
==Spring Cloud本身也是基于SpringBoot开发而来,SpringCloud是一系列框架的有序集合,也是把非常流行的微服务的技术整合到一起,是属于微服务架构的一站式技术解决方案。==
Spring Cloud包含了:
注册中心:Eureka、consul、Zookeeper
负载均衡:Ribbon
熔断器:Hystrix
服务通信:Feign
网关:Gateway
配置中心 :config
消息总线:Bus
集群状态等等....功能
Spring Cloud的版本
SpringCloud是一系列框架组合,为了避免与框架版本产生混淆,采用新的版本命名方式,形式为大版本名+子版本名称
大版本名用伦敦地铁站名
子版本名称三种
SNAPSHOT:快照版本,尝鲜版,随时可能修改
M版本,MileStone,M1表示第一个里程碑版本,一般同时标注PRE,表示预览版
SR,Service Release,SR1表示第一个正式版本,同时标注GA(Generally Available),稳定版
SpringCloud与SpringBoot版本匹配关系
| SpringBoot | SpringCloud | | ---------- | -------------------------------- | | 1.2.x | Angel版本 | | 1.3.x | Brixton版本 | | 1.4.x | Camden版本 | | 1.5.x | Dalston版本、Edgware | | 2.0.x | Finchley版本 | | 2.1.x | Greenwich GA版本 (2019年2月发布) |
鉴于SpringBoot与SpringCloud关系,SpringBoot建议采用2.1.x版本
常见远程调用方式:
RPC:(Remote Produce Call)远程过程调用
HTTP:网络传输协议
-
RestTemplate是Rest的HTTP客户端模板工具类
-
-
实现对象与JSON的序列化与反序列化
-
不限定客户端类型,目前常用的3种客户端都支持:HttpClient、OKHttp、JDK原生URLConnection(默认方式)
它的功能就是,可以模拟浏览器发送请求。比如在A系统,通过
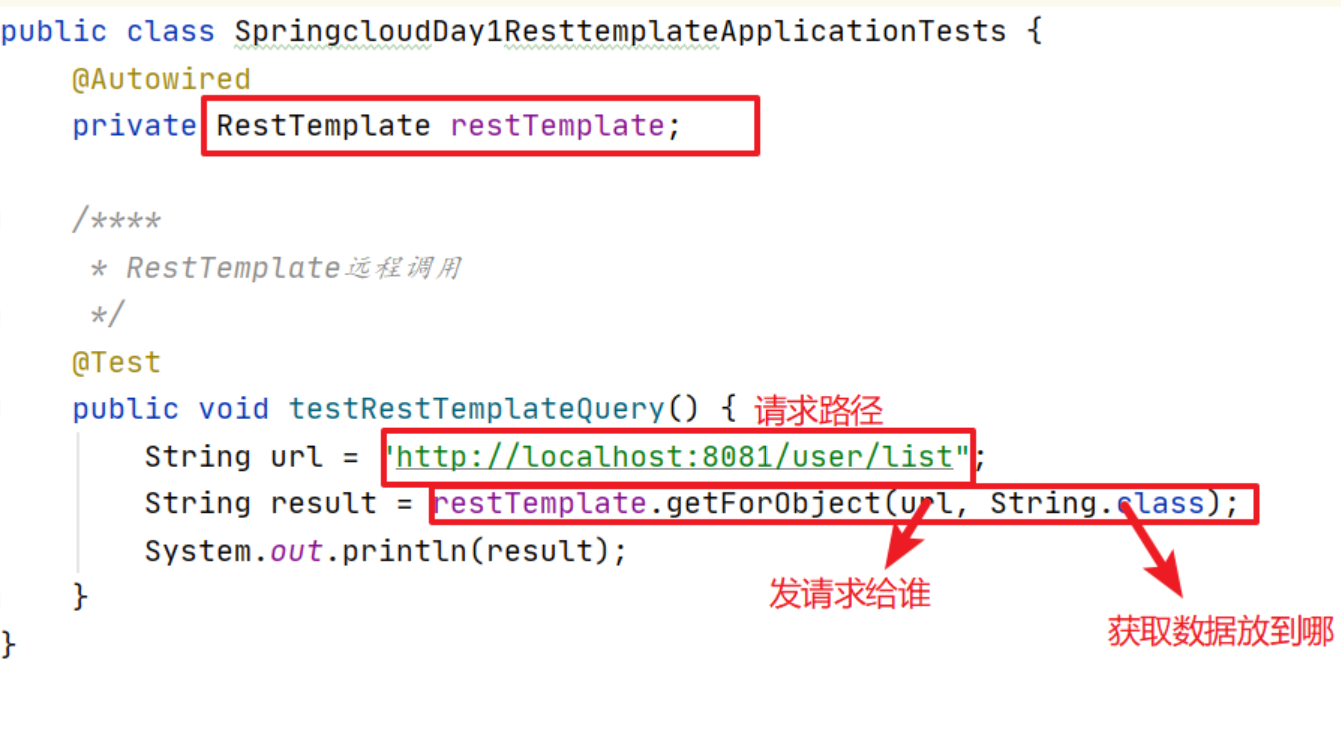
那么,通过
- 服务消费者使用RestTemplate调用服务提供者,使用RestTemplate调用的时候,需要先创建并注入到SpringIOC容器中
- 在服务消费者中,我们把url地址硬编码到代码中,不方便后期维护
- 在服务消费者中,不清楚服务提供者的状态(user-provider有可能没有宕机了)
- 服务提供者只有一个服务,即便服务提供者形成集群,服务消费者还需要自己实现负载均衡
- 服务提供者的如果出现故障,不能及时发现。
Eureka解决了第一个问题:服务的管理,注册和发现、状态监管、动态路由。
Eureka负责管理记录服务提供者的信息。服务调用者无需自己寻找服务,Eureka自动匹配服务给调用者。
Eureka与服务之间通过心跳机制进行监控;
原理图如下:
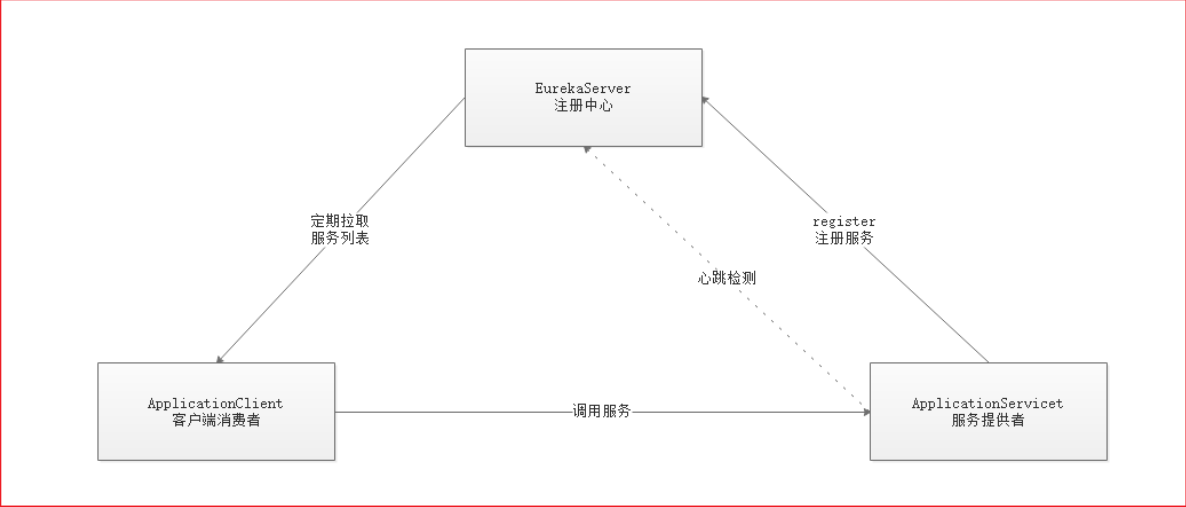
Eureka:就是服务注册中心(可以是一个集群),对外暴露自己的地址
服务提供者:启动后向Eureka注册自己的信息(地址,提供什么服务)
服务消费者:向Eureka订阅服务,Eureka会将对应服务的所有提供者地址列表发送给消费者,并且定期更新
心跳(续约):提供者定期通过http方式向Eureka刷新自己的状态
Eureka实现:
1、先需要创建一个工程,用于配置Eureka的服务端,这个服务的将暴露一个地址,让所有客户端全部将ip地址以及端口号注册到这个服务端中,这样谁想调谁,从这个服务端就可以获取到对应的ip地址和端口号
2、服务端的启动类加@EnableEurekaServer注解,表明这个工程是一个Eureka的服务端
3、配置文件暴露地址
4、在所有客户端的启动类加@EnableEurekaClient注解,表明这些工程是客户端,这些客户端一启动,就会把自身的地址端口号等信息注册到服务端上
5、然后就可以动态通过DiscoveryClient可以获取到Eureka server上指定的服务信息,再利用restTemplate对象发送请求,实现相互之间的通信
配置Eureka服务端:
依赖:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>springcloud-parent</artifactId> <groupId>com.xxxx</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>springcloud-eureka-server</artifactId> <dependencies> <!--eureka-server依赖--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency> </dependencies> </project>
启动类:加@EnableEurekaServer注解表明这是服务端
@EnableEurekaServer @SpringBootApplication public class EurekaServerApplication { public static void main(String[] args) { SpringApplication.run(EurekaServerApplication.class,args); } }
配置文件:指定应用名称,这样在获取的时候方便,因为这就是服务端,不需要将自己注册到服务端,也不需要从服务端获取信息,然后暴露自己的地址,给客户端注册
server: port: 7001 #端口号 spring: application: name: eureka-server # 应用名称,会在Eureka中作为服务的id标识(serviceId) eureka: client: register-with-eureka: false #是否将自己注册到Eureka中 fetch-registry: false #是否从eureka中获取服务信息 service-url: defaultZone: http://localhost:7001/eureka # EurekaServer的地址
配置客户端:
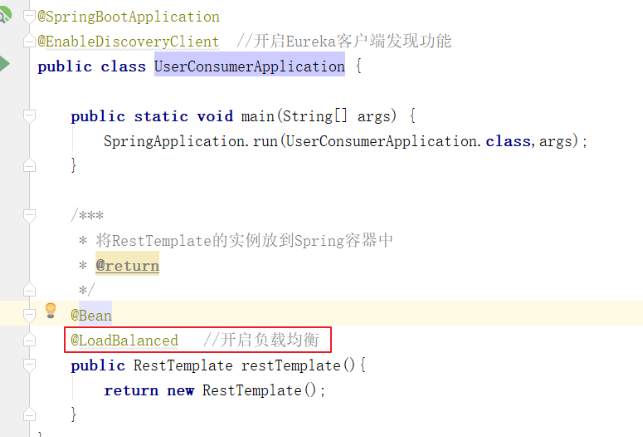
启动类: 因为后面代码要使用到restTemplate对象,所以这里面需要先将它交给spring容器,另外客户端的启动类上要加@EnableEurekaClient注解,表示这个工程是客户端,这样才会将自己信息注册到服务端
@SpringBootApplication @EnableEurekaClient public class UserConsumerApplication { public static void main(String[] args) { SpringApplication.run(UserConsumerApplication.class,args); } /*** * 将RestTemplate的实例放到Spring容器中 * @return */ @Bean public RestTemplate restTemplate(){ return new RestTemplate(); } }
配置文件:这里面要指定客户端的名字,这样在服务端里面就可以根据这个名字找到这个工程,再配置服务端的地址,指定使用ip而不是计算机名
server: port: 10182 spring: application: name: user-consumer #服务的名字,不同的应用,名字不同,如果是集群,名字需要相同 #指定eureka服务地址 eureka: client: service-url: # EurekaServer的地址 defaultZone: http://localhost:7001/eureka instance: #指定IP地址(指定这个客户端的ip) ip-address: 127.0.0.1 #访问服务的时候,推荐使用IP(默认使用的不是ip而是计算机名) prefer-ip-address: true
代码类,从服务端获取指定工程的地址,调用指定工程获取数据,并响应前端:
@RestController @RequestMapping(value = "/consumer") public class UserController { //restTemplate可以给指定路径发送请求,获取数据 @Autowired private RestTemplate restTemplate; //DiscoveryClient可以获取到Eureka server上指定的服务信息(如端口号和ip地址) @Autowired private DiscoveryClient discoveryClient; /**** * 在user-consumer服务中通过RestTemplate调用user-provider服务 * @param id * @return */ @RequestMapping(value = "/{id}") public User queryById(@PathVariable(value = "id")Integer id){ //根据服务名(在注册服务的时候就配置指定了服务名)获取服务信息 //因为可能集群原因,所以获取的服务应该是一个集合,集群配置的时候配置同名服务就可以 List<ServiceInstance> instances = discoveryClient.getInstances("USER-PROVIDER"); //获取第一个服务对象 ServiceInstance serviceInstance = instances.get(0); //将这个服务对象中的ip地址和端口号获取出来,拼接到发送的请求路径里面,就可以实现动态获取路径 String host = serviceInstance.getHost(); int port = serviceInstance.getPort(); String url = "http://"+host+":"+port+"/user/find/"+id; //然后利用restTemplate对象根据指定路径发送请求,将请求返回的数据封装到User对象中,最终返回给前端 return restTemplate.getForObject(url,User.class); } }
使用时,可能会出现索引越界,正常现象,过三十秒就可以了。
Eureka的自我保护机制
当服务正常关闭操作时,会发送服务下线的REST请求给EurekaServer。
服务中心接受到请求后,将该服务置为下线状态
服务中心每隔一段时间(默认60秒)将清单中没有续约的服务剔除。
通过eviction-interval-timer-in-ms配置可以对其进行修改,单位是毫秒
Eureka会统计服务实例最近15分钟心跳续约的比例是否低于85%,如果低于则会触发自我保护机制。
服务中心页面会显示如下提示信息

1.自我保护模式下,不会剔除任何服务实例
2.自我保护模式保证了大多数服务依然可用
3.通过enable-self-preservation配置可用关停自我保护,默认值是打开
Ribbon是Netflix发布的负载均衡器,有助于控制HTTP客户端行为。为Ribbon配置服务提供者地址列表后,Ribbon就可基于负载均衡算法,自动帮助服务消费者请求。
Ribbon默认提供的负载均衡算法:轮询,随机,重试法,加权。我们可用自己定义负载均衡算法
实现:
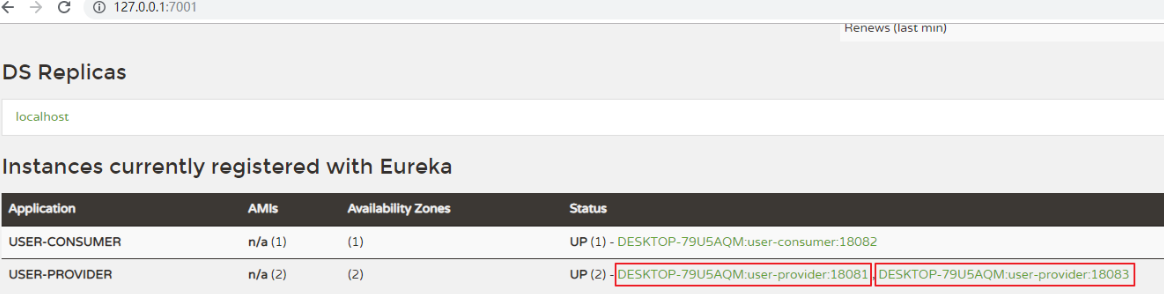
如果想要做负载均衡,我们的服务至少2个以上,为了演示负载均衡案例,我们可以复制2个工程
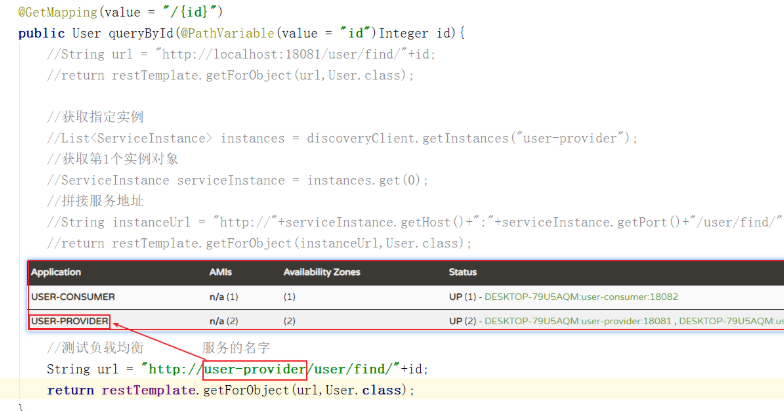
这两个工程注册服务的名字必须一致,其它的关键依赖要有,工程名字不一样,端口号要更改,不然端口冲突,当服务端和这两个集群的工程都启动以后,访问服务端的地址,就能看到以下界面:
Eureka已经集成Ribbon,所以无需引入依赖,要想使用Ribbon,直接在RestTemplate的配置方法上添加@LoadBalanced注解即可
采用服务名访问配置
修改user-consumer的调用方式,不再手动获取ip和端口,而是直接通过服务名称调用,代码如下:
配置修改轮询策略:Ribbon默认的负载均衡策略是轮询,通过如下
# 修改服务地址轮询策略,默认是轮询,配置之后变随机 user-provider: ribbon: #轮询 #NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #随机算法 #NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #重试算法,该算法先按照轮询的策略获取服务,如果获取服务失败则在指定的时间内会进行重试,获取可用的服务 #NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RetryRule #加权法,会根据平均响应时间计算所有服务的权重,响应时间越快服务权重越大被选中的概率越大。刚启动时如果同统计信息不足,则使用轮询的策略,等统计信息足够会切换到自身规则。 NFLoadBalancerRuleClassName: com.netflix.loadbalancer.ZoneAvoidanceRule
SpringBoot可以修改负载均衡规则,配置为ribbon.NFLoadBalancerRuleClassName
格式{服务名称}.ribbon.NFLoadBalancerRuleClassName
为什么只输入了Service名称就可以访问了呢?不应该需要获取ip和端口吗?
负载均衡器动态的从服务注册中心中获取服务提供者的访问地址(host、port)
显然是有某个组件根据Service名称,获取了服务实例ip和端口。就是LoadBalancerInterceptor
这个类会对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真正服务地址信息,替换服务id。
1.微服务中,一个请求可能需要多个微服务接口才能实现,会形成复杂的调用链路。
2.如果某服务出现异常,请求阻塞,用户得不到响应,容器中线程不会释放,于是越来越多用户请求堆积,越来越多线程阻塞。
3.单服务器支持线程和并发数有限,请求如果一直阻塞,会导致服务器资源耗尽,从而导致所有其他服务都不可用,从而形成雪崩效应;
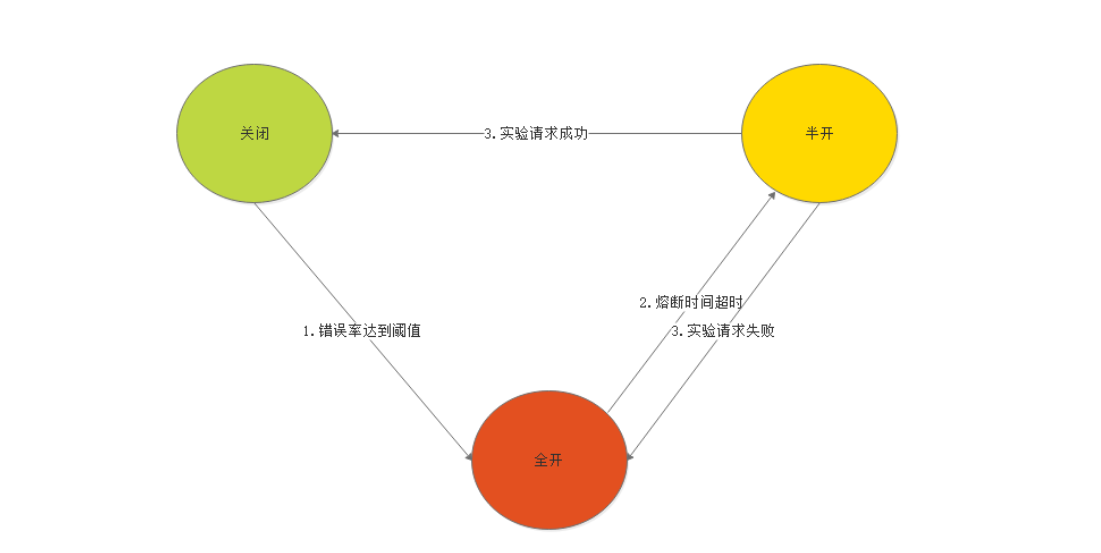
1.Closed:关闭状态,所有请求正常访问
2.Open:打开状态,所有请求都会被降级。
Hystrix会对请求情况计数,当一定时间失败请求百分比达到阈(yu:四声)值(极限值),则触发熔断,断路器完全关闭
默认失败比例的阈值是50%,请求次数最低不少于20次
3.Half Open:半开状态
Open状态不是永久的,打开一会后会进入休眠时间(默认5秒)。休眠时间过后会进入半开状态。
半开状态:熔断器会判断下一次请求的返回状况,如果成功,熔断器切回closed状态。如果失败,熔断器切回open状态。
threshold reached 到达阈(yu:四声)值
under threshold 阈值以下
熔断器的核心:线程隔离和服务降级
1.线程隔离:是指Hystrix为每个依赖服务调用一个小的线程池,如果线程池用尽,调用立即被拒绝,默认不采用排队。
2.服务降级(兜底方法):优先保证核心服务,而非核心服务不可用或弱可用。触发Hystrix服务降级的情况:线程池已满、请求超时。
局部熔断案例
目标:服务提供者的服务出现了故障,服务消费者快速失败给用户友好提示。体验服务降级
<!--熔断器-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
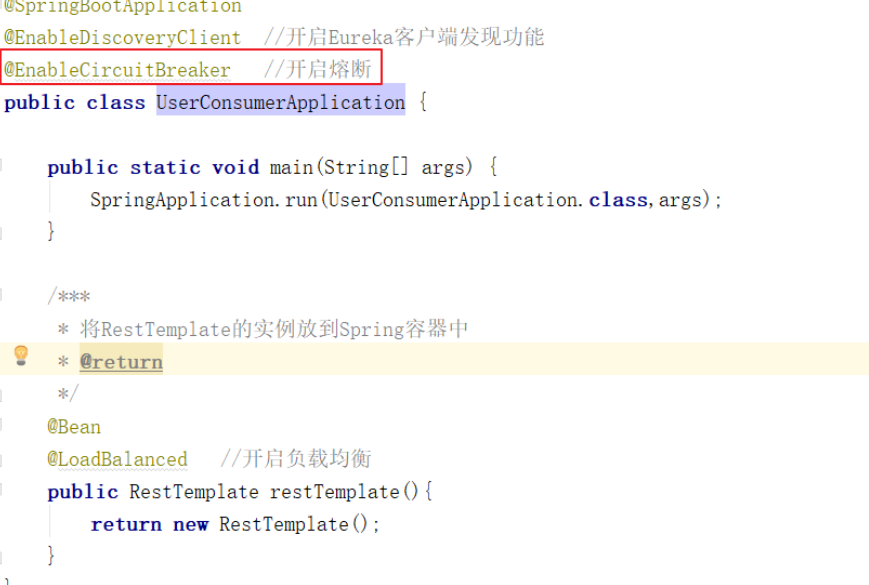
开启熔断的注解
修改该工程启动类,在该启动类上添加注解:@EnableCircuitBreaker
服务降级处理
添加降级处理方法,方法如下:
/**** * 服务降级处理方法 * @return */ public User failBack(Integer id){ User user = new User(); user.setUsername("服务降级,默认处理!"); return user; }
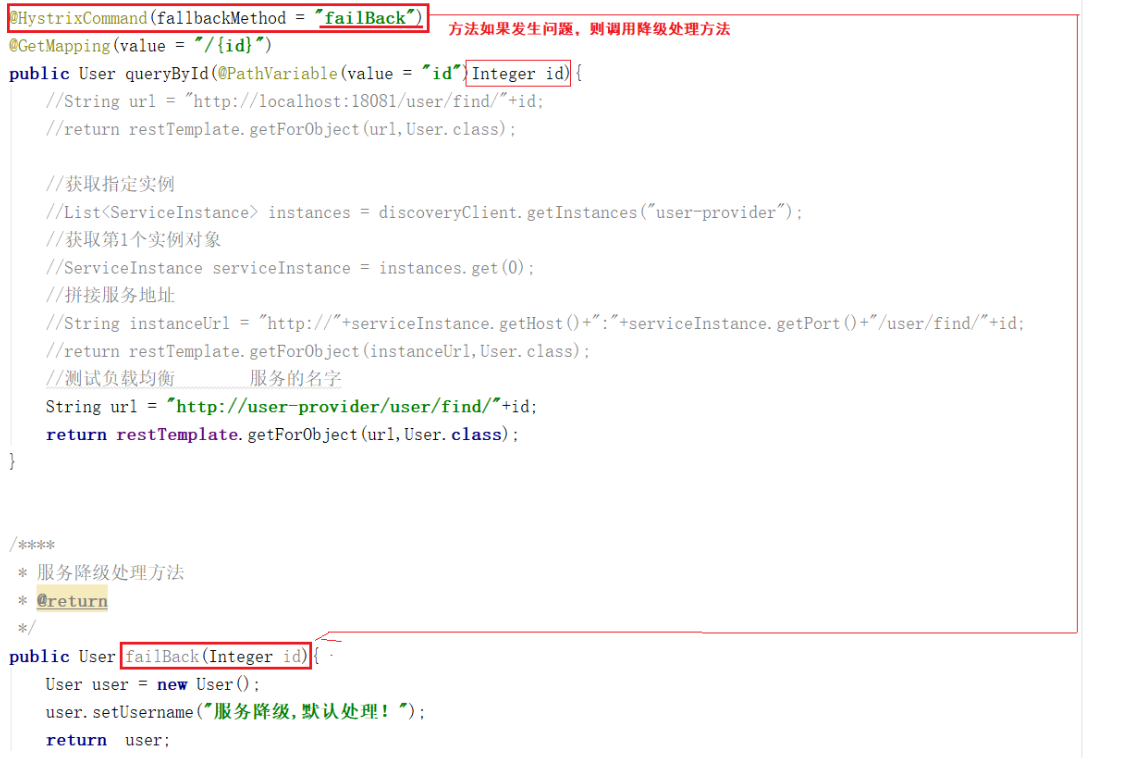
因为熔断的降级逻辑方法跟正常逻辑方法一样,必须保证相同的参数列表和返回值相同
# 配置熔断策略: hystrix: command: default: circuitBreaker: # 强制打开熔断器 默认false关闭的。测试配置是否生效 forceOpen: false # 触发熔断错误比例阈值,默认值50% errorThresholdPercentage: 50 # 熔断后休眠时长,默认值5秒 sleepWindowInMilliseconds: 10000 # 熔断触发最小请求次数,默认值是20 requestVolumeThreshold: 10 execution: isolation: thread: # 熔断超时设置,默认为1秒 timeoutInMilliseconds: 2000
(1)方法上服务降级的fallback兜底方法
使用HystrixCommon注解,定义
@HystrixCommand(fallbackMethod="failBack")用来声明一个降级逻辑的fallback兜底方法
(2)类上默认服务降级的fallback兜底方法
刚才把fallback写在了某个业务方法上,如果方法很多,可以将FallBack配置加在类上,实现默认FallBack
@DefaultProperties(defaultFallback=”defaultFailBack“),在类上,指明统一的失败降级方法;
总结使用服务降级的步骤:
1、在需要调用其它工程的工程添加hystrix的初步依赖
2、在需要调用其它工程 的启动类上添加@EnableCircuitBreaker注解,这个注解能开启熔断,就是说如果该启动类的工程调用另一个工程的时候,被调用的工程报错,本工程就可以使用服务降级,返回一个兜底方法,并且会根据熔断规则,达到条件进行熔断(不会再向该工程调用,等待配置的时间过后会再次根据配置规则进行尝试,尝试成功才会关闭Open,具体看熔断器的图,三种状态)
3、在工程调用另一个工程的具体实现的那个类中,编写一个服务降级的方法,当被调用工程报错以后,这个服务降级方法就会被返回。
4、在调用其它工程的具体方法上添加@HystrixCommand(fallbackMethod = "failBack")注解,参数中指定一个降级方法的方法名,如果这个方法调用的工程报错,则指定一个服务降级方法,将其返回。
5、如果一个工程调用另一个工程,这个工程的调用类中的方法需要的参数以及返回值都是一样的话,可以在类上加注解,只配置一个服务降级方法,这样这个类中的所有方法调用的工程出现问题,都会将配置的服务降级方法返回,而不需要每个调用的方法都加注解,每个方法都配置一个服务降级方法。在类上添加@DefaultProperties(defaultFallback = "defaultFailBack")注解,这个操作称之为全局熔断。
-
-
集成了Hystrix的熔断器功能
-
支持请求压缩
-
大大简化了远程调用的代码,同时功能还增强啦
-
1. 导入feign依赖
<!--配置feign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
2. 编写Feign客户端接口
//指定要调用的服务名称,当工程启动,就会根据Springmvc注解上的路径拼接服务名,去调用相应服务 @FeignClient(value = "PROVIDER") public interface UserService { /*** * 根据ID查询用户信息 * @param id * @return */ @RequestMapping(value = "/user/find/{id}") public User findById(@PathVariable(value = "id") Integer id); }
3. 消费者启动引导类开启Feign功能注解
@SpringBootApplication @EnableEurekaClient//申明这工程是一个Eureka的客户端 @EnableCircuitBreaker//熔断器 @EnableFeignClients//开启feign public class UserConsumerApplication { public static void main(String[] args) { SpringApplication.run(UserConsumerApplication.class,args); } }
4. 使用feign
@RestController @RequestMapping(value = "/consumer") public class UserController { //注入定义好的feign客户端接口,将会根据这个接口调用指定工程 @Autowired private UserService userService; /**** * 在user-consumer服务中通过RestTemplate调用user-provider服务 * @param id * @return */ @RequestMapping(value = "/{id}") @HystrixCommand(fallbackMethod = "failBack") public User queryById(@PathVariable(value = "id")Integer id){ //通过注入的接口实现类(框架自动实现)调用方法 return userService.findById(id); } /**** * 服务降级处理方法 * @return */ public User failBack(Integer id){ User user = new User(); user.setUsername("服务降级,默认处理!"); return user; } }
Feign会通过动态代理,帮我们生成实现类。
注解@FeignClient声明Feign的客户端,注解value指明服务名称
接口定义的方法,采用SpringMVC的注解。Feign会根据注解帮我们生成URL地址
注解@RequestMapping中的/user,不要忘记。因为Feign需要拼接可访问地址
# 修改服务地址轮询策略,默认是轮询,配置之后变随机 user-provider: ribbon: #轮询 NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule ConnectTimeout: 10000 # 连接超时时间 ReadTimeout: 2000 # 数据读取超时时间 MaxAutoRetries: 1 # 最大重试次数(第一个服务) MaxAutoRetriesNextServer: 0 # 最大重试下一个服务次数(集群的情况才会用到) OkToRetryOnAllOperations: false # 无论是请求超时或者socket read timeout都进行重试
1. 在配置文件application.yml中开启feign熔断器支持
在配置文件application.yml中开启feign熔断器支持:默认关闭
feign: hystrix: enabled: true # 开启Feign的熔断功能
2. 编写FallBack处理类,实现FeignClient客户端
//将这个实现类交给spring容器 @Component public class UserServiceImpl implements UserService { //如果接口调用的方法报错,那么就会将这个服务降级方法返回 @Override public User findById(Integer id) { User user = new User(); user.setUsername("服务降级"); return user; } }
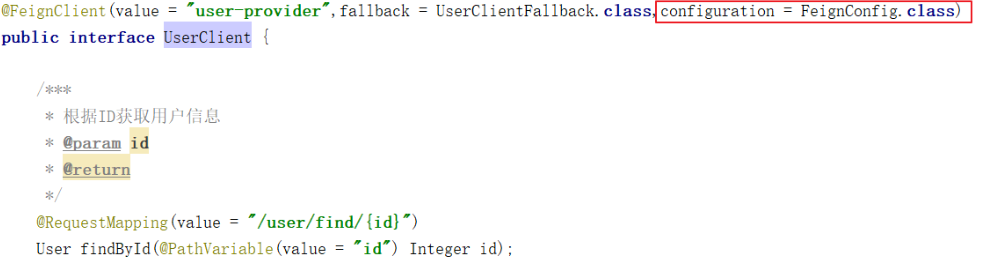
3. 在@FeignClient注解中,指定FallBack处理类。
//value = "PROVIDER":指定要调用的服务名称, //fallback = UserClientFallback.class指定本接口的实现类,这个实现类中完成了熔断器中的服务降级功能 // 当工程启动,就会根据Springmvc注解上的路径拼接服务名,去调用相应服务 //path = "/user":如果这个实现类中的所有方法路径中,都由/user开头,那么就可以在这里指定,它会将/user自动拼接 @FeignClient(value = "PROVIDER",fallback = UserServiceImpl.class,path = "/user") public interface UserService { /*** * 根据ID查询用户信息 * @param id * @return */ @RequestMapping(value = "/find/{id}") public User findById(@PathVariable(value = "id") Integer id); }
SpringCloudFeign支持对请求和响应进行GZIP压缩,以减少通信过程中的性能损耗。
通过配置开启请求与响应的压缩功能:
feign: compression: request: enabled: true # 开启请求压缩 response: enabled: true
也可以对请求的数据类型,以及触发压缩的大小下限进行设置
feign: compression: request: enabled: true # 开启请求压缩 mime-types: text/html,application/xml,application/json # 设置压缩的数据类型 min-request-size: 2048 # 设置触发压缩的大小下限 #以上数据类型,压缩大小下限均为默认值
1. 在application.yml配置文件中开启日志级别配置
# com.xxx 包下的日志级别都为Debug
logging:
level:
com.xxx: debug
2. 编写配置类,定义日志级别bean。
@Configuration public class FeignConfig { /*** * 日志级别 * @return */ @Bean public Logger.Level feignLoggerLevel(){ return Logger.Level.FULL; } }
3. 在接口的@FeignClient中指定配置类
4. 重启项目,测试访问
实现网关的技术:
+ nginx
+ spring cloud zuul
+ spring cloud gateway (微服务领域里中推荐使用,目标是替代Netflix Zuul)
-
-
断言Predicate函数:路由转发规则
-
1.端口过多,不容易维护
2.安全问题不好处理
3.日志在不同的微服务,无法有效的聚合 查看。
4.跨域的问题不好解决
5.登录的多次问题
通过网关来解决。
1. 创建gateway-service工程SpringBoot
添加依赖
<dependencies>
<!--网关依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- Eureka客户端 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
2. 编写基础配置
3. 编写路由规则,配置静态路由策略
4. 启动网关服务进行测试
# 注释版本 server: port: 8886 spring: application: name: api-gateway # 应用名 cloud: gateway: routes: #id唯一标识,可自定义 - id: user-service-route #路由的服务地址,如果符合某种条件,就要转发到的地址 uri: http://localhost:8882 # 路由拦截的地址配置(断言)这里表示只要是/user开头的并且必须是它开头的路径才可以通过网关 predicates: - Path=/user/** # Eureka服务中心配置 eureka: client: service-url: # 注册Eureka Server集群 defaultZone: http://127.0.0.1:7001/eureka
这是一个初步的网关配置,非常简单,在这个网关微服务中只需要写启动类和配置文件,配置文件中配置路由地址和断言规则,再将这个微服务注册到Eureka注册中心就可以了,但是还存在问题,路由地址是写死的,如果转发地址的那个微服务做了集群操作,写死会造成集群失效,不管怎么样都会只发到一个微服务地址上,并且没有过滤器的配置。
修改映射配置:通过服务名称获取:lb://服务名
# 注释版本 server: port: 8886 spring: application: name: api-gateway # 应用名 cloud: gateway: routes: #id唯一标识,可自定义 - id: user-service-route #路由的服务地址,如果符合某种条件,就要转发到的地址 #uri: http://localhost:8882 #lb协议表示从Eureka注册中心获取服务请求地址 #user-provider访问的服务名称。 #路由地址如果通过lb协议加服务名称时,会自动使用负载均衡访问对应服务 uri: lb://user-provider # 路由拦截的地址配置(断言)这里表示只要是/user开头的并且必须是它开头的路径才可以通过网关 predicates: - Path=/user/** # Eureka服务中心配置 eureka: client: service-url: # 注册Eureka Server集群 defaultZone: http://127.0.0.1:7001/eureka
默认过滤器:出厂自带,实现好了拿来就用,不需要实现
全局默认过滤器
局部默认过滤器
自定义过滤器:根据需求自己实现,实现后需配置,然后才能用哦。
全局过滤器:作用在所有路由上。
局部过滤器:配置在具体路由下,只作用在当前路由上。
默认过滤器几十个,常见如下:
| 说明 | |
|---|---|
| AddRequestHeader | 对匹配上的请求加上Header |
| AddRequestParameters | 对匹配上的请求路由 |
| AddResponseHeader | 对从网关返回的响应添加Header |
| StripPrefix |
全局过滤器:对输出响应头设置属性
对输出的响应设置其头部属性名称为X-Response-Default-MyName,值为itheima
修改配置文件:这个配置效果是在转发后获得的响应体中添加响应体的名称和响应体的值,又因为这是全局配置,所以所有的路由转发的响应都会添加配置响应体
spring: cloud: gateway: # 配置全局默认过滤器 default-filters: # 往响应过滤器中加入信息,前面一个是响应体名称,后面是响应体的值,自己根据需求设置 - AddResponseHeader=X-Response-Default-MyName,xxxx
在gateway中可以通过配置路由的过滤器PrefixPath 实现映射路径中的前缀
配置请求地址添加路径前缀过滤器:这个配置会在路由的路径上自动加一个前缀,比如浏览器发的请求是http://localhost:8886/find/1,那么在路由转发的时候就会根据以下配置发送成:http://localhost:8886/user/find/1
另外,如果要做这个配置的话,那么断言就要更改了,因为原先的断言没有/user这个前缀就进不来这个网关微服务,而请求如果加/user的话,这个配置又会自动拼接一个/user,这样两个/user的路径就会找不到
spring: application: # 应用名 name: api-gateway cloud: gateway: routes: #id唯一标识,可自定义 - id: user-service-route #路由的服务地址 #uri: http://localhost:18081 #lb协议表示从Eureka注册中心获取服务请求地址 #user-provider访问的服务名称。 #路由地址如果通过lb协议加服务名称时,会自动使用负载均衡访问对应服务 uri: lb://user-provider # 路由拦截的地址配置(断言) predicates: - Path=/** filters: # 请求地址添加路径前缀过滤器 - PrefixPath=/user default-filters: - AddResponseHeader=X-Response-Default-MyName,itheima
第二:去除路径前缀:
在gateway中通过配置路由过滤器StripPrefix,实现映射路径中地址的去除。通过StripPrefix=1来指定路由要去掉的前缀个数(从左边开始计算)。如:路径/api/user/1将会被路由到/user/1。
spring: application: # 应用名 name: api-gateway cloud: gateway: routes: #id唯一标识,可自定义 - id: user-service-route #路由的服务地址 #uri: http://localhost:18081 #lb协议表示从Eureka注册中心获取服务请求地址 #user-provider访问的服务名称。 #路由地址如果通过lb协议加服务名称时,会自动使用负载均衡访问对应服务 uri: lb://user-provider # 路由拦截的地址配置(断言) predicates: - Path=/** filters: # 请求地址添加路径前缀过滤器 #- PrefixPath=/user # 去除路径前缀过滤器 - StripPrefix=1 default-filters: - AddResponseHeader=X-Response-Default-MyName,xxxx
自定义过滤器也有两个:全局自定义过滤器,和局部自定义过滤器。
自定义全局过滤器的案例,自定义局部过滤器的案例。
自定义全局过滤器的案例:模拟登陆校验。
基本逻辑:如果请求中有Token参数,则认为请求有效放行,如果没有则拦截提示授权无效
1.在gateway-service工程编写全局过滤器类,实现GlobalFilter,Ordered两个接口
2.编写业务逻辑代码
3.访问接口测试,加token和不加token。
注意:这个实现类的名字必须以GlobalFilter结尾,前缀自己定义
@Component public class LoginGlobalFilter implements GlobalFilter, Ordered { /*** * 过滤拦截 * @param exchange * @param chain * @return */ @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { //获取请求参数,.getfirst(“token”)表示获取请求路径中第一个tonken String token = exchange.getRequest().getQueryParams().getFirst("token"); //如果token为空,则表示没有登录 if(StringUtils.isEmpty(token)){ //没登录,状态设置403 exchange.getResponse().setStatusCode(HttpStatus.PAYLOAD_TOO_LARGE); //结束请求 return exchange.getResponse().setComplete(); } //放行 return chain.filter(exchange); } /*** * 定义过滤器执行顺序 * 返回值越小,越靠前执行 * @return */ @Override public int getOrder() { return 0; } }
局部过滤器定义
自定义局部过滤器,该过滤器在控制台输出配置文件中指定名称的请求参数及参数的值,以及判断是否携带请求中参数,打印.
1. 在gateway-service中编写MyParamGatewayFilterFactory类
注意:这个实现类的名字必须以GlobalFilter结尾,前缀自己定义
@Component public class MyParamGatewayFilterFactory extends AbstractNameValueGatewayFilterFactory { /** * 处理过程 默认需要在配置配置文件中配置 NAME ,VALUE * * @param config * @return */ public GatewayFilter apply(NameValueConfig config) { return new GatewayFilter() { //- MyParam=name,value @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { String name111 = config.getName();//获取参数名name的值 String value111 = config.getValue();//获取参数名value的值 System.out.println("获取配置中的参数的NAME值:" + name111); System.out.println("获取配置中的参数的VALUE值:" + value111); //获取参数值 String name = exchange.getRequest().getQueryParams().getFirst("name"); if (!StringUtils.isEmpty(name)) { System.out.println("哈哈:" + name); } //添加到头信息或者作为参数传递等等. return chain.filter(exchange); } }; } }
2. 实现业务代码:循环请求参数中是否包含name,如果包含则输出参数值,并打印在第三步配置的参数名和值
3. 修改配置文件
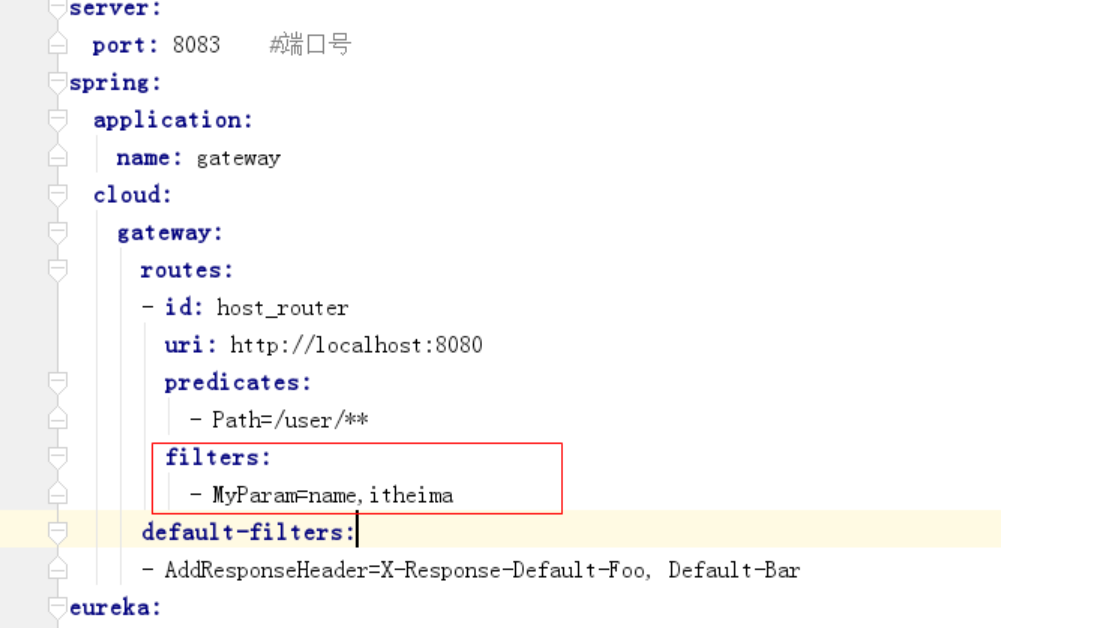
4. 访问请求测试,带name参数
测试访问,检查后台是否输出name和xxxx;访问<http://localhost:18084/api/user/find/2?name=xxxx&tomen=aaa>会输出。
-
-
网关实现鉴权、动态路由等等操作。
-
