Kaggle Machine Learning Tutorials
How-Models-Work
Introduction
We'll start with an overview of how machine learning models work and how they are used. This may feel basic if you've done statistical modeling(统计学模型) or machine learning before. Don't worry, we will progress to building powerful models soon.
This micro-course will have you build models as you go through following scenario(方案):
Your cousin has made millions of dollars speculating(投机) on real estate(不动产). He's offered to become business partners with you because of your interest in data science. He'll supply the money, and you'll supply models that predict how much various houses are worth.
You ask your cousin how he's predicted real estate(房地产,不动产) values in the past. and he says it is just intuition(直觉). But more questioning reveals that he's identified price patterns from houses he has seen in the past, and he uses those patterns to make predictions for new houses he is considering.
Machine learning works the same way. We'll start with a model called the Decision Tree. There are fancier models that give more accurate predictions. But decision trees are easy to understand, and they are the basic building block for some of the best models in data science.
For simplicity, we'll start with the simplest possible decision tree.
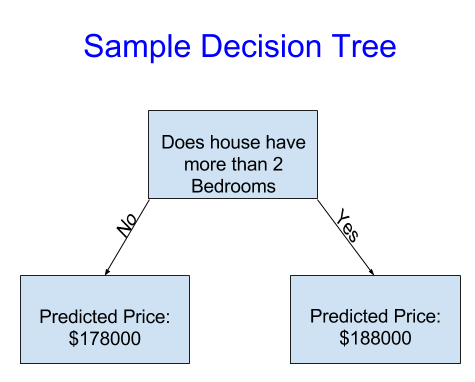
It divides houses into only two categories. The predicted price for any house under consideration is the historical average price of houses in the same category.
We use data to decide how to break the houses into two groups, and then again to determine the predicted price in each group. This step of capturing patterns(price patterns) from data is called fitting(拟合) or training the model. The data used to fit the model is called the training data.
The details of how the model is fit(怎么拟合) (比如 how to split up the data(the first action)) is complex enough that we will save it for later. After the model has been fit, you can apply it to new data to predict prices of additional homes.
Improving the Decision Tree
Which of the following two decisions trees is more likely to result from fitting the real estate(房地产,不动产) training data?

The decision tree on the left (Decision Tree 1) probably makes more sense, because it captures the reality that houses with more bedrooms tend to sell at higher prices than houses with fewer bedrooms. The biggest shortcoming of this model is that it doesn't capture most factors affecting home price, like number of bathrooms, lot size, location, etc.
You can capture more factors using a tree that has more "splits."(分歧) These are called "deeper" trees. A decision tree that also considers the total size of each house's lot might look like this:
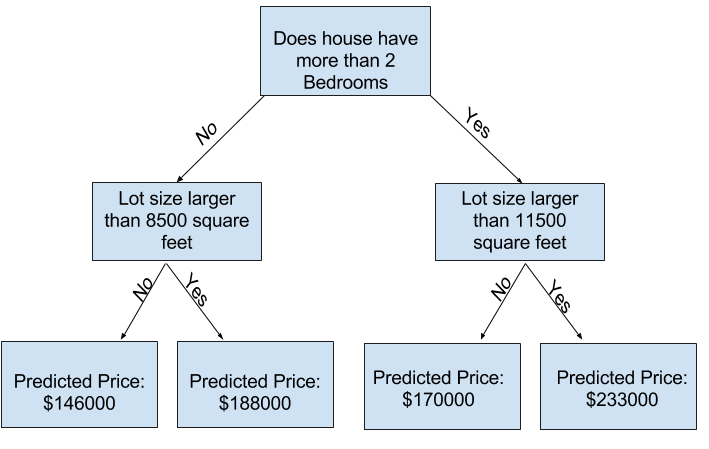
You predict the price of any house by tracing through(追踪) the decision tree, always picking the path corresponding to that house's characteristics(特点). The predicted price for the house is at the bottom of the tree. The point at the bottom where we make a prediction is called a leaf.
The splits and values at the leaves will be determined by the data(数据决定分歧和值), so it's time for you to check out the data you will be working with.
Continue
Let's get more specific(特定). It's time to Examine(考察) Your Data.
Basic-Data-Exploration
Using Pandas to Get Familiar With Your Data
The first step in any machine learning project is familiarize yourself with the data. You'll use the Pandas library for this. Pandas is the primary tool data scientists use for exploring and manipulating data. Most people abbreviate pandas in their code as pd. We do this with the command.
import pandas as pd
The most important part of the Pandas library is the DataFrame. A DataFrame holds the type of data you might think of as a table. This is similar to a sheet in Excel, or a table in a SQL database.
Pandas has powerful methods for most things you'll want to do with this type of data.
As an example, we'll look at data about home prices in Melbourne(墨尔本), Australia. In the hands-on exercises, you will apply the same processes to a new dataset, which has home prices in Iowa(爱荷华州).
The example (Melbourne) data is at the file path ../input/melbourne-housing-snapshot/melb_data.csv.
We load and explore the data with the following commands:
# save filepath to variable for easier access
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# read the data and store data in DataFrame titled melbourne_data
melbourne_data = pd.read_csv(melbourne_file_path)
# print a summary of the data in Melbourne data
melbourne_data.describe()
Interpreting Data Description
The results show 8 numbers for each column in your original dataset. The first number, the count, shows how many rows have non-missing values(非缺失值).
Missing values arise for many reasons. For example, the size of the 2nd bedroom wouldn't be collected when surveying a 1 bedroom house. We'll come back to the topic of missing data.
The second value is the mean, which is the average. Under that, std is the standard deviation(标准差), which measures how numerically spread out(分布) the values are.
To interpret(诠释) the min, 25%, 50%, 75% and max values, imagine sorting each column(列) from lowest to highest value. The first (smallest) value is the min. If you go a quarter way(4分位) through the list, you'll find a number that is bigger than 25% of the values and smaller than 75% of the values. That is the 25% value (pronounced "25th percentile"). The 50th and 75th percentiles are defined analogously(similar or correspondent in some respects though otherwise dissimilar), and the max is the largest number.
Your Turn
Get started with your first coding exercise.
Code Exercise
# Set up code checking
from learntools.core import binder
binder.bind(globals())
from learntools.machine_learning.ex2 import *
print("Setup Complete")
import pandas as pd
# Path of the file to read
iowa_file_path = '../input/home-data-for-ml-course/train.csv'
# Fill in the line below to read the file into a variable home_data(填充行以读the文件到变量home_data)
# pay attention to pd.read_csv()
home_data = pd.read_csv(iowa_file_path)
# Print summary statistics in next line
home_data.describe()
# What is the average lot size (rounded to nearest integer)(四舍五入到最近的整数)?
avg_lot_size = 10517
# As of today, how old is the newest home (current year - the date in which it was built)
newest_home_age = 10
# Think About Your Data
# The newest house in your data isn't that new. A few potential explanations for this:
# 1.They haven't built new houses where(地方) this data was collected.
# 2.The data was collected a long time ago. Houses built after the data publication(发布) wouldn't show up.
# If the reason is explanation #1 above, does that affect your trust in the model you build with this data? What about if it is reason #2?
# How could you dig into the data to see which explanation is more plausible(apparently reasonable and valid)?
# Check out this discussion thread to see what others think or to add your ideas.
我的思路:
最新房屋也没有那么新(没到2020年),潜在解释有:
1.没有在数据搜集处建新房屋
2.数据搜集于很久前,在数据发布后的房屋建设不出现
可以看到2000-2010即为后25%房屋建设年份,原大于以前年份,而最新房屋也仅是2010年
Going with reason #1 is not a good idea because it looks strange that they didn't build even a single house after year 2010.(在2010年后一个房屋都没建过不合理)
So, I will go with reason #2 - The data was collected a long time ago. Houses built after the data publication wouldn't show up.
——————
your-first-machine-learning-model
Selecting Data for Modeling
Your dataset had too many variables to wrap your head around(to accept something that one does not particularly want to accept), or even to print out nicely. How can you pare down(减少) this overwhelming amount of data to something you can understand?
We'll start by picking a few variables using our intuition(直觉). Later courses will show you statistical techniques to automatically prioritize(优先) variables.
To choose variables/columns, we'll need to see a list of all columns in the dataset. That is done with the columns property of the DataFrame (the bottom line of code below).
import pandas as pd
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.columns
Index(['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG',
'Date', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom', 'Car',
'Landsize', 'BuildingArea', 'YearBuilt', 'CouncilArea', 'Lattitude',
'Longtitude', 'Regionname', 'Propertycount'],
dtype='object')
# The Melbourne(墨尔本) data has some missing values (some houses for which some variables weren't recorded.)(不存在某些值。)
# We'll learn to handle missing values in a later tutorial.
# Your Iowa(爱荷华) data doesn't have missing values in the columns you use.
# So we will take the simplest option for now, and drop houses from our data.
# Don't worry about this much for now, though the code is:
# dropna drops missing values (think of na as "not available")(去not available数据)
# axis是轴,axis=0为down(row)(axis=None),axis=1为cross(column)
melbourne_data = melbourne_data.dropna(axis=0)
There are many ways to select a subset of your data. The Pandas Micro-Course covers these in more depth, but we will focus on two approaches(方法) for now.
- Dot notation(class.object), which we use to select the "prediction target"
- Selecting with a column list, which we use to select the "features"
Selecting The Prediction Target
You can pull out(拔出) a variable with dot-notation. This single column is stored in a Series, which is broadly like a DataFrame with only a single column of data.
We'll use the dot notation to select the column we want to predict, which is called the prediction target. By convention(惯例), the prediction TARGET is called y. So the code we need to save the house prices in the Melbourne data is
y = melbourne_data.Price
Choosing "Features"
The columns that are inputted into our model (and later used to make predictions) are called "features." In our case, those would be the columns used to determine the home price. Sometimes, you will use all columns except the TARGET as features. Other times you'll be better off(更好) with fewer features.
For now, we'll build a model with only a few features. Later on you'll see how to iterate and compare models built with different features.
We select multiple features by providing a list of column names inside brackets([]). Each item in that list should be a string (with quotes('')).
Here is an example:
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
By convention, this data is called X.
X = melbourne_data[melbourne_features]
Let's quickly review the data we'll be using to predict house prices using the describe method and the head method, which shows the top few rows.
```python
X.describe()
X.head()
Visually checking your data with these commands is an important part of a data scientist's job. You'll frequently find surprises in the dataset that deserve further inspection.
Building Your Model
You will use the scikit-learn library to create your models. When coding, this library is written as sklearn, as you will see in the sample code. Scikit-learn is easily the most popular library for modeling the types of data typically stored in DataFrames.
The steps to building and using a model are:
- Define(类型): What type of model will it be? A decision tree? Some other type of model? Some other parameters of the model type are specified too.
- Fit(拟合pattern): Capture patterns from provided data. This is the heart of modeling.
- Predict: Just what it sounds like
- Evaluate(评估): Determine how accurate the model's predictions are.
Here is an example of defining a decision tree model with scikit-learn and fitting it with the features and target variable.
from sklearn.tree import DecisionTreeRegressor
## Define model. Specify a number for random_state to ensure same results each run
melbourne_model = DecisionTreeRegressor(random_state=1)
## Fit model
melbourne_model.fit(X, y)
DecisionTreeRegressor(criterion='mse', max_depth=None, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=1, splitter='best')
Many machine learning models allow some randomness in model training. Specifying a number for random_state ensures you get the same results in each run. This is considered a good practice. You use any number, and model quality won't depend meaningfully on exactly what value you choose.
We now have a fitted model that we can use to make predictions.
In practice, you'll want to make predictions for new houses coming on the market rather than the houses we already have prices for. But we'll make predictions for the first few rows of the training data to see how the predict function works.
print("Making predictions for the following 5 houses:")
print(X.head())
print("The predictions are")
print(melbourne_model.predict(X.head()))
Making predictions for the following 5 houses:
Rooms Bathroom Landsize Lattitude Longtitude
1 2 1.0 156.0 -37.8079 144.9934
2 3 2.0 134.0 -37.8093 144.9944
4 4 1.0 120.0 -37.8072 144.9941
6 3 2.0 245.0 -37.8024 144.9993
7 2 1.0 256.0 -37.8060 144.9954
The predictions are
[1035000. 1465000. 1600000. 1876000. 1636000.]
Model Building Exercise
——————

