


【译】索引进阶(十):索引内部结构
【译注:此文为翻译,由于本人水平所限,疏漏在所难免,欢迎探讨指正】
原文链接:传送门。
在之前的系列文章中我们对索引进行了一个逻辑梳理,关注于它能为我们干什么。现在是时候对其进行一个物理上的分析并检查索引的内部结构。只有理解了索引的内部我们才能够理解索引的开销。只有通过了解索引的内部结构以及它是如何维护的,你才能够理解并最小化创建,修改,移除索引的开销,并理解数据行是如何插入,修改及删除的。
因此,在本章开始,除了索引的益处之外,我们将关注点扩展至包含索引的开销上。毕竟,最小化开销是最大化益处的一部分,而最大化索引的益处是本进阶系列一直所致力达成的。
叶子和非叶子层级
任何索引的结构都包含叶子和非叶子层级。尽管我们没有明确的说明,之前所有的层级关注于索引的叶子节点。因此,叶子节点其实就是表本身,每一个叶子节点的条目就是表的一行数据。对于非聚集索引,叶子节点包含了每行数据的一个对应的条目(过滤索引除外)。每一个条目包含了索引键列,可选的包含列,以及书签,而这个书签要么是聚集索引键列,要么是RID值,具体是哪一种值取决于其依赖表是一个聚集索引或是一个堆。
一个索引条目也叫作一个索引行,不管它是一个表的数据行(聚集索引叶子节点条目),指向一个表数据行(非聚集索引叶子节点),或者指向更低层的页(非叶子节点)。
非叶子节点是在叶子节点之上建立的一种结构,它使得SQL SERVER能够:
- 按索引键顺序维护索引条目。
- 给定一个索引键值快速找到叶子节点行。
第一章中,我们使用了电话本的相似性来帮助解释索引的益处。我们电话本的用户正在查找“Meyer, Helen”,知道那个条目会在任何姓氏排序列表的中间,于是直接跳转到黄页的中间开始查找,然而,SQL SERVER没有关于英语姓氏及其他任何数据的内在知识,除非它从开始到结束遍历整个索引,否则它不知道哪个页是中间页。因而SQL SERVER在索引中建立了一个额外的结构。
非叶子节点
这个额外的结构称作非叶子层级,或者节点层级。被认为是建立在叶子层级之上,不管它的叶子物理定位在哪,它的目的是对于每一个索引,为SQL SERVER提供一个单独的页入口点,以及一个从此页到包含任何给定索引键值 页的最短传输距离。
索引中的每一个页,不管它的层级,包含索引行或者条目,在叶子节点页,就像我们重复看到的那样,每一个条目要么指向一个表行,要么就是一个表行,因此如果一个表包含10亿行数据,那么索引的叶子节点便包含了10亿个条目。在叶子节点之上的节点,也就是最底层的非叶子节点,每一个条目指向一个叶子节点页。如果我们的10亿条目的索引平均每页100个条目,那么叶子层级包含了1,000,000,000 / 100 = 10,000,000个页。反过来,最低的非叶子层级包含10,000,000个条目,每一个指向一个叶子层级页,跨度100,000个页节点。
每一个更高层级的非叶子层级包含一些数据页,它的每个条目指向下一层级的页。我们的下一个更高层级非页节点将包含 100,000个条目,并且有1,000个页。而其之上的层级包含1000个条目及10个页大小,而这之上的层级将包含10个条目并聚集在一个页中,它便在这儿停止。
坐落在索引顶部的页称为根节点页,位于根节点之下及页子节点之上的索引层级称为中间节点。层级从叶子节点的0开始计数,因此最低的中间节点总是层级1。
非叶子层级的条目总是包含索引条目及指向更低层级页的指针,包含列仅仅存在于叶子层级条目,非叶子层级条目并不会携带它们。
索引中除了根节点之外的每个页,都包含了两个额外的指针,这些指针指向索引序列同一级别的下一个及上一个页。这样的双向链表索引使得SQL SERVER可以对任何层级的页进行升序或者降序扫描。
一个简单的示例
如下显示在图1的图表,帮助演示了这种索引的类似树的结构,图表代表了创建在Personnel.Employee 表的LastName / FirstName列上的索引,其使用了如下的SQL:
CREATE NONCLUSTERED INDEX IX_Full_Name ON Personnel.Employee ( LastName, FirstName, ) GO
图表注意:
指向页的指针包含了数据库文件编号及页编号,因此一个指针值5:4567指向了 #5号数据库文件的 第4567个页。
大部分示例值是从AdventureWorks数据库的Person.Contact表取出,还有一些其他数据为了演示目的被添加进去。
Karl Olsen是示例中最常见的名字,有如此多的Karl Olsens以至于其条目跨越了整个中间节点。
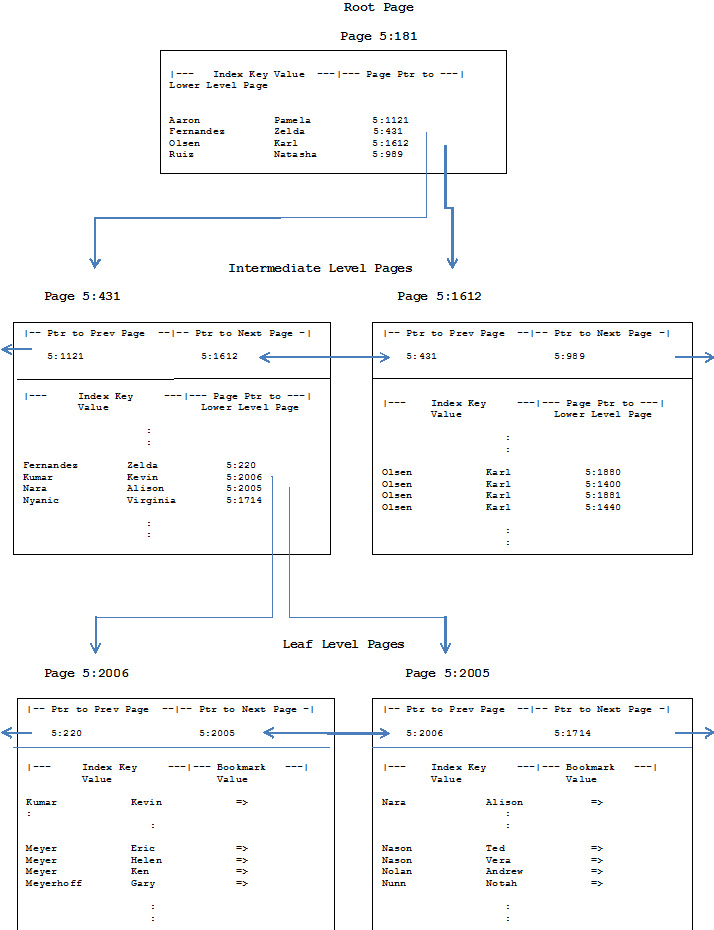
图1:索引的垂直横切
为了清晰和演示的目的,图表与典型的索引在如下方面有些不同:
典型索引每页的条目数比如上所示的 条目数要多,因此,除了根节点之外的每一层的页数也比演示的要多,特别的,叶子层级会比我们演示在如上的空间受限的图表里包含更多的页。
The entries of an actual index are not sequenced on the page. It is the page’s entry offset pointers that provide sequenced access to the entries. (See Level 4 – Pages and Extents for more information regarding offset pointers.)
There can be, and often is, more correlation between the physical and logical sequence of an index than is shown in the diagram. This lack of correlation between the physical and logical sequence of an index is called external fragmentation, and is discussed in Level 11 – Fragmentation.
如同之前提到的,一个索引可能包含多个中间节点。
这就如同我们的电话本用户,他将要查找“Helen Meyer“,打开电话本,然后发现第一页是粉色的,在粉色页序列条目列表中有一条说:For names between “Fernandez, Zelda” and “Olsen, Karl” see blue page 5:431,
当我们的用户跳转至蓝页5:431,那页的一个条目说:For names between “Kumar, Kevin” and “Nara, Alison” see white page 5:2006,粉色页对应着根节点,蓝页对应着中间节点,白色页便对应着叶子节点。
索引深度
根节点的位置和索引的其他信息一起存储在一个系统表中,每当SQL SERVER需要访问匹配一个索引键值的索引条目,它从根节点开始通过索引中每个层级的一个页,直到到达包含指定索引键条目的叶子节点。在我们的十亿行表的示例中,五次页读取会将SQL SERVER从根节点带到叶子层级的页及它所期望的条目,在我们的图表示例中,三次读取便足够了。在聚集索引中,叶子层级的页包含了实际的表数据行,在一个非聚集索引中,叶子条目要么包含了聚集索引键列,要么是一个RID值。
一个索引的层级数,或者说深度取决于索引键的大小及条目数。在AdventureWorks 数据库,没有一个索引的深度超过3,在包含非常大的表或者非常宽的索引键列的数据库中,6甚至更大的索引深度都会发生。
sys.dm_db_index_physical_stats函数提供关于索引的信息,包括索引类型,深度,以及大小。它是一个能够被查询的表值函数,显示在列表1的例子返回了SalesOrderDetail表所有索引的概要信息。



SELECT OBJECT_NAME(P.OBJECT_ID) AS 'Table' , I.name AS 'Index' , P.index_id AS 'IndexID' , P.index_type_desc , P.index_depth , P.page_count FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('Sales.SalesOrderDetail'), NULL, NULL, NULL) P JOIN sys.indexes I ON I.OBJECT_ID = P.OBJECT_ID AND I.index_id = P.index_id;
列表1:查询sys.dm_db_index_physical_stats函数,结果显示在图2。

相反的,显示在列表2的代码请求了一个特定索引的详细信息:SalesOrderDetail 表的uniqueidentifier 列的非聚集索引。它对于每个索引层级返回一行,如图所示。
ELECT OBJECT_NAME(P.OBJECT_ID) AS 'Table' , I.name AS 'Index' , P.index_id AS 'IndexID' , P.index_type_desc , P.index_level , P.page_count FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('Sales.SalesOrderDetail'), 2, NULL, 'DETAILED') P JOIN sys.indexes I ON I.OBJECT_ID = P.OBJECT_ID AND I.index_id = P.index_id;

从上图结果我们能够看到:
- 这个索引的叶子层级有407个页;
- 仅有的中间层级包含2个页;
- 根层级总是只有一个页。
一个索引的非叶子部分的大小一般是叶子节点大小的十分之一到二百分之一,其取决于哪些列组成了搜索键,书签的大小,以及如果有的话,哪些列被指定为包含列。换句话说,索引一般非常的宽和短,这与大部分的索引示例图表不同,如上图所示的索引非常高并且窄。
请记住,包含列仅仅对于非聚集索引是可用的,并且仅仅出现在叶子层级的条目中,它们被更高层级的条目所忽略,这就是为什么它们没有被添加到非叶子层级的大小。
因为聚集索引的叶子层级是表的数据行,一个聚集索引的非叶子部分是额外的信息,需要额外的存储。不管是否创建索引,数据行都是存在的,因此,创建一个聚集索引会占据时间并消耗资源,但是,当创建结束后,仅仅会消费很少的额外存储空间。
结论
给定一个索引键值,索引的结构可以使得SQL SERVER快速访问到指定的条目,一旦索引条目被发现,SQL SERVER能够:
- 访问那个条目对应的数据行;
- 从那个点升序或者降序遍历索引。
这种索引数结构已经使用了很长时间了,甚至比关系数据库的时间还要长,它已在时间中证明了自身。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南