


【译】索引进阶(八):SQL SERVER唯一索引
【译注:此文为翻译,由于本人水平所限,疏漏在所难免,欢迎探讨指正】
原文链接:传送门。
在本章节我们检查唯一索引。唯一索引的特别之处在于它不仅提供了性能益处,而且提供了数据完整性益处。在SQL SERVER中,唯一索引是保证主键约束和候选键约束的唯一合理的方式。
唯一索引和约束
唯一索引与其他任何索引并没有什么不同,唯一不同之处在于它不允许多个条目具有相同的索引键值。既然索引中的一个条目映射到了交互表的一行,那么阻止条目被加入到索引中便是阻止了数据行被加到表中。这便是为什么唯一索引是主键约束和候选键约束的保证。
声明一个主键或者唯一性索引都会导致SQL SERVER自动创建索引。你可以具有一个唯一索引而没有与之匹配的约束,但是没有唯一索引的话,你不能具有任何唯一约束。定义一个约束会导致与约束同名的一个索引被创建。不首先删除约束,你是不能删除索引的,因为约束是不能离开索引而存在的。删除约束也会导致与之关联的索引被删除。
每张表包含超过一个唯一索引是可能的。举个例子,AdventureWork库的Product 表具有四个唯一索引,ProductID, ProductNumber, rowguid, ProductName这四个列各有一个唯一索引。AdventureWorks 数据库的设计者选择ProductID 作表的主键,其他三个作替换键,有时候 称为候选键。
你能够用CREATE INDEX 语句创建一个唯一索引,如下所示:


CREATE UNIQUE NONCLUSTERED INDEX [AK_Product_Name] ON Production.Product ( [Name] );
也可以通过定义约束来创建唯一索引,如下所示:

ALTER TABLE Production.Product ADD CONSTRAINT PK_Product_ProductID PRIMARY KEY CLUSTERED ( ProductID );
在第一个例子中,你将确保不会有两个商品会有相同的商品名,在第二个例子中, 你将确保没有两个商品会有相同的ProductID 值。因为定义一个主键约束或者候选键约束会导致一个索引被创建,因此在约束的定义中你必须指定必要的索引信息,因此CLUSTERED关键字出现在上述ALTER TABLE 子句中。如果表包含有违反约束后者违反索引限制的数据,那么“CREATE INDEX ”语句会失败。
如果索引能够被创建,那么后续任何会 违反约束或索引的DML都会失败。举个例子,假设我们尝试着插入一条具有重复商品名的数据行,插入语句如下所示:
INSERT Production.Product ( Name, ProductNumber, Color, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice, Size, SizeUnitMeasureCode, WeightUnitMeasureCode, [Weight], DaysToManufacture, ProductLine, Class, Style, ProductSubcategoryID, ProductModelID, SellStartDate, SellEndDate, DiscontinuedDate ) VALUES ( 'Full-Finger Gloves, M', 'A unique product number', 'Black', 4, 3, 20.00, 40.00, 'M', NULL, NULL, NULL, 0, 'M', NULL, 'U', 20, 3, GETDATE(), GETDATE(), NULL ); 列表1:插入重复的商品名
这条语句会执行失败,我们会收到如下的错误信息:
Msg 2601, LEVEL 14, State 1, Line 1 Cannot INSERT duplicate KEY row IN object 'Production.Product' WITH UNIQUE INDEX  'AK_Product_Name'. The statement has been terminated.
这条信息告知我们AK_Product_Name 索引成功的保护了我们的表,它阻止了一个包含已经存在的商品名的数据行的非法插入。
在主键约束和唯一索引之间存在着一些细微的差异:
- 主键约束禁止null值,没有任何索引条目的索引键允许包含null值。而唯一性索引却允许null值。然而,既然唯一性索引认为两个null值是相互重复的,在每列中,只有一个包含null值的检索键值可以在索引中存在。
- 创建一个主键约束会导致创建一个聚集索引,除非以下事情发生:
- 表已经是一个聚集索引。
- 当你定义约束时候指定了NONCLUSTERED 关键字。
- 当你创建唯一约束并且表不是聚集索引时,创建唯一性约束会导致创建一个非聚集索引,除非你指定了CLUSTERED 关键字。
- 每张表只能有一个主键约束,但是可以有多个唯一性约束。
当决定是否创建一个唯一约束或者仅仅只是创建一个唯一索引时,请遵从MSDN库中的SQL SERVER文档:
“There are no significant differences between creating a UNIQUE constraint and creating a unique index that is independent of a constraint. Data validation occurs in the same manner, and the query optimizer does not differentiate between a unique index created by a constraint or manually created. However, you should create a UNIQUE constraint on the column when data integrity is the objective. This makes the objective of the index clear.”
组合使用唯一索引和过滤索引
我们在上面提到的唯一索引的属性:它们只允许存在一个null值,通常与通用的商业规则会有冲突。通常我们会想要保证一个列中已经存在的值是唯一的,而允许那一列多行数据都可以没有任何值。
举例来说,假设你是某个商品供应商,你会从第三方厂商那边得到某些商品,并且你将自己的产品信息保存在一张ProductDemo表中,你为所有的商品都分配了一个ProductID 值,同时你也保留了商品的UPC(Universal Product Code) 值。然而并不是所有厂商的产品都会有一个UPC值,因此你的表会存在如下部分数据:
ProductID |
UPCode | Other Columns |
| (Primary Key) | (Unique, but not a key) | |
| 14AJ-W | 036000291452 | |
| 23CZ-M | ||
| 23CZ-L | ||
| 18MM-J | 044000865867 |
表1:ProductDemo表的部分内容
在第二列,你必须要确保UPC列的唯一性同时还需要允许null值的存在,提供这种功能的最好方式是组合使用唯一索引与过滤索引(过滤索引是第七章的主题,它在SQL SERVER 2008被引入)。
为了演示这个,我们创建了一个简单的表,其包含上面显示的列:
CREATE TABLE ProductDemo ( ProductID NCHAR(6) NOT NULL PRIMARY KEY, UPCode NCHAR(12) NULL );
现在我们向其插入4条空UP Code行,那么四条数据会被加入到表中,如下所示:
INSERT ProductDemo (ProductID , UPCode) VALUES ('14AJ-W', '036000291452') , ('23CZ-M', NULL) , ('23CZ-L', NULL) , ('18MM-J', '044000865867');
然而当我们试着插入一行具有重复UPCode 值的数据行:
INSERT ProductDemo (ProductID , UPCode) VALUES ('14AJ-K', '036000291452');
我们接收到了如下错误信息并且数据行没有被插入。
Msg 2601, Level 14, State 1, Line 1
Cannot insert duplicate key row in object 'dbo.ProductDemo' with unique index 'AK_UPCode'.
The statement has been terminated.
如同在本章之前的例子所做的那样,你可以选择指定IGNORE_DUP_KEY 选项。因此,我们原始的 CREATE INDEX 语句没有经过措辞:
CREATE UNIQUE NONCLUSTERED INDEX AK_Product_Name
ON Production.Product ( [Name] )
WITH ( IGNORE_DUP_KEY = OFF );
这个选项的名称使人产生一些误解,因为当存在唯一索引时,重复的键值从来不会被忽略。更确切的说,唯一索引从来不会允许重复的键值。这个选项控制着插入多行数据时候可执行的行为。举个例子,你有两张表:表A和表B,它们有相同的表架构,那么你可以向SQL SERVER提交如下插入语句:
INSERT INTO TableA SELECT * FROM TableB;
SQL SERVER会尝试复制所有表B的数据行到表A,如果 表B的两条数据因为重复的值而不能被复制到表A会怎么样呢?你是希望其他所有行被复制,只有重复的两行失败呢,还是希望整个插入语句都会失败?
这个选择将由你来做。当你创建唯一索引时候,你将决定发生什么,当一个插入语句企图向一个唯一索引中插入多个重复键值时。IGNORE_DUP_KEY 的两个设置列举如下:
- IGNORE_DUP_KEY = OFF
整个插入语句都会失败,并列出一个错误信息,注意,此选项是默认的。
- IGNORE_DUP_KEY = ON
只有与已存在的行索引键值重复的行才会失败,并列出一个告警信息,注意,如果一个唯一索引同时又是过滤索引那么这个选项不能被设置。
IGNORE_DUP_KEY 这个选项仅仅影响INSERT 语句,它会被UPDATE,CREATE INDEX, ALTER INDEX 语句忽略,当给一个表添加主键索引或者唯一索引时,也可以指定IGNORE_DUP_KEY 选项。
为什么唯一索引能提供意想不到的益处?
唯一索引能提供意料之外的性能益处。这是因为它们提供给SQL SERVER一些我们视为理所当然而SQL SERVER绝不会假设的信息,AdventureWork数据库Product 表的两个唯一索引:ProductID 和ProductName提供了证明了这个例子。
假设你收到了一个来自仓库员工的请求,这个查询会展示给他们一些Product 表中各个产品的如下信息:
- 产品名
- 产品被出售的次数
- 这些销售的总价值
为了解决此问题,你写出了如下查询:
SELECT [Name] , COUNT(*) AS 'RowCount' , SUM(LineTotal) AS 'TotalValue' FROM Production.Product P JOIN Sales.SalesOrderDetail D ON D.ProductID = P.ProductID GROUP BY ProductID
仓库员工非常开心看到这个查询,因为它给了他们想要的结果。每个产品一行数据,每行包含了产品名,销售次数和总销售额。部分输出如下所示:
Name RowCount TotalValue
---------------------------------- ----------- ----------------------------------
Sport-100 Helmet, Red 3083 157772.394392
Sport-100 Helmet, Black 3007 160869.517836
Mountain Bike Socks, M 188 6060.388200
Mountain Bike Socks, L 44 513.000000
Sport-100 Helmet, Blue 3090 165406.617049
AWC Logo Cap 3382 51229.445623
Long-Sleeve Logo Jersey, S 429 21445.710000
Long-Sleeve Logo Jersey, M 1218 115249.214976
Long-Sleeve Logo Jersey, L 1635 198754.975360
Long-Sleeve Logo Jersey, XL 1076 95611.197080
HL Road Frame - Red, 62 218 394255.572400
然而,你关心于这个查询的潜在消耗,SalesOrderDetail 是这个查询所涉及的表中较大的那个,并且它的数据行必须按照产品名称分组,而这个产品名存在于Product 表,并不在SalesOrderDetail 表中。通过SSMS,你注意到SalesOrderDetail 表在它的主键上是聚集的(SalesOrderID / SalesOrderDetailID),当试着按产品名称分组时候这并不会产生任何益处。
如果你运行第五章的代码:包含列,你在SalesOrderDetail.ProductID 外键上创建了如下的非聚集索引:
CREATE NONCLUSTERED INDEX FK_ProductID_ModifiedDate ON Sales.SalesOrderDetail ( ProductID, ModifiedDate ) INCLUDE ( OrderQty, UnitPrice, LineTotal );
你感觉这个索引会对你的查询有所帮助,因为它包含了你的查询需要的所有信息,除了产品名之外,它按ProductID 的顺序排列,但是你仍关心于把一个表的信息按照另一个不同表的值进行分组。
你返回到SSMS,打开“显示实际的执行计划”选项,运行查询,注意到执行计划显示如下图:
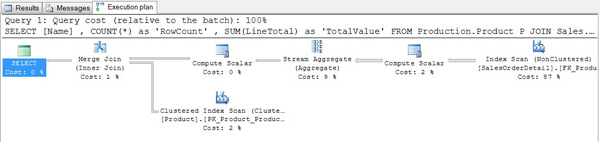
首先你很惊奇于看到Product表的产品名称索引,Product.AK_Product_Name从来没有使用过,即使它的列是GROUP BY子句的聚合键。那么你意识到 Product.Name有一个唯一索引和 Product.ProductID有一个唯一索引会告知SQL SERVER每一个product name和每一个product id都会有一个产品,因此e, GROUP BY [Name] 或者GROUP BY ProductID 是一样的分组,也就是说,它们都会一个产品产生一个分组。
因此查询优化器认为你的查询和如下的查询是相同的:
SELECT[Name] , COUNT(*)AS 'RowCount' , SUM(LineTotal)AS 'TotalValue' FROM Production.Product P JOIN Sales.SalesOrderDetail D OND.ProductID= P.ProductID GROUP BY ProductID
因此两个ProductID索引会同时支持对所请求数据的连接和分组操作。
SQL SERVER 能够同时扫描SalesOrderDetail 表上的覆盖索引和Product 表的聚集索引,它们两者都是以ProductID的顺序排列的,产生每个分组的总数,然后以产品名称合并,并不需要做任何排序或者哈希,简而言之,SQL SERVER为你的查询产生尽可能高效的执行计划。
如果你移除Product.AK_Product_Name 索引,像这样:
IF EXISTS ( SELECT * FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID(N'Production.Product') AND name = N'AK_Product_Name') DROP INDEX AK_Product_Name ON Production.Product;
那么新的执行计划(如下所示)并不高效,它需要额外的排序和合并操作。

你能够看到尽管唯一索引的主要目的是提供了数据的一致性,它也能够帮助查询优化器决定收集数据的最高效的方式,即使那个索引并不是设计用来访问数据的。
结论
唯一索引为主键约束和候选键约束提供支持。唯一索引可以与其交互的约束一起存在,但唯一约束不能离开它的索引而存在。
唯一索引可以同时是一个过滤索引(filtered index),这保证了唯一性的列可以允许多个null值存在。
IGNORE_DUP_KEY选项影响了多行插入语句的行为。
唯一索引能够提供更好的查询性能,即使索引并没有被使用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南