

20199315 2019-2020-2 《网络攻防实践》 综合实践
20199315 2019-2020-2 《网络攻防实践》 综合实践
With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning 论文复现
实验概述
实验目的
任务要求
四大顶会/顶级期刊论文重现与改进:
从四大安全会议挑选1篇论文,阅读并重现该论文的工作,如果能够改进可加分。具体要求如下:
-
从整体上介绍下论文的研究内容、论文的出处和作者、论文的研究方法、优缺点等。
-
具体介绍论文的研究工作。
-
通过分析该论文,请列出来与论文相关的值得研究的方向并详细介绍如何研究,给出研究思路
-
要求提供所读论文的电子版、综合实践报告、制作PPT讲解分析、录制视频、论文源代码(必须项)
-
评分根据工作量、内容分析的深刻程度、PPT和视频的质量、报告的质量等综合评定。
实验目的
完成期末综合实践相关要求,在以四大顶级安全会议为主的相关会议期刊论文中,选取一篇论文,阅读并重现该论文的工作。文章方面,对作者所做的基本研究工作有一定理解,完全看懂论文中的方法,包括整体结构、各个模块的组成、每个部分的参数和超参数如何设置等。如果某些细节论文没有阐述清楚,可以上网查询相关材料,甚至是给作者发邮件询问。环境方面,确保对编程语言较为熟悉,有对应的包或框架等。在前二者确定的情况下,结合作者团队公开的代码等信息完成复现,产生类似的实验结果与结论。
实验意义
一篇科学论文的成功复现可以让我们掌握完成以下 3 个步骤所需的所有信息:(1)设置相同的实验;(2)遵循相同的方法;(3)获得类似的实验结果。从复现论文的过程中,我们可以了解先前未曾接触过的安全类等领域的相关知识,为日后相关领域学习积攒知识与经验;甚至是学习作者提出的创新性方法,以后进行进一步改进,有自己的实验论文可以发表等等。
论文信息
论文题目
《With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning》
论文出处
刊登于USENIX Security 2018。
论文作者
Bolun Wang, UC Santa Barbara;
Yuanshun Yao, University of Chicago;
Bimal Viswanath, Virginia Tech;
Haitao Zheng and Ben Y. Zhao, University of Chicago.
论文概述
迁移学习是为解决深度学习面临困境的一种有效的方法,它允许用户通过从预先训练的、有大型数据集的集中式(教师)模型中“学习”,来快速构建准确的深度学习(学生)模型。我们假设教师模型的缺乏多样性导致了模型训练的集中化,从而增加了学生模型对错误分类攻击的脆弱性。论文首先帮助读者理解什么是迁移学习,以及迁移学习模型所存在的漏洞。我们确定了攻击者如何将学生模型与相对应的教师模型相关联的技术,对黑盒学生模型发起高成功率的定向误分类攻击。并在现实中广泛使用的教师模型上对此进行了实验验证。论文还提出了针对本文提到的攻击的多种防御方法,并分析了各种方法的优劣。最后,在假定攻击者不确定选择了何种教师模型的情况下,论文设计了一种指纹方法,只需要对学生模型进行少量图像查询就可以确定他的教师模型。
论文优势
论文实现的攻击方式的创新点在于,前人计算扰动程度都是使用Lp范数,但是它无法衡量人眼对于图像失真程度的感知,最终生成的对抗样本会对原图所有像素点都产生一些微弱的视觉暇疵,这也使得攻击易被发现。

本篇论文引入了DSSIM计算扰动程度,它是一种对图像失真度的客观测量指标。添加扰动后的对抗样本与原图相比,视觉上几乎没有差别。

论文另一大创新是“指纹”方法的提出与实现。本文设计了一种“指纹”方法,只需要对学生模型进行少量图像查询就可以确定他的教师模型。我们所讲到的“指纹”并不是针对指尖纹路进行分类识别,而是形象描述了这种由学生模型对应到教师模型的方法,就好比现实生活中,根据人与指纹的1:n关系,可以精准确定到这是谁的指纹一样。论文引入了经济学中的“基尼系数”的概念,当基尼系数<0.011时即可认为该学生模型是由某个教师模型训练得到的。
实验环境
环境要求
keras==2.2.0
numpy==1.14.0
tensorflow-gpu==1.8.0
h5py==2.8.0
Python 2.7.
数据集列表
PubFig:该数据集用于训练本文中的人脸识别模型。
CASIA Iris:此数据集用于训练Iris识别任务。
GTSRB:此数据集用于训练交通标志识别模型。
VGG Flower:此数据集用于训练Flower Recognition模型。
实验内容及原理
背景
现在很多企业都在做深度学习,但是高质量模型的训练需要非常大的标记数据集,比如在视觉领域ImageNet模型的训练集包含了1400万个标记图像,但是小型公司没有条件训练这么大的数据集或者无法得到这么大的数据集。
对于这个问题,当前一个普遍的解决方案就是迁移学习:一个小型公司借用大公司预训练好的模型来完成自己的任务。
首先了解一下什么是迁移学习,以及是什么对抗攻击。
迁移学习
什么是迁移学习
Transfer Learning,通常被译为“迁移学习”,是把别的模型学习到的参数架构等信息迁移到了当前的目标问题上,是当前比较常用的获取深度学习所需数据集的方案。
前百度首席科学家、斯坦福的教授吴恩达(Andrew Ng)曾经说过:“迁移学习将会是继监督学习之后的下一个机器学习商业成功的驱动力”。

迁移学习是一种机器学习方法,是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。用神经网络的词语来表述,就是一层层网络中每个节点的权重从一个训练好的网络迁移到一个全新的网络里,而不是从头开始,为每个特定的任务训练一个神经网络。
我们之所以对迁移学习感到兴奋,其原因在于现代深度学习的巨大价值是针对我们拥有海量数据的领域。但是,也有很多问题领域,我们没有足够数据。比如语音识别中,像是普通话,我们有很多数据,但是比如方言、少数民族特色语言,我们的数据就不够庞大。所以,为了针对那些数据量不那么多的语言进行语音识别,就可以从学习普通话中得到的东西进行迁移学习。
通常,如果源领域数据量充足,而目标领域数据量较小,这种场景就比较适合做迁移学习。例如我们我们要对一个任务进行分类,但是这个任务(目标域)中数据不够充足,然而却又大量的相关的训练数据(源领域),但是此训练数据与所需进行的分类任务中的测试数据特征分布不同(例如语音情感识别中,一种语言的语音数据充足,然而所需进行分类任务的情感数据却极度缺乏),在这种情况下如果可以采用合适的迁移学习方法则可以大大提高样本不充足任务的分类识别结果。
举个形象的例子,王夫人突然要出差,需要王先生在家陪孩子。但是王先生没有任何带孩子的经验,若是从头学起,肯定是来不及的。这时候王先生可以去问问王夫人平时都要做些什么,甚至是加入几个奶爸经验分享互助群,希望能将他人脑子里的知识一股脑地转移到自己脑中,这就是迁移学习。
与传统机器学习的不同
传统机器学习通常有两个基本假设,即训练样本与测试样本满足独立同分布的假设和必须有足够可利用的训练样本假设。

此外,在机器学习的经典监督学习场景中,如果我们要针对一些任务和域 A 训练一个模型,我们会假设被提供了针对同一个域和任务的标签数据。我们可以在下图中清楚地看到这一点,其中我们的模型 A 在训练数据和测试数据中的域和任务都是一样的。现在,让我们假设,一个任务就是我们的模型要去执行的目标,而域就是数据的来源。
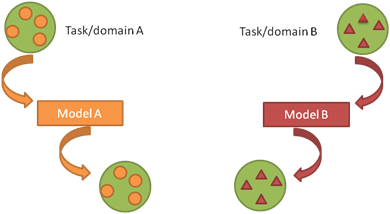
现在我们可以在这个数据集上训练一个模型 A,并期望它在同一个任务和域中的未知数据上表现良好。在另一种情况下,当给定一些任务或域 B 的数据时,我们还需要可以用来训练模型 B 的有标签数据,这些数据要属于同一个任务和域,这样我们才能预期能在这个数据集上表现良好。当我们没有足够的来自于我们关心的任务或域的标签数据来训练可靠的模型时,传统的监督学习范式就支持不了了。
即使是跟迁移学习比较相似的多任务学习,多任务学习是对目标域和源域进行共同学习,而迁移学习主要是对通过对源域的学习解决目标域的识别任务。下图就展示了传统的机器学习方法与迁移学习的区别:
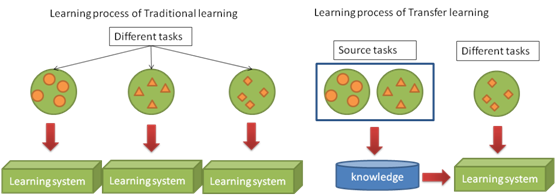
迁移学习主要解决了目前机器学习中存在的两个问题:
第一,是数据量不足的问题。虽然互联网和移动互联网催生了数据量的爆炸式增长,但在一些非互联网领域仍然存在数据量小的困境。医疗领域就是一个典型,有一些发病率较低的疾病样本数量很少,但会存在与它相关联的疾病和治疗方法,我们就可以通过已有的模型进行迁移,从而对疑难杂症进行大数据分析从而得出有效的诊疗方案。
第二,是个性化推荐的问题。每个人的喜好兴趣都不相同,通过数据可以分析出一个人的用户画像,对他进行内容的精准推荐。但如何给一个没有书籍浏览信息的人进行阅读推荐呢?这可以通过迁移学习,对他的音乐、艺术作品兴趣,包括学习经历等一系列信息,与他的阅读兴趣进行关联,从而实现在没有该领域数据积累下的个性化推荐。
迁移学习过程
论文中,称大公司的模型为“教师模型”,小公司迁移教师模型并加入自己的小数据集进行训练,得到属于自己的高质量模型“学生模型”。
迁移学习就是将“知识”从预先训练的教师模型转移到新的学生模型,学生模型的任务与教师模型的任务具有很大的相似性。该“知识”通常包括模型架构和与图层关联的权重。迁移学习使组织无需访问大量数据集或GPU集群即可快速构建针对其应用程序上下文定制的准确模型。
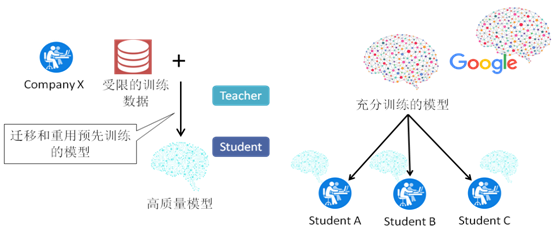
学生模型通过复制教师模型的前N-1层来初始化,并增加了一层全连接层用于分类,之后使用自己的数据集对学生模型进行训练,训练过程中,前K层是被冻结的,即它们的权重是固定的,只有最后N-K层的权重才会被更新。前K层之所以在训练期间要被冻结,是因为这些层的输出已经代表了学生任务中的有意义的特征,学生模型可以直接使用这些特征,冻结它们可以降低训练成本和减少所需的训练数据集。

根据训练过程中被冻结的层数K,可以把迁移学习分为以下3种方法:
1.深层特征提取器(Deep-layer Feature Extractor):K=N-1,学生任务与教师任务非常相似,需要的训练成本最小;
2.中层特征提取器(Mid-layer Feature Extractor):K<N-1,允许更新更多的层,有助于学生为自己的任务进行更多的优化;
3.全模型微调(Full Model Fine-tuning):K=0,学生任务和教师任务存在显著差异,所有层都需要微调。
实例介绍
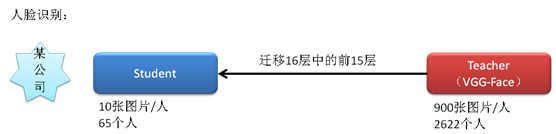
一个小公司准备实行人脸打卡上班,需要识别65个人的人脸,但它只有每人10张图的小数据集,它迁移了VGG-Face(由牛津大学视觉组于2015年发表的大规模人脸识别数据集,共16层)前15层,只将最后一层分类层改成了65分类,最后得到的分类准确率为93.47%。
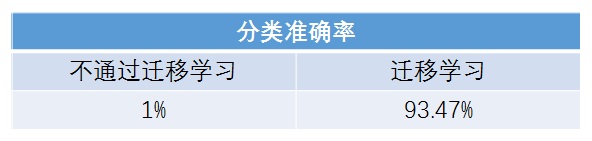
使用相同的数据集但使用随机权重(没有预先训练的权重)来训练学生模型,准确性会提高,会产生接近随机猜测的效果。
安全漏洞
迁移学习的安全问题性源于它缺乏多样性,即用户只能从很少的教师模型中进行选择,同一个教师模型可能被很多个公司迁移,攻击者如果知道了教师模型就可以攻击它的所有学生模型。
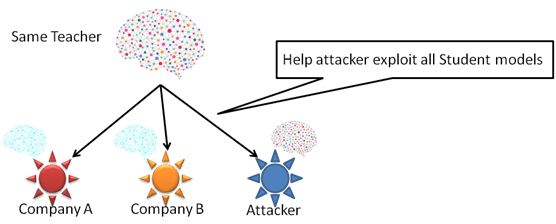
如今,大多数甚至可以说是所有的流行模型都已公开提供,以增加采用率。即使将来教师模型成为专有模型,针对单个教师模型的攻击者也可以通过冒充学生获得访问教师模型的方式来获取它。
对抗性攻击
什么是对抗性攻击
由于机器学习算法的输入形式是一种数值型向量(numeric vectors),所以攻击者就会通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击。
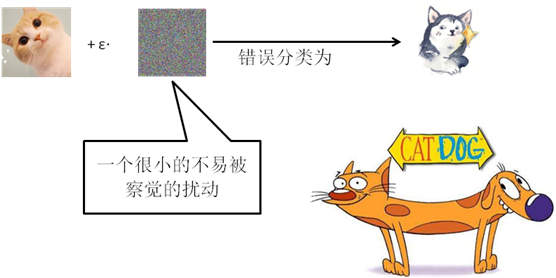
和其他攻击不同,对抗性攻击主要发生在构造对抗性数据的时候,之后该对抗性数据就如正常数据一样输入机器学习模型并得到欺骗的识别结果。基于深度学习的图像分类网络,大多是在精心制作的数据集下进行训练,并完成相应的部署,对于数据集之外的图像或稍加改造的图像,网络的识别能力往往会受到一定的影响。针对深度学习网络的对抗性攻击的目标是修改输入图像,以使它们在DNN中被错误分类。给定一个源图像,攻击者施加一个很小的不易被察觉的扰动,以使受害DNN将其错误分类为特定目标类别或除真实类别之外的任何类别。
分类
基于对于攻击者对分类器掌握多少信息的假设可以把对抗性攻击分为两类:
白盒攻击:攻击者能够获知分类器的内部体系结构及所有权重。它允许攻击者对模型进行无限制的查询,直至找到一个成功地对抗性样本。这种攻击常常在最小的扰动下获得接近100%的成功,因为攻击者可以访问深度神经网络的内部结构,所以他们可以找到误分类所需的最小扰动量。然而白盒攻击一般被认为是不切实际的,因为很少会有系统公开其模型的内部结构。
黑盒攻击:攻击者不知道受害者的内部结构。攻击者要么尝试反向工程DNN的决策边界,建一个复制品用于生成对抗样本;要么反复查询生成中间对抗样本并不断迭代改进。黑盒攻击的成功率通常低于白盒攻击,并且需要对目标分类器进行大量的查询。
常用术语
- Adversarial example/image
对抗样本/图像是干净图像的一个修改版本,它被故意干扰(例如通过添加噪声)来混淆/愚弄机器学习技术,如深层神经网络。
- Adversarial perturbation
对抗性扰动是指加到干净的图像中,使其成为一个对抗样本的噪声。
- Adversarial training
对抗训练是指除了使用干净的图像外,还使用对抗性图像来训练机器学习模型。
- Adversary
对抗者更多的是指创造对抗样本的代理人。然而,在某些情况下,这个对抗样本本身也被称为对抗者。
- ‘Semi-black-box’ attacks
在某些情况下,假定对抗者对模型的了解有限(例如,训练过程和/或其结构),但肯定不知道模型参数。在这些情况下,使用任何关于目标模型的信息都被称为“半黑箱”攻击。
- Detector
检测器是一种用于(仅)检测图像是否是对抗样本的工具。
- Fooling ratio/rate
欺骗率是指一个经过训练的模型在受到干扰后改变其预测标签的图像百分比。
- One-shot/one-step methods & iterative methods
一次/一步方式通过执行一步计算,例如计算模型损失梯度一次来产生对抗扰动。相反的是迭代方式,它们多次执行相同的计算以获得单个扰动。后者通常在计算上很昂贵。
- Quasi-imperceptible perturbations
准不可察觉的扰动会轻微地损害图像,就人类感知方面而言。
- Rectifier
整流器(校正器)修改对抗样本,以将目标模型的预测恢复到其对同一示例的干净版本的预测。
- Targeted attacks & non-targeted attacks
目标攻击欺骗了模型,使其错误地预测对抗性图像为特定标签。它们与非目标攻击相反,在非目标攻击中,对抗性图像的预测标记是不相关的,只要它不是正确的标记。
- Threat model
威胁模型是指一种方法所考虑的潜在攻击类型,例如黑匣子攻击。
- Transferability
可转移性是指对抗性范例即使对生成模型以外的模型也保持有效的能力。
- Universal perturbation & universality
普遍扰动能够以很高的概率在任意图像上欺骗给定模型。普遍性是指扰动的性质是“图像不可知论”,而不是具有良好的可转移性。
对迁移学习的攻击
攻击模型
当前常规模型的默认访问模式是:教师模型被深度学习服务平台公开;学生模型离线训练且不公开。
基于此,论文提出了一个新的针对迁移学习的对抗性攻击,即对教师模型白盒攻击,对学生模型黑盒攻击。攻击者知道教师模型的内部结构以及所有权重,但不知道学生模型的所有权值和训练数据集,只能对学生模型S使用有限的查询。我们认为给定的攻击者希望触发S的错误分类,除了单个对抗性样本触发错误分类外,在预攻击期间不会进行其他查询处理。
已知假设
假设攻击者知道欲攻击的学生模型S是使用某个确定的T作为教师模型训练的,并且知道在学生模型训练期间冻结了哪些图层。许多服务提供商(例如Google Cloud ML)在其官方教程中发布了此类信息,所以这类信息获取是较为容易的。后期也将进一步放宽此假设,并考虑此类信息未知的情况,提出使用一些其他查询从学生模型中提取此类信息的技术。
攻击策略
攻击目标
把source图猫误识别为target图狗。
攻击思路
首先将target图狗输入到教师模型中,捕获target图在教师模型第K层的输出向量。之后对source图加入扰动,使得加过扰动的source图(即对抗样本)在输入教师模型后,在第K层产生非常相似的输出向量。由于前馈网络每一层只观察它的前一层,所以如果我们的对抗样本在第K层的输出向量可以完美匹配到target图的相应的输出向量,那么无论第K层之后的层的权值如何变化,它都会被误分类到和target图相同的标签。
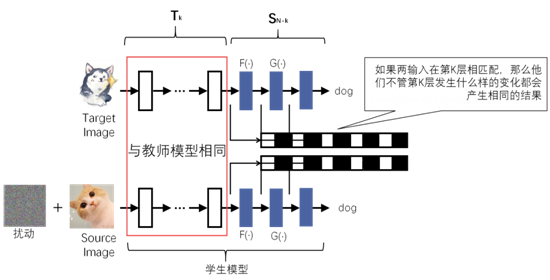
攻击图如图所示。在给定猫和狗的图像的情况下,攻击者将计算模拟在第K层上的狗图像的内部表示的扰动。如完美匹配,则对抗样本将被分类为狗,而不再关心S_(N-K)中的未知层。
定向/非定向攻击
定向攻击:将source image x_s误分类成target image x_t所属标签。本文建立的攻击模型属于定向攻击。
非定向攻击:将source image x_s误分类成任意其他的source image所属标签。
非定向攻击需要确定一个“方向”把source image推出它自己的决策边界。但是要预测这个“方向“是非常难的,所以本文的解决方法是,把每个定向攻击的攻击目标都试一遍,然后选出与source image第K层输出向量距离最小的类别作为目标。
扰动计算
本文通过求解一个有约束的最优化问题来计算扰动。目标是模拟隐藏层第K层的输出向量,约束是扰动不易被人眼察觉。即在扰动程度perturb_magnitude小于一定约束值(扰动预算P)的前提下,最小化对抗样本(扰动后的source image)第K层的输出向量与target image 第K层的输出向量的欧式距离。
min Distance(T_K (X_S+∆),T_K (X_t ))
s.t. perturb_magnitude(X_S+∆,X_S ) <P_budget
前人计算扰动程度都是使用L_p范数,但是它无法衡量人眼对于图像失真程度的感知。
假设x和y为我们要进行对比的两张图,SSIM(Structural Similarity)为二者的结构相似度,SSIM从luminance(l,亮度)、contrast(c,对比度)和structure(s,结构)三个方面对两张图进行比较:
SSIM(x,y)=l(x,y)*c(x,y)*s(x,y)
=((2μ_x μ_y+C_1)/(〖μ_x〗^2+〖μ_y〗^2+C_1 ))*((2σ_x 〖σμ〗_y+C_2)/(〖σ_x〗^2+〖σ_y〗^2+C_2 ))*((σ_xy+C_3)/(σ_x σ_y+C_3 ))
其中μ为均值,σ为标准差。
DSSIM(Structural Dissimilarity)是从SSIM中引申出的差异度量指标。
DSSIM= (1-SSIM)/2
本文使用DSSIM计算扰动程度,它是一种对图像失真度的客观测量指标。
攻击效果及影响因素
随机选择1000个source, target图像对,定向攻击的攻击成功率即为,成功将图像误分类为目标label的百分比。作者给出的针对人脸识别攻击成功率为92.6%,虹膜识别攻击成功率为95.9%。
影响攻击效果的因素有:
- (1)扰动预算P
扰动预算P的选择直接关系到攻击的隐蔽性。P越小攻击成功率越低。通过使用DSSIM度量方法测量图像失真,我们发现P=0.003是人脸图像的一个安全阈值。其对应的L_2范数值明显小于前人的结果。
- (2)距离度量方法
距离度量方法也会影响攻击效果,使用DSSIM产生的扰动不易察觉,使用L_2的扰动更明显。DSSIM能考虑到图像的潜在结构,而L_2平等对待每一个像素,并经常在脸部产生明显的“纹身样” 图案。
- (3)迁移学习方法
迁移学习方法也非常影响攻击效果,本文的攻击对于Deep-layer Feature Extractor是非常有效的,但对于Full Model Fine-tuning无效。
攻击层的选择
攻击者首先要判断学生模型是否使用了Deep-layer Feature Extractor,因为它是最易被攻击的方法。
如果学生模型的迁移学习方法是Deep-layer Feature Extractor,攻击者需要攻击第N-1层以获得最佳的攻击性能;
如果学生模型的迁移学习方法不是Deep-layer Feature Extractor,攻击者可以尝试通过迭代瞄准不同的层,从最深层开始,找到最优的攻击层。
攻击防御
论文还提出了3种针对本文攻击的防御方法:
- (1)通过Dropout随机输入,在预测过程中增加不确定性。
这种方法的主要好处是可以轻松部署,无需更改基础学生模型,对于已经部署好的Student model是理想的。但是,这种方法具有三个局限性。首先,对于模型成功率、模型准确性均具有不可忽略的影响。对于某些应用程序(例如,基于面部识别的身份验证系统),这可能是不可接受的。其次,这种方法对于虹膜识别等高度敏感的分类任务可能不符合现实需求。最后,攻击者可以通过在对抗性图像制作管道中添加一个Dropout层来规避这种防御。
- (2)在对分类准确性没有明显影响的情况下修改学生模型层权重。
这被认为是其中最可行的方案。修改学生模型,更新层权值,确定一个新的局部最优值,在提供相当的或者更好的分类效果的前提下扩大它和教师模型之间的差异。这又是一个求解有约束的最优化问题,约束是对于每个训练集中的x,让教师模型第K层的输出向量和学生模型第K层的输出向量之间的欧氏距离大于一个阈值,在这个前提下,让预测结果和真实结果的交叉熵损失最小。
- (3)将模型进行组合(正交模型orthogonal models)作为防御。
让提供者训练多个学生模型,每个模型来自单独的教师模型,并一起使用它们来回答查询(例如,基于多数投票)。 因此,即使攻击者成功愚弄了集成中的单个Student模型,其他模型也可能具有抵抗力(因为对抗性样本始终适合于特定的Student模型)。但同时会增加培训多个学生的一次性计算成本。
给定S确定T
前面我们的定向误分类攻击是在攻击者知道使用了哪个教师模型的前提假设下进行的,接下来我们放宽这个条件,考虑攻击者不能找出所使用的教师模型的情况。今天的深度学习服务(比如Google Cloud ML, Facebook PyTorch, Microsoft CNTK)会帮用户从一系列教师模型中生成学生模型。这种情况下,攻击者就得自己寻找他要攻击的学生模型对应的教师模型。本文设计了一种“指纹”方法,只需要对学生模型进行少量图像查询就可以确定他的教师模型。
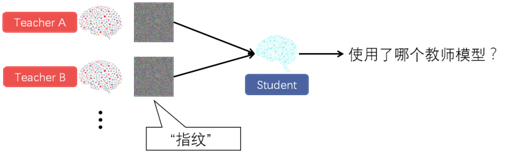
因为现实生活中,对于常规的深度学习任务,目前只有少数几个公开可用的高质量、预训练过的模型。所以我们不妨假设给定一个学生模型,攻击者可以知道它的教师模型候选池,候选池中的一个教师模型生成了该学生模型。比如Google Cloud ML 给图像分类任务提供的是Inception v3 , MobileNet及其变体作为教师模型。所以攻击者只需要在这一组候选模型中识别。
如果迁移方法为Deep layer Feature Extractor:
对于学生模型的最后一层(第N层),如果输入的图片是x,则预测的结果是:
S(x)=W_N*T_(N-1) (X)+B_N
其中,W_N是第N层的权值向量,B_N是偏置向量,T_(N-1) (•)是在第N-1层的输出向量。
当T_(N-1) (•)已知,我们的目标是找到一个输入图像x,使得T_(N-1) (x)=0, 这样S(x)=0+B_N=B_N。由于不同的教师模型的T_(N-1) (•)存在较大差异,所以如果将教师模型A的指纹图像x输入到教师模型B生成的学生模型中,它的T_(N-1) (x)一般不会是0 向量。
我们可以根据S(x)的离散度(dispersion)大小来判断该教师模型是否是与学生模型对应。
判断方法:如果S(x)的第一项为0,S(x)的 dispersion会非常低。dispersion通过基尼系数(Gini coefficient)来计算,取值范围为0~1,一个教师模型的指纹图像x输入学生模型产生的S(x)越接近0 (本文测试结果<0.011),说明有越有可能是该教师模型产生的该学生模型。攻击者可以根据dispersion的大小来判断哪个模型容易攻击。
基尼系数是经济学中的概念,在本文中如果基尼系数非常大,说明该学生模型对应的教师模型不在候选池中,或者该学生模型选择的不是Deep-layer Feature Extractor的迁移学习方法。
需要特别指出的是,我们所讲到的“指纹”并不是针对指纹信息进行分类识别,而是形象描述了这种由学生模型对应到教师模型的方法,就好比现实生活中,根据人与指纹的1:n关系,可以精准确定到这是谁的指纹一样。
复现过程
选择学生模型
我们选择精度最高的模型作为以后分析中的目标学生模型。表格显示了不同迁移方法的分类准确性。其中,中层特征提取器对应数值中带括号的数字是指,为达到相应精度而选择的层数K,以及教师的总层数。我们通过试验所有可能的K值来显示最佳Student模型的结果。

结果表明,使用深层特征提取器时,人脸识别可实现最高的准确度(98.55%),其次是虹膜识别。这是由于学生模型和教师模型任务的相似性,为迁移学习带来巨大受益。花卉的分类任务在全模型微调中表现最佳,因为两方模型任务不同,并且共享图层的收益也较小。最后,交通标志识别在采用中层特征提取器(选择16层中的第10层)时有较好表现。
选择攻击层
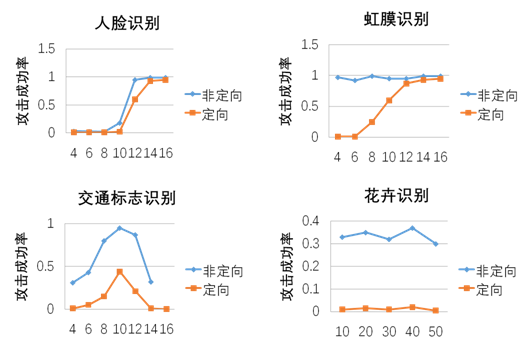
在攻击者不知道用于训练Student模型的确切迁移方法的情况下,攻击者需要首先选择“教师”层进行攻击,这就要考虑在传输过程中冻结的最深层是哪一层。
下图展示了以不同层为目标时,学生模型的目标和非目标攻击成功率。X轴表示目标图层。在训练过程中,脸部识别和虹膜识别任务会冻结前15层;交通标志识别任务冻结了前10层;花卉的分类任务不冻结。
选择扰动预算
在人脸识别中,不同的P对于攻击成功率的影响变化如下图。
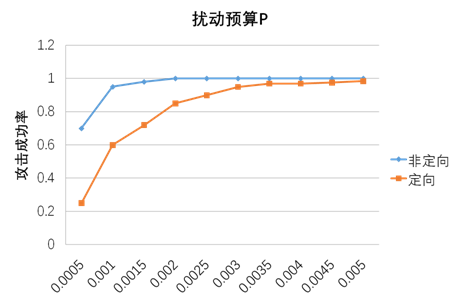
可见P=0.003是人脸图像的一个安全阈值,我们的实验将会展现扰动预算P=0.003的设定下的结果。
运行与结果
运行环境
代码规定的环境要求在第一章已经讲过了,这里简单介绍下我在实际复现论文代码时的配置。
使用的python为3.6版本,比要求的2.7版本较高,这也导致直接运行代码会产生一点小错误,具体问题与解决方案可见最后
遇到的问题与解决的内容。
参数修改
针对迁移学习的对抗攻击
在运行代码之前,需要对pubfig65_vggface_mimic_penalty_dssim.py文件的“PARAMETER”部分内容进行修改。本章节提到的所有下载均可在5.1章节找到相关链接。
(1)下载教师和学生的模型文件,并将其放置在正确的路径中。模型文件由TEACHER_MODEL_FILE和指定STUDENT_MODEL_FILE。可以下载经过预训练的模型,并将其放置在models文件夹下。
(2)论文作者提供了一个示例数据文件(sample data file),其中包含了Student模型中的每个标签的1张图像。下载数据文件后,将其放在datasets文件夹下。
(3)如果使用的是GPU,则需要指定要用于攻击的GPU。这个由DEVICE变量指定。如果找不到指定的GPU,则默认情况下它将回落到CPU。
(4)攻击配置由此部分参数指定。最重要的参数是NB_PAIR和DSSIM_THRESHOLD。
“指纹”方法判断教师模型
GitHub提供了两个示例代码文件,展示了如何在给定学生的情况下对教师模型进行指纹识别。
pubfig65_fingerprint_vggface.py显示了对VGGFace模型进行“指纹”识别并在使用VGGFace作为教师模型训练的人脸识别学生模型上进行测试。
pubfig65_fingerprint_vgg16.py显示了对VGG-16模型进行“指纹”识别并在同一人脸识别学生模型上进行测试。如前文所述,正确教师的指纹图像应产生均匀分布的预测结果,且该预测结果的基尼系数应当比较低(<0.011)。
与前面的攻击示例类似,运行前我们需要更改几个参数。本章节提到的所有下载均可在5.1章节找到相关链接。
(1)指定DEVICE中使用的GPU。
(2)由TEACHER_MODEL_FILE和STUDENT_MODEL_FILE规定模型文件的路径,或者可以直接从Keras的load_and_build_models()函数内部加载Teacher模型(见example)。
(3)DSSIM阈值(DSSIM_THRESHOLD)在“指纹”方法中设置为1。这是因为这并不是要进行攻击,因此不必隐秘。
(4)建立攻击者时,mimic_img标记设置为False。这是因为我们模拟了全零向量,而不是目标图像的内部表示。
代码运行
对抗性攻击
选定原图分别为29和8,攻击实现它们被误认为是目标7,实现错误分类的目的。每次的最终结果将原图source、添加扰动后的对抗样本、目标图target合成为一张图,以source-target.png命名。从图中也可以看到每次攻击耗时大约是400多秒。
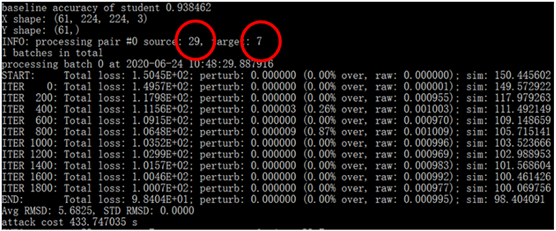
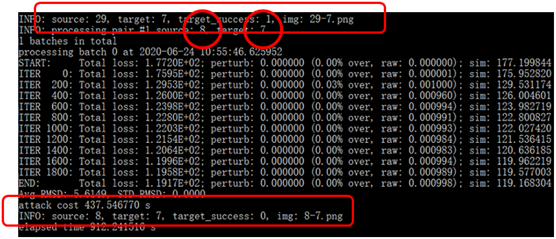

“指纹”方法判断教师模型
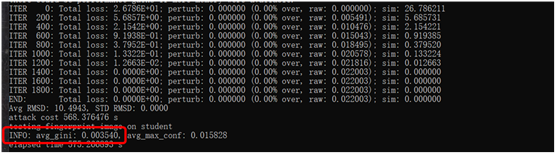
运行后,可以看到pubfig65_fingerprint_vggface.py产生的基尼系数为0.003540,小于0.011,认为该人脸识别学生模型是以VGGFace作为教师模型进行训练的,与实际相符。pubfig65_fingerprint_vgg16.py产生的基尼系数为0.508905,说明该模型不是以VGG-16模型为教师模型训练的,符合现实情况。
输出结果
我们可以在对应的文件夹下看到生成了这两张图片。根据论文设计的方案,添加扰动后的对抗样本与原图相比,视觉上几乎没有差别。


总结感悟
实验总结
迁移学习是小公司训练自身数据集的一种有效的方法,它允许用户通过从预先训练的、有大型数据集的集中式(教师)模型中“学习”,来快速构建准确的深度学习(学生)模型。首先通过论文的学习,对迁移学习、对抗性攻击有了基本的理解,然后对论文提出的针对迁移学习的攻击做了详细研究。接着对照作者在论文中的设定,以及GitHub上的提示信息,完成了代码结果的复现工作。
遇到的问题及解决
- 问题1:代码运行时报错:“NameError: name 'xrange' is not defined”
分析:在Python 2中,经常会用xrange()创建一个可迭代对象,通常出现在“for循环”中,这种行为与生成器非常相似。在Python 3中,range() 的实现方式与xrange()函数相同,所以就不存在专用的xrange(),如果你在Python 3使用xrange()就会出现NameError: name 'xrange' is not defined这个错误。
解决方法:将xrange()函数全部换为range()。
- 问题2:前文讲到,根据训练过程中被冻结的层数K,可以把迁移学习分为3种方法,并提到我们的攻击对深层特征提取器效果明显,仿佛特征提取器更易被攻击。那么为什么如今许多深度学习框架仍将深度层特征提取器用作迁移学习的默认配置,而非全模型微调呢?
分析:事实上,全模型微调和中间层特征提取器的确可以帮助学生模型更好的抵御本文提到的攻击。但这两种方法在实际应用中受限较大,尤其是在学生训练数据有限的情况下。例如,对于人脸识别,当将训练数据集从每类90张图像减少到每类50张图像时,将其往后推2层(即在第13层进行传输)会将模型分类的准确性降低到19.1%。然而此时深层特征提取器仍可达到97.69%的分类精度。除了性能之外,这些方法还比深层特征提取器有着更高的训练成本。这也是如今许多深度学习框架都将深度层特征提取器用作迁移学习的默认配置的原因。
- 问题3:教师模型上白盒攻击能否转移到学生模型身上?
分析:先前的工作确定了对抗样本在同一任务的不同模型之间的可传递性。对迁移学习的另一种潜在攻击是利用对教师的现有白盒攻击来制作对抗性样本,然后将其转移给学生。由于教师和学生模型具有不同的类别标签,因此我们只能执行非针对性的攻击。实验结果表明,由此产生的攻击对前文提到的人脸识别、虹膜识别、交通标识识别、花卉种类识别四个任务均无效:只有<0.3%的对抗性样本会在Student模型中触发错误分类。 据此可以认为,对教师模型的白盒攻击不会迁移给学生。攻击失败的原因可能是教师和学生任务之间的差异。学生模型的分类层(和决策边界)与教师模型不同,因此使用教师模型的决策边界分析(基于分类层)计算的对抗样本在学生模型上失败。
思考感悟
见实验报告
相关文献
相关下载
论文下载
数据集
预训练模型
其他
参考文献
此为本人网络攻防综合实践(安全类顶会论文复现)内容,为课程展示还制作了讲解PPT,如果您有任何需要,或是对博客内容存有疑问,可联系。

